데이터 모델
물리적 혹은 추상적으로 존재하는 현실세계를 단순화되고 정형화된 형태로 표현하는 하나의 방식 또는 규범
실제 데이터가 갖는 특성을 살리면서, 목적에 맞게 관심있는 정보만을 단순화하여 표현하는 방식
데이터에 대한 조작이 가능해야함
예)
의사라는 개체에서 이름, 전공, 나이, 전화번호, 주소 등의 데이터로 표현하는 과정을 모델링이라고 함

릴레이션(relation)의 개념
관계형 데이터 모델(relational data model)
- 테이블 형식을 이용하여 데이터들을 정의하고 설명한 모델
- 실세계의 데이터를 누구나 직관적으로 이해할 수 있는 형태로 기술할 수 있는 간단한 방식을 제공
- 테이블을 릴레이션(relation)이라고 부름
릴레이션(relation)
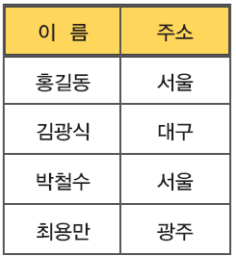
수학적으로 두 개 이상의 집합으로부터 각 집합을 구성하는 원소들의 순서쌍에 대한 집합을 의미
이름 = {홍길동, 김광식, 박철수, 최용만}
주소 = {서울, 대구, 서울, 광주}
순서쌍: {<홍길동, 서울>, <김광식, 대구>, <박철수, 서울>, <최용만, 광주>}
속성(attribute)
필드, 컬럼
릴레이션을 구성하는 각 열(column)의 이름
예)
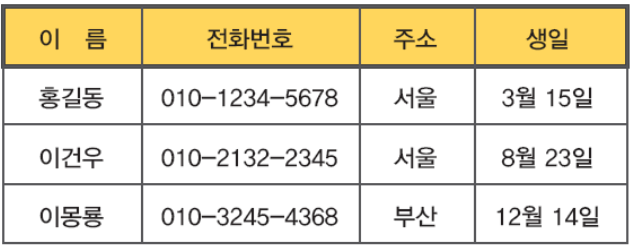
주소록의 속성: 이름, 전화번호, 주소, 생일
튜플(tuple)
레코드, 행
릴레이션의 각 행(row)
예)
주소록의 튜플: <홍길동, 010-1111-1111, 서울, 1월 1일>

도메인(domain)
각 필드에 입력 가능한 값들의 범위(자료형), 각 필드가 가질 수 있는 모든 값들의 집합
원자값(atomic value, 더 이상 분리되지 않는 값)이어야 함
예)
이름: 개인 이름들로 구성된 문자열 집합
전화번호: "nnn-nnnn-nnnn"의 형식으로 구성된 문자열의 집합
주소: 도시를 나타내는 문자열의 집합
생일: "nn월 nn일"로 구성된 문자열의 집합
널(null)
특정 필드에 대한 값을 알지 못하거나 아직 정해지지 않아 입력하지 못한 경우의 필드의 값
0이나 공백 문자와는 다름
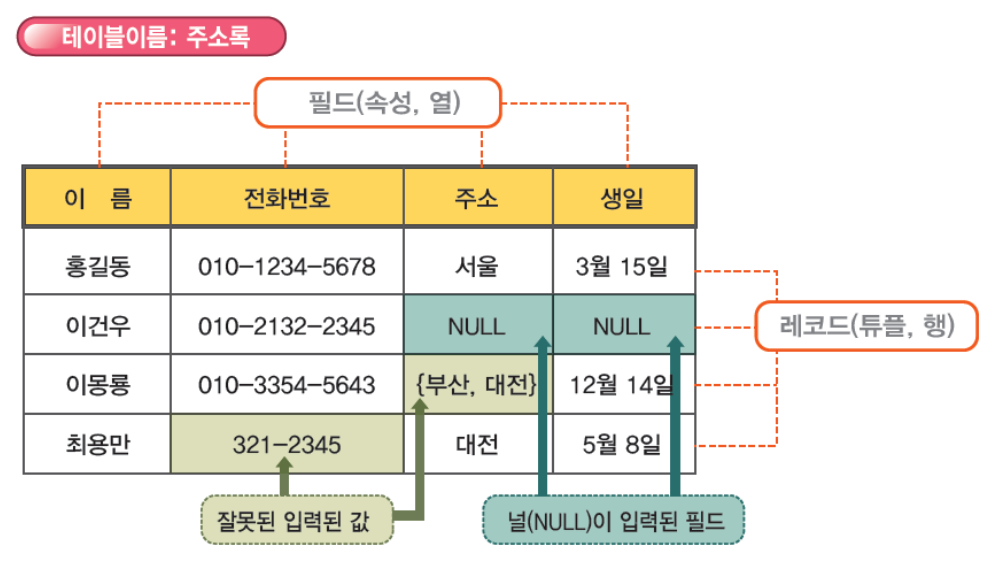
{부산, 대전}의 경우 도메인은 더이상 분리디지 않는 값이어야 한다는 조건을 충족하지 못했음
테이블 스키마와 테이블 인스턴스
테이블 스키마(table schema, 스키마)
테이블 정의에 따라 만들어진 데이터 구조
예)
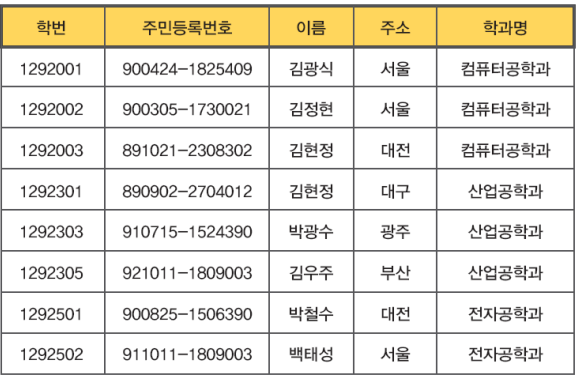
신입생(학번, 주민등록번호, 이름, 주소, 학과명)차수(degree)
테이블 스키마에 정의된 필드의 수
테이블 인스턴스(table instance, 인스턴스)
테이블 스키마에 현실 세계의 데이터를 레코드로 저장한 형태
스키마는 한번 정의하면 거의 변함이 없지만, 인스턴스는 수시로 바뀔 수 있음
레코드의 삽입, 삭제, 수정 등기수(cardinality)
테이블 인스턴스 레코드의 수
아래 테이블에서 기수는 8임
테이블의 특성
중복된 레코드가 존재하지 않음
중복된 정보가 저장되지 않는다.
- 테이블의 인스턴스는 레코드들의 집합임
레코드간의 순서는 의미가 없음
- 테이블 인스턴스는 레코드들의 집합임
- 첫번째/두번째 레코드 라는 표현은 의미가 없음
레코드 내에서 필드의 순서는 의미가 없음
- 테이블 스키마는 필드들의 집합으로 표현됨
- 첫번째/두번째 필드 라는 표현은 의미가 없음
모든 필드는 원자값을 가짐
키(key)
필드들의 일부로 각 레코드들을 유일하게 식별해낼 수 있는 식별자(identifier)
- 레코드간의 순서가 의미가 없으므로 레코드를 구분하기 위해서는 각 레코드의 값을 이용함
- 일반적으로 하나의 필드를 지정하여 키로 지정하나, 여러 개의 필드들로 키를 구성할 수도 있음
두개 이상의 필드로 구성된 키를 복합키(composite key)라고 함관계형 데이터 모델에서
특정 레코드를 구별하거나 탐색하기 위한 유일한 방법
