2026.04.07
문제 설명
H-Index는 과학자의 생산성과 영향력을 나타내는 지표입니다. 어느 과학자의 H-Index를 나타내는 값인 h를 구하려고 합니다. 위키백과1에 따르면, H-Index는 다음과 같이 구합니다.
어떤 과학자가 발표한 논문 n편 중, h번 이상 인용된 논문이 h편 이상이고 나머지 논문이 h번 이하 인용되었다면 h의 최댓값이 이 과학자의 H-Index입니다.
어떤 과학자가 발표한 논문의 인용 횟수를 담은 배열 citations가 매개변수로 주어질 때, 이 과학자의 H-Index를 return 하도록 solution 함수를 작성해주세요.
제한 사항
- 과학자가 발표한 논문의 수는 1편 이상 1,000편 이하입니다.
- 논문별 인용 횟수는 0회 이상 10,000회 이하입니다.
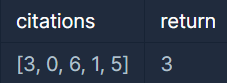
입출력 예
문제 풀이
1차 실행 오류
if문 내부의 조건인 entry.getKey() > citations[i]을 반대로 설정함
import java.util.Map;
import java.util.HashMap;
class Solution {
public int solution(int[] citations) {
int answer = 0;
Map<Integer, Integer> count = new HashMap<>();
for (int i = 0; i < citations.length; i++) {
count.put(citations[i], count.getOrDefault(citations[i], 0) + 1);
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() > citations[i]) {
count.put(entry.getKey(), entry.getValue() + 1);
}
}
}
int min = 0;
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() <= entry.getValue() &&
entry.getKey() > min) {
min = entry.getKey();
}
}
return min;
}
}2차 실행 오류
2번째 for문에서 인용된 횟수가 많은 논문이 먼저 나오게 되면,
그보다 적은 인용 횟수를 가진 논문의 개수가 올라가지 않음
예)
6회 인용 횟수를 가진 논문의 수가 첫번째로 나왔을 때,
그 뒤에 3회 인용 횟수를 가진 논문의 수는 2가 되어야 하지만 1이 됨
import java.util.Map;
import java.util.HashMap;
class Solution {
public int solution(int[] citations) {
int answer = 0;
Map<Integer, Integer> count = new HashMap<>();
for (int i = 0; i < citations.length; i++) {
count.put(citations[i], count.getOrDefault(citations[i], 0) + 1);
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() < citations[i]) {
count.put(entry.getKey(), entry.getValue() + 1);
}
}
}
int min = 0;
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() <= entry.getValue() &&
entry.getKey() > min) {
min = entry.getKey();
}
}
return min;
}
}3차 실행 오류
순회 도중 HashMap을 수정하면 ConcurrentModificationException 예외 발생
import java.util.Map;
import java.util.HashMap;
import java.util.Arrays;
class Solution {
public int solution(int[] citations) {
int answer = 0;
Arrays.sort(citations);
Map<Integer, Integer> count = new HashMap<>();
for (int i = 0; i < citations.length; i++) {
count.put(citations[i], count.getOrDefault(citations[i], 0) + 1);
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() < citations[i]) {
count.put(entry.getKey(), entry.getValue() + 1);
}
}
}
int max = 0;
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() <= entry.getValue() &&
entry.getKey() > max) {
max = entry.getKey();
}
}
return max;
}
}4차 실행 오류
[10, 10, 10]이 입력되었을 때와 같은 경우의 수가 고려되지 않음
3이 리턴이 되어야 하지만, 0이 리턴됨
import java.util.Map;
import java.util.HashMap;
import java.util.Arrays;
import java.util.List;
import java.util.ArrayList;
class Solution {
public int solution(int[] citations) {
int answer = 0;
Arrays.sort(citations);
Map<Integer, Integer> count = new HashMap<>();
// 해시맵에 인용 수와 횟수 저장
for (int i = 0; i < citations.length; i++) {
count.put(citations[i], count.getOrDefault(citations[i], 0) + 1);
// 해당 인용 수 보다 적은 횟수를 가진 논문의 횟수 증가
List<Integer> keys = new ArrayList<>(count.keySet());
for (int key : keys) {
if (key < citations[i]) {
count.put(key, count.get(key) + 1);
}
}
}
// H-Index 찾기
int max = 0;
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() <= entry.getValue() &&
entry.getKey() > max) {
max = entry.getKey();
}
}
return max;
}
}나의 코드
소요 시간: 49분
시간 복잡도: O()
문제를 봤을 땐 간단해보여서 쉽게 해결할 수 있을줄 알았음
코드 로직상에 여러 오류가 있었고, 예외도 발생하였으며,
고려하지 않은 경우의 수도 있었음.
3차 실행 오류 부터는 어떤게 잘못된지 이해가 잘 안돼서 AI를 활용하여
오류 사항만 찾고 코드 수정은 직접 하는 방식으로 해결함
import java.util.Map;
import java.util.HashMap;
import java.util.Arrays;
import java.util.List;
import java.util.ArrayList;
class Solution {
public int solution(int[] citations) {
int answer = 0;
Arrays.sort(citations);
Map<Integer, Integer> count = new HashMap<>();
// 해시맵에 인용 수와 횟수 저장
for (int i = 0; i < citations.length; i++) {
count.put(citations[i], count.getOrDefault(citations[i], 0) + 1);
// 해당 인용 수 보다 적은 횟수를 가진 논문의 횟수 증가
List<Integer> keys = new ArrayList<>(count.keySet());
for (int key : keys) {
if (key < citations[i]) {
count.put(key, count.get(key) + 1);
}
}
}
// H-Index 찾기
int max = 0;
for (Map.Entry<Integer, Integer> entry : count.entrySet()) {
if (entry.getKey() <= entry.getValue() &&
entry.getKey() > max) {
max = entry.getKey();
}
else if (entry.getKey() > entry.getValue() &&
entry.getValue() > max) {
max = entry.getValue();
}
}
return max;
}
}AI 코드
내림차순 정렬 후 인덱스+1과 값을 비교
[6, 5, 3, 1, 0]
i=0 → 6 >= 1 ✅ h=1
i=1 → 5 >= 2 ✅ h=2
i=2 → 3 >= 3 ✅ h=3
i=3 → 1 >= 4 ❌ break
H-Index = 3
코드 해석
Arrays.stream(citations).boxed().toArray(Integer[]::new);
Arrays.stream(citations) // int[] → IntStream으로 변환
.boxed() // IntStream → Stream<Integer>로 변환 (int → Integer)
.toArray(Integer[]::new) // Stream<Integer> → Integer[]로 변환// int[]는 Collections.reverseOrder() 사용 불가
int[] arr = citations;
Arrays.sort(arr, Collections.reverseOrder()); // ❌ 컴파일 에러
// Integer[]는 가능
Integer[] arr = ...;
Arrays.sort(arr, Collections.reverseOrder()); // ✅// Integer[]::new 는 아래와 동일
.toArray(size -> new Integer[size])import java.util.Arrays;
import java.util.Collections;
class Solution {
public int solution(int[] citations) {
Integer[] arr = Arrays.stream(citations).boxed().toArray(Integer[]::new);
Arrays.sort(arr, Collections.reverseOrder());
int h = 0;
for (int i = 0; i < arr.length; i++) {
if (arr[i] >= i + 1) {
h = i + 1;
} else {
break;
}
}
return h;
}
}