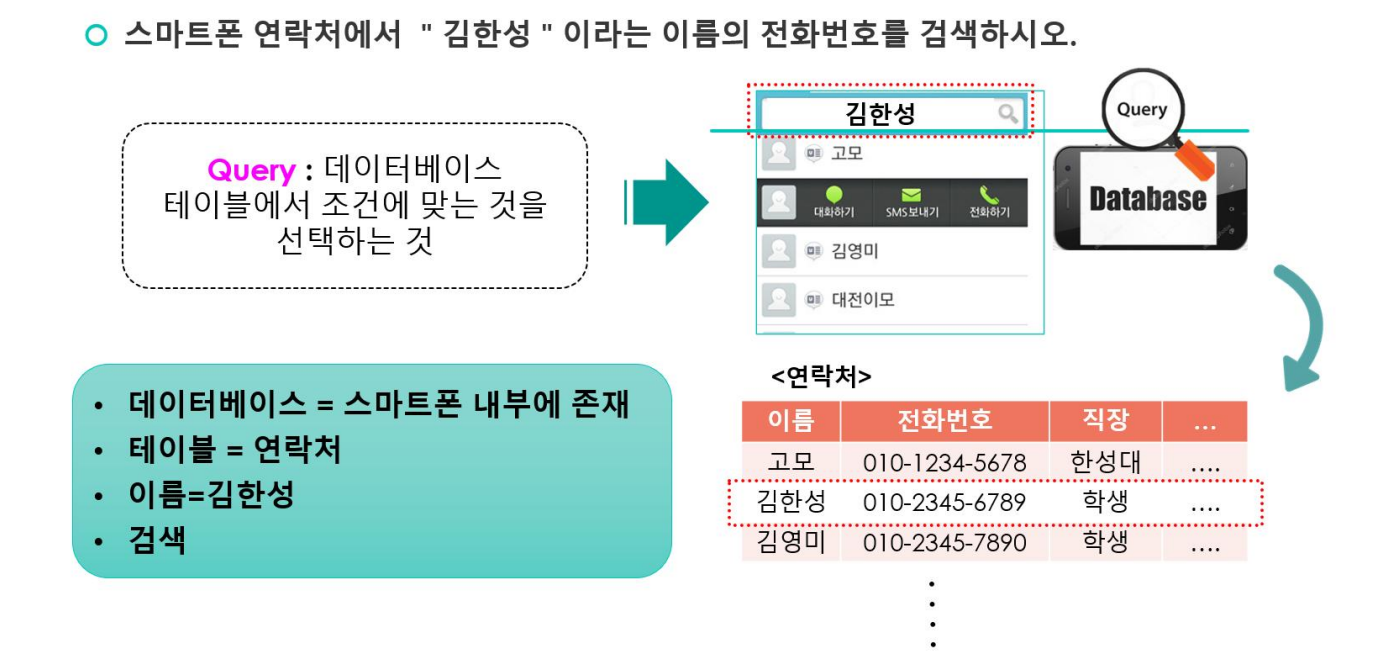
Query
데이터베이스 테이블에서 조건에 맞는 것을 선택하는 것
SQL(Structured Query Language)
사용자와 데이터베이스 시스템 간에 의사소통을 하기 위한 언어
- 데이터베이스의 테이블을 작성, 수정, 검색할 수 있는 언어

- 표준 질의어로 채택되어 널리 쓰이는 관계형 질의언어
- 자연어와 유사하고 비절차적 언어이므로 사용하기에 용이함
SQL의 구성
- SQL은 크게 DDL과 DML로 구성됨
데이터 정의 언어(DDL: Data Defination Language)
데이터 저장 구조를 명시
테이블 스키마의 정의, 수정, 삭제
-
테이블 생성
CREATE TABLE <테이블 이름> <속성(예) id INTEGER NOT NULL)>
한글의 경우 한 글자에 3바이트를 차지하므로 차지하므로
varchar(12)의 경우 4글자까지 저장이 가능함 -
테이블 삭제
drop table <테이블 이름> -
테이블 수정
추가
alter table <테이블 이름> add <추가할 필드>
예) alter table student add age int
삭제
alter table <테이블 이름> drop column <삭제할 필드>
예) alter table student drop column age
데이터 조작 언어(DML: Data Manipulation Language)
사용자가 데이터를 접근하고 조작할 수 있게 하는 언어
레코드의 검색(search), 삽입(insert), 삭제(delete), 수정(update)
-
레코드 삽입
insert into <테이블 이름> values <레코드>
예) insert into department (office, dept_id, dept_name) values ('201호', '920', '컴퓨터공학과')
위와 같이 속성을 명시했을 경우,
처음 테이블을 만들 때와 같은 순서로 입력하지 않아도 됨
예) insert into department values ('920', '컴퓨터공학과')
속성을 명시하지 않고 넣을 경우, 처음 테이블을 만들 때와 같은 순서로 레코드들을 삽입해야 함 -
레코드 수정
update <테이블 이름> set <수정 내역> where <조건>
예)update professor set position='교수' where name='고희석'
테이블의 모든 레코드에 대해 수정을 적용하려면 where을 생략
예)update student set year += 1 -
레코드 삭제
delete from <테이블 이름> where <조건>
예)delete from professor where name='김태석' -
레코드 검색
select <필드리스트> from <테이블 이름> where <조건>
중복된 레코드를 제거하고 검색하고 싶다면distinct 사용
예)select distinct address from student
모든 필드 값을 탐색할 때에는 * 사용
예) select student.stu_id
from student, department
where student.dept_id = department.dept_id and
student.year = 3 and
department.dept_name='컴퓨터공학과'
탐색 순서는 from →where → select
Select
-
기본적으로 중복을 허용
중복을 제거하려면 select 다음에 distict 키워드 삽입
select distinct dept_name from instructor; -
+, -, *, / 연산자를 사용한 산술 표현식을 포함할 수 있음
select ID, name, salary/12 from instructor; -
where의 경우 +, -, *, /, and, or, 비교 연산자 등 사용 가능
실습
-
오라클 내부적으로 저장되는 것과 별개로
콘솔에서는 1바이트당 무조건 2칸 폭으로 설정
한글 하나당 2칸을 사용하기 때문 -
따라서
varchar(12)일 경우 24칸으로 설정함
콘솔창은 12를 문자 수로 간주하기 때문
오라클 내부와 콘솔 창에서의 너비는 다르다
column <속성 이름> format a8
n은 표현할 문자의 개수로, 한글의 경우 한 글자당 2바이트이므로
a8은 최대 한글 4글자 혹은 영어 8글자 폭으로 지정
column <속성 이름> format 999
9의 개수는 표현할 정수의 자리수
999는 최대 3자리의 정수까지 표현 가능
COMMIT
-
INSERT,UPDATE,DELETE는SELECT와 달리 데이터베이스의 내용을
변경시키기 때문에 신중해야 한다. -
따라서 대부분의 DBMS들은 이 명령어를 실행하면 즉시 반영하지 않고
COMMIT명령을 내리면 데이터베이스에 영구적으로 반영한다.
COMMIT명령을 내리면 취소가 불가능하다.
COMMIT명령을 내리기 전이라면,ROLLBACK명령어를 통해 취소가 가능하다. -
SQL*PLUS에서는 EXIT 명령을 사용할 때 COMMIT을 자동으로 수행
또는SET AUTOCOMMIT ON;명령을 실행하면 자동 커밋
집계함수
select절과having,order by절에서만 사용 가능sum,avg는 숫자형 데이터 타입을 갖는 필드에서만 적용 가능- 비교 연산자와 사칙연산은
having절과 함께 사용이 가능함
count
데이터의 개수를 구한다.
count (distinct <필드이름>)
- 해당 필드에 값이 몇개인지 출력
- distinct: 서로 구별되는 값의 개수가 필요한 경우에만 사용
중복되는 데이터를 제외한 수를 리턴 - NULL은 계산에서 제외됨
- <필드이름> 대신
*가 사용된 경우, 레코드의 개수를 계산
예)
1) student 테이블에서 3학년이 몇 명인지 출력
select count(\*) from student where year = 3;
2) student 테이블에서 dept_id 필드에 값이 몇 개인지 출력
select count(dept_id) from student;
sum
- 데이터의 합을 구한다.
sum(<필드이름>)
예)
전체 교수들의 재직연수 합
select sum(2012 - year_emp) from professor;
emp 테이블에서 저장된 모든 직원들의 급여 합을 출력
select sum(sal) from emp;
avg
- 데이터의 평균 값을 구한다.
avg(<필드이름>)
예) 전체 교수의 평균 재직연수를 출력
select avg(2012 - year_emp) from professor;
max, min
- 데이터의 최대/최소 값을 구한다.
max(<필드이름>);
min(<필드이름>);
레코드의 순서 지정
- 항상 마지막에 위치함
order by
- 검색 결과를 정렬하여 출력
- 오름차순을 기본으로 함
order by<필드리스트>;
예) student 테이블에서 3, 4학년 학생들의 이름과 학번을 검색
select name, stu_id from student where year = 3 or year = 4
order by name, stu_id;
학생 이름으로 오름차순 정렬하며, 같은 이름에 대해서는 stu_id의 오름차순 정렬
desc
- 검색 결과를 내림차순으로 출력
select name, stu_id from student where year = 3 or year = 4
order by name desc, stu_id;
stu_id 뒤에는 desc가 없으므로 이름이 같을 때
stu_id 기준을 오름차순 정렬
GROUP BY
select절에 집계 함수를 사용할 경우 다른 필드 사용 금지
예)
SELECT name, COUNT(\*) FROM student; 해당 질의는 불가능
name COUNT(*)
홍길동
장발장 4 ← 4를 어느 name에 붙여야 하는가?
신데렐라
콩쥐group by를 사용하면 그룹별로 집계함수 적용 가능
group by <필드리스트>
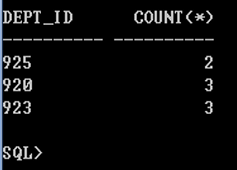
예) student 테이블에서 학과번호별로 레코드의 개수를 출력
select dept_id, count(\*) from student group by dept_id
HAVING
- 그룹에 대한 조건을 명시할 때 사용
having <집계함수 조건>
예) 평균 재직년수가 10년 이상인 학과에 대해서만 교수 숫자와 평균 재직년수, 최대 재직년수 출력
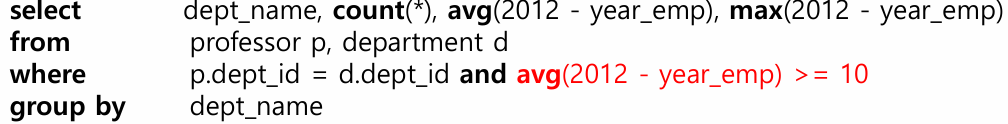
위의 질의는 오류임
where절과 집계함수는 단독으로는 동시 사용 불가.
즉, where절로 집계 함수에 조건을 거는 것은 불가능함
집계 함수에 조건을 걸 때에는 having을 사용해야 함
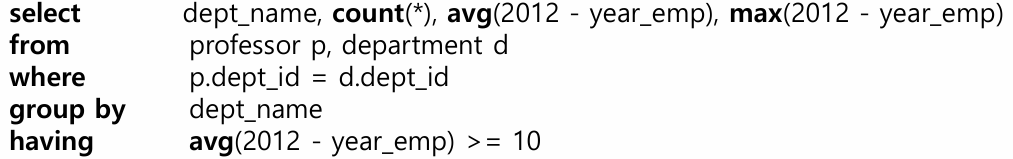
위의 질의는 가능
집계 함수와 필드를 사용하고 싶다면 group by를, 집계 함수에 조건을 걸고 싶다면 having을 사용해야 함
중간 점검
1. FROM → 테이블 가져오기
2. WHERE → 행 필터링
3. GROUP BY → 그룹으로 묶기
4. HAVING → 그룹 필터링
5. SELECT → 출력할 컬럼 선택
6. ORDER BY → 정렬LIKE
-
문자열에 대해서 일부분만 일치하는 경우를 찾아야 할 때 사용
where <필드이름> like <문자열패턴>
필드이름에 문자열패턴이 포함되어 있는지 확인 -
%서울%: '서울'이라는 단어가 포함된 문자열
-
%서울: '서울'이란 단어로 끝나는 문자열
-
서울%: '서울'이란 단어로 시작하는 문자열
-
___: 정확히 3개의 문자로 구성된 문자열 -
___%: 최소 3개 이상으로 구성된 문자열
예) student 테이블에서 김씨 성을 가진 학생들을 출력
select \* from student where like '김%'
재명명
- 테이블이나 필드에 대한 재명명
예)
select student.name, department.dept_name from student, department
where student.dept_id = department.dept_id
→
select s.name, d.dept_name from student s, department d
where s.dept_id = d.dept_id
- 동일 테이블이 2번 사용되는 경우
예) student 테이블에서 '김광식' 학생과 주소가 같은 학생들의 이름과 주소
select s2.name from student s1, student s2
where s1.address = s2.address and s1.name='김광식'
null의 처리
<필드이름> is null/is not null
예) takes 테이블에서 학점이 'A+'가 아닌 학생들의 학번을 검색
select stu_id from takes where grade <> 'A+'
<>는 !=를 의미함
INNER JOIN



집합 연산
UNION
예)
student 테이블의 학생 이름과 professor 테이블의 교수 이름을 합쳐서 출력
select name from student union select name from professor;
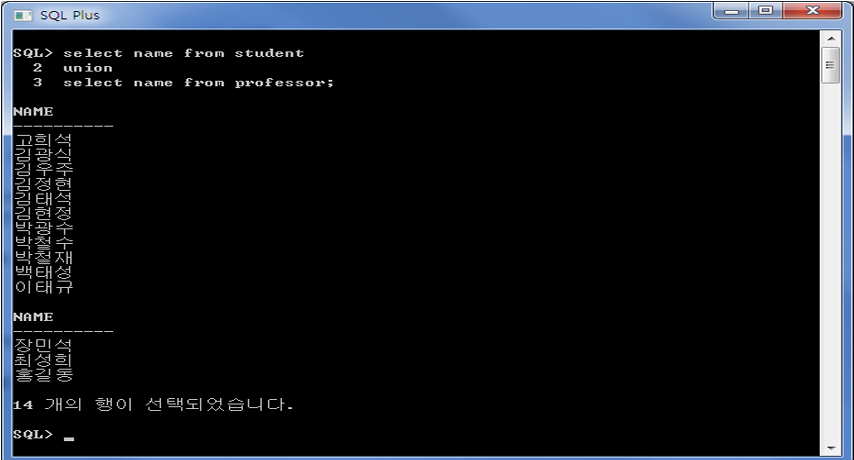
union연산자는 기본적으로 중복을 제거하기 때문에
중복을 유지하고 싶다면union all연산자를 사용
INTERSECT

두 select 결과에서 공통으로 존재하는 행 반환
MINUS

첫번째 select 결과에서 두번째 select 결과에 있는 행을 제외하고 출력
