2021.05.18
ex16_update.sql
update문
-
DML(select, insert, update, delete)
-
원하는 행의 원하는 컬럼값을 수정하는 명령어
-
update 테이블명 set 컬럼명 = 수정할 값 [, 컬럼명 = 수정할 값] x N [where절]
-- 트랜잭션 처리
commit;
rollback;
select * from tblcountry;
-- 대한민국 수도 -> 서울 => 수도를 이전 -> 세종시
-- capital 컬럼값 바꾸기(특정한 행을 찾아서 업데이트하기(
update tblcountry set
capital = '세종시'; -- 모든 capital이 세종시로 바뀜..
update tblcountry set
capital = '세종시'
-- where area = 10; -- 보장x -> 겹치는 면적이 생길 수 있음
where name = '대한민국'; -- primary key 컬럼을 조건으로 지정하면 유일한 행을 검색할 수 있다.****-- 1년 후 > 인구증가 > 10%증가
-- 한국 4405 -> 4845.5
-- 중국 120660 -> 132726
update tblcountry set
population = population * 1.1;-- 'AS'에 속한 나라만 인구수 증가
update tblcountry set
population = population * 1.1
where continent = 'AS'; update tblcountry set
capital = '제주시',
area = area + 10,
population = population * 1.2
where name = '대한민국'; -- 절대 하면 안되는 행동!!!!! -> PK는 절대 수정하면 안된다!!!!!
select * from tblinsa;
update tblinsa set
num = 2000
where num = 1001;ex17_delete.sql
delete문
- DML
- 데이터를 삭제하는 명령어(레코드, 행)
- delete [from] 테이블명 [where절]
commit;
rollback;
select * from tblcountry;
delete from tblcountry;
-- 아시아에 속한 국가 삭제하기
delete from tblcountry where continent = 'AS';
delete from tblcountry where name = '대한민국';ex18_groupby.sql
group by절
-
레코드들을 특정 컬럼값(1개 or N개)에 맞춰서 그룹을 나누는 역할
-
그룹을 왜 나누는지?
- 각각의 나눠진 그룹 대상 -> 집계 함수를 적용하기 위해(*) -> count, sum, aug, max, min
-
group by 컬럼명 [, 컬럼명] x N
[WITH ]
SELECT column_list
FROM table_name
[WHERE search_condition][GROUP BY group_by_expression]
[HAVING serach_condition]ORDER BY order_expression [ASC|DESC]];
SELECT 컬럼리스트
FROM 테이블명
WHERE 조건
GROUP BY 그룹기준
ORDER BY 정렬;
★★★★ select를 구성하는 모든 절들은 실행 순서가 있다.(불변) -> 무조건 암기(이해) ★★★★
- FROM절
- WHERE절
- GROUP BY
- SELECT절
- ORDER BY절
group by를 사용한 select절에서 사용할 수 있는 표현
- 집계함수
- group by 한 컬럼(집합 데이터)
-- tblinsa. 부서별로 직원수가 몇명?
select count(*) from tblinsa; -- 총직원수
select distinct buseo from tblinsa; -- 부서
select count(*) from tblinsa where buseo = '총무부'; -- 7
select count(*) from tblinsa where buseo = '개발부'; -- 14
select count(*) from tblinsa where buseo = '영업부'; -- 16
select count(*) from tblinsa where buseo = '기획부'; -- 7
select count(*) from tblinsa where buseo = '인사부'; -- 4
select count(*) from tblinsa where buseo = '자재부'; -- 6
select count(*) from tblinsa where buseo = '홍보부'; -- 6
-- group by 적용
select buseo, count(*) from tblinsa group by buseo;
select
buseo as 부서명,
count(*) as 부서인원수,
round(avg(basicpay)) as 부서평균급여,
round(sum(basicpay)) as 부서급여총액
from tblinsa
group by buseo;-- 직위
-- ORA-00979: not a GROUP BY expression( GROUP BY 표현식이 아닙니다.)
select
jikwi, -- 집합데이터 (그룹기준)
-- name, -- 개인데이터
count(*) -- 집합데이터 (그룹기준)
from tblinsa
group by jikwi;-- 남자 직원수? 여자 직원수? -> 성별 그룹
select
-- ssn,
substr(ssn, 8, 1),
case
when substr(ssn, 8, 1) = '1' then '남자'
when substr(ssn, 8, 1) = '2' then '여자'
end as gender,
count(*)
from tblinsa
group by substr(ssn, 8, 1);-- 대륙별 국가수, 대륙별 인구수가 많은 나라의 인구수
select
continent,
count(*),
max(population)
from tblcountry
group by continent;-- 국가명이 PK라서 한그룹에 두개 이상 값이 있을 수 없음
select
name,
count(*)
from tblcountry
group by name;-- 성별마다 평균 몸무게, 평균키
select
gender,
round(avg(height),1),
round(avg(weight),1)
from tblcomedian
group by gender;-- 직업별 인원수
select
job,
count(*) -- 인원수
from tbladdressbook
group by job
-- order by job asc; -- 직업 가나다 순으로 정렬
order by count(*) desc; -- 인원수가 많은 순으로 정렬-- 시도 구군 동 번지
-- 서울특별시 동대문구 장안벚꽃로 267
select
-- substr(adreess,1,5) -- 자릿수 안맞음
-- instr(address, ' ') -- 첫번째 나오는 스페이스 위치
substr(address,1,instr(address,' ') -1), -- 첫번째자리에서 공백위치 바로 전까지 문자열 가져오기
count(*)
from tbladdressbook
group by substr(address,1,instr(address,' ') -1)
order by count(*) desc;having절
- 조건절
- group by에 대한 조건절 > 집계 결과를 대상으로 조건을 질문
where절
- 조건절
- from에 대한 조건절 > 레코드 하나하나를 대상 조건을 질문
SELECT 컬럼리스트
FROM 테이블명
WHERE 조건
GROUP BY 그룹기준
HAVING 조건
ORDER BY 정렬;
★★★★ select를 구성하는 모든 절들은 실행 순서가 있다.(불변) -> 무조건 암기(이해) ★★★★
- FROM절
- WHERE절
- GROUP BY
- HAVING절
- SELECT절
- ORDER BY절
A. from절 -> where절 : 개인(레코드 1개씩)에 대한 조건
-> 30명 중(from)에 키가 180 cm이상(where)인 사람(개인)B. group by절 -> having절 : 그룹에 (집계함수) 대한 조건
-> 사는 곳 그룹, 각각 count(*) (group by) -> 5명 이상 그룹만 (집계)
-- BUSEO COUNT(*)
-- --------------- ----------
-- 총무부 7
-- 개발부 14
-- 영업부 16
-- 기획부 7
-- 인사부 4
-- 자재부 6
-- 홍보부 6
select
buseo,
count(*) -- 부서별 사원수
from tblinsa
group by buseo; -- BUSEO COUNT(*)
-- --------------- ----------
-- 총무부 3
-- 개발부 4
-- 영업부 5
-- 기획부 2
-- 인사부 2
-- 자재부 2
-- 홍보부 1
select
buseo,
count(*) -- 구서별 200만원 이상 받는 사원수
from tblinsa -- 1. 사원수 60명
where basicpay > 2000000 -- 2. 200만원이하 받는 개인 탈락
group by buseo; -- 3. 200만원이상 받는 사람들만 그룹-- BUSEO COUNT(*)
-- --------------- ----------
-- 총무부 7
-- 영업부 16
-- 기획부 7
-- 인사부 4
select
buseo,
count(*)
from tblinsa -- 1. 60명
-- where basicpay > 2000000
group by buseo -- 2. 부서별 그룹
having avg(basicpay) > 1500000; -- 3. 각 부서의 평균 급여를 구함 > 평균 급여가 150만원많은 부서만 남음 (집단조건)-- BUSEO COUNT(*)
-- --------------- ----------
-- 기획부 2
select
buseo,
count(*)
from tblinsa -- 1. 60명
where basicpay > 2000000 -- 2. 급여가 200만원 넘는 개인 30명
group by buseo -- 3. 30명으로 그룹
-- having avg(basicpay) > 1500000; -- 4. 그룹에서 150만원 미만인 사람 (이미 개인이 200만원 이상이기 때문에 조건을 높여야함)
having avg(basicpay) > 2500000;문제
-- tblCountry. 대륙별로 최대 인구수, 최소 인구수, 평균 인구수 가져오시오.
select
max(population) as 최대인구수,
min(population) as 최소인구수,
avg(population) as 평균인구수
from tblCountry
group by continent;
-- hr.employees. 직업별(job_id) 직원수를 가져오시오.
select
job_id,
count(*)
from employees
group by job_id;
-- tblinsa. 부서별로 직원들의 급여 총합, 부서인원수, 최고급여액, 최저급여액 가져오시오.
select
buseo,
sum(basicpay),
count(*),
max(basicpay),
min(basicpay)
from tblInsa
group by buseo;
-- tblAddressbook. 고향별(hometown) 인원수를 가져오시오. 정렬(인원수 내림차순)
select
hometown,
count(*)
from tblAddressbook
group by hometown;-- tblinsa. 부서별 직급의 인원수 가져오시오. group by + decode
select
buseo as 부서,
count(*) as 인원,
count(decode(jikwi, '부장', 1)) as 부장, -- 부장이면 1, 부장이 아니면 0 -> count로 세면 인원이 나옴
count(decode(jikwi, '과장', 1)) as 과장,
count(decode(jikwi, '대리', 1)) as 대리,
count(decode(jikwi, '사원', 1)) as 사원
from tblInsa
group by buseo;
-- 부서와 직급을 그룹으로 묶기
-- 개발부 과장 2
-- 개발부 대리 2
-- 개발부 부장 1
-- 개발부 사원 9
select
buseo,
jikwi,
count(*)
from tblinsa
group by buseo, jikwi -- 다중그룹
order by buseo,jikwi;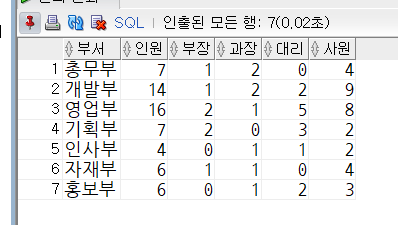

-- 부서별 남녀 인원수?
-- 다중 그룹
select
buseo,
substr(ssn, 8, 1),
count(*)
from tblinsa
group by buseo, substr(ssn, 8, 1)
order by buseo, substr(ssn, 8, 1); 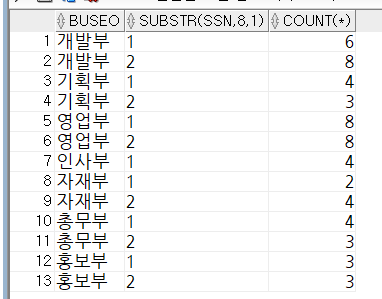
rollup()
- group by에서 사용
- group by의 결과에서 집계결과를 더 자세하게 반환한다.(summary, 요약)
select
buseo,
count(*),
sum(basicpay),
round(avg(basicpay))
from tblInsa
group by rollup(buseo);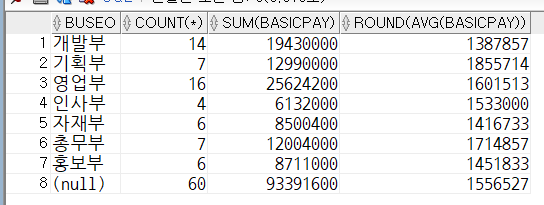
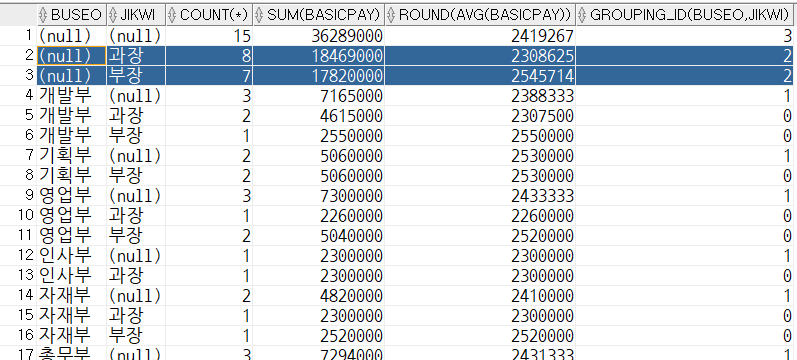
select
buseo,
jikwi,
count(*),
sum(basicpay),
round(avg(basicpay)),
grouping_id(buseo, jikwi) -- 0(일반행), 1(소계행), 3(총계행) : 레코드가 무슨 성질을 가지고 있는지 구분할 수 있는값
from tblInsa
group by rollup(buseo, jikwi);- 1차 그룹에 대한 결과(중간정산) (개발부, 기획부,,,) -> 모든 대상에 대한 결과(총정산)
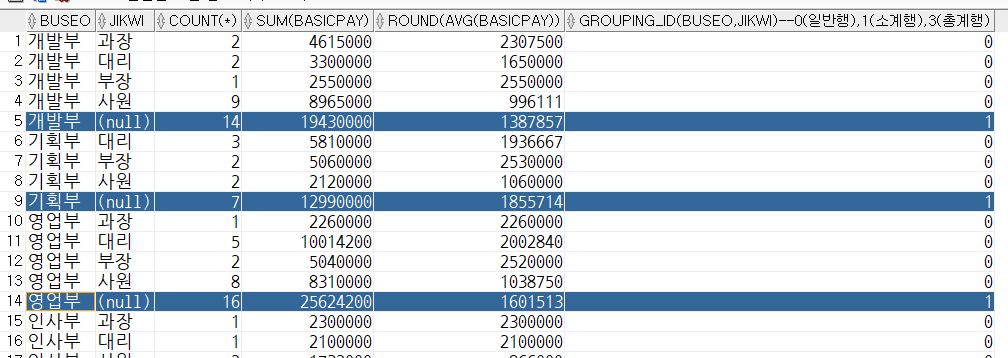
-- cube
select
buseo,
jikwi,
count(*),
sum(basicpay),
round(avg(basicpay)),
grouping_id(buseo, jikwi)
from tblInsa
where jikwi in ('부장','과장')
group by cube(buseo, jikwi);-
1차소계 : rollup() -> 그룹에 상하관계가 있다고 생각
-
1차소계, 2차소계 : cube() -> 그룹이 동등관계라고 생각
ex19_subquery.sql
메인 쿼리, Main Query
- 하나의 select(insert, update, delete)로만 구성된 쿼리
서브 쿼리
- 하나의 문장에 2개 이상의 select를 추가해서 구성된 쿼리
- 하나의 쿼리 안에 또다른 쿼리가 들어있는 형태
- 삽입 위치: select절, from절, where절, order by절 등...
select + select x N
insert + select x N
update + select x N
delete + select x N
-- tblcontry. 인구수가 가장 많은 나라의 인구수는? -> 그 나라는?
select max(population) from tblcountry; -- 120660
select name from tblcountry where population = 120660;
-- ORA-00934: group function is not allowed here(그룹함수는 허가되지 않습니다.)
-- select name from tblcountry where population = max(population); -> 에러 -> name : 개인데이터, max(population) : 그룹함수
-- (select max(population) from tblcountry) => 서브쿼리
-- 장점 : 작업(실행해야하는 문장 횟수)을 단축시킬 수 있다.
select name from tblcountry where population = (select max(population) from tblcountry); -- 중국-- tblinsa. 급여가 가장 많은 사람의 이름?
select max(basicpay) from tblinsa; -- 2650000
select name from tblinsa where basicpay = 2650000; -- 허경운
select name from tblinsa where basicpay = (select max(basicpay) from tblinsa);-- tblinsa. 평균급여보다 많이 받는 직원들?
select avg(basicpay) from tblinsa; -- 1556526
select * from tblinsa where basicpay > 1556526;
select * from tblinsa where basicpay > (select avg(basicpay) from tblinsa);-- tblinsa. '홍길동'과 같은 부서에 근무하는 사람들?
select buseo from tblinsa where name = '홍길동';
select * from tblinsa where buseo = '기획부';
select * from tblinsa where buseo = (select buseo from tblinsa where name = '홍길동')and name <> '홍길동'; -- '홍길동'은 제외서브쿼리의 용도 ★★★★★★
-
조건절(where, having) 비교값으로 사용
a. 반환값이 1행 1열 > 단일값, 값 1개 > 데이터가 필요한 곳에 모두 사용 가능 > 스칼라 쿼리(1행 1열) > 연산자 사용
b. 반환값이 N행 1열 > 다중값, 값 N개 > in 사용(열거형 비교)
c. 반환값이 1행 N열 > 복합값, 값 N개 > 연산자 사용(N : N)
d. 반환값이 N행 N열 > b + c > b와 c방식을 혼합해서 사용
- 1-a
-- 최대 급여를 가지는 사람
select
*
from tblinsa
where basicpay = (select max(basicpay) from tblinsa); -- 2650000
-- (select max(basicpay) from tblinsa) 자체를 데이터로 봐도 무방하다.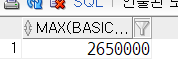
- 1-b
-- 급여가 260만원 이상 받는 사람들이 근무하는 부서의 명단? (급여가 260만원 이상 받는 사람들이/ 근무하는 부서의 명단(우리나라 문장 특성상 뒤의 문장이 메인쿼리, 앞이 서브 쿼리일 확률이 높다.))
select
*
from tblinsa
where buseo in (select buseo from tblinsa where basicpay >= 2600000); -- 기획부, 총무부 (같은 컬럼값이 여러 행으로 나올땐 in을 사용)
-- where buseo in ('기획부', '총무부');
-- 기획부 대리와 같은 지역에 사는 사람들?
select city from tblInsa where buseo = '기획부' and jikwi = '대리'; -- 전남, 서울, 인천
select * from tblInsa where city in ('서울', '인천', '전남');
select * from tblInsa where city in (select city from tblInsa where buseo = '기획부' and jikwi = '대리'); - 1-c
-- '홍길동'이 사는 지역과 같은 지역에 살고, 같은 직위를 가지는 직원?
select city, jikwi from tblInsa where name = '홍길동'; -- 서울, 부장
select * from tblInsa where city = '서울' and jikwi = '부장';
-- 2:2 -> N:N 비교
select * from tblInsa where (city, jikwi) = (select city, jikwi from tblInsa where name = '홍길동');
- 1-d
-- 급여를 2600000원 이상 받는 직원의 부서와 사는 곳이 동일한 직원들?
select buseo, city from tblInsa where basicpay >= 2600000;
select * from tblInsa
where (buseo, city) in (select buseo, city from tblInsa where basicpay >= 2600000);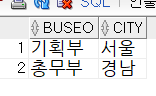
서브쿼리의 용도
-
컬럼리스트에서 사용
a. 반환값이 1행 1열 > 스칼라 쿼리
- 정적 쿼리 (모든 행에 동일한 값을 반환)
- 상관 서브 쿼리 (서브 쿼리의 값과 바깥쪽 메인 쿼리의 값을 연계시켜 값을 반환) ★★★★★★★★★★
select
name,
basicpay,
-- avg(basicpay), -- ORA-00936: missing expression (집계함수는 일반 컬럼과 동시에 사용 불가)
from tblinsa;- 정적쿼리 - 레코드에 상관없이 값이 똑같음
select
name,
basicpay,
-- (select 100 from dual),
-- 100,
-- 집계함수를 바로 넣으면 에러가 나지만, 서브쿼리로 데이터를 먼저 추출하면 상수라고 생각한다.
(select round(avg(basicpay)) from tblinsa) -- 1556527, 회사의 평균급여
from tblinsa;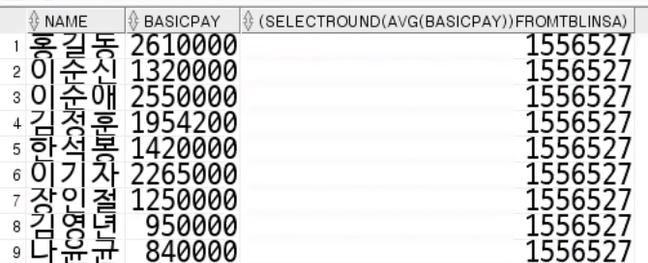
select
name, -- 개인정보
buseo, -- 개인정보
(select round(avg(basicpay)) from tblinsa) as 평균급여, -- 집합 정보
-- (select jikwi from tblinda where name = '홍길동') -- 단일값, 나머지 컬럼과 관계있는 서브 쿼리만 사용할 것(연관없는 데이터는 쓰지 말 것..)
from tblinsa;- 상관 서브 쿼리 - 레코드마다 값이 다름
select * from tblMen;
select * from tblWomen;
-- 남자이름, 남자키, 여자이름, 여자키
select
name as 남자이름,
height as 남자키,
couple as 여자이름,
(select height from tblWomen where name = '장도연') as 여자키 -- 여자테이블의 height
from tblMen
where name = '홍길동';
-- 조건 변경-> 홍길동(x), 모든 커플
select
name as 남자이름,
height as 남자키,
couple as 여자이름,
(select height from tblWomen where name = tblMen.couple) as 여자키 -- tblMen.couple : 남자테이블 소유의 컬럼 -> 상관서브 쿼리
from tblMen
-- where name = '홍길동';
where couple is not null; -- 커플의 컬럼 값에 이름이 적혀있으면 커플, 없으면 솔로(null)select * from employees; -- 직원
select * from departments; -- 부서
-- 직원의 이름과 부서명을 가져오시오.
select
first_name || ' ' || last_name as name,
-- department_id, -- 부서 식별자
(select department_name from departments where department_id = employees.department_id) as department -- 부서명
from employees;