
다양한 언어의 포스터의 내용을 → 영어로 번역하는 솔루션
아래는 솔루션 전체 플로우차트▼
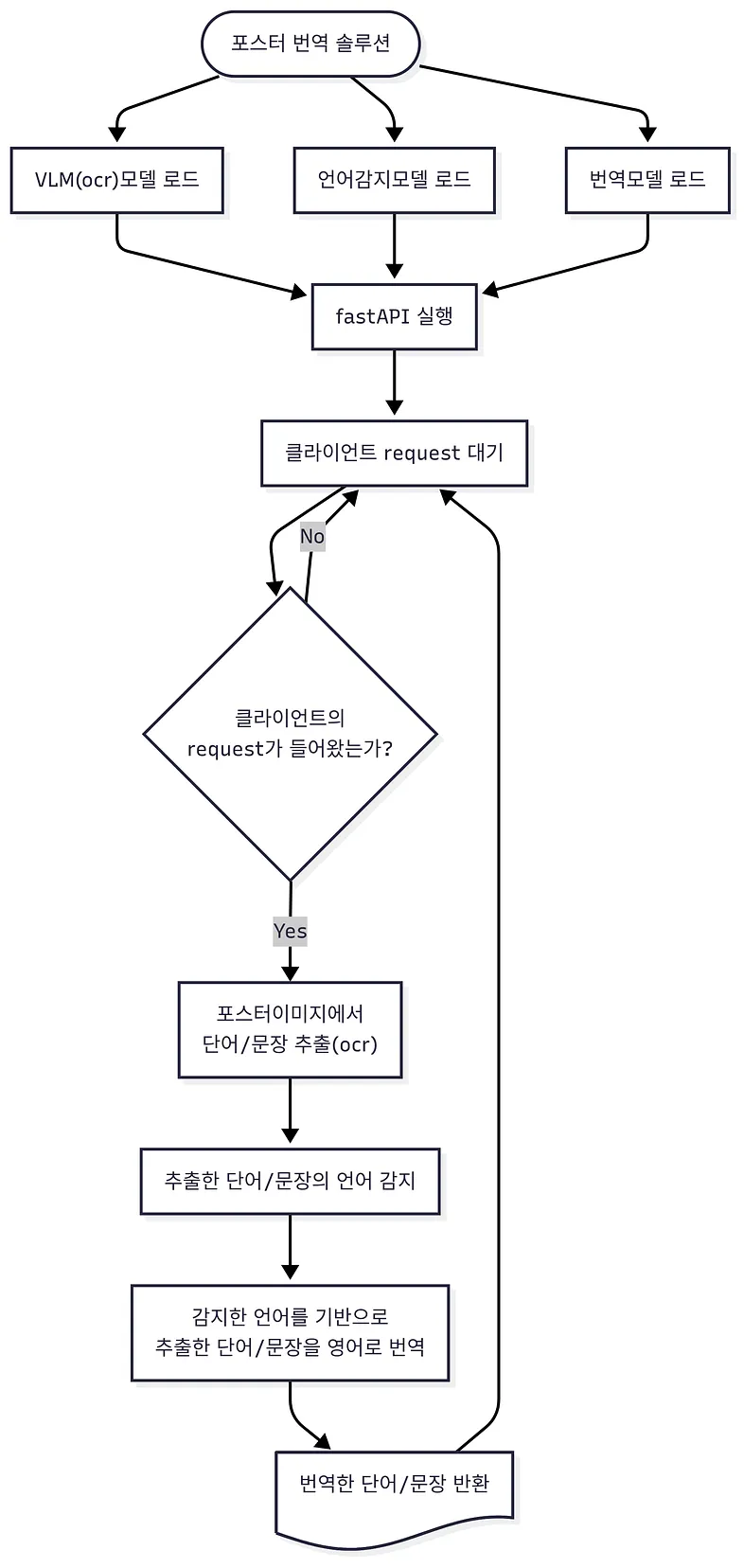
1. 솔루션을 위한 필수환경
- 쿠다 12.8지원하는 드라이버 ( 525 <= x < 580)
- GPU메모리 12GB 이상
- 70GB의 여유공간 (이미지 : 18GB + 컨테이너 50GB)
2. 사용 모델 및 기술
- NanoNets-OCR-s (OCR)
- fastText (언어감지)
- m2m100_418M (번역)
- fastAPI(배포 및 사용)
3. 도커컴포즈파일.yaml ▼
name: ${PROJECT_NAME}
services:
MY_APP:
image: aptr:v1
container_name: ${CONTAINER_NAME:-aptr_container}
ports:
- "${PORT}:${PORT}"
command: bash -li -c "RUN_API ${PORT} && exec bash"
environment:
- PORT=${PORT}
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
healthcheck:
test: ["CMD", "curl", "-f", "http://127.0.0.1:${PORT}/"]
interval: 30s
timeout: 300s
retries: 3
start_period: 60s
shm_size: 1gb
stdin_open: true
tty: true
restart: unless-stopped4. 도커컴포즈env파일.env ▼
PROJECT_NAME='MyProject' #반드시 따옴표 안에서 작성
CONTAINER_NAME='my_container' #반드시 따옴표 안에서 작성
PORT=87875. 클라이언트 API호출 예제 ▼
import base64
import requests
if __name__ == "__main__":
with open("./sample_poster_image.jpg", "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
# 서버에 보낼 데이터 구성
data = {
"image": encoded_string
}
# JSON형태로 POST 요청 (내부에서 utf-8로 인코딩하여 전송)
url = "http://127.0.0.1:8787/translate“
response = requests.post(url, json=data)
print(response.status_code)
print(response.text)개발시 고려한 사항
A. 도커이미지 최적화
도커이미지는 nvidia/cuda 도커이미지를 기반으로 만들었음. 도커이미지 제작시 컨테이너의 크기를 최소화 하기 위해 컨테이너 내에서 수십줄의 명령어를 &&으로 이어 단 한번의 명령어로 만들어 크기를 최적화 했음. 최적화 전후 용량차이는 약 3GB 차이. 아래는 실제 사용한 bash명령어. 환경함수 등록까지 모두 bash에서 처리함▼
apt update && \
apt install -y wget git python3.10 pip nano curl && \
pip install --no-cache-dir torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128 && \
pip install transformers==4.52.4 accelerate==1.10.1 packaging==25.0 && \
pip install fasttext==0.9.3 sentencepiece==0.2.1 fastapi==0.116.2 && \
pip install "uvicorn[standard]"==0.35.0 flash-attn==2.8.3 --no-build-isolation pyarmor==7.7.4 && \
cat >> ~/.bashrc << 'EOF' &&
function RUN_API(){
local port_num="$1"
#cd /workspace/APTr-v1 || return
python3 /workspace/APTr-v1/app.py "$port_num"
}
EOF
source ~/.bashrc && \
apt clean && \
apt autoremove -y && \
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/* && \
rm -rf ~/.cache/pip/* /tmp/* /var/log/* &&
find /usr -name "*.pyc" -delete && find /usr -name "__pycache__" -type d -exec rm -rf {} + && \
history -c && > ~/.bash_historyB. 코드 및 디렉토리 암호화(난독화)
파이선 기반의 솔루션 중 가장 강력한 암호화 패키지인 pyArmor를 이용. 디렉토리와 모델 암호화는 직접 변수를 수정해가며 수행하였음. 아래는 암호화 된 인퍼런스 코드의 일부▼

C. 여러 OCR모델 빌드 및 테스트
고객의 컴퓨팅 환경이 그리 좋지 못하였기에 12GB이하의 GPU에서도 원활하게 돌아갈 수 있는 성능 좋은 모델을 찾는데 많은 시간을 사용함. 특히 포스터내의 문자/단어 인식을 위해 테스트한 모델은 다음과 같음▼
- paddle OCR
- CRAFT
- DocLayout-YOLO
- Nanonets-OCR-s
처음엔 OCR모델만 찾다 결국 VLM모델로 넘어간거긴하지만 최종적으로 Nanonets 모델이 가장 나은 성능을 보였기에 선택함.
D. 언어인식 모델 빌드 및 테스트
고객이 번역하고자 하는 포스터의 언어가 정해져있지 않았기에 다국어 → 영어로 번역이 가능한 모델을 찾아야했음. fasttext와 m2m100모델이 가장 적합하였기에 선택. 약 100개의 언어를 100개의 언어로 번역 가능.
