아키텍처란?
- Architecture : 건축물, 구조, 건축술..
- 전체 시스템의 밑그림
소프트웨어 아키텍처?
- 소프트웨어를 구성하는 구성요소(모듈 / 컴포넌트 등) 간의 관계를 관리하는 시스템의 구조이자
- 소프트웨어의 설계와 업그레이드를 통제하는 지침과 원칙이다.
- 계층형 아키텍처, 클린 아키텍처, 헥사고날 아키텍처 ...
우리가 제일 처음 프로젝트를 시작 하기에 앞서, 구성요소들을 어떠한 방법으로 조립할 것 이고, 어떠한 지침을 가지고 개발을 해 나갈 것인가를 정하는 규칙이다.
우리는 아키텍처를 사용하며 목표하는 최소한의 인력으로 최대한의 기능을 유지보수 할 수 있는 마법 같은 일을 해 낼 수 있다.
그렇다면 클린 아키텍처는?
소프트웨어가 가진 본연의 목적을 추구하려면 소프트웨어는 반드시 '부드러워'야 한다.
다시 말해 변경하기 쉬워야 한다.
이해관계자가 기능에 대한 생각을 바꾸면, 이러한 변경사항을 쉽게 적용할 수 있어야 한다. (이하 로버트 C. 마틴, 클린 아키텍처)
클린아키텍처는 이 부드러움을 최우선으로 보존하는 것을 목표로 한다.
부드러움이란 우리가 어떠 한 코드를 변경 하려고 할 때, 외부의 요인과 상관 없이 코드를 변경 할 수 있어야 하고, 이 말은 즉, Business Rule(업무규칙) 은 외부 요인에 의존하지 않는다는 말이다.
이게 무슨 의미일까?
여기서의 외부 요인은 클린 아키텍처에서 정의하는 저 수준의 정책으로 DB, UI, Frameworks 등을 말한다.
Business Rule 은 고 수준의 정책으로 실제 도메인 모듈의 주 기능을 말하고 저 수준 정책과 상관 없이 동작해야 함을 의미한다.
그래도 모르겠다?
간단하게 설명하면 이렇다(실제 구현은 간단하지 않겠지만)
우리가 자주 사용하는 Mysql 이 회사의 정책으로 인해 NoSql 로 변경된다고 생각해보자. 그렇다면 우리는 우리가 이미 만들어 놓았던 도메인의 주 기능 로직을 변경해야 할까?
클린아키텍처를 사용한다면 답은 "아니다" 이다.
우리가 작성해 놓은 로직은 DB 에 관한 어떠한 사실도 알고 있으면 안된다. 업무규칙인 도메인 로직은 DB 가 Mysql 이던 Nosql 이던 상관없이 정상적으로 작동해야만 한다.(아래에서 코드 예시를 보면 이해가 빠를 것이다)
그렇다면 어떻게 할 수 있을까?
관심사의 분리
모든 아키텍처들이 그렇듯, 클린 아키텍처에서 가장 중요하게 생각하는 메인 컨셉은 "관심사의 분리" 이다.
관심사의 분리란, DDD에서 각각의 도메인은 서로 다른 도메인에 대하여는 관심을 가져서도, 있어서도 안 되 듯이,
아키텍처에서는 목적을 달성하기 위해 시스템을 계층으로 구분하고, 저수준의 정책을 가진 하위 계층은 고수준의 정책을 가진 상위 계층에 대해 관심을 가져서도, 있어서도 안된다는 말이다.
쉽게 보자
클린 아키텍처의 모든 계층은 아래에서 설명 하겠지만, 우선 계층이 무엇인지 보자.
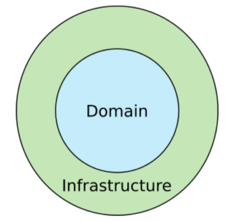
Domain 과 Infrastructre 라는 두개의 계층이 존재한다.
Domain 계층은 실제 우리가 원하는 목표를 실행하기 위한 로직이 존재하는 계층이다.
Infrastructre 계층은 Framework, DB, UI 등 외부적인 요소들에 대한 계층이다.
이런식으로 계층을 분리하게 된다면, Domain 계층은 목표를 실행하기 위한 로직만, Infrastructre 계층은 외부적인 요소들만 실행하는 목표를 이룸으로 써 각 계층간 목표하는 관심사가 분리 되어진다.
이렇게 두 계층이 존재한다고 가정할 때, 클린 아키텍처는
모든 소스코드 의존성은 반드시 outer에서 inner로, 고수준 정책을 향해야 한다
라는 정의를 통하여 두 관심사의 연결 방법을 제한 하였다.
여기서의 고수준은 원 안쪽으로 갈 수록 고수준, 저수준은 원 밖 으로 갈 수록 저수준이다.
Infrastructre 계층은 Domain 계층에만 의존성이 향해야 하고, 이말은 즉, Domain 계층은 Infrastructre을 의존하면 안된다는 말이다.
클린 아키텍처의 계층
클린 아키텍처의 가장 유명한 그림을 보자
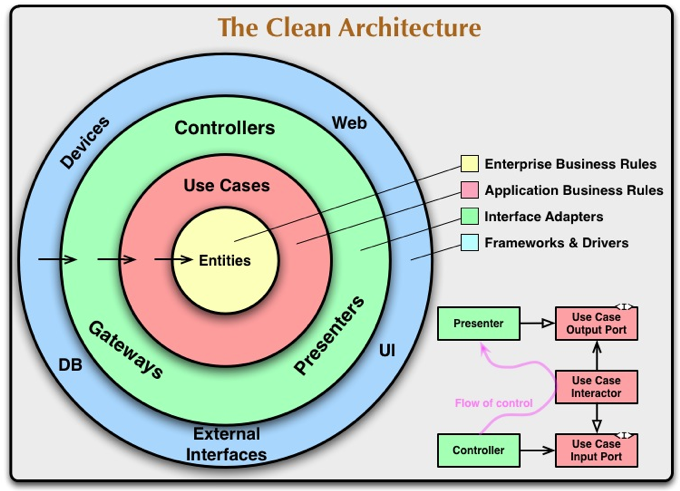
위 그림에서의 Domain 계층이 Entities 와 UseCase 로 분리되었고, Infrastructre 계층과 Domain 계층 사이에 Adapter 계층이 추가 되었다. 화살표로 표시된 의존성 표시는 밖에서 안으로, 저수준에서 고수준으로만 향한다.
고수준의 정책부터 하나씩 확인해 보자
Entity-Repository (Entities)
계속 말해왔던 업무 규칙 은 Domain 계층에 속해 있었고, Domain 계층은 Entities(Entity-Repository) 와 UseCase 로 구성되어 있다고 했다.
Domain 계층은 주 기능을 구현하는 계층이였고, 주 기능은 핵심 업무 규칙과(UseCase), 핵심 업무규칙이 사용 하는 핵심 업무 데이터(Entity-Repository) 로 나뉜다.
Entity-Repository 는 핵심 업무 규칙을 구체화 하고, 구현한 함수들로 구성 되어 있다.
<?php
namespace Core\Entities;
class User
{
private $id;
private $firstName;
private $lastName;
private $email;
public function __construct($id,$firstName,$lastName,$email)
{
$this->id=$id;
$this->firstName=$firstName;
$this->lastName=$lastName;
$this->email=$email;
}
public function getId()
{
return $this->id;
}
public function getFirstName()
{
return $this->firstName;
}
public function getLastName()
{
return $this->lastName;
}
public function getEmail()
{
return $this->email;
}
}<?php
namespace Persistence;
use Core\Application\Repository\UserRepositoryInterface;
use Core\Entities\User;
class UserRepository implements UserRepositoryInterface
{
private $database;
public function __construct(DatabaseInterface $database)
{
$this->database=$database->getInstance();
}
public function add(User $user): void
{
$this->database->insert('USER_TABLE', [
'id' => $user->getId(),
'firstName' => $user->getFirstName(),
'lastName' => $user->getLastName(),
'email' => $user->getEmail()
]);
}
public function find(string $id):User
{
$result=$this->database->select("USER_TABLE", "*", [
"id" => $id
]);
if($result==false) return None;
foreach($result as $item)
{
return new User($item['id'],$item['firstName'],$item['lastName'],$item['email']);
}
}
}UseCase
UseCase 는 시스템이 사용되는 방법을 설명한다. 사용자가 제공하는 입력, 사용자에게 보여줄 출력, 그리고 해당 출력을 생성하기 위한 처리 단계를 기술한다.(핵심 업무 규칙)
UseCase 는 Entity 내부의 구체화 된 핵심 업무 규칙을 언제, 어떻게 호출할지 정하고 제어하게 된다. 즉, UseCase 는 Entity 에 의존하고 있다.
업무 규칙은 사용자 인터페이스나 데이터베이스와 같은 저수준의 관심사로 인해 오염되어서는 안 되며, 시스템의 심장부에 위치해 있다.
덜 중요한 코드는 이 심장부에 플러그인되어야 하고, 업무 규칙은 시스템에서 가장 독립적이며 가장 많이 재사용 될 수 있는 코드여야 한다.
<?php
namespace Core\Application\Manager;
use Core\Entities\User;
use Core\Application\Repository\UserRepositoryInterface;
class UserManager
{
private $userRepository;
public function __construct(UserRepositoryInterface $userRepository){
$this->userRepository=$userRepository;
}
public function add(User $user): void
{
$this->userRepository->add($user);
}
public function find(string $id):User
{
return $this->userRepository->find($id);
}
}Adapter
Adapter 는 데이터를 UseCase 속으로 전달하기 위함이고, 반대로 UseCase 에서 외부 요소(DB, Web..) 등으로 전달하기 위한 계층이다. 가장 편리한 형식으로 계층간 데이터를 전달할 수 있도록 구성해야 하고, Adapter 속의 어떠한 코드도 외부 요소에 대해서 알아서는 안된다 (외부 요소 계층보다는 고수준의 정책)
우리가 알고 있고, 자주 사용하는 DTO, VO 등이 Adapter 계층에 해당한다고 보면 된다.
(코드 참조 https://github.com/sahbijabnouni/clean-architecture-php)
소프트웨어 아키텍처를 사용하는 관점
아키텍처는 구현과 측정을 통해 증명해야 하는 가설이다
-톰 길브(Tom Gilb)
아키텍처는 무언가를 확실하게 만드려고 할 때 사용하는 것이 아닌, 선택한 아키텍처에서 계속해서 탐구하고 증명하며 나아가는 여정이라고들 한다.
우리가 아키텍처를 무턱대고 따라한다고 해서 작성한 코드들의 퀄리티가 보장되거나, DDD 혹은 TDD 의 개념을 적용 할 수 있는 것은 절대 아니다.
스스로가 구조를 설계하고, 코드를 구현하면서 목표하고자 하였던 방향이 올바른 방향으로 나아가고 있는지 계속해서 확인하는 과정이 필요할 것이다. 기능에 목표를 두고 속도만을 우선시 해서 개발하다 보면 결국은 생산성은 0을 수렴하게 된다. 우리는 이러한 방향을 지양하며 좋은 아키텍처와 TDD 같은 생산성을 0으로 수렴하지 않도록 도와주는 방법을 지향해야 한다.
빨리 가는 유일한 방법은 제대로 가는 것이다.
(이하 로버트 C. 마틴, 클린 아키텍처)

질보고 갑니다