
Tableau (21.08.23 - 21.08.26)
Tableau 필수 기능
데이터 준비
유니온
엑셀에서 sheet 및 파일을 세로로 연결하여 불러오기.
- 한 파일에 sheet가 여러개인 경우 :
Drag and Drop. sheet 아래에 붙이면 '유니온' 할 수 있다. 또는 왼쪽에서 '새 유니온'을 클릭하여 원하는 sheet를 선택하여 불러올 수 있다. - 여러 파일을 연결하는 경우 :
파일을 불러온 후, '유니온으로 변환'을 클릭하여 원하는 파일을 이어 부를 수 있다. - 각 sheet 또는 파일에서의 column 필드 명이 다른 경우 하나로 합치기 :
command를 누른 채, 병합을 원하는 필드를 선택 > 우클릭 후, '불일치 필드 병합'
조인(물리적 결합) & 관계(느슨한 결합) & 블렌딩(화면에서의 ad-hoc 결합)
가로로 연결하여 불러오기.
좌측 상단에서 '추가' 클릭 > 연결할 파일 불러오기
- 조인 : 더블클릭하여 Drag and Drop으로 연결하기. (key field를 잘 잡아 주어야한다.) > 데이터 판을 새로 만듦.
- 관계(느슨한 결합) : Drag and Drop으로 연결하기.
- 블렌딩 결합 : 각각 데이터를 따로 분석 한다. 단, 먼저 시작하는 데이터가 메인이 되기 때문에 중요하다. 왼쪽 행 값에 Drag and Drop.(관계보다 더 느슨/유연하게 결합한다.)
필터
📌 필터
필터는 Tableau의 본질과 맞닿아 있는 기능이다.
필터는 다양한 스토리텔링을 가능하게 한다.
필터는 Tableau의 Order of Operations를 구성하는 행심요소이다.
필터의 종류
추출 필터
데이터 원본 필터 : 데이터 준비 창에서 작업 창으로 넘어오는 과정에서 필터가 걸린다.
컨텍스트 필터
차원 필터 : 일반적으로 필터를 건다는 뜻. (차원 테이블 우클릭 > '필터표시' 필터를 바깥으로 빼주기 때문에 편리하다.)
측정값 필터
테이블 계산 필터
숨기기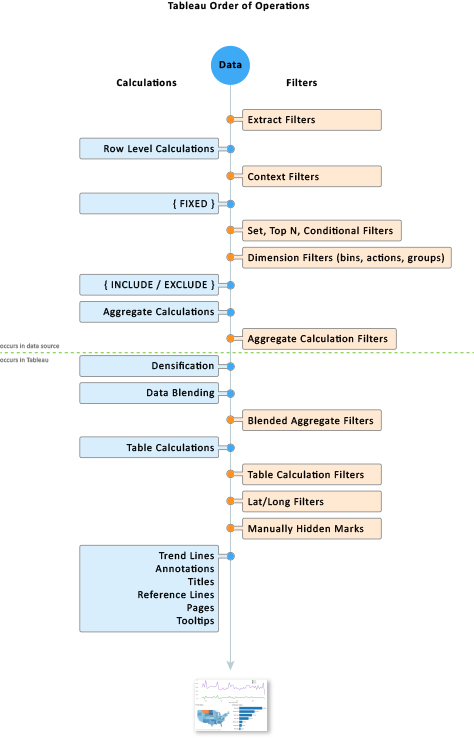
이중축과 결합축 차트
이중축 차트
- 행에 두개의 데이터가 있을 때, 우클릭 > 이중축 클릭, 또는 차트 오른편에 Drag and Drop.
- 축의 값에 차이가 크지만 스케일이 비슷 할 때,
축에서 우클릭 > 축 동기화 클릭동기화를 시켜 오해를 줄여준다. - 축의 값이 전혀 다른 값일 때는 동기화하지 않는다.
- 행의 알약의 위치를 변경해주면 원하는 그래프를 앞쪽으로 당겨서 볼 수 있다.
- 이중축 차트를 이용함으로서 비교하여 더 많은 인사이트를 발견할 수 있다.
결합축 차트
- 하나의 축에 결합하는 형태.
- 추가할 측정값을 축에다 Drag and Drop.
- 이중축 보다는 자유도가 떨어진다.
- 측정값이 전혀 다른 경우에는 결합축으로 보여주는 것은 변화를 잘 볼 수 없다. (이 경우에는 이중축 차트로 표현한다.)
이중축 + 결합축 차트
- 스케일이 비슷한지 확인 후 차트를 그려야 한다.
- 스케일이 비슷한 데이터와 전혀 다른 데이터를 함께 결합시켜 차르를 만들 때, 이중축과 결합축 차트를 함께 사용하여 만든다.
분석패널
상수라인 및 평균라인
- 상수라인
- 좌측 '분석' > 상수라인 원하는 행 또는 열에 Drag and Drop > 값기재(1B : 10억) > 상수라인 우클릭 '편집' > 레이블에 상세 내용
1차 매출 목표=<값>기재 가능 - 상수라인은 여러개 넣을 수 있다.
- 좌측 '분석' > 상수라인 원하는 행 또는 열에 Drag and Drop > 값기재(1B : 10억) > 상수라인 우클릭 '편집' > 레이블에 상세 내용
- 평균라인
- 좌측 '분석' > 평균라인 Drag and Drop > 평균라인 우클릭 '편집' > 레이블 사용자 지정
<계산>=<값>기재 가능
- 좌측 '분석' > 평균라인 Drag and Drop > 평균라인 우클릭 '편집' > 레이블 사용자 지정
총계
- 좌측 '분석' > 총계 Drag and Drop > 엑셀에서 처럼 총계를 보여준다.
- Drag and Drop에서 '소계'에 드롭하면 하위 합계를 확인할 수 있다.
추세선
- 좌측 '분석' > 추세선 Drag and Drop
예측 및 클러스터링
- 좌측 '분석' > 예측 Drag and Drop
- 연속형, 불연속형 모두 예측이 가능하다.
- 좌측 '분석' > 클러스터 Drag and Drop
- 클러스터는 좌측 다른 차원으로 빼서 활용할 수 있다.
참조선
- 좌측 '분석' > 참조선 Drag and Drop
지도
지리적 역할 부여
- 필요한 차원에서 우클릭 > 지리적 역할 > 시트 지우고, 차원 더블클릭
- 인터넷이 연결되어 있어야 한다.
점 좌표 표현
- 지리적 역할이 잘 부여 되어 있고, 적절한 레벨로 잘 분기하는게 중요하다.
맵 계층 & 맵 옵션
- 상단
맵 > 맵 계층: 다양하게 활용할 수 있다. - 상단
맵 > 맵 옵션 - 지도 좌측상단의 압정 모양을 누르면 원래 모양으로 돌아온다.
Vworld 배경 지도 활용
- Vworld 소스 사용.
- tms 다운 >
문서 > 내 Tableau 리포지토리 > 맵 원본붙여넣기.
- tms 다운 >
- https://douluvviz.tumblr.com/post/150711864227/using-vworld-background-map-in-tableau
Tableau level up
계산된 필드
계산된 필드란?
기존의 필드를 활용할 수도 있고, 함수를 가지고 새롭게 만들 수도 있다.
Tableau 분석의 확장성.
- 좌측 검색 화살표 또는 우클릭
계산된 필드 만들기 > 이름 만들기 > 함수 넣어 만들기(집계 레벨로 만들어지기 때문에 sum 함수를 사용하여 만들어야 한다.)- 새롭게 만든 필드 앞에는
=기호가 있다.
- 새롭게 만든 필드 앞에는
Tableau에서 활용할 수 있는 여러가지 함수들
- 좌측 검색 화살표 또는 우클릭
계산된 필드 만들기 > 우측 화살표 : tableau에서 사용할 수 있는 함수 확인 가능 - null 값이 있을 경우 계산이 안되므로
zn함수를 사용하여 0으로 바꿔준다. split구분자 단위로 끊어서 원하는 순서에 있는 것을 가져온다. (ex 서울시 서초구 서초동)- // 맨 앞에 슬래시 두개를 넣으면 주석처리된다.
IF 함수
IF 함수
- 계산된 필드를 이용하여 만들고 차트에 적용.
- ex ) Sales의 값이 3억이 넘으면 High, 그렇지 않으면 Low
IF SUM([Sales]) > 300000000 THEN 'High' ELSE 'Low' END- IF 조건 THEN True 결과 ELSE False 결과 END
(ELSE는 생략 가능하나 END는 필수!)
- IF 조건 THEN True 결과 ELSE False 결과 END
IIF 함수
- 조건, True일 때의 결과, False일 때의 결과
IIF(SUM([Sales]) > 300000000, 'High', 'Low')
함수 없이 조건 만으로도 심플하게 True, False 결과를 도출할 수 있다.
IF 함수 오류
True일 때의 결과 데이터 타입 = False일 때의 결과 데이터 타입 동일하지 않으면 오류가 발생한다.
ATTR과 같은 함수를 사용하여 집계로 바꿔줄 수 있다.
매개변수
CONSTANT into DYNAMIC
사용자의 능동적 역할을 유도함으로 다양한 가능성을 열어준다.
매개변수 만들기 & 적용하기
- 좌측에서
매개 변수 만들기 > 데터 유형 > 현재 값(나중에 변경 가능) > 허용 가능한 값(목록: 4지선다와 비슷, 범위: 지정한 값 이내에서만 수정 가능 - 매개변수를 만든 후,
매개변수 우클릭 > 매개변수 표시 - 매개변수는 독립적으로 활용할 수 없다.
- 참조선 활용 :
분석 > 참조선 > 값: 매개변수 선택 - IF함수 활용 :
IF SUM([Sales]) > [매개변수 이름] THEN 'High' ELSE 'Low' END - IIF함수 활용 :
IIF([매개변수 이름] = TRUE, [TRUE값], [FALSE값])(매개변수 이름 옆의 =TRUE 생략 가능) - CASE문 :
CASE [매개변수 이름] WHEN 'A' THEN [A가 있는 필드 이름] END(띄어쓰기 유의)
- 참조선 활용 :
- 그룹만들기 : 필드에서
우클릭 > 만들기 > 그룹 > 원하는 목록 선택 with command - TopN :
매개변수 만들기 > 범위 선택, 값 넣기
필터 선반에 필드 올리기 > 상위 > 필드 기준 > 위에서 만든 매개변수 선택
집합
그룹을 만들어 비교, 대비할 수 있다.
집합 만들기
- 필드에서
우클릭 > 만들기 > 집합 > 원하는 목록 선택:
관심의 대상을 직접 선택하여 새로운 필드로 만든다. - 데이터 카테고리를 올려서 원하는
데이터를 선택 with command > 벤다이어그램 클릭 - 조건으로 만들기 : 필드에서
우클릭 > 만들기 > 집합 > 원하는 목록 선택&집합 편집 > 조건 > 수식 사용 - 상위 개념으로 만들기 :
집합 만들기 > 상위 > 필드 기준 사용
결합된 집합
- 기준이 서로 다른 집합을 결합.
- 집합 연산 : 우클릭
결합된 집합 만들기 > 다른 집합 선택 > 집합 범위를 선택한다.- 모체가 같은 집합만 결합할 수 있다. (공통된 필드에서 집합을 각각 만들어야 한다.)
Tableau 테이블
테이블 계산
- Tableau가 지원하는 계산 방법 중 하나.
- 두번째 계산(Secondary), 메인은 집계 계산이다.
- 설정을 통해 계산을 할 수 있다.
테이블 패널 셀 옆으로 아래로
- 테이블 : 처음부터 끝까지
- 패널 : 보이는 뷰(하나의 블럭?)
- 셀 : 하나의 지점
- 옆으로 : 테이블 옆 방향으로 누적하여 계산
- 아래로 : 테이블 아래 방향으로 누적하여 계산
중첩된 테이블(Nested Table) 계산
- 테이블 계산이 두번 연속으로 들어간 계산.
테이블 계산 편집 > 누계 > 보조 계산 추가- 누적으로 쌓아 올려서 볼 수 있다.
함수
INDEX SIZE RANK TOTAL
- INDEX : '마크' >
index()필드 만들기 > 데이터 패널에 Drag and Drop > 인덱스 생성 완료
줄 서 있는 그래도 번호를 매긴다. - SIZE : '마크' >
size()필드 만들기
제일 끝값을 확인. - RANK : '마크' >
rank(SUM[Sales])
()안의 기준점으로 랭킹을 매긴다. 편집을 통해 sorting 개념을 설정할 수 있다. - TOTAL : '마크' >
total(SUM[Sales])
()안에 기준이 필요하다.
WINDOW
- customizing이 가능한 계산의 범위.
- 이미 계산 된 값은 또 계산 할 수 없기 때문에 계산 된 값을 다시 계산 할 때 사용한다.
- WINDOW 기준 범위 내에서 여러 계산을 할 수 있다.
- WINDOW_AVG 계산의 경우, 값이 부족한 경우 null을 선택한다.
테이블 계산과 필터
차원 필터를 사용할 때 주의
- 앞쪽의 필터에 영향을 받기 때문에 주의해서 사용해야 숫자가 뭉개지지 않는다.
- 숨기기 작업을 이용할 수 있지만 데이터가 업데이트 되었을 때 유용하지 않다.
- last 함수를 사용하면 데이터가 업데이트 되어도 수정하지 않아도 된다.
- 필드에서
last()함수 필드 만들기 > 필터에 Drag and Drop > last 값을 0으로 설정하면 마지막만 남는다.
예) last()=0 : 최신 값 / last()=1 : 전 월 / last()=12 : 끝에서 13번째 (1년 뒤)
테이블 계산 필터로 만들기 (LOOKUP 활용)
- LOOKUP() : 문자열 집계 함수
- LOOKUP(ATTR([Customer Name]), 0) : attr 활용, 0대신 -1을 쓰면 앞에 있는 정보를 가져온다.
- 필드에 LOOKUP 함수 필드를 만들기 > 필터 Drag and Drop
LOD
VLOD란?
View Level of Detail, Tableau의 화면이 어떤 필드에 의해 어떻게 쪼개져 있는가.
모든 측정값은 VLOD에서 표현된다.
VLOD를 결정하는 것은 오직 차원이다.
LOD 표현식
예 syntax : {Include[차원1],[차원2]:SUM([측정값)}
(SUM 대신 다른 측정값 사용 가능)
INCLUDE LOD
- 뷰에 반드시 표시되지 않아도 되는 차원을 계산에 고려한다.
예) 성별 정보가 포함되지 않은 뷰에 표시되는 성별을 포함하여 각 환자의 평균 혈압을 고려한다. - 데이터베이스에서 상세한 세부 수준으로 계산하여 다시 집계한 후 뷰에는 간단한 세부 수준으로 표시하려는 경우에 유용하다.
- INCLUDE 세부 수준 식에 기반하는 필드는 뷰에서 차원을 추가하거나 제거할 경우 변경된다.
EXCLUDE LOD
- 계산을 목적으로 뷰에서 일부 세부 정보를 제거한다.
예) 뷰가 각 환자에 대한 것이라도 개별 환자를 고려하지 않고 특정 의약품에 대한 환자의 평균 혈압을 고려한다.
FIXED LOD
- 나머지 계산에 대한 특정 차원을 설정한다.
예) 최대값을 환자ID로 고정하여 데이터 집합의 전체 최대값 대신 각 환자의 최대 혈압을 반환할 수 있다.
INCLUDE & EXCLUDE Vs. FIXED
- INCLUDE & EXCLUDE의 결과값은 항상 측정값.
- FIXED의 결과값은 차원 또는 측정값이 될 수 있다.
