
2021.03.30
-
JVM
운영체제 위에 눈에 안보이는 운영체제가 돌아간다고 생각
-
JDK
-
javap.exe - 역번역, 역컴파일 (완벽하게 번역이 되지 않아서 잘 안쓰임, 이론적으로 불가능한 작업, 존재 이유? 소스가 유실되었을때 분석하는 용도.)
-
jar.exe - 자바전용 압축프로그램 (압축이유? 파일을 손쉽게 보내거나(배포) 보관하기 쉽도록 압축함.)
-
-
JAVA API 문서
자바의 기능을 설명해둔 도움말
jdk 1.8 documentation -> https://docs.oracle.com/javase/8/docs/api/
Java의 바이블
- 자바 프로젝트 하나가 프로그램 하나라고 볼 수 있다.
-
패키지(= 폴더) : 자바 소스파일을 관계된 것 끼리 정리하고 분할하는 용도.
-
패키지를 먼저 만들고 안에 클래스 (소스파일)을 만든다.
-
부모 aaa 패키지의 자식 패키지 ddd만드는 방법 :
scr폴더 우클릭 - package - aaa.ddd
-
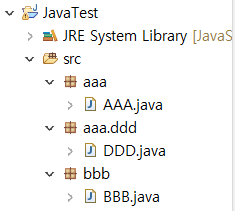
- 클래스 이름은 대문자로 시작해야한다.
public class Ex01 {
public static void main(String[] args) {
}
}- 특수문자 (자주쓰는 것들 영어표현으로 알아두기)
^ : xor (엑스오어)
| : vertical dar , pipe
@ : at sign
~ : tild-
괄호 표현
() : 소괄호
{} : 중괄호
[] : 대괄호
< > : 부등호
-
비교 연산자 읽기 (왼쪽부터 읽는다.)
A > B : A가 B보다 크다 (초과)
A < B : A가 B보다 작다 (미만)
A >= B : 이상
A <= B : 미만
- 주석(Comment)
컴파일러가 번역을 하지 않는 요소 개발자가 프로그래민 코드와 상관없이 여러가지 내용을 작성하고 싶을 때 주석을 달면, 코드 가독성 향상, 전달력 향상, 팀작업 향상
// 단일 라인 주석
/*다중
라인
주석*/- 기본 구문 설명
//패키지 선언
//-> 해당 파일(클래스)이 해당 패키지 내에 위치합니다.
package com.test.java;
//클래스 - 선언부, 헤더, 식별자, 코드의 집합
public class Ex02 {
//메소드 - 구현부, 바디, 내용물 작성, 코드의 집합
public static void main(String[] args) {
System.out.println("안녕하세요");
}
}- 괄호 표현 방식 (회사마다 방식이 다름)
K&G - 코드가 짧아지는 장점, 이클립스가 기본적으로 쓰는 방식
BSD : 가독성이 좋지만 코드가 길어짐, VSCode에서 기본적으로 쓰는 방식
-
식별자 명명 규칙
작업할때 여러가지 요소의 이름을 짓게 된다. 이름을 지을 때 지켜야하는 규칙
폴더명, 파일명, 클래스명, 메소드명, 변수명 ... 모든 이름
- 영문자 + 숫자 + _ 만 사용한다. (한글, 스페이스, 특수문자 사용금지)
- 숫자로 시작 불가 (숫자로 시작하고 싶으면 _를 먼저 써주자)
- 의미있게 이름 지을 것(가장 중요한 규칙!!!!!), 약자 사용 금지(풀네임으로 작성 할 것)
- 들여쓰기 규칙
- 탭키 - 작성이 편함, 환경에 따라 여백의 길이가 다르게 보임
- 스페이스키 - 작성이 불편함, 환경이 달라도 일정한 길이로 여백이 보임
수업 (20p~55p~ 73p)
자료형(Data Type)
데이터의 형태, 길이(범위) 등을 미리 정의하고 분류한 규칙(약속)
ex) "숫자" - 자료형
100, 200 - 자료
자바 언어의 자료형
- 원시형 (Primitive Type), 값형(Value Type) - 8가지
A. 숫자형 (양수와 음수를 모두 표현하는 자료)
a. 정수형(-2^n-1 ~ 2^n-1 -1)
- byte : 1byte(8bit)
- short : 2byte(16bit)
- int : 4byte(32bit)
- long : 8byte(64bit)
b. 실수형(부동 소수점)
- 범위 : -무한 ~ +무한대 라고 생각하자.
- float : 4byte(32bit) -> 단정도형 (정도 : 정밀도, 정확도)
- double : 8byte(64bit) -> 배정도형 (단정도형보다 배로 정밀도가 높다.)
B. 문자형
- char : 2byte
- 다른 언어(옛날 언어) : char이 1byte인 아스키코드를 썼었다.
- 1byte(아스키코드 : 256 표현가능, 비영문권 표현불가)
=> 2byte(유니코드 : 65536가지 표현가능, 모든형태의 문자표현가능)
C. 논리형
- boolean : 1byte
- 명제(참, 거짓) -> true, false- 참조형 (Reference Type)
-
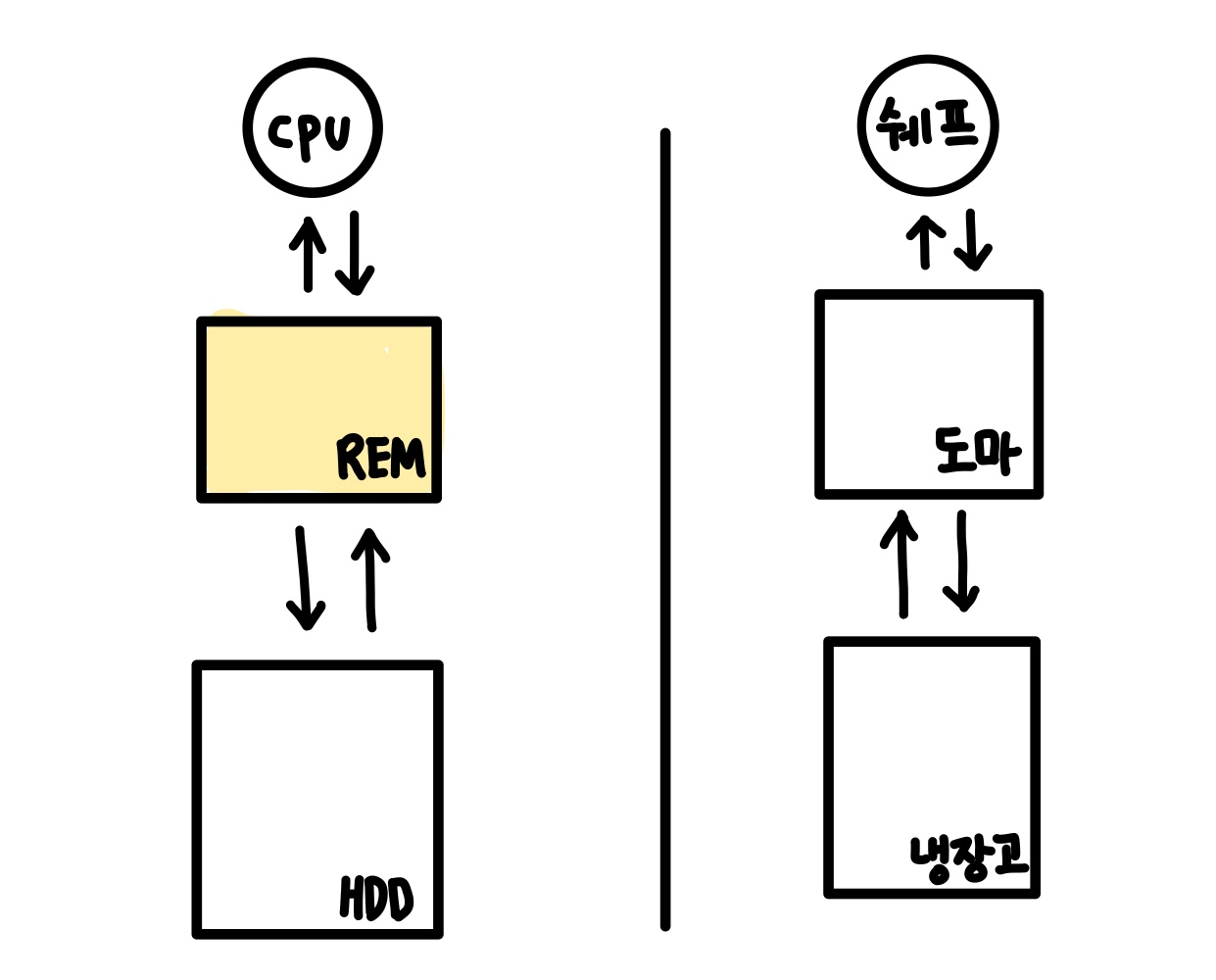
CPU
REM에서만 데이터를 가져와 연산작업을 한다. (다른 곳에 직접 접근 못함)
CPU가 아주 좋아도 REM이 작으면 처리 속도가 느림.
(쉐프가 한번에 처리할 수 있는 요리가 많아도 도마가 작으면 처리속도가 느리다. )
-
REM(주기억장치)
휘발성(전원이 공급되지 않으면 데이터가 사라짐)
(도마 -> 퇴근할때 생선을 도마 위에 두고 갈 수 없듯이)
-
HDD(보조기억장치)
자기적 신호로 메모리 저장 (반영구적)
-
메모리
-
메모리를 확대해 보면 칸칸이로 이루어져 있다.
-
메모리 한칸은 0 또는 1만 사용 가능하다.
-
메모리 공간은 효율적으로 사용하는 것이 좋다.
- 프로그램이 실행되고 있는 공간에 다른 프로그램을 실행 할 수 없다. (독점)
- 그러므로 다른 프로그램이 쓸 수있도록 여유 공간이 필요하다.
- 공간을 쓰다가 더이상 쓰지 않으면 반드시 제거해서 여유공간을 늘려주는 것이 좋다. (GC)
- 최소한의 데이터 공간을 사용하기 위해, 내가 취급하려고 하는 데이터가 어느정도의 범위에 해당하는 데이터인지 알고 있어야 한다.
-
-
메모리공간을 얼마나(몇칸이나) 사용할지 자유롭게 정하는 것 보단 -> 규칙을 정하자 ! (칸 수마다 이름을 정하자.) -> ex) 2칸 - apple, 8칸 - banana 라고 하자 -> 더 의사소통이 명확해짐
-
자바에서는 메모리 공간을 얻어갈때 길이와 용도를 패턴으로 만들어 두고 이름을 붙여놨다.(= 자료형)
-
GC (Garbage Collector)
운영환경이(= JVM)이 GC를 이용해 더이상 쓰지 않는 메모리 공간을 회수해 메모리 관리를 자동으로 처리해준다.
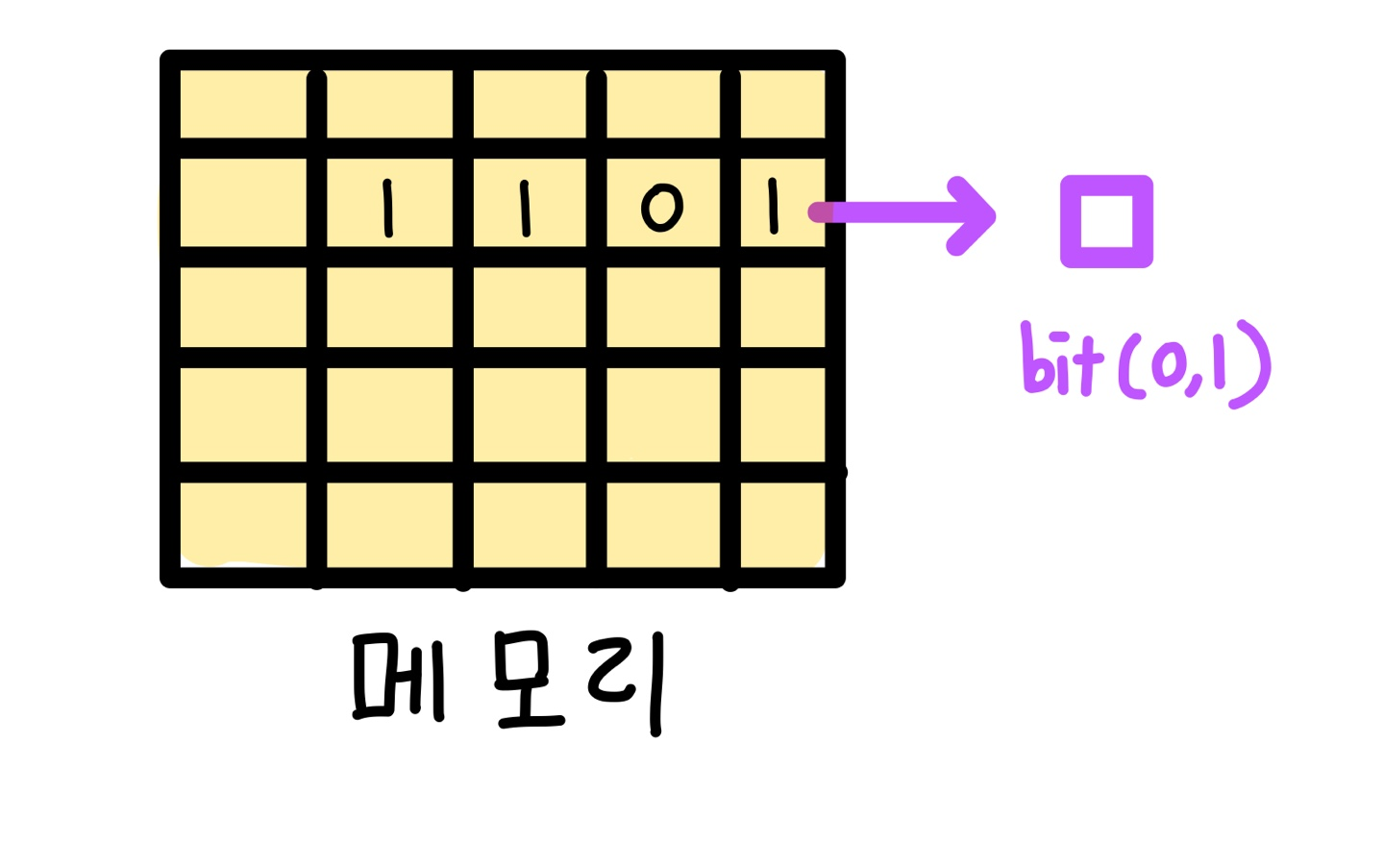
bit와 byte
-
1칸 = 1bit = 0 또는 1만 저장 가능
-
8bit = 1byte = byte = 8칸 사용한다.
-
bit는 너무 작은 단위라 써먹을 곳이 없어서, 8칸를 써서 byte라고 부르기로 함. (자바의 최소 단위)
-
byte : 2^8 =256가지(8칸으로 만들 수 있는 가지 수)의 상태를 표현 할 수 있는 저장 공간이다.
1byte = 숫자0부터 255까지를 저장할 수 있음(00000000~11111111) -> 양수

-
음수, 양수 표현 할때
-
부호비트 (0 - 음수, 1 - 양수 표현) + Data(값을 저장하는데 사용)
-
데이터 비트 -> 7bit로 표현 할 수있는 범위 -> 2^7 = 128 -> 0 ~ 127
-
음수와 양수를 포함해서 표현한다면 : -128 ~ 127 (0은 양수에서 표현)
-
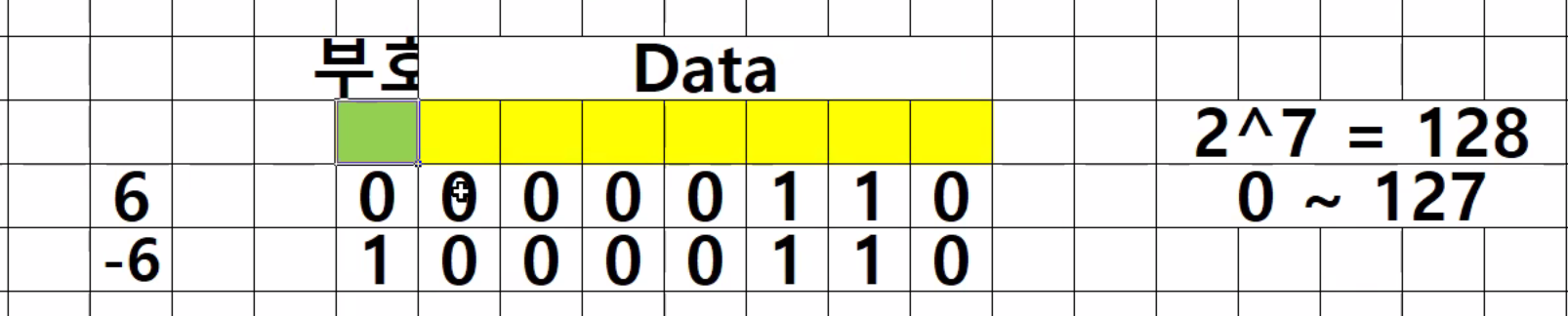
71p
-
실수형 - float , double
- 가수부의 크기로 값손실이 일어남.

-
char
- 문자코드표(어떤 문자가 가지는 숫자를 코드값으로 하기로 한다. )
- 아스키코드 (8bit) -> 256가지표현가능(영어대소문자+아라비안숫자+특수문자등) ->비영문권 표현 불가.
-
boolean
- 1byte
- true, false
성적처리 프로그램을 만들거야.
--> 데이터 : 학생 성적 -> 메모리 등록
데이터를 어떻게 메모리에 올릴까? -> 몇가지를 선택해야함
1) 내가 취급하려는 데이터를 선택
-> 국어점수
2) 데이터의 형태와 길이를 선택
-> 국어 점수의 형태 (숫자) 와 길이(0점~100점)를 정한다.
3) 자바의 자료형을 선택 (가장 효율적인 범위의 자료형 선택)
-> byte 선택 (-128 ~ 127)
4) 메모리에 3번의 자료형에 해당하는 공간 얻어오기
-> 변수를 사용
5) 얻은 공간에 데이터 입출력하기
-> System.out.println(변수);
정리
- 자료형 하나를 선택
- 자료형으로 공간을 하나얻음
- 공간에 원하는 데이터를 저장한 뒤
- 저장된 데이터 호출해서 화면에 출력
변수(Variable)
- 프로그램이 실행되다가 변수를 만나면 메모리에서 변수 타입 크기 만큼의 공간을 사용한다.
- 변수는 할당 받은 공간의 메모리 주소를 대신하는 역할을 한다.
- 변수를 생성(변수 선언)
- 변수를 생성하기 위해 자료형이 필요하다.
- 자료형 + 변수명;
- 문장(Statement) -> 명령어
- ; -> 문장 종결자
- 내가 점수를 저장할 메모리의 공간이 필요하기 때문에 타입을 정하고 변수 선언
byte kor;- = 대입연산자 (오른쪽의 데이터를 왼쪽의 공간에 넣어라)
- 변수값 대입하기, 할당하기 -> 변수 초기화 하기
- 얻어낸 공간에 데이터를 넣음
kor = 100;- 변수값 호출하기 -> 저장한 데이터 사용 -> 화면출력(println)
- 저장한 데이터를 화면에 출력하기 위해서 변수 사용
//System.out.println(변수);
//System.out.println(데이터);
System.out.println(kor);- 변수 - 선언과 초기화 동시에 하기 & 변수 표현 방법
-
변수 선언하기
byte eng; -
변수 초기화
eng =90;
//변수 선언하기
byte n1; //선언
n1 = 100; //초기화
//코드의 재사용성, 중복제거
//선언과 동시에 초기화
byte n2 = 120;
byte n3;
byte n4;
//중복제거 -> 한줄로 표현 가능
byte n5, n6, n7;
byte n8 = 10, n9 = 8, n10, n11; - 변수 사용하기
System.out.println(eng);
- 변수 치환하기(값을 덮어쓰기)
eng = 80;
- 상수와 리터럴
//똑같은 eng라는 표현을 출력했는데 90이 찍혔다가 80이 찍혔다.-> 변하는 수 -> 변수
System.out.println(eng);
//100 -> 상수(변하지 않는수) = 데이터 = 리터럴(Literal)
System.out.println(100);(Literal)
System.out.println(100);- 표현 방식에 따라 주석처리 하는 방법
//너비, 높이, 거리(한줄로 표현했을때 - 주석 불편)
byte width = 100, height = 50, distance = 70;
//이 방법이 가장 좋음(수정하기 용이, 주석 사용 용이)
byte width = 100; //너비
byte height = 50; //높이
byte distance = 70; //거리
byte width = 100, //너비
height = 50, //높이
distance = 70; //거리
-
변수의 특징
- 변수끼리 값을 복사 할 수있음
byte a = 10;
byte b;
b = 20;
//a 변수안의 데리터를 가져와서 b 변수에 복사해라(변수끼리 값을 복사할 수 있다.)
b = a;
System.out.println(b);
a = 5;
System.out.println(b); //복사된 다른 값은 영향을 받지 않는다.- 같은 이름을 가진 변수 두 개 사용 불가
//같은 이름을 가진 변수 두 개 사용 불가
//에러 메세지 : Duplicate local variable a (변수 a가 중복, 충돌)
byte a;
byte a; -> 에러
//어떤 변수 a를 사용해야 할지 알 수 없음.
a = 10; -> 에러
//자바는 대소문자를 구분한다.
//문법적으로 에러가 나지는 않지만 사용하지 말자..!
//수학점수(너가 말하는 메스는 어떤 걸 말하는 거니?..?)
byte math;
byte Math;
byte MaTh;
byte MatH;
byte MATH;
- 자바는 변수가 초기화되지 않은 상태에서 사용이 불가능 ```java byte size; //에러 메세지 : The local variable size may not have been initialized (로컬변수 size는 초기화 되지 않은 것 같아) System.out.println(size); -> 에러 ```
-
변수 명명법
- 영문자 + 숫자 + _ + $(가능은 하지만 안쓰는게 좋음) 조합
- 숫자로 시작 불가
- 예약어 사용 불가
- 의미있게 이름 붙일 것
//에러 메세지 : Syntax error on token "123", delete this token (변수 명은 123(숫자)로 시작 할 수 없어)
byte 123num; -> 에러
byte _123num;
//예약어 사용불가
// 컴파일러가 혼동이 될 수 있으므로
byte byte;
//국어점수 (이중에 뭐가 국어점수야..? -> 주석을 달아봤자 효율성이 떨어짐)
byte a1 = 100;
byte b1 = 200;
byte c1 = 300;
//어떤 의미인지 알 수 있게 이름을 정하자.
byte kor = 100;
byte eng = 200;
byte math = 300;
byte koreaScore = 100;
//이름 줄여서 사용 금지
byte ks = 100;
//변수명이 너무 길어
//ctrl + space(자동완성 기능)
//이클립스(Code Assistance), Visual Studio(인텔리센스))
//장점 : 오타 줄어줌, 구문 제공(암기가 줄어듦), 타이핑 속도 향상, 생산성 향상
System.out.println(koreaScore);식별자 명명법 패턴
많은 사람들이 오랜시간 동안 이름을 지음 -> 경험이 쌓임 -> 패턴이 만들어짐
- 헝가리언 표기법
- 파스칼표기법
- 캐멀 표기법
- 스네이크 표기법
- 케밥 표기법
-
헝가리언 표기법
- 식별자를 만들 때 식별자의 접두어로 해당 자료형을 표시하는 방법
- 변수만들때 말고 인터페이스 만들때 사용함. (interface IHello {})
byte num; //변수를 봤을때 어떤 타입인지 알 수 있음.
byte bnum;
byte b_num;
byte byte_num;
//변수에 마우스를 가져다 대면 무슨 타입인지 뜨기 때문에 헝가리언
표기법을 잘 안씀.
num = 110;-
파스칼표기법
- 식별자를 만들 때 식별자의 첫문자를 항상 대문자 표기 + 나머지 문자는 소문자로 표기
- 식별자가 2개 이상의 단어로 조합되면 각 단어의 첫문자는 항상 대문자로 표기 + 나머지 문자는 소문자로 표기
- 변수명 만들때 사용 안함, 주로 클래스 이름을 만들때 사용함.
//수학점수 -> math + score
byte mathscore; //어떤 단어가 합쳐졌는지 알기 어려움
byte math_score; // --> 스네이크 표기법
byte mathScore; // --> 캐멀 표기법
byte MathScore; // --> 파스칼 표기법