1. 세 가지 집계 방법론과 효율성
mongodb에서 도큐먼트를 집계(평균, 합계 등등)하는 방법은 크게 세가지가 있다.
1. 데이터 베이스의 정보를 불러와 애플리케이션 단계에서 집계하는 방법
2. MongoDB의 맵-리듀스 기능을 이용하는 방법
3. MongoDB의 집계 파이프라인 기능을 이용하는 방법
또한 집계명령을 수행할 경우 원본 데이터 보다 결과 데이터 양이 더 적다. 따라서 집계 연산을 데이터 처리 초기 단계에서 할수록 속도면에서 유리한 점이 있다.
처리 속도 면에서 보자면 집계파이프 라인 > 맵-리듀스 방식 > 애플리케이션 순으로 볼 수있다.
데이터를 어떻게 가공할지 자유도를 살펴보면 정반대의 결과를 얻는다.
애플리케이션 > 맵 - 리듀스 > 집계파이프 라인 순의 자유도를 가진다.
2. 인덱스
보통 자료를 저장하거나 분류할때 색인을 하게된다. 만약 이러한 색인이 없다면 모든 자료를 일일이 찾아아가야 하기 때문에 읽기 작업에서의 시간이 오래 걸리게 된다.
DB 또한 마찬가지다. 쿼리를 수행할 때 인덱스가 없다면 모든 도큐먼트를 일일이 조회해야 한다.
그러나 인덱스를 만들면 도큐먼트 생성 및 수정 시 마다 인덱스를 업데이트 해줘야 하기에 속도 저하가 있다.
정리
1. 인덱스는 쿼리 작업을 매우 효율적으로 만든다.
2. 인덱스를 만들면 도큐먼트 생성 수정 시 속도 저하가 생긴다. (그러나 읽기 성능 향상폭이 더 크기 때문에 사용한다.)
3. 다수의 필드를 대상으로 조회를 할 때는 복합 인덱스(ex/ 제목-사전순)가 유용하다.
4. a-b 복합 인덱스는 a 단순 인덱스와 같은 기능을 할 수 있다.
3. 복제 세트 이해하기
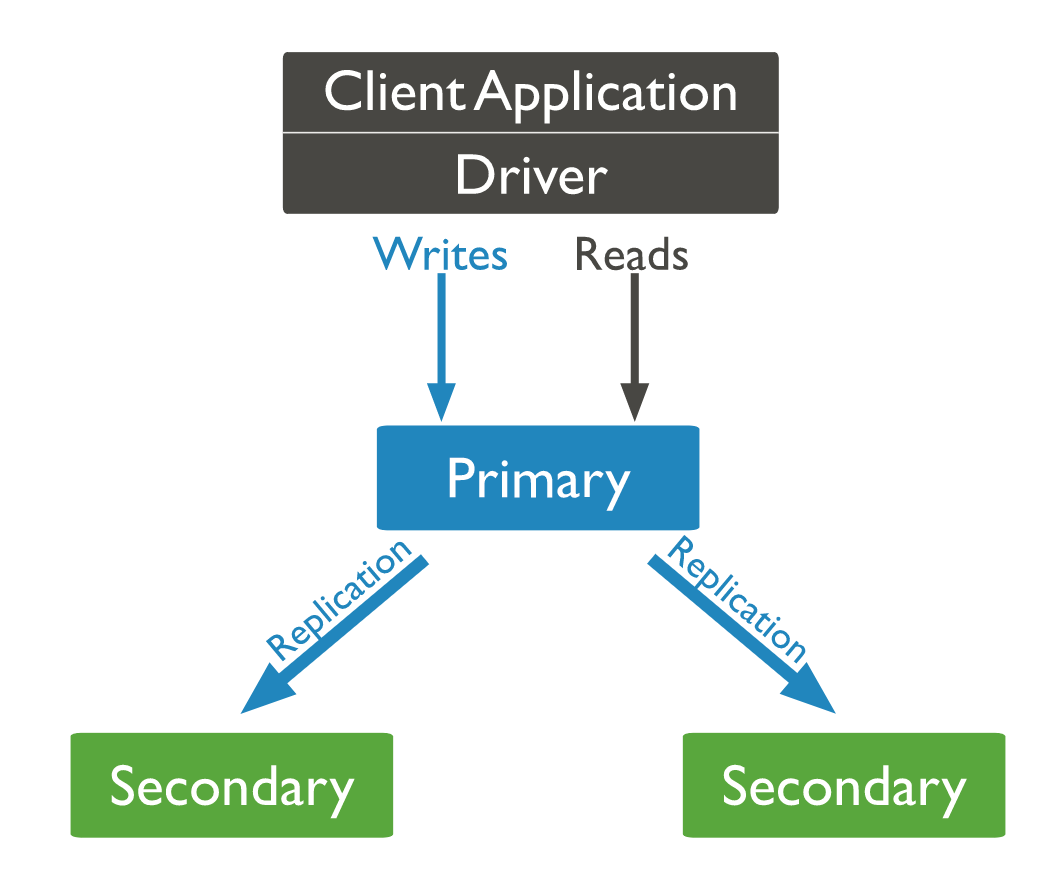
구성
복제 세트는 같은 정보를 공유하는 Data Set 이다.
복제 세트는 primary, secondary, aviter로 구성되어있는데 각각의 역할은 다음과 같다.
또한 일정 시간마다 heartbeat를 통해 서로의 상태를 확인한다.
1. primary : client의 CRUD요청을 직접적으로 받아 들이고 처리한다.
2. secondary : primary가 바뀌면 그대로 따라서 바뀐다.
3. aviter : 선거에서 투표를 하기위해 존재한다.
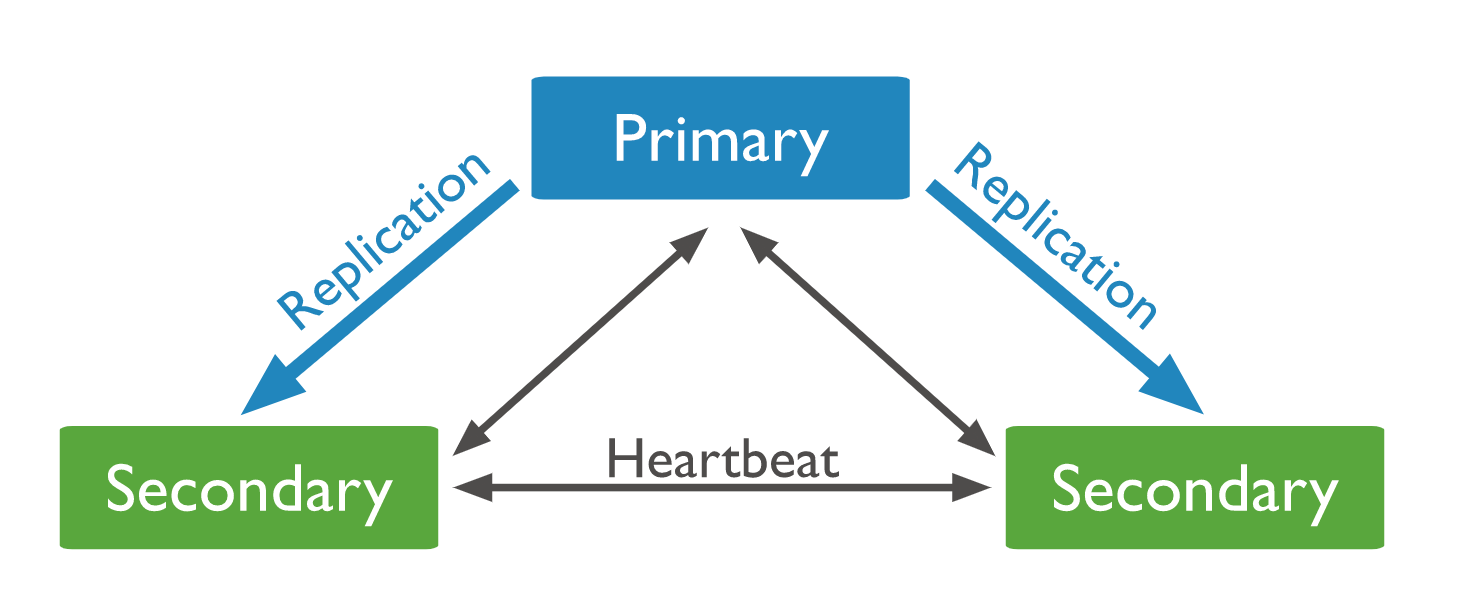
복제의 이유
- 높은 가용성을 위해서.(primary가 연결이 끊어지거나 하는 불상사 방지)
- 정보의 안전한 보호를 위해서
- READ 속도를 빠르게 하기 위해서(아닐 경우도 있음)
복제 세트의 선거
-
프라이머리가 무슨 이유에서든지 죽게 되면, 복제 세트 구성원 중 과반수의 세컨더리가 이를 감지하여 선거를 개최한다.
-
세컨더리와 아비터는 새로운 프라이머리를 뽑는 투표를 하게 된다. 우선 순위가 높은 순서대로 세컨더리는 후보가 되고, 과반수의 찬성표를 받은 세컨더리는 프라이머리가 된다.
-
별 문제가 없다면 찬성표를 던지지만 다음과 같은 경우는 반대표를 던진다.
ex) 프라이머리가 아직 정상 작동으로 생각되는경우, 후보 세컨더리 보다 더 최신의 데이터를 전달 받은 경우 등
4. Read-Concern 과 Write-Concern
Read-Concern 과 Write-Concern이 필요한 이유
복제 세트에서 구성원의 정보가 동기화 되는 데에는 필연적으로 시간이 필요하다.
Read-Concern : 어느 정도 동기화 수준을 기준으로 쓰기 작업을 마무리 할지를 설정한다.
Write-Concern : 어느 정도 동기화 수준을 기준으로 정보를 읽어올지 설정한다.
설정 예시
import pymongo
from pymongo.write_concern import WriteConcern
from pymongo.read_concern import ReadConcern
client = pymongo.MongoClient('localhost',27017)
db = client.get_database("student")
rc = ReadConcern(level = 'majority')
wc = WriteConcern(w=1, wtimeout = 200 , j = True)
col = db.get_collection("post", write_concern = wc, read_concern=rc)
Read-Concern설정
rc = ReadConcern(level = 'majority')- local : 연결된 인스턴스에서만 정보를 불러온다.
- majority : 복제 세트 대다수에 저장된 정보로 불러온다.
- linearizable : 시간 제한 내에서 복제 세트 구성원의 정보를 확인해서 대다수에 저장된 정보로 불러온다.
Write-Concern과 저널링
메모리에 정보를 저장하는 시간이 장기 저장 장치(HDD,SSD)에 저장하는 시간보다 훨씬 빠르다.
쓰기 작업은 메모리에 변경 사항을 남겼다가 일정 주기(50ms)로 디스크에 변경사항을 기록한다.
이처럼 디스크에 변경사항을 임시로 저장하는 작업을 저널링 이라고 한다.
wc = WriteConcern(w=1, wtimeout = 200 , j = True)| 필드 | 설명 |
|---|---|
| w | 복제 세트의 어느 정도의 구성원에 쓰기 작업이 완료되어야 전체 쓰기 작업이 완료되었다고 판단할지 결정하는 옵션, 숫자나 문자열로 지정가능 |
| j | 이 옵션이 True 값을 가지면 변경 사항을 바로 저널링해서 만약 장애가 발생하더라도 문제가 없게 만든다. 기본값은 False |
| wtimeout | w옵션에서 설정한 구성원들을 기다릴 수 있는 최대시간(ms). 주어진 시간이 지나도 정해진 구성원에 쓰기 작업이 마무리되지 않으면 에러를 반환하지만 이미 실행한 쓰기 작업자체는 취소되지 않는다. 쓰기 작업이 무한적 지연되는 것을 막기 위한 옵션으로 w값이 1보다 커야 사용할 수 있다. |
