탐색의 속도에 대해
탐색을 지원하는 집합을 구현하는 방법에는 여러가지가 존재한다. 그리고 그것들의 시간복잡도는 다음과 같다.
-
배열
- 최악의 경우 O(n)
-
이진 탐색 트리
- 평균 O(log n), 최악의 경우엔 O(n)
-
Red-Black 트리
- 최악의 경우에도 O(log n)
-
B-트리
- 최악의 경우에도 O(log n)
O(log n)보다 더 빠르게 풀 수 있을까?
-
분명 O(log n)안에 문제를 풀 수 있다면 아주 빨리 푸는 것이다.
간단하게만 생각해보면, 데이터 개에서 특정 데이터 1개를 찾는데 수행하는 연산의 수가 64번 밖에 안된다는 의미이다. -
하지만 64번도 아닌 1번만 연산하면 된다면?
-
그 방법에 대해서 알아보자.
아주 단순한 해결 방법
당신이 학교의 도서관을 운영해본다고 해보자.
학교의 학생이 400명이라고 가정했을 때, 도서관의 자리를 400자리를 만들면 모든 학생들이 쾌적하게 사용할 수 있을 것이다.
위 도서관의 예시에서 아이디어를 얻어, 1~N사이의 수 k개가 원소인 집합을 다음과 같이 구현할 수 있다.
-
길이가 k인 배열 A를 선언한다.
-
수 i가 집합의 원소라면 A[i] = 1, 아니라면 A[i] = 0
- 삽입 O(1) 시간
- (A[i] = 1;)
- 삭제 O(1) 시간
- (A[i] = 0;)
- 검색 O(1) 시간
- (return A[i];)
위 방법은 1~N 사이의 수가 아주 알뜰살뜰하게 꽉 차있으면 효율적인 방법이 될 것이다. 그런데…
- 삽입 O(1) 시간
**There’s No Such Thing as a Free Lunch.
(공짜 점심은 없다.)**
위의 예시처럼 원소의 개수가 적고, 집합의 원소가 될 수 있는 후보군이 아주 많을 때(N이 클 때) 문제가 발생한다.
위의 아이디어의 단점은 보완하고 장점을 착안한 자료 구조가 바로 해시 테이블이다.
해시 함수란?
해시 테이블을 알기 전에 해시 함수라고 불리는 함수에 대해 알아보자.
우리가 일상에서 자주 접하는 대형 웹사이트(구글, 네이버, 카카오, 쿠팡 등)에 로그인 하기 위해서는 비밀번호를 입력해야 한다.
그런데, 비밀번호는 보안유지를 해야하기 때문에 Raw하게(생으로) 저장하면 안된다. 그때 사용하는 함수가 해시 함수이다.
String hash_Function(String s){
String ret = Make_String_Hard_To_Read(s)
return ret
}로그인 과정은 위와 같은 함수로 만든 새로운 문자열을 저장공간에 저장한 뒤, 사용자가 로그인을 시도할 때 입력하는 문자열을 다시 해시 함수에 넣어 원래 저장되어 있던 문자열과 비교하는 과정이다.
해시 테이블
해시 테이블은 도서관 자리 아이디어와 해시 함수 아이디어를 병합하여 고안한 자료구조이다.
원소가 저장될 자리가 원소의 값에 의해 아주 빠르게(상수 시간만큼) 결정되는 자료구조
사족이 너무 길었으므로 바로 예시를 확인하자.
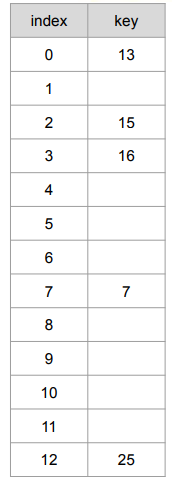
삽입 방법
탐색 방법
아이디어는 다음과 같다.
- 해시 함수를 이용해서 원소가 저장될 위치를 결정함!
- 보통 해시 함수는
의 꼴이다. - 이 때, p는 소수로, 해시 테이블의 크기와 일치한다.
해시 테이블에 집합 {25, 13, 16, 15, 7}을 저장하는 예시
- 먼저 25를 저장해보자.
- 25 mod 13 = 12, 12에 저장
- 13을 저장해보자.
- 13 mod 13 = 0, 0에 저장
- 16을 저장해보자.
- 16 mod 13 = 3, 3에 저장
- 이런식으로 진행하면 된다.
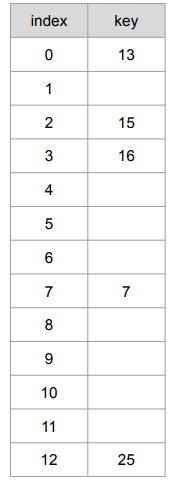
해시 테이블에서 특정한 값을 탐색하는 과정을 알아보자.
아이디어
- 의 결과값(인덱스)에 를 넣었으니 찾을 때도 해당 인덱스에 방문한다.
예시
- 16이 들어있는지 확인하려면…
- , 3번째 인덱스에 방문하여 16이 있는지 확인한다.
- 29가 들어있는지 확인하려면…
- , 3번째 인덱스에 방문하여 29가 있는지 확인한다.
- 29가 없으니 집합에 29라는 숫자는 없는 것!
충돌!
위 탐색 예시에서 원소 29를 삽입한다고 생각해보자.
-
, 3번째 인덱스에 원소 29를 삽입하면 된다.
-
그런데 이미 3번째 인덱스는 16이라는 원소가 존재한다.
-
이 경우를 해시 테이블에서의 충돌(Collision)이라고 칭한다.
충돌을 관리해주지 않는다면 자료구조로서 활용할 수 없으니 충돌을 관리하는 법을 알아보자.
충돌 관리 - 해시 체인
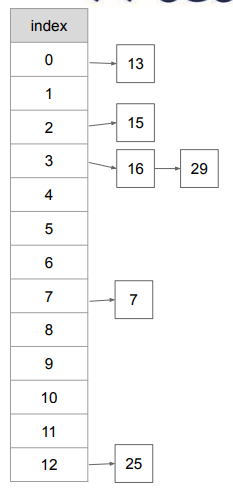
아이디어
- 원소를 삽입할 때, 만약 해당 인덱스에 원소가 존재한다면…(충돌 발생)
- 연결 리스트 형태로 원소를 뒤이어 붙인다.
한계
- 해시 함수의 반환값이 3인 원소가 계속 삽입된다고 가정해보자.
- 원래 해시 테이블의 길이인 13보다 더 큰 연결 리스트가 발생할 수 있다.
- 해시 테이블을 사용하는 이유가 빠른 탐색, 삽입, 삭제 때문인데 그렇게 된다면 해시 테이블의 사용 이유를 잃게 된다.
충돌 관리 - 선형 조사
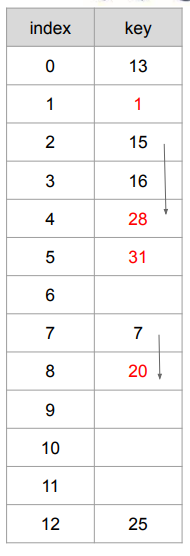
28, 31, 20, 1, 38을 추가한 모습
충돌 관리 - 이차원 조사
아이디어 (선형 조사)
- 충돌이 발생한 경우 해당 인덱스에 저장하는 것이 아닌 다음 인덱스에 저장하는 방식
- 만약 그 다음칸도 충돌이 일어난다면?
- 비어있는 칸이 나올때까지 반복한다.
한계 (일차 군집)
- 선형 조사로 충돌을 관리하게 되면 특정 영역에 원소들이 몰리게 되는데, 이를 일차 군집이라 칭한다.
- 일차 군집이 발생하게 되면 원하는 값을 탐색할 때 전혀 관련없는 값을 읽고 비교하게 된다. (그것도 아주 많이!)
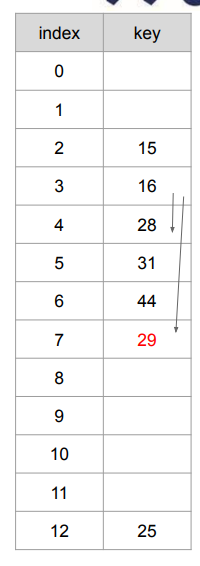
29를 추가한 모습
아이디어
- 일차 군집(값들이 한 곳에 몰리는 것)을 피하기 위해 해시 함수를 다음과 같이 변경한다.
- 저장하려는 인덱스가 비어있지 않는 경우 빈칸이 나올 때까지 칸 씩 이동한다.
예시
왼쪽 표에 29를 넣는 경우
- 29 mod 13 = 3 → 16이 차지 중
- 1칸 → 28이 차지 중
- 4칸 → 7번째 인덱스 → 삽입!
한계
- 삽입하려는 원소 가 만약 라면, 움직이는 칸 수가 같아 계속 충돌이 발생한다.
- 28, 41, 54, 67을 넣는다고 생각해보자.
충돌 관리 - 이중 해싱
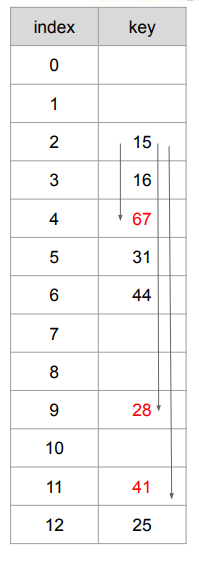
아이디어
- 이차 군집을 막기 위해, 똑같은 칸(1,4,9,…)을 이동하는 대신 또 다른 해시 함수를 사용
이 때, 11과 13(m)은 서로소이다.
예시
- 좌측 표에서 빨간색으로 표시된 수를 28, 41, 67 순으로 삽입해보자.
- 28 삽입
- .
- 따라서 2번째 인덱스로부터 7칸 떨어진 9번째 인덱스에 저장됨.
- 41 삽입
- .
- 따라서 2번째 인덱스로부터 9칸 떨어진 11번째 인덱스에 저장됨.
- 67 삽입
- .
- 따라서 2번째 인덱스로부터 2칸 떨어진 4번째 인덱스에 저장됨.
삭제
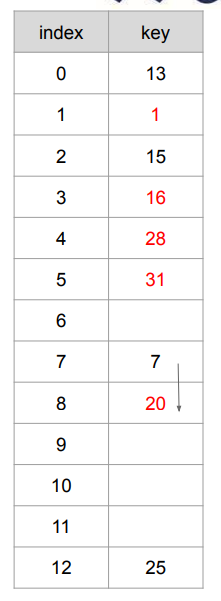
- 해시 테이블에 있는 원소를 삭제할 때, 단순히 삭제하면 다음과 같은 문제가 발생한다.
- 3번 칸에 있는 16을 지운다고 가정.
- 16을 삭제한 뒤, 28을 탐색할려고 하면 3번째 칸이 비어있는 값이기 때문에 28이 없다고 판단.
해결 방법
- 단순히 원소를 삭제할 때, 원소를 없애는 것이 아닌 DELETED 라고 표시.
- DELETTED 인 경우 값을 쓸 수 있으며, 탐색 시에는 다음 값으로 진행 할 수 있다.
다양한 문제들
위 예시에서 알아봤듯이, 군집이라는 것은 설계 방법에 따라 피할 수 있다.
허나 삽입하는 원소가 해시 테이블의 크기에 가까워진다면?
→ 어떤 방식으로 설계하든 군집이 발생할 확률이 늘어난다.
따라서 적재율 이라는 개념을 도입하여 군집의 발생 확률을 줄이고자 한다.
적재율
은 저장된 원소의 개수이며, 은 해시 테이블의 크기이다.
위 정의에 따르면 평균적으로 해시 테이블의 한 원소(해시 값)에는 만큼의 원소가 있다고 생각할 수 있다. (자연스러운 생각은 아니나, 수학적으로 그렇다!)
만약, 라면, 일차 군집이 발생할 확률이 높다. (비둘기집 원리)
그렇다면 이를 어떻게 해결할 수 있을까?
- 해시 테이블의 크기를 두 배로 늘린다.
- 안에 있던 값들은 해시 테이블의 크기가 새로 정의되었으니 새로운 해시 함수를 이용해 다시 만든다.
탐색의 끝은 어떻게 인지하는가?
해시 테이블 안에 존재하지 않는 어떤 값을 탐색할 때, 알고리즘이 끝나는 조건은 무엇일까?
- 해시 테이블에서의 탐색은…
- 접근한 인덱스에 원하는 데이터가 있다면 존재하는 것이다.
- 접근한 인덱스에 원하는 데이터가 아닌 다른 데이터가 있다면 다음 인덱스를 조사한다.
- 접근한 인덱스에 값이 비어있다면, 존재하지 않는 것이다.
허나, 군집이 발생하여 탐색의 종료가 애매해지는 경우가 있다. 그럴 때 종료 조건을 고려해보자.
군집이 발생하는 경우(적재율이 높은 경우) 탐색의 종료를 알 수 없는 케이스(무한 루프)가 발생한다.
그러므로 군집의 발생을 최소화 시켜야 한다.
