#TIL
Transformer & BERT
transformer 이전에도 여러 언어모델들이 나왔었다. RNN부터 sequence to sequence(LSTM), TextCNN 등..
그러나 이젠 transformer 위주의 언어모델들이 사용된다.
Transformer
- RNN은 사용하지 않고 오직 attention으로만 구성
- attention으로 단어의 의미를 문맥에 맞게 잘 표현할 수 있음
- 병렬화 가능
- BERT, GPT등 모델의 기반
transformer가 풀려고 하는 문제는?
기계번역, 질의 응답 등
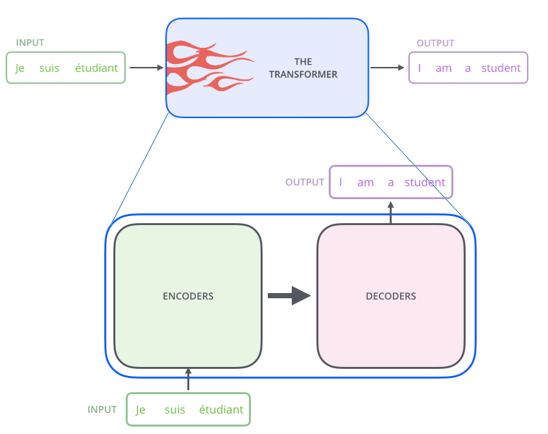
초반의 RNN 모델들의 구조와 비슷하다. encoder, decoder로 구성
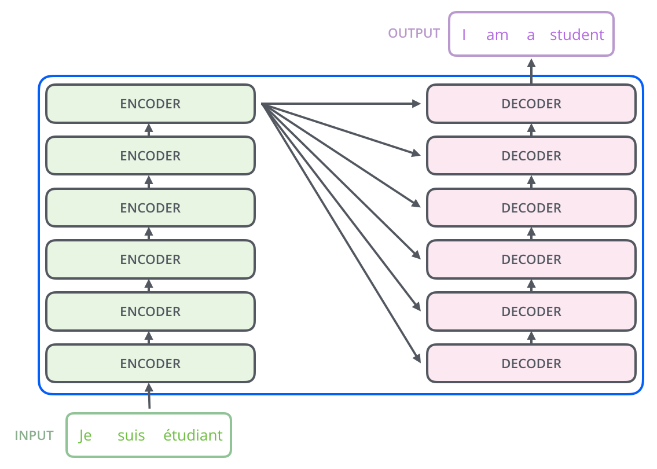
각 encoder의 구조는 동일하다!
그렇지만 각각 encoder 안에 들어있는 모델 파라미터들은 공유되지 않는다.
(decoder도 마찬가지!)
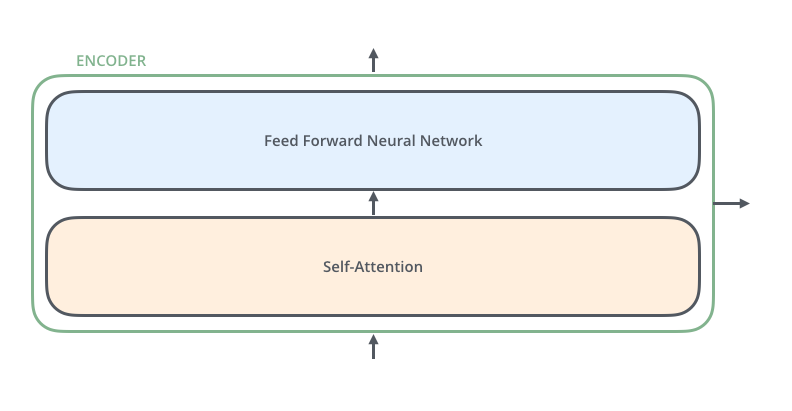
각각의 단어의 의미를 이해하는데 있어서 그 단어만을 사용하는 것이 아니라 그 주변의 문맥을 사용한다!! 즉, 문맥화된 단어의 의미를 파악하는 것이라고 할 수 있다.
self-attention은 각각의 문맥을 파악해야하므로 의존성이 있기 때문에 병렬화가 어렵다.
그러나 feed forward는 의존성 없이 독립적이기 때문에 병렬화가 가능하다.
또한, 모델이 표현할 수 있는 표현력을 한 번 더 높여주는 역할이라고 할 수 있다.
BERT
풀려고 하는 문제는?
Transfer learning을 통해 적은 양의 데이터로도 양질의 모델을 학습하는 것
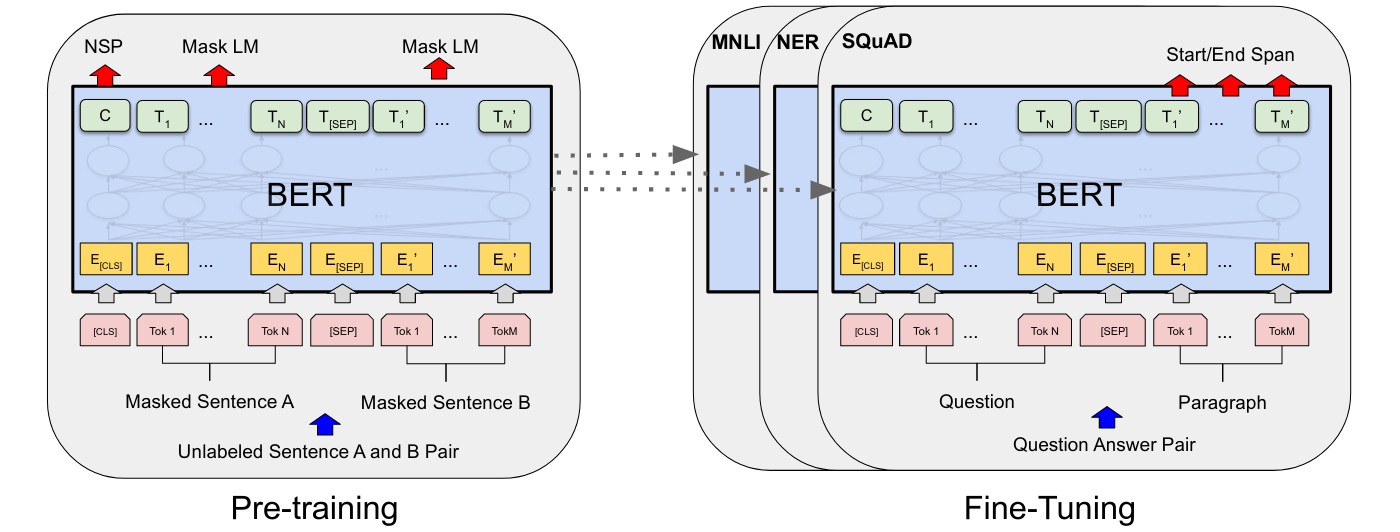
이렇게 pre-training 부분과 fine-tuning 부분으로 나뉜다.
pre-trained 된 모델을 가지고 fine-tuining 부분에서 classifier 문제를 푼다.
강의를 한번만 듣고나서는 머리에 제대로 안남는것같다..
한번 더 GO

공부중입니다 :D