1주차-안드로이드개요
안드로이드
- 스마트폰, 태블릿 등의 모바일 디바이스를 위한 모바일 운영체제
- 리눅스 커널을 기반으로 한 소프트웨어 스택
2주차-코틀린기초
코틀린의 특징
1) 실용성
- 이미 검증되고 많이 사용하는 언어 기능을 채택
2) 간결성
- 타입 추론, getter/setter
3) 안정성(Null Safety)
4) 호환성(Interoperability)
5) 다양한 플랫폼 지원
- JVM 기반의 서버, 안드로이드, 코틀린 자바스크립트, 코틀린-native 등
6) 정적 타입 언어
- statically typed lang(java, kotlin)
7) 함수형 언어(Functional Lang)
8) 오픈 소스
패키지(packages)
자바와 다르게 코틀린은 소스 파일의 위치와 이름을 정하는 데에 제한이 없음
- 한 파일에 여러 개의 클래스를 넣을 수 있다.
- 패키지 구조와 디렉터리 구조가 일치할 필요가 없다
변수와 값(Variables & Value)
val
- 값 변경 불가
- 변수라고 부르지 않고 값이라고 부름
- value의 줄임말
var
- 값 변경 가능
- variable의 줄임말
타입 추론(Type Inference)
- 코틀린 변수 선언 시, 타입을 명시하지 않아도 컴파일러에 의해 정해짐
타입(Types)
-
자바와 달리
원시타입(primitive types)과 참조타입(wrapper type)을 구분하지 않음 -
서로 다른 타입의 값을 자동으로 변환 해주지 않기 때문에,
명시적으로 값 변환을 해주어야 함

if 문
- 코틀린에서 if는 statement가 아니라 expression으로 사용 가능함
- if문의 결과로 어떠한 값을 받을 수 있음
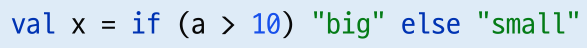
Any 타입, 타입 체크(is)
- 자바의 Object와 비슷한 개념으로 코틀린에는 Any가 있음
- 코틀린은 원시타입에 대해서도 Any가 가능함
- 타입 체크:
A is Type

타입 변환(as)
타입A as 타입B

문자열(String)
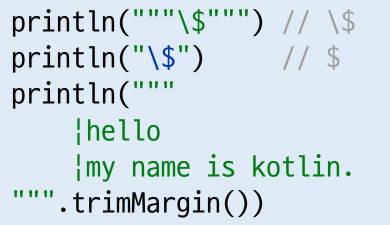
- 코틀린은 문자열 내부에 변수와 expressiont을 넣을 수 있다.

- 3중 따옴표를 사용하면 어떤 문자든 이스케이프 없이 그대로 쓸 수 있음
비교 연산(==or===)
- 객체 내용 비교에
==연산자를 사용하고,
객체 레퍼런스 비교에===연산자를 사용한다. - 문자열 비교에
==연산자를 쓸 수 있다.
Function
fun 함수이름(매개변수 리스트) = expression인 경우,
리턴 타입이 추정 가능하므로 생략됨(void타입인 경우도 생략 가능)- Default argument 지원

- Named argument 지원
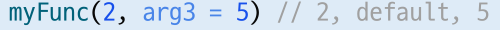
Function-Lamda
- 람다(Lamda) 함수는 익명 함수(이름이 없는 함수)
- 인자가 한 개이고 타입이 생략 가능한 경우
디폴트 인자를 써서 인자리스트 부분을 생략 가능
val sum = { x: Int, y: Int -> x + y }
fun lambdaTest(a : (Int) -> Int) : Int { return a(10) }
lambdaTest({x -> x + 10 }) // 인자 타입(Int) 생략 가능
lambdaTest({ it + 10 }) // 람다에 인자(매개변수)가 1개 뿐이므로 인자리스트(x ->) 생략
lambdaTest{it + 10} // 람다가 함수의 유일한 인자이면, 함수의 괄호 생략Function-Lamda(예제)
val array = arrayOf(MyClass(10, "class1"), MyClass(20, "class2"), MyClass(30, "class3"))
println(array.filter({ c : MyClass -> c.a < 15 })
// 람다가 함수 인자의 마지막으로 사용되면, 괄호 밖으로 뺄 수 있음
array.filter() { c : MyClass -> c.a < 15 }
// 람다가 함수의 유일한 인자이면, 함수의 괄호를 생략할 수 있음
array.filter { c : MyClass -> c.a < 15 }
// 인자 타입 생략 가능(컴파일러가 이미 array는 MyClass 타입인 것을 알기 때문)
array.filter { c -> c.a < 15 })
// 디폴트 매개변수 이름으로 it을 사용할 수 있음
array.filter { it.a < 15 } // 일반적으로 가장 많이 사용되는 형태When
switch문과 비슷하지만 케이스 마다 타입이 달라도 되며,
expression으로 사용할 수 있음
fun test (arg : Any) {
when(arg) {
10 -> println("10")
in 0..9 -> println("0 ≤ x ≤ 9")
is String -> println("Hello, $arg")
!in 0..100 -> println("x < 0 and x > 100")
else -> {
println("unknown")
}
}
}Null Safety
null이 가능한 타입과 불가능한 타입 구분
타입 뒤에?를 붙이면 nullable 타입
import java.util.NullPointerException
fun testNull(arg: String?) {
println(arg?.uppercase())
println(arg?.uppercase() ?: "-")
// "?:" 엘비스 연산자로 왼쪽 수식의 값이 null이라면 "-"을 리턴하라는 의미
}
Exception
try/catch문을 expression을 사용할 수 있음- 자바와 달리 모든 예외를 catch하게 강제하지 않음
3주차-코틀린OOP
Class
- 자바와 달리 기본적으로 public class
- 객체를 생성할 때 new 클래스를 쓰지 않음
- 속성 접근 메소드를 자동으로 만들어주며, 커스텀 접근 메소드를 만들 수 있음
Interface
- 인터페이스 구현 클래스의 메소드 구현에서
override를 반드시 써야함
기본적으로 상속, 오버라이드 금지
- interface, abstract class는 기본적으로 상속(구현), 메소드 오버라이드 가능
- class는 기본적으로 상속, 메소드 오버라이드 금지
상속이나 오버라이드가 가능하게 하려면open키워드 사용 - 메소드 오버라이드 접근 변경
final: 오버라이드 금지, 기본적으로 final임
open: 오버라이드 가능, 명시적으로 open을 붙여야 오버라이드 가능
abstrack: 반드시 오버라이드 해야 함, abstract class 내에서만 사용 가능
override: 오버라이드 가능
기본적으로 공개(public)
- 클래스와 메소드 모두 기본적으로 public
- 접근(access) 변경자
public: 기본 모듈
internal같은 모듈
protected: 상속 받은 클래스에서만 접근 가능
private: 같은 클래스에서만 접근 가능
중첩(Nested) 클래스
- 코틀린에서 중첩 클래스는 자바에서 정적(static) 중첩 클래스와 같음
- 내부 클래스를 만들려면 중첩 클래스 앞에
inner키워드 사용

봉인(sealed) 클래스
- 특정 클래스를 상속하는 클래스를 제한할 수 있다.
sealed class Expr {
// Num과 Sum을 하나의 타입으로 묶어주는 부모 역할을 함과 동시에 상속 범위 제한을 함
// 만약 sealed 클래스가 아니라면 나중에 새로운 클래스가 추가되었을 때,
// eval에서 else를 강제로 써야함
class Num(val value: Int) : Expr()
class Sum(val left: Expr, val right: Expr) : Expr()
}
fun eval(e: Expr): Int =
when(e) {
is Expr.Num -> e.value
is Expr.Sum -> eval(e.right) + eval(e.left)
// Expr의 타입은 Num과 Sum 2개밖에 없기 때문에 else가 필요하지 않음
}
fun main() {
val r = eval(Expr.Sum(Expr.Num(10), Expr.Num(10)))
println(r)
}Constructor
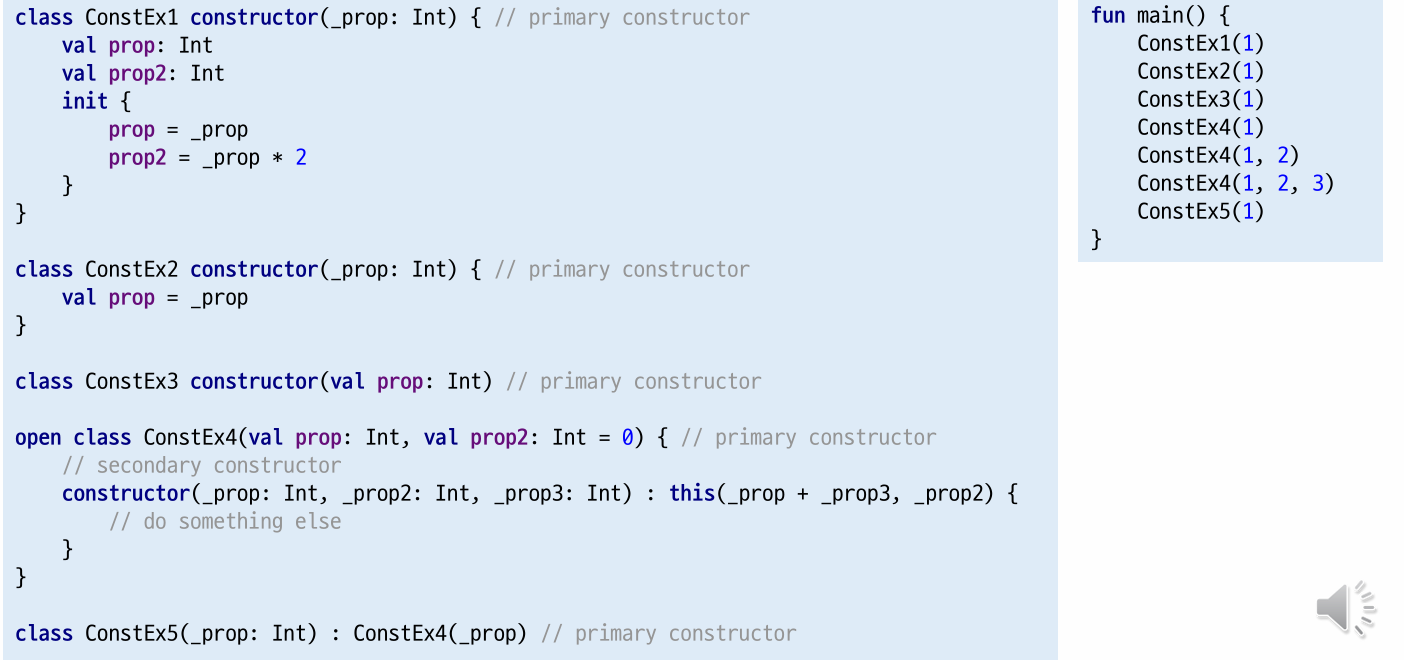
Primary constructor
- 클래스 이름 옆에 정의하는 생성자
- constructor는 생성자이며, primary contructor는 생략 가능함
default argument와 같은 기능을 함- 단, java의 경우
default argument가 존재하지 않아,
여러 생성자를 만들어야 하는 경우secondary constructor를 사용함
Secondary constructor
- 클래스 내부에 정의하는 생성자
- secondary constructor는 메소드와 생성자의 구분을 위해 사용함
- construct가 붙은 secondary constructor는
반드시 this()로 primary constructor를 호출해야함
Property와 getter/setter
- public 속성에 대해 setter를 private으로 정의하면 클래스 밖에서는 get만 가능
- interface에서 property를 정의할 수 있지만,
이 property는 구현 클래스에서 반드시 오버라이드 해야함
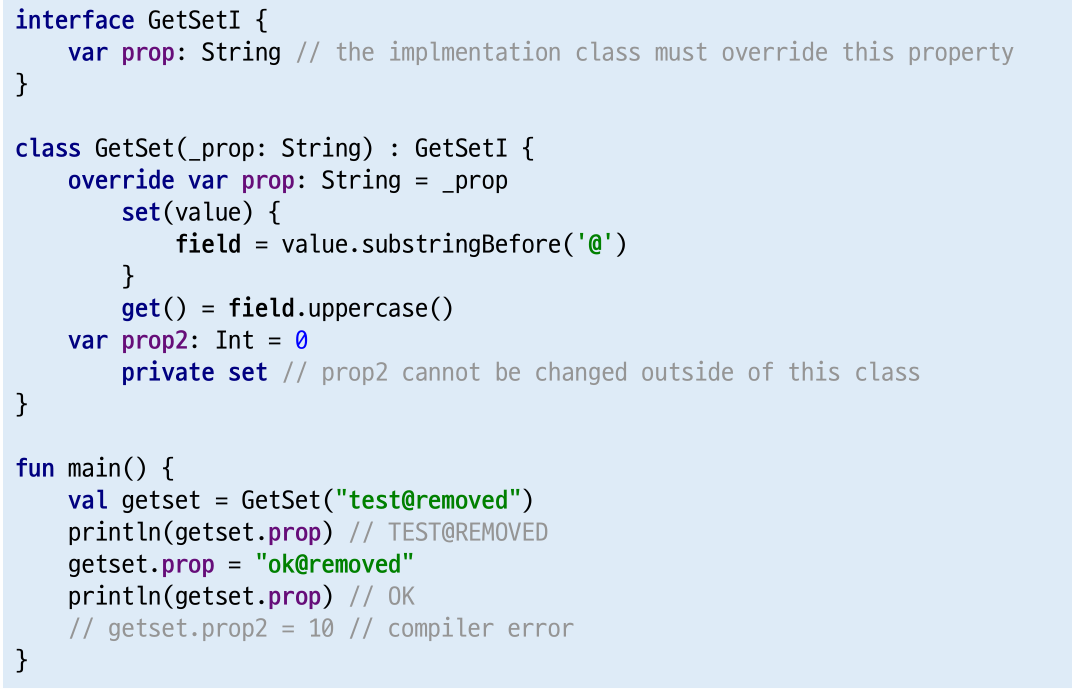
data class
- data class를 생성하면 자동으로
equals()hashCode()toString()copy이 생성됨
Object 키워드
-
클래스 정의 없이 바로 객체를 생성하는 방법
1) 싱글톤 만들기
2)companion object만들기
3)anonymous obeject를 만들 때 사용 -
Companion Object는 이 객체를 포함하는 클래스의 private 멤버에 접근 가능
Extension Method/Property
- 이미 만들어진 클래스의 메소드와 속성을
클래스를 상속하거나 수정하지 않고도 추가할 수 있음 - 이렇게 추가된 메소드는 오버라이드 불가능
- 자바의 기존 Collection들에 다양한 유틸 함수들을 이 방법으로 추가

- 속성에도 확장 가능

연산자 오버로딩
- 이항 산술 연산자 (+, -, *, /, %) 오버로딩 가능
오버로딩할 때 연산자 이름 plus, minus, times, div, rem - 단항연산자
unaryPlus,unaryMinus,not,inc,dec - 비교 연산자
equals,compareTo

위임(Delegation)
- 상속과 유사하지만 다름
1) 상속은 강한 결합, 위임은 약한 결합
2) 상속은 불가여도 위임은 가능
3) 위임(상속)할 클래스와 동일한 인터페이스를 구현해야 함
// 상속
open class Animal {
fun eat() = println("eating")
}
class Dog : Animal() // Animal을 상속
val d = Dog()
d.eat() // eating ← Animal의 메소드를 그대로 물려받음// 위임
interface Printable {
fun print()
}
class Printer : Printable {
override fun print() = println("printing")
}
// Printer 객체에게 Printable 구현을 위임
class Office(p: Printer) : Printable by p
val office = Office(Printer())
office.print() // printing ← Printer가 대신 처리// 위임이 필요한 이유
interface Printable {
fun print()
}
interface Scannable {
fun scan()
}
class Printer : Printable {
override fun print() = println("printing")
}
class Scanner : Scannable {
override fun scan() = println("scanning")
}
// 상속은 하나만 가능하지만, 위임은 여러 개 조합 가능
class Office(p: Printer, s: Scanner) : Printable by p, Scannable by s4주차-코틀린FP
Functional Programming (FP)?
함수형 프로그래밍이란?
-
자료 처리를 수학적 함수의 계산으로 다루고
상태 변경(changing state)과 가변 데이터(mutabledata)를 쓰지 않는 프로그래밍 패러다임 -
명령형 프로그래밍(imperative programming)에서는 상태를 바꾸는 것을 강조하는 것과는 달리, 함수형 프로그래밍은 함수의 응용을 강조
-
1930년대에 계산가능성, 결정문제, 함수 정의, 함수 응용과 재귀를 연구하기 위해 개발된 형식체계인 람다 대수(lamda-calculus)에 근간을 두고 있다.
수학적 함수와 명령형 프로그래밍에서 사용되는 함수
-
명령형 프로그래밍의 함수
1) 프로그래밍의 상태 값을 바꾸는 부수 효과가 생길 수 있음
2) 참조 투명성이 없고, 같은 코드라도 실행되는 프로그램의 상태에 따라
다른 결과값이 나옴 -
함수형 프로그래밍의 함수(수학적 함수)
1) 함수의 출력 값은 함수에 입력된 인수에만 의존
2) 인수 x에 같은 값을 넣고 함수 f를 호출하면 항상 f(x)라는 결과가 나옴
(참조 투명성)
3) 부수 효과를 제거하면 프로그램 동작 이해와 예측이 쉬움
함수형 프로그래밍 기본 요소
- pure function
부수 효과가 없는 함수
thread-safe하여 병렬 계산 용이 - anonymous function: 익명 함수
코틀린에서는{x -> x \* x} - higher-order function: 고차(고계)함수, 함수를 인자나 리턴으로 다루는 함수
코틀린에서는(1..10).map {it \* it}
코틀린은 순수한 함수형 언어가 아님. 함수형 언어의 요소 뿐 아니라
명령형 언어, 객체 지향 언어 패러다임을 모두 가지고 있음
Lamda
어원: 람다 대수
이름이 없는 함수
형식: {파라미터 -> 함수 바디}
{x: Int, y: Int -> x + y}- 함수 바디에서 마지막 수식(expression)이 리턴 값이 됨
Lamda에서 로컬 변수 참조
- val, var 구분 없이 모든 로컬 변수 참조가 가능함
Collection filter, map, groupBy와 lamda
data class Student(val name: String, val age: Int)
fun main() {
val data = listOf(Student("Jun", 21), Student("James", 25),
Student("Tom", 21), Student("Jane", 23), Student("John", 23))
println(data.filter {it.age >= 22})
// [Student(name=James, age=25), Student(name=Jane, age=23),
// Student(name=John, age=23)]
println(data.map {it.age - 20})
// [1, 5, 1, 3, 3]
println(data.filter {it.age >= 22}.map(Student::name)
// [James, Jane, John]
println(data.groupBy {it.age})
// {21=[Student(name=Jun, age=21), Student(name=Tom, age=21)],
// 25=[Student(name=James, age=25)],
// 23=[Student(name=Jane, age=23), Student(name=John, age=23)]}
val words = arrayOf("hello", "hi", "hot", "apple",
"orange", "access", "order", "about")
println(words.groupBy {it.first()})
// {h=[hello, hi, hot], a=[apple, access, about], o=[orange, order]}
}
Collection all, any, count, find와 lambda
fun main() {
val nums = arrayOf(-5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5)
println(nums.all {it is Int}) // true
println(nums.all {it > 0}) // false
println(nums.any {it > 0}) // true
println(nums.count {it > 0}) // 5
println(nums.find {it > 0}) // 1
}Collection flatMap과 lambda
- 중첩된 Collection을 하나의 리스트로 생성/리턴
flatMap에 주어진 람다는Iterable객체를 리턴하고,
이Iterable을 모두 연결하여 하나의List로 만듦
public inline fun <T, R>
Iterable<T>.flatMap(transform: (T) -> Iterable<R>) : List<R>fun main() {
val list = listOf("abc", "cde", "efg")
println(list.flatMap {it.toList()} // [a, b, c, c, d, e, e, f, g]
println(list.flatMap {it.toList()}.toSet()) // [a, b, c, d, e, f, g]
class Classes(val name: String, val students: List<String>)
val classes = listOf(Classes("Cprog", listOf("james", "john", "greg")),
Classes("OS", listOf("james", "john", "jane", "tom")),
Classes("Net", listOf("john", "jane", "alex", "sam")) )
println(classes.flatMap { it.students }.toSet().sorted())
// [alex, greg, james, jane, john, sam, tom]
}Collection asSequence
-
filter,map등의 함수를 부를 때, 바로 다른 리스트를 생성하게 됨 -
이러한 함수를 매우 큰 데이터에 대해 여러번 이어서 사용하면 매우 느려질 것
-
이런 경우
Sequence를 사용하면
리스트 생성을 최대한 늦추게 하는 방법임
실제로 리스트 생성 작업을 최대한 늦추기 때문에 lazy 연산이라고 보통 부름 -
Sequence를 사용하여 연산을 끝낸 후에,
다시toList()로Collection을 바꾸어 사용함
lamda와 SAM
SAM: Single Abstract Method
- 인터페이스가 하나의 메소드만 가진 경우
- 코틀린에서 이런 SAM인 경우, lamda로 처리할 수 있음
fun interface doInterface { // SAM
fun doIt()
}
fun doSomething(di: doInterface) = di.doIt()
fun main() {
doSomething(object : doInterface { // java-like
override fun doIt() { println("Java-like way") }
})
}
doSomething( doInterface { println("SAM") } )
doSomething { println("SAM 1") }
/*
doSomething {
override doIt() {
println("SAM1")
}
}
과 같음
추상 메소드가 1개이기 때문에 생략이 가능*/
val doi = { println("SAM 2") }
doSomething(doi)Scope 함수
- 객체의 이름을 반복하지 않고, 그 객체에 대해 여러 연산을 수행할 수 있음
- 종료:
let,run,with,apply,also - 함수 인자로 lamda를 전달하는데,
이 lamda 내에서 객체를it또는this로 지칭 - 함수의 리턴 값은 객체 또는 lamda의 결과
- scope 함수는 언어 문법이 아닌 표준 라이브러리
Scope 함수-with, apply
fun main() {
val str = with (StringBuilder()) { // this로 객체 지정
this.append("Hello, ")
append("This ") // this 생략
append("is an example of ")
append("lambda with.")
.toString()
} // with의 리턴값은 마지막 expression
println(str)
val str2 = StringBuilder().apply {
this.append("Hello, ")
append("This ") // this 생략
append("is an example of ")
append("lambda apply.")
}.toString() // apply는 StringBuilder를 리턴함
println(str2)
}Scope 함수-let, run, also
fun main() {
val r1 = "hello".let {
println("$it")
it.length
}
val v2 = "hello".run {
println("$this")
length
}
val v3 = "hello".also {
println("$it")
}.length
println("$r1, $r2, $r3") // 5, 5, 5
}Collection 연산자 오버로딩
[]
- get(idx), set(idx, value)
in
- contains(value)
iterator
- 컬렉션을 순서대로 하나씩 순회하기 위한 객체
내부적으로for문을 이용함 Iterable을 이용하여 해당 클래스가 순회 가능함을 명시- Iterator Implementation
- Iterator
data class Three(var x: Int, var y: Int, var z: Int) : Iterable<Int> {
operator fun get(idx: Int) : Int {
return when(idx) {
0 -> x
1 -> y
2 -> z
else ->
throw IndexOutOfBoundsException("Invalid index $idx")
}
}
operator fun set(idx: Int, value: Int) {
when(idx) {
0 -> x = value
1 -> y = value
2 -> z = value
else ->
throw IndexOutOfBoundsException("Invalid index $idx")
}
}
operator fun contains(value: Int) = (x == value || y == value || z == value)
inner class MyIterator : Iterator<Int> {
var curIdx = 0
override fun next(): Int {
val ret = this@Three[curIdx]
curIdx++
return ret
}
override fun hasNext(): Boolean {
return curIdx <= 2
}
}
override fun iterator(): Iterator<Int> = MyIterator()
}
fun main() {
val three = Three(1, 2, 3)
println("${three[0]}, ${three[1]}, ${three[2]}")
println(3 in three)
for (i in three) {
println(i)
}
}가변 인자
- 인자의 개수가 정해져있지 않을 때 사용
vararg를 매개 변수 이름 앞에 사용spread연산자: *을 배열 앞에 붙여서 가변 인자로 넘겨줄 수 있음
val list = listOf(1, 2, 3, 4)
fun listOf<T>(vararg values: T): List<T> { } // 가변 인자 선언
val args = arrayOf("1", "2", "3", "4")
val list2 = listOf("0", *args) // spread 연산자
println(list2) // 0, 1, 2, 3, 4Infix Function
- 함수 이름을 인자 중간에 넣어서 호출
infix fun Int.add(other: Int): Int {
return this + other
}
println(3.add(5)) // 일반 호출
println(3 add 5) // infix 호출Destructuring declaration
- 값 2개를 리턴받아 2개의 변수에 대입
data class Result(val result: Int, val status: String)
fun calcSomething(): Result {
// computations
return Result(404, "Not Found")
}
fun main() {
val (num, str) = 1 to "one"
println("$num, $str") // 1, one
val collection = mapOf(1 to "one", 2 to "two")
for ((a, b) in collection) {
println("$a, $b")
}
val (result, status) = calcSomething()
println("$result, $status") // 404, Not Found
}5주차-안드로이드UI
반응형 디자인
-
모바일은 기기마다 화면 크기와 비율이 제각각
-
유연한 레이아웃(Flexible Layout)
화면 크기에 따라 너비나 높이가 유동적으로 변하는 구조 -
안전 영역(Safe Area)
노치 디자인이나 하단 바에 UI가 가려지지 않도록 보호하는 영역 -
적응형 UI(Adaptive UI)
기기 유형에 따라 레이아웃 구조 자체가 바뀌는 설계
사용자 경험(UX) 원칙
-
디자인 가이드라인이 없어도 지켜야 할 최소한의 규칙
-
시각적 계층 구조
중요한 정보는 크고 진하게 배치하여 사용자의 시선을 유도 -
피드백(Affordance)
버튼을 눌렀을 때 색이 변하거나 진동이 오는 등, 동작이 수행됨을 알려야 함 -
일관성(Consistency)
앱 전체에서 확인 버튼의 위치나 뒤로가기 동작이 일관되어야 함 -
접근성(Accessibility)
저시력자나 색약 사용자를 위한 충분한 대비와 텍스트 크기 고려
이미지의 경우 content Description을 제공하여 시각장애인 고려
모바일 앱 계층구조
컴포넌트(Component)
- UI를 구성하는 최소 단위
- Button, Text, Image 등
레이아웃(Layout)
- 컴포넌트들을 화면에 배치하는 규칙
- 가로/세로 정렬, 여백, 중첩
- Row, Column, Box
컨테이너(Container)
- 앱의 기본적인 뼈대, 또는 시각적 효과를 위해 여러 컴포넌트를 하나로 묶어 관리하는 단위
- Scaffold: 앱의 기본적 뼈대
- Surface: 컴포넌트를 감싸고 배경색, 테두리, elevation 등을 부여
모바일 앱 UI 패러다임 변화
명령형(Imperative)→선언형(Declarative)으로
모바일 UI 프레임워크 패러다임 변화
명령형 UI
- "버튼의 색을 빨갛게 바꾸고, 텍스트를 '확인'으로 변경하라"
와 같은 상태 변화에 따른 UI의 변경 과정을 일일이 코딩 (예전 방식) - Android XML 레이아웃 방식
- Android View 방식
선언형 UI
- UI 상태(State)를 정의. "UI 상태가 '완료'라면 버튼은 빨간색이고
텍스트는 '확인'이다." 라고 UI 선언을 작성 - 프레임워크가 UI 상태 변화를 감지하면 자동으로 UI 선언에 따라 화면을 그림
- 안드로이드 Jetpack Compose에서 UI 선언은 Composable로 작성함
- UI는 상태의 함수
안드로이드 View 방식
안드로이드 처음부터 있던 UI 작성 방식
컴포넌트, 레이아웃은 모두 View를 상속
컴포넌트
- 정보를 출력, 입력 받기 위한 UI 구성 요소
- TextView, Button, EditText, Checkbox 등
레이아웃
- 사용자 인터페이스에 대한 시각적 형태
- XML 파일로 작성하고, 소스 코드에서 로드하여 사용함
- LinearLayout, ConstrainsLayout 등
View 클래스
- 화면에 표시 가능한 사각형 영역
- 각각의 뷰는 알아서 자신의 내용을 그리고, 이벤트 처리
ViewGroup은View이지만 다른View를 포함할 수 있는View
레이아웃은ViewGroup에 속함- UI 컴포넌트, 레이아웃 모두 View를 상속하여 구현
- View의 속성 = 컴포넌트, 레이아웃의 속성
Jetpack Compose
- 안드로이드 기존 XML 방식이 아닌, kotlin으로 UI를 만드는 툴킷
장점
- XML의 방식에 비해 코드의 양이 줄어든다.
- kotlin 만으로 만들 수 있다.
- 선언형 UI, 직관적 API
- 기존 View에서도 사용 가능
Composable Function
- Jetpack Compose에서 UI를 선언형으로 기술하는 함수
- 간단한 버튼이나 텍스트 필드를 포함하여 리스트나 그리드같은
복잡한 레이아웃 등의 UI 요소를 생성하는 함수 - 다른 Composable function 내에서만 호출 가능
- 상태(State)를 가질 수 있음
상태가 바뀌면 composable function은 recomposition에 의해 다시 실행됨 - Composable function 작성 주의
이름은 대문자로 시작, 명사형으로 할 것
pure function으로 만들것
레이아웃(Layout)
- Column, Row Box 레이아웃 함수를 사용하여 자식 위젯을
세로, 가로, 겹치게 배치할 수 있음
Modifier
- 컴포넌트의 크기, 레이아웃, 모양, 클릭, 이벤트 등을 결정
- 호출 순서 중요
dp와 sp 단위
dp(Density-independent Pixels)
- 화면의 밀도와 상관없이 항상 동일한 물리적 크기 유지
- 버튼 크기, 레이아웃 간격, 이미지 크기 등 UI 요소의 크기를 정할 때 사용
sp(Scale-independent Pixels)
- 사용자의 시스템 글꼴 크기 설정에 따라 크기가 가변적으로 변하는 단위
- 텍스트 크기를 정할 때 사용
슬롯 기반 레이아웃(컨테이너)
- UI 컨테이너에 빈 공간(슬롯)을 남겨두어
개발자가 원하는대로 채울 수 있게 함 - 대표적으로 Scaffold
@Preview
- 애뮬레이터를 실행하지 않고도 UI를 실시간으로 확인
6주차-UI 상태와 리소스
UI 상태 관리(State Management)
-
기존 안드로이드 View(명령형 UI)에서는 컴포넌트를 find해서
해당 컴포넌트의 데이터를 수정 -
Compose UI는 상태(State)의 함수이며, UI는 상태에 따라 변경됨
-
로컬 상태와 전역 상태
로컬 상태: 특정 화면 내에서만 쓰이는 임시 데이터
예) 입력창의 텍스트
전역 상태: 앱 전체에서 공유되는 데이터
예) 로그인 유저 정보 -
상태가 변경되면 해당 상태를 이용하는 컴포저블 함수가 다시 실행
(Recomposition)
상태 관리 패턴
상태 호이스팅(State Hoisting)
-
컴포저블을 재사용 가능하고 테스트하기 쉽게 만들기 위해
상태를 위쪽(Caller)으로 올리는 패턴 -
가능한 한 pure function으로 만들어서 관리
방법: 상태 변수 대신 value와 onValueChange 이벤트 콜백을 파라미터로 전달
장점: Stateless 컴포저블을 만들어 UI 로직과 비즈니스 로직을 분리
단방향 데이터 흐름(Unidirectional Data Flow)
-
데이터는 위에서 아래로 흐르고, 이벤트는 아래에서 위로 전달되는 구조
이를 통해 데이터 무결성을 유지 -
상태를 가능한 한 위쪽에서 관리하여 유지보수가 용이
Compose의 상태 관리
mutableStateOf와 State<T>
- Compose가 추적할 수 있는 관찰 가능한 (Observable) 객체
- mutableState는 값이 변경되면 Compose에 알림을 보내 리컴포지션을 유발
remember
- 리컴포지션은 함수가 다시 실행되는 과정
remember를 사용하지 않으면 함수가 다시 시작될 때 마다 변수가 초기화
역할: 리컴포지션 사이에서 값을 메모리에 보관
주의: 기기 회전(Configuration Change) 시에는 데이터가 저장되지 않음
이 경우rememberSaveable을 사용
상태 호이스팅(State Hoisting)
- 상태를 composable 외부로 옮겨서 Stateless하게 만드는 것
ViewModel과 StateFlow 통합
- 비즈니스 로직과 UI 상태를 ViewModel로 완전히 격리
- ViewModel과 StateFlow의 관계는
상태의 보관소(Storage)와 상태의 전달 통로(Pipe)
ViewModel
- UI 상태를 액티비티 생명 주기에 따라 관리하는 객체
- 액티비티가 완전히 종료될 때 까지 상태(데이터)를 유지함
화면 회전 등으로 액티비티가 다시 생성되더라도 ViewModel은 유지됨
StateFlow
- 코틀린 코루트에서 제공. 관찰 가능한(Observable) 상태 흐름
- 상태 변수에 저장된 데이터가 변경되면,
이를 관찰하는 대상(Composable)에게 알림
액티비티(Activity)
- 사용자와 상호작용할 수 있는
단일 화면(Single Screen)을 의미하는 앱 구성 요소 - 리소스 접근이나 시스템 서비스 호출에 필요한 context 제공
ViewModel + StateFlow → 단방향 흐름 패턴
- UI는 ViewModel의 StateFlow(Observable)을 관찰
- 사용자 이벤트가 발생하면 UI는 ViewModel의 함수 호출
- ViewModel은 로직 수행 후 StateFlow의 값을 업데이트
- StateFlow가 새로운 값을 방출하면, 이를 관찰하던 UI가 Recomposition
ViewModel과 라이프사이클
- Activity보다 생명 주기가 길기 때문에,
내부에 Activity의 Context를 유지하면 안됨 - 화면 회전 시 Activity는 종료되지만, ViewModel 객체는 유효하게 살아 있음
State<T>와 StateFlow<T>
State는 Compose 전용
- 값을 읽기만 하면 됨
상태가 바뀌면 바로 리컴포지션 동작 - 컴포저블 함수 내에서 사용
StateFlow는 코틀린 언어의 코루틴에 포함
- 데이터가 변하면 관찰자에게 알림, 이를 State와 연결해야 리컴포지션 동작
리소스
다국어 지원
테마 및 스타일 대응
유지보수 효율성
- 앱 전체에서 공통으로 사용되는 단어를 리소스로 관리하면,
나중에 수정해야 할 때, 파일 한 곳만 고치면 됨
리소스 문자열
@Preview(locale="ko")와 같이 미리보기에서 언어 변경하여 확인 가능
리소스 이미지
- Color, Dimension, Integer 등도 리소스로 관리할 수 있음
7주차-액티비티와 인텐트
액티비티(Activity)
-
앱 구성 요소, 사용자와 상호작용할 수 있는 화면 제공
-
안드로이드 앱 구성 요소
액티비티, 서비스, 브로드캐스트 리시버, 컨텐트 프로바이더 -
앱의 시작은 보통 액티비티에서
-
앱에는 2개 이상의 액티비티가 포함될 수 있음
Compose UI에서는 한 액티비티에서 컴포저블을 이용해서
여러 화면을 구성하고, 화면 전환을 하는 것이 일반적임 -
액티비티는 ComponentActivity를 상속하여 만듦
-
Compose UI인 경우 ComponentActivity를 상속
-
Android View 시스템에서는 Activity나 AppCompatActivity를 상속
API 호환성을 높이기 위해 AppCompatActivity 사용 권장
액티비티(Activity) 사용-메소드 오버라이드
라이프 사이클 콜백
- onCreate, onStart, onResume, onPause, onStop, onDestroy
- 현재 액티비티의 상태를 알고, 해당 상태에 맞는 동작을 위해 사용
액티비티 라이프 사이클
onCreate → onStart → onResume
→ 액티비티 활성화 →
onPause → onStop → onDestroy
액티비티 전환 시 라이프 사이클 콜백
MainActivity에서 SecondActivity 시작
1) MainActivity의 onPause()
2) SecondActivity의 onCreate → onStart() → onResume()
3) MainActivity의 onStop()
단말기의 뒤로가기 버튼 누름
1) SecondActivity의 onPause()
2) MainActivity의 onRestart() → onStart() → onResume()
3) SecondActivity의 onStart() → onDestroy()
화면을 회전시켜 액티비티 보기 방향 바꾸기
onPause() → onStop() → onDestroy()
→ onCreate() → onStart() → onResume()
인텐트(Intent)
- 일종의 메시지 객체
- 다른 앱 구성 요소에 Intent를 보내 작업을 요청
- 기본적인 사용 사례
1) 액티비티 시작하기
2) 서비스 시작하기
3) 브로드캐스트 전달하기
인텐트로 액티비티 시작하기
startActivity(Intent(this, SecondActivity::class.java))-
시작하려는 액티비티(SecondActivity.class)를 지정하고 Intent 생성
이렇게 명시적으로 액티비티 클래스를 지정하는 것을 명시적 인텐트라고 함 -
startActivity()에 인텐트 객체를 인자로 해서 호출
val context = LocalContext.current
val intent = Intent(context, SecondaActivity::class.java)
context.startActivity(intent)- Composable에서는 LocalContext에서 context를 가져와서 사용
LocalContext: 현재 사용 가능한 context를 알려줌
인텐트 유형
명시적(explicit) 인텐트
- 시작할 구성 요소의 이름을 지정
위의 두 코드 모두 명시적 인텐트
암시적(implicit) 인텐트
- 이름을 지정하지 않고 일반적인 작업(전화걸기, 지도보기 등)을 지정
ViewModel과 SavedStateHandle
- 시스템이 메모리가 부족할 때, 우선순위가 낮은 앱의 프로세스를 종료하며 이때 ViewModel은 메모리에서 사라짐
- 앱이 다시 시작할 때
SavedStateHandle을 사용하면 시스템이 보존해둔
Saved State 번들에서 데이터를 복구할 수 있음
class MyViewModel(private val savedStateHandle: SavedStateHandle) : ViewModel() {
private val COUNT_KEY = "count"
// SavedStateHandle에서 값을 가져오거나 기본값 설정
// StateFlow로 변환하여 Compose에서 관찰 가능하게 만듦
val countStateFlow: StateFlow<Int> = savedStateHandle.getStateFlow(COUNT_KEY, 0)
fun increaseCount() {
val currentCount = savedStateHandle.get<Int>(COUNT_KEY) ?: 0
savedStateHandle[COUNT_KEY] = currentCount + 1
}
}