
💡 LeetCode 79:
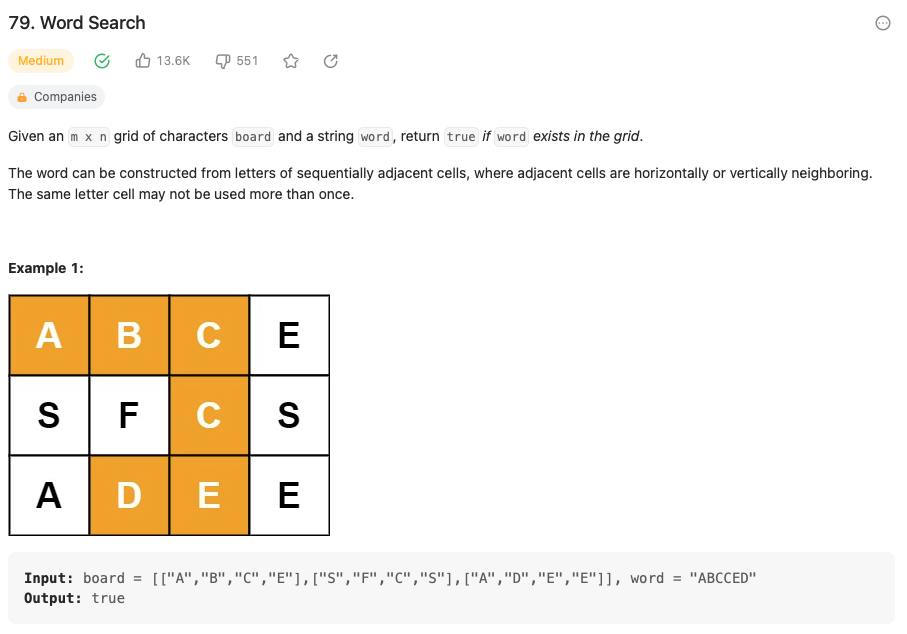
주어진 board 배열에서 주어진 word를 연속된 문자로 찾는 것이 가능한지 탐색
🌱 코드 in Python
알고리즘: DFS
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
dx = [1, 0, -1, 0]
dy = [0, 1, 0, -1]
w, h, l = len(board[0]), len(board), len(word)
visit = [[0 for _ in range(w)] for _ in range(h)]
def dfs(cx, cy, c, idx):
if c != word[idx]:
return False
if idx == l - 1:
return True
for x, y in zip(dx, dy):
nx, ny = cx + x, cy + y
if 0 <= nx and nx < w and 0 <= ny and ny < h and visit[ny][nx] == 0 and idx < l - 1:
visit[ny][nx] = 1
if (dfs(nx, ny, board[ny][nx], idx + 1)):
return True
visit[ny][nx] = 0
count = Counter(sum(board, []))
if count[word[0]] > count[word[-1]]:
word = word[::-1]
for i in range(h):
for j in range(w):
if board[i][j] == word[0]:
visit[i][j] = 1
if (dfs(j, i, board[i][j], 0)):
return True
visit[i][j] = 0
return False인덱스 숫자를 두고 word의 해당 인덱스와 board의 문자가 같은지를 비교한다.
상하좌우를 전부 탐색하며 문자가 같지 않을 경우 해당 depth의 탐색을 종료한다.
사실 원래는
count = Counter(sum(board, []))
if count[word[0]] > count[word[-1]]:
word = word[::-1] 요부분 코드가 없었다. 이 코드를 넣은 이유는

속도가 스레기였기 때문입니다.
그래서 찾아보니 저렇게 주어진 문자열을 아예 뒤집어서 탐색하는 방법이 있었다.
이런 생각 어케하지 진짜..
나도 이런 참신한 발상을 떠올릴 수 있는 사람이었으면 좋겠다.
저렇게 할 경우 탐색 횟수를 획기적으로 줄일 수 있는 것이었다.

그렇게하면 이렇게 속도가 확!! 빨라진다.
그리고 여기서 또 알아봐야 할 것 sum(board, []) 의 활용!
이렇게 하면 2차원 배열의 board가 1차원 배열로 변경 가능해진다.
sum함수는 첫번째 인자로 iterable한 객체를 받고, 두번째 인자로 초기값을 갖는다.
두번째 인자는 옵셔널하며, 기본값은 0이다.
지금의 경우 board라는 2차원 배열이 []를 초기값으로 하여 하나의 리스트로 합쳐지는 것이다.
다양한 예시는 chat GPT에게 물어보세요!
그런데 카운트를 사용하면서 메모리를 0.2mb 더 잡아먹게 됐다.
메모리 자체로는 나쁘지 않은데 beats가 나를 가슴아프게 해...
그래서 또 찾아본 방법!
def exist(self, board: List[List[str]], word: str) -> bool:
dx = [1, 0, -1, 0]
dy = [0, 1, 0, -1]
w, h, l = len(board[0]), len(board), len(word)
def dfs(cx, cy, c, idx, visit):
if c != word[idx]:
return False
if idx == l - 1:
return True
visit.add((cy, cx))
for x, y in zip(dx, dy):
nx, ny = cx + x, cy + y
if 0 <= nx and nx < w and 0 <= ny and ny < h and (ny, nx) not in visit and idx < l - 1:
if (dfs(nx, ny, board[ny][nx], idx + 1, visit.copy())):
return True
count = Counter(sum(board, []))
if count[word[0]] > count[word[-1]]:
word = word[::-1]
for i in range(h):
for j in range(w):
if board[i][j] == word[0]:
visit = set()
if (dfs(j, i, board[i][j], 0, visit)):
return True
return False요렇게 방문 배열이 아니라 set을 활용하는 방법이 있었다!
오 정말 다들 배운 사람들이야

그럼 요렇게 속도는 좀 안좋아졌지만 메모리 사용률이 0.1mb 준다 ^_^
구냥 방문배열 처리가 나은 것 같기도 하다 ㅋㅋ
🧠 기억하자
- 속도를 줄일 수 있는 방법 생각해보기.
- 원본 문자열을 뒤집을 생각하다니!
