
temperature:
- 각 토큰의 의미를 모델이 이해하는 최종과정에서 추론 확률 분포를 조절하는 파라미터.
- 예시) "It is mine." 이라는 문장에서 It 이라는 토큰에 대해 모델이 아래 확률분포로 예상 후보들을 추론할 수 있음.
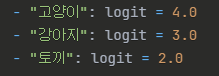
이후 최종적으로 It 토큰의 의미를 결정(추론)하는 과정에서 temperature 값을 사용함.
temparature값의 변화에 따른 모델의 추론결과는 아래와 같음.
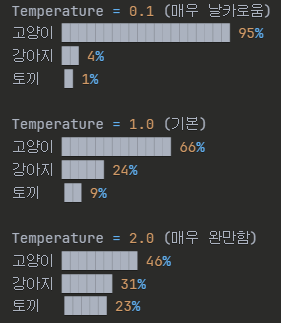
- 값이 높을수록 모델은 주어진 입력을 확장해서 이해하려고 노력함. 따라서 OCR task와 같이 입력(문서)를 그대로 이해해야 하는 상황에서는 매우 낮은 값을 줘야함.
repetition_penalty:
- 생성된 각 토큰의 확률분포 중 최대값을 가지는 값을 나눗셈으로 낮춰서 반복을 억제하는 파라미터.
- 가장 큰 확률을 가지는 값(의미)의 확률을 낮춤으로써 확률분포 정규화 시 1순위와 2순위의 확률 격차가 줄어듬. 결국 2순위 값의 영향력이 강해짐에 따라 1위 토큰의 반복 확률이 점점 낮아짐.

- 이 파라미터를 이용하면 OCR수행 시 한셀만 무한 반복해서 출력하는 문제를 해결할 수 있음
frequency_penalty:
- 동일한 토큰 등장에 대해 [등장횟수 비례] 패널티 부여.
- 패널티가 높을수록 자율성↑. why? 동일한 토큰 사용에 제약이 걸림에 따라 유사 토큰(≒동의어)를 사용해야하기 때문.

presence_penalty:
- frequency_penalty와 99% 동일함. 차이점은 동일한 토큰 등장에 대해 [상수] 패널티를 부여한다는것.
Min-p (Minimum Probability):
- 토큰의 확률분포를 결정하는 값. Threshold의 역할을 수행.
- 각 토큰이 가지는 확률 분포에서 최대 값 × Min-p 값보다 큰 값들만 남김.
- 예시) It 이라는 토큰의 의미 확률분포가 [고양이: 0.6, 강아지: 0.3, 토끼: 0.1] 일 때 Min-p가 0.2라면?
-> 0.6 × 0.2 = 0.12 의 값이 threshold가 되고 이 값보다 큰 값들만 채택함.
따라서 It 토큰의 의미확률분포는 = [고양이: 0.6, 강아지: 0.3]가 되고 정규화를 통해 최종 확률분포는 [고양이: 0.75, 강아지: 0.25]와 같이 합이 1.0이 되도록 조정됨.
[매우중요] 모델 추론 시 각 패널티 및 파라미터들이 적용되는 시점 시각화

