2021.05.21
ex21_view.sql
뷰, View
-
DB Object중 하나(테이블, 시퀀스, 제약사항, 뷰) -> 데이터 베이스에 영구 저장
-
가상 테이블, 뷰 테이블
-
일종의 테이블의 복사본
-
뷰는 테이블처럼 취급한다.
-
자주 사용하는 select의 결과를 저장하는 객체(★★★★)
-
테이블을 직접 사용하는 것에 비해 간편함(구문 단축)
-
뷰는 읽기 전용이다.(★★★)
-
뷰는 select의 결과를 저장하는 객체(X) -> select문을 저장하는 객체(O)(★★★★★★)
create view 뷰이름
as
select문뷰의 분류
- 단순 뷰
- 하나의 기본 테이블을 사용해서 만든 뷰
- CRUD 가능O -> R만 사용할 것
- 복합뷰
- 두개 이상의 기본 테이블을 사용해서 만든 뷰(Subquery, join, union..)
- R만 가능
-- 뷰 생성
-- ORA-00955: name is already used by an existing object 동일한 이름을 가진 객체를 만들 수 없다.
create view vwInsa
as
select * from tblInsa;
select * from tblinsa; -- 테이블보기
select * from vwinsa; -- 뷰보기
select * from tblinsa where buseo = '기획부';
select * from vwinsa where buseo = '개발부';
drop view vwinsa;-- create or : 없으면 만들고, 있으면 수정(대체, 기존것을 없애고 새로 만듦)
create or replace view vwinsa
as
select * from tblinsa where buseo = '기획부';
-- vwInsa : 기획부 직원 테이블
select * from vwinsa;
create or replace view vwInsaMaleSeoul
as
select * from tblinsa where substr(ssn, 8,1) = '1' and city = '서울';
select * from vwInsaMaleSeoul;
-- system계정으로 변경 후 실행하면 에러남.
-- ORA-00942: table or view does not exist
-- 관리자 계정은 모든 다른 계정의 자원을 접근할 수 있음.(앞에 소유주를 써주면 된다.)
select * from hr.tblinsa;
select * from hr.vwInsaMaleSeoul;create or replace view vwvideo
as
select
m.name as "회원명",
v.name as "비디오제목",
r.rentdate as "대여날짜",
case
when r.retdate is null then '반납안함'
when r.retdate is not null then '반납완료'
end as "반납상태"
from tblgenre g
inner join tblvideo v
on g.seq = v.genre
inner join tblrent r
on v.seq = r.video
inner join tblmember m
on m.seq = r.member;
select * from vwvideo;
-- 불가능한 행동(복합뷰)
-- insert into vwvideo(회원명, 비디오제목, 대여날짜, 반납상태) values ('홍길동', '해리포터','2021-05-21', null);
-- delete from vwvideo where 조건;-- 서울 직원 뷰
-- 홍길동 -> 서울
create or replace view vwSeoul
as
select * from tblinsa where city = '서울';
select * from vwSeoul;
commit;
rollback;
select * from tblInsa;
-- 홍길동 -> 제주
update tblInsa set city = '제주' where num = 1001;
-- 홍길동이 없음... -> 테이블을 건드렸더니 뷰에도 영향을 미침.
select * from vwSeoul;
-- 서울 직원 삭제
delete from tblInsa where city = '서울';
-- 서울 직원이 다 삭제됨..
select * from vwSeoul;
-- 뷰는 select문을 저장하는 객체이다!!!뷰 사용시 주의할 점
- 뷰는 절대로 읽기 전용으로 사용한다.
- 뷰로 insert, update, delete 작업은 금지한다. -> 테이블로 할 것!!
commit;
rollback;
create or replace view vwMen
as
select * from tblMen;
-- 1. select
select * from vwMen;
-- 2. insert
insert into (name, age, height, weight, couple) values ('테스트', 20,175, 65, null);
-- 3. update
update vwMen set age = 25 where name = '테스트';
-- 4. delete
delete from vwMen where name = '테스트';
-- 이름만 가지고 insert, update, delete 쓸 수 있는 뷰(복합뷰,단순뷰)인지 아닌지 혼동이 된다.
-- vwInsa
-- vwInsaSeoul
-- vwMen
-- vwContry인라인뷰
-- 인라인 뷰, Inline view
create or replace view vwSeoul
as
select * from tblInsa where city = '서울';
select * from vwSeoul; -- 재사용 가능
-- 서브쿼리를 from절에 사용 == 인라인뷰
select * from (select * from tblInsa where city = '서울'); -- 1회성ex22_union.sql
join
- 테이블을 합치는 기술
- 횡(가로) : 컬럼과 컬럼을 더하는 작업
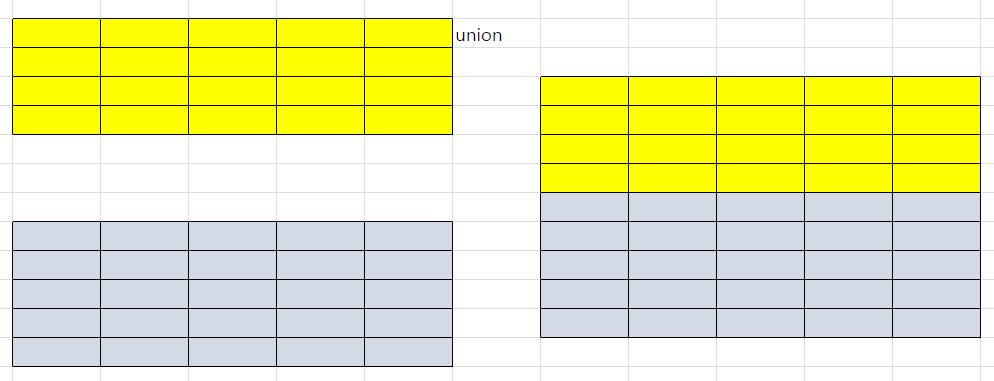
Union
- union, union all, intersect, minus
- 테이블을 합치는 기술
- 종(세로) : 테이블의 레코드와 다른 테이블의 레코드를 더하는 작업
- 수학 집합 개념 지원(합집합, 교집합, 차집합..)
select * from tblMen;
select * from tblWomen;
select * from tblMen m
inner join tblWomen w
on m.couple = w.name;
-- 데이터베이스 연산
-- union
-- 1. 컬럼의 개수가 일치해야한다.
-- 2. 컬럼의 타입이 일치해야한다.
-- 1,2가 불일치하면 union 실패
select * from tblMen
union -- (+)
select * from tblWomen;-- 유니온의 성질
create table tblUnionA(
color varchar2(30) not null
);
create table tblUnionB(
color varchar2(30) not null
);
insert into tblUnionA values ('red');
insert into tblUnionA values ('yellow');
insert into tblUnionA values ('blue');
insert into tblUnionA values ('black');
insert into tblUnionA values ('white');
insert into tblUnionB values ('orange');
insert into tblUnionB values ('green');
insert into tblUnionB values ('skyblue');
insert into tblUnionB values ('yellow');
insert into tblUnionB values ('red');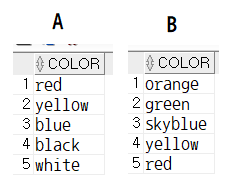
-- union : 두 테이블을 합쳤을 때 중복되는 행을 자동으로 제거 *****
select * from tblUnionA
union
select * from tblUnionB;
-- union all : 두 테이블을 합쳤을 때 중복되는 행을 그대로 포함
select * from tblUnionA
union all
select * from tblUnionB;
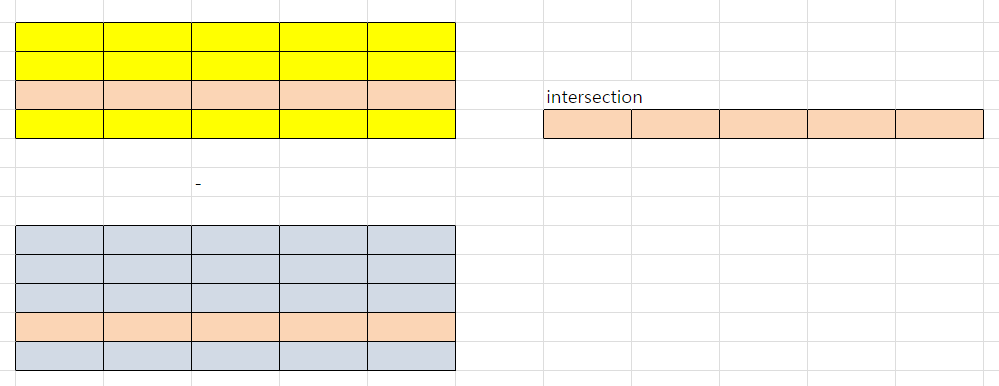
-- intersect : 두 테이블을 합쳤을 때 중복되는 행만 포함(교집합)
select * from tblUnionA
intersect
select * from tblUnionB;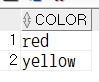
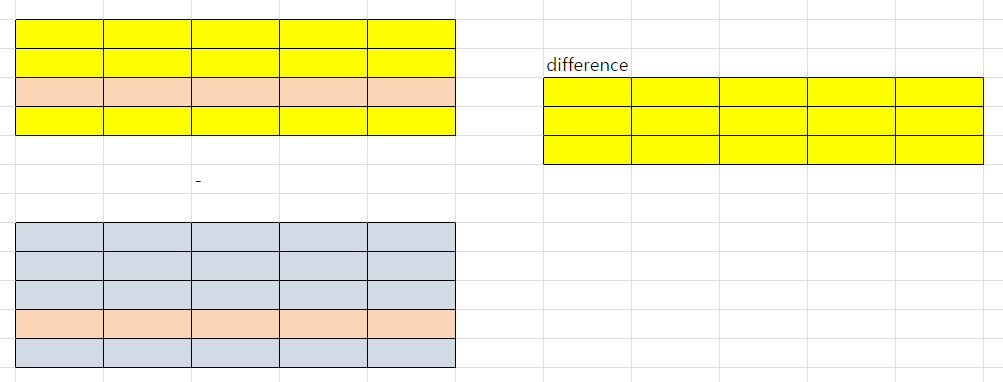
-- minus : A - B
select * from tblUnionA
minus
select * from tblUnionB;

- select : 원하는 행만 추출
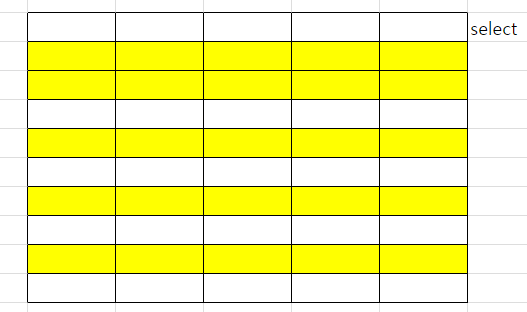
- project : 원하는 컬럼만 추출
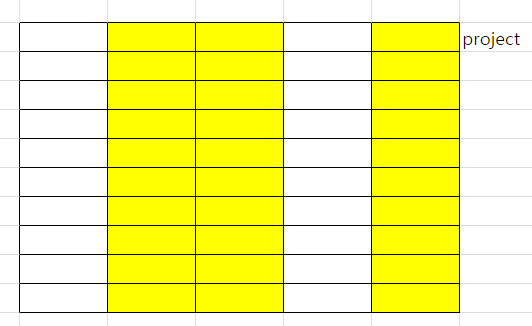
- union : 독립된 두 테이블을 세로로 합치는 행동
- difference : A-B (차집합)
- intersection : 교집합
ex23_pseudo.sql
Pseudo Column, 의사 컬럼
- 실제 컬럼이 아닌데 컬럼처럼 행동하는 객체
rownum
- 오라클 전용, Ms-SQL(top),mySQL(limit)
- 행번호를 반환하는 컬럼
- 서브 쿼리에 많이 의존(인라인 뷰)
- rownum은 주로 from절이 호출될때 같이 실행된다.(★★★★★)
- 게시판 페이지번호에 사용된다.
-- 에러 : 와일드카드(*)와 다른 컬럼(표현식 등)은 목록으로 연결될 수 없다.
-- select *, sysdate from tblcountry;
select c.*, sysdate from tblcountry c;
-- 질문의 조건에 1행이 포함되면 결과O, 포함안되면 결과X
select c.*, rownum from tblcountry c;
select c.*, rownum from tblcountry c where rownum = 1;
select c.*, rownum from tblcountry c where rownum <= 5;
select c.*, rownum from tblcountry c where rownum = 5; -- x
select c.*, rownum from tblcountry c where rownum >= 3 and rownum <= 7; -- x-- 급여를 많이 받는 순으로 1~10등까지 가져오기
select -- 2.
name,
basicpay,
rownum
from tblInsa -- 1. 60명 + rownum할당
order by basicpay desc; -- 3. rownum 이미 1번에 할당이 끝났다.-- 인라인 뷰(from절 서브쿼리)
select name, basicpay, rnum, rownum from (select name, basicpay, rownum as rnum from tblInsa order by basicpay desc);
select name, basicpay, rownum from (select name, basicpay from tblInsa order by basicpay desc) where rownum <= 10;
select name, basicpay, rownum from (select name, basicpay from tblInsa order by basicpay desc) where rownum = 1; -- 급여순위 1등
-- select name, basicpay, rownum from (select name, basicpay from tblInsa order by basicpay desc) where rownum >=3 and rownum <= 5;
-- 급여 순위 3~5등
-- rnum : 가운데 쿼리의 rownum : 정적인 번호
-- rownum : 바깥쪽 쿼리의 rownum : 동적인 번호
select name, basicpay, rnum from (select name, basicpay, rownum as rnum from (select name, basicpay from tblInsa order by basicpay desc))
where rnum between 3 and 5;-- basicpay + sudang -> 급여 순위
-- 정리. 이 2가지 경우만 이해하면 끝!!!
-- Case A.
select name, salary, rownum from (select name, basicpay + sudang as salary from tblInsa order by basicpay + sudang desc)
where rownum <= 3;
-- Case B.
select * from (select name, salary, rownum as rnum from (select name, basicpay + sudang as salary from tblInsa order by basicpay + sudang desc))
where rnum >= 5 and rnum <= 10;-- 지역별(hometown) 거주자가 몇명? -> 지역별 거주자가 많은 순위 1~3
select hometown, cnt, rownum from (select
hometown,
count(*) as cnt
-- rownum -> 개인정보
from tbladdressbook
group by hometown
order by count(*) desc)
where rownum <= 3;
-- 5위
select * from (select hometown, cnt, rownum as rnum from (select
hometown,
count(*) as cnt
-- rownum -> 개인정보
from tbladdressbook
group by hometown
order by count(*) desc))
where rnum = 5;-- tblAddressBook. 직업별 인원수 -> 순위 1~10등, 11~20등
select * from (select a.*, rownum as rnum from (select job, count(*) as cnt from tblAddressBook group by job order by count(*) desc) a);
select * from (select a.*, rownum as rnum from (select job, count(*) as cnt from tblAddressBook group by job order by count(*) desc) a)
where rnum between 1 and 10;
select * from (select a.*, rownum as rnum from (select job, count(*) as cnt from tblAddressBook group by job order by count(*) desc) a)
where rnum between 11 and 20;ex24_hierarchical.sql
Hierarchical Query, 계층형 쿼리
- 오라클 전용
- 레코드간의 관계가 서로 상하 수직 구조인 경우 적당한 구조의 결과셋을 만들어 주는 역할
- 한 테이블에 부모, 자식 레코드가 동시에 있는 경우 > 자기 참조 테이블
- 조직도, 답변형 게시판, BOM(자제명세서)
컴퓨터
- 본체
- 메인보드
- 그래픽카드
- 랜카드
- CPU
- 메모리
- 모니터
- 보호필름
- 프린터
- 잉크카트리지
- A4용지create table tblComputer (
seq number primary key, -- 식별자(PK)
name varchar2(50) not null, -- 요소명
qty number not null, -- 수량
pseq number null references tblComputer -- 부모 부품(FK)
);
insert into tblComputer values (1, '컴퓨터', 1, null); -- 루트(root)
insert into tblComputer values (2, '본체', 1, 1);
insert into tblComputer values (3, '모니터', 1, 1);
insert into tblComputer values (4, '프린터', 1, 1);
insert into tblComputer values (5, '메인보드', 1, 2);
insert into tblComputer values (6, '그래픽카드', 1, 2);
insert into tblComputer values (7, '랜카드', 1, 2);
insert into tblComputer values (8, 'CPU', 1, 2);
insert into tblComputer values (9, '메모리', 1, 2);
insert into tblComputer values (10, '보호필름', 1, 3);
insert into tblComputer values (11, '잉크카트리지', 1, 4);
insert into tblComputer values (12, 'A4용지', 100, 4);
select * from tblComputer;-- 셀프조인: 부품 + 부모부품
select
c1.name as "부품",
c2.name as "부모부품"
from tblComputer c1
inner join tblComputer c2
on c1.pseq = c2.seq;
select
c1.name as "부품",
c2.name as "부모부품"
from tblComputer c1
left outer join tblComputer c2
on c1.pseq = c2.seq;/*
계층형 쿼리
- start with절 + connect by절
- 계층형 쿼리에서만 사용 가능한 의사 컬럼을 제공
- prior : 의사컬럼. 가상 부모 레코드
- level : 의사컬럼. N세대, (누가 상위요소인지 하위요소인지 알 수 있음, 계층구조)
- start with : 최상위 요소를 어떤 걸로 시작할 지 정함
*/
select
lpad(' ', (level -1) * 5) || name,
prior name,
level
from tblComputer
-- start with seq = 1
-- start with seq = (select seq from tblComputer where name = '컴퓨터')
start with pseq is null
connect by prior seq = pseq; -- 부모 자식을 연결시켜주는 연결고리
select
lpad(' ',(level - 1) * 2) || name as 직원명,
-- prior name as 상사명
department
from tblself
start with super is null
connect by super = prior seq;
-- prior : 부모 레코드
-- connect_by_root : 최상위 레코드
select
lpad(' ', (level -1) * 5) || name,
prior name,
level,
connect_by_root name as "루트부품명",
connect_by_isleaf as "리프노드", -- 최말단 노드인지 알려줌
sys_connect_by_path(name,'->')
from tblComputer
start with pseq is null
connect by prior seq = pseq
-- order by name asc -- 일반 정렬 사용 불가
order siblings by name asc; -- 형제끼리만 정렬
모르면 괴롭고 알면 즐겁다.