: 주어진 암호가 단일치환암호일때, 빈도 분석을 통해 복호화하는 방법이다.
파일 설명
-
homework_20191686.py
: 단일 치환 암호문의 빈도 분석을 하는 python 파일 -
encryption.txt
: python 파일을 실행할 때 사용하는 암호문 txt 파일 -
result_decode.txt
: python 파일 실행시 생성되는 파일로, 암호문을 복호화한 글이 저장되는 txt파일 -
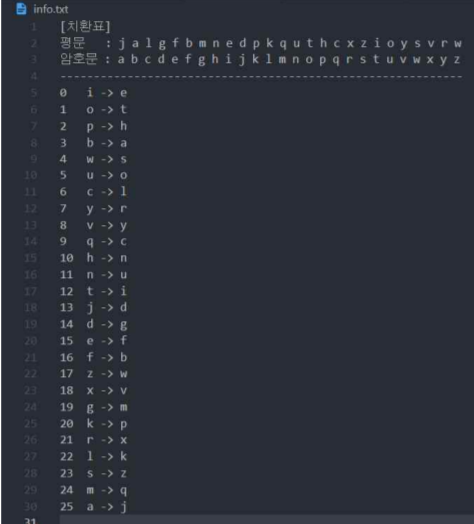
info.txt
: python 파일 실행시 생성되는 파일로, 암호문의 치환표 및 복호화 순서가 저장되는 txt파일
실행 방법
-
해당 repository clone : 터미널에 다음과 같은 명령어 입력
git clone https://github.com/Hyewon0223/SecurityProtocol.git -
cd SecurityProtocol을 통해 해당 repository로 이동 -
해독하고 싶은 암호문을 encryption.txt 파일로 저장 후 아래의 명령어 실행
python .\homework1_20191686.py
→ 알파벳 a를 b로 바꾸고 싶다면,a b입력
→ 종료하고 싶다면,exit입력
코드 설명
알파벳 빈도수
: 각 알파벳의 빈도수를 파악해 최빈도를 갖는 알파벳을 e로 치환한다.
txt = []
# 읽기 권한으로 파일 열기
with open("encryption.txt", "r", encoding="utf-8") as f_r:
# 변수에 해당 파일의 영문자를 소문자로 저장
data = f_r.read().lower()
Alphabet = 'abcdefghijklmnopqrstuvwxyz'
freq = [0] * 26
freq_dict = {}
'''
# 알파벳 빈도수
'''
for ch in data:
# txt = [[before1, after1],[before2, after2]] 형식으로 저장
txt.append([ch,'-'])
if ch in Alphabet:
# idx값이 a일때 0, b일때1, ..., z일때 25가 됨
# freq = [a빈도수, b빈도수, ..., z빈도수]
idx = Alphabet.find(ch)
freq[idx] += 1
# freq 배열을 내림차순으로 정렬할 경우, 순서가 섞이면 어떤 문자인지 알 수 없음
# 따라서, freq_dict에 사전 형식으로 저장, key는 알파벳, value는 freq 배열의 값을 가짐
# freq_dict = {'a' : a빈도수, 'b' : b빈도수, ...}
for i in range(0,26):
freq_dict[Alphabet[i]] = freq[i]
# freq_dict를 내림차순으로 정렬
sorted_freq = sorted(freq_dict.items(), key = lambda item: item[1], reverse = True)
print("빈도수 별 알파벳 정렬_내림차순")
print(sorted_freq)
print('---------------------------------------------------------------------------')
print(data)
alphabet_replace = []
user = input("> ")알파벳 치환 및 정보 저장
: 먼저 the를 찾고, 다른 단어와 빈도수를 통해 남은 알파벳을 파악한다.
with open("encryption.txt", "r", encoding="utf-8") as f_r:
# 알파벳 빈도수 코드
while (user != "exit") :
# decode는 파일에 저장하는 문자열 저장
# result는 사용자에게 보여지는 문자열 저장 -> 색상 포함
decode = ""
result = ""
# a를 b로 치환하고 싶다면 a b로 입력
# 입력 받은 정보를 공백 기준으로 배열에 저장
# user_split = ["a","b"]
# 입력받은 모든 user_split을 alphabet_replace에 저장
user_split = user.split()
alphabet_replace.append(user_split)
# 치환할 알파벳을 txt[i][1]에 저장
for idx in range(0,len(data)):
if (txt[idx][0] == user_split[0]):
txt[idx][1] = user_split[1]
if (txt[idx][1] != '-'):
decode += txt[idx][1]
result += '\033[31m'+txt[idx][1]+'\033[0m'
else:
result += txt[idx][0]
decode += txt[idx][0]
print(result)
print('-------------------------------------------------')
# result_decode.txt에 복호화한 문자열 저장
with open("result_decode.txt", "w", encoding="utf-8") as f_w:
f_w.write(decode)
# info.txt에 치환표 및 복호화 순서 저장
with open("info.txt", "w", encoding="utf-8") as f_w2:
sort_alphabet = sorted(alphabet_replace,key=lambda x:x[0])
f_w2.write("[치환표]\n")
before = "암호문 : "
after = "평문 : "
idx2 = 0
# 치환표 작성
for idx in range(0,len(Alphabet)):
before += Alphabet[idx]+' '
if (sort_alphabet[idx2][0] == Alphabet[idx]):
after += sort_alphabet[idx2][1] + ' '
if (idx2<len(sort_alphabet)-1):
idx2+=1
else :
after += ' '
f_w2.write(after)
f_w2.write('\n')
f_w2.write(before)
f_w2.write('\n')
f_w2.write('---------------------------------------\n')
# 복호화한 순서 작성
for i in range(0,len(alphabet_replace)):
text = str(i) + '\t' + alphabet_replace[i][0] + ' -> ' + alphabet_replace[i][1] + '\n'
f_w2.write(text)
user = input("> ")치환표
: 주어진 암호문을 복호화하면 다음과 갖는 치환표를 갖는다.

pt~~~