1. 집합연산자
집합연산자(UNION, INTERSECT, EXCEPT)
집합연산자란 두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법이다.
테이블에서 select한 컬럼의 수와 각 컬럼의 데이터 타입이 테이블간 일치해야 오류가 나지 않는다.
UNION VS UNION ALL
- 기본적으로 합집합을 뜻한다고 생각하면 된다.
- union 의 경우 중복을 제거 하고 정렬된 형태로 보여주는 반면에
union all의 경우 중복을 제거하지 않고 정렬도 하지 않는다.
select name,email from class_a
union
select name,email from class_bINTERSECT
두 개의 테이블에서 겹치는 부분을 추출한다.(교집합)
추출 후에는 중복된 결과를 제거한다.
select name, email from class_a
intersect
select name, email from class_bEXCEPT(MINUS)
두 개의 테이블에서 겹치는 부분을 앞의 테이블에서 제외하여 추출한다.(차집합)
추출 후에는 중복된 결과를 제거한다.
select name, email from class_a
except
select name, email from class_b2. 계층형 질의
계층형 질의란 테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해 사용하는 것이다.
대표적인 데이터베이스로는 ORACLE, SQL SERVER가 있다.
계층형 질의 예시(oracle)
select level, 자식 column, 부모 column, 타겟 column
from 테이블 이름
start with 부모 column is NULL
-- 부모 컬럼이 NULL 인 행이 루트가 된다 --
connect by prior 자식 column = 부모 column
-- 상위 데이터와 하위 데이터의 연결 방식--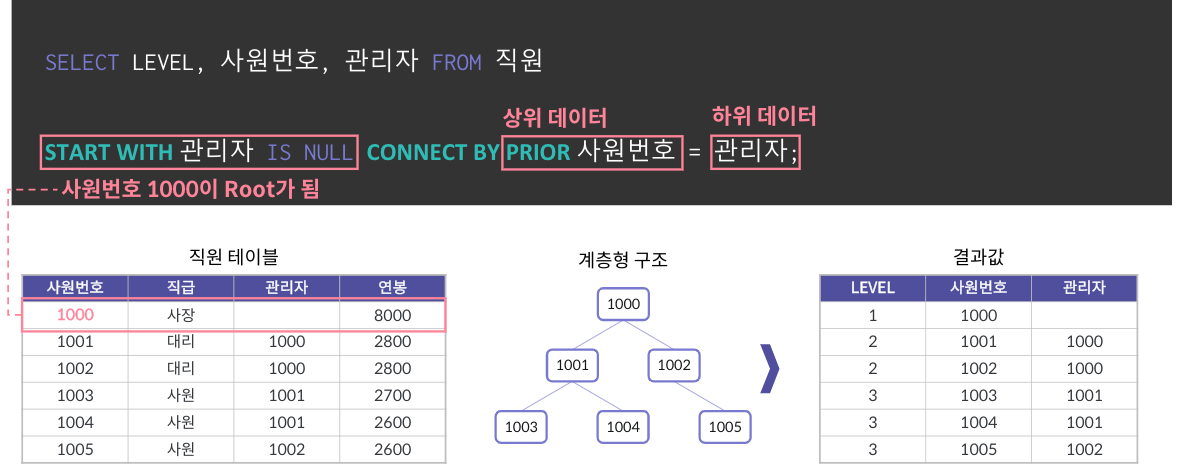
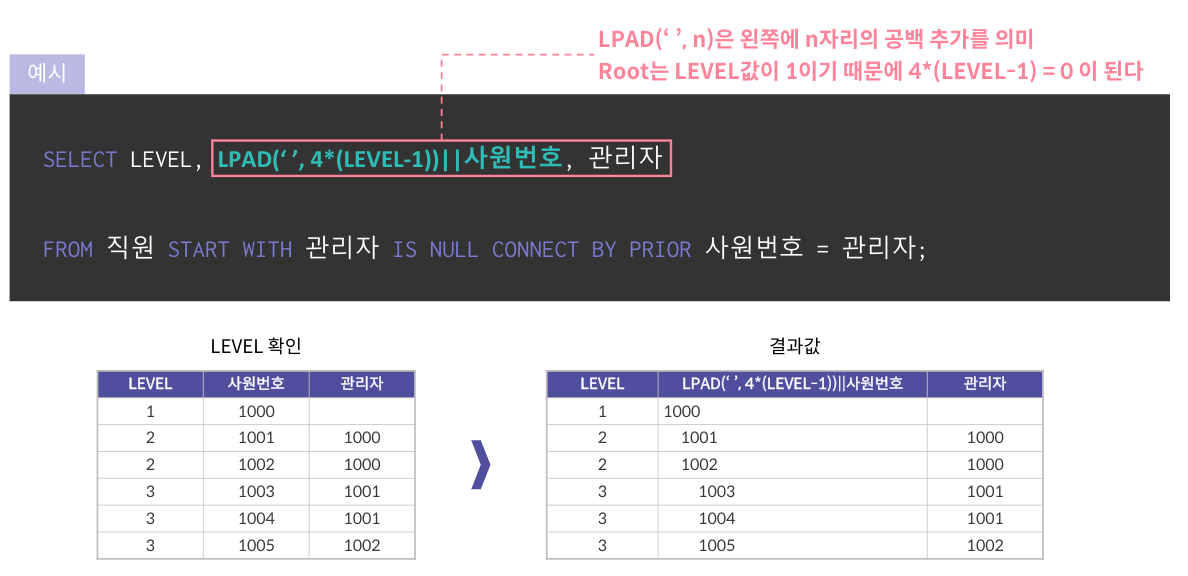
CONNECT BY 키워드(oracle)
- LEVEL : 검색 항목의 깊이를 의미하며, 계층구조에서 루트의 레벨이 1
- CONNECT_BY_ROOT : 현재 전개할 데이터의 루트 데이터 값 표시
- CONNECT_BY_ISLEAF : 현재 전개할 데이터가 리프(최하위) 데이터 인지에 대한 값 표시(0 or 1)
- SYS_CONNECT_BY_PATH(A,B) : 루트 데이터부터 현재까지 전개한 경로 표시(A:컬럼명, B:구분자)
계층형 질의 예시(MY SQL / MAIRA DB)
WITH REVURSIVE CTE(member_id, manager_id, lvl)
AS (
SELECT member_id, manager_id, 0 AS lvl
FROM MEMBER
WHERE manager_id IS NULL
UNION ALL
SELECT a.member_id, a.manager_id, b.lvl + 1
FROM MEMBER a
JOIN CTE AS b
ON a.manager_id = b.memeber_id
)
SELECT member_id, manager_id, lvl
FROM CTE
ORDER BY member_id, lvl;

웹 개발자로 활동하고 있습니다.