머신러닝과 컴퓨터비전
머신러닝이란 Data와 Output을 입력으로 줬을 때, Program이 나오는 것을 의미합니다.
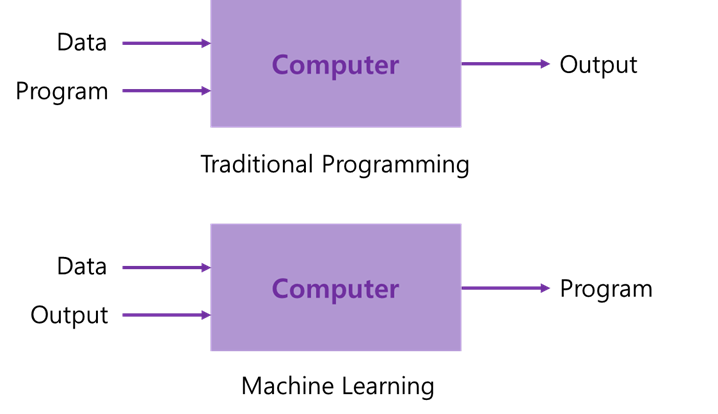
이러한 머신러닝을 컴퓨터비전 측면에서 활용해볼 수도 있습니다.
- 얼굴 인식
- Image Classification
- Object Detection
- Semantic Segmentation
- Instance Segmentation
머신러닝의 종류
Supervised Learning (지도학습)
Training Data에 Label이 포함되어 있을 때 학습 방법입니다.
따라서, 학습 시 성능이 좋지만 Label을 분류할 때 사람의 노동력을 필요로 합니다.
Unsupervised Learning (비지도학습)
Training Data에 Label이 포함되어 있지 않을 때 학습 방법입니다.
따라서, 영상만 수집해도 학습을 진행할 수 있습니다.
Semi-supervised Learning (준지도학습)
Supervised Learning와 Unsupervised Learning을 결합한 방식입니다. 일부만 Label이 존재합니다.
Reinforcement Learning (강화학습)
Supervised Learning
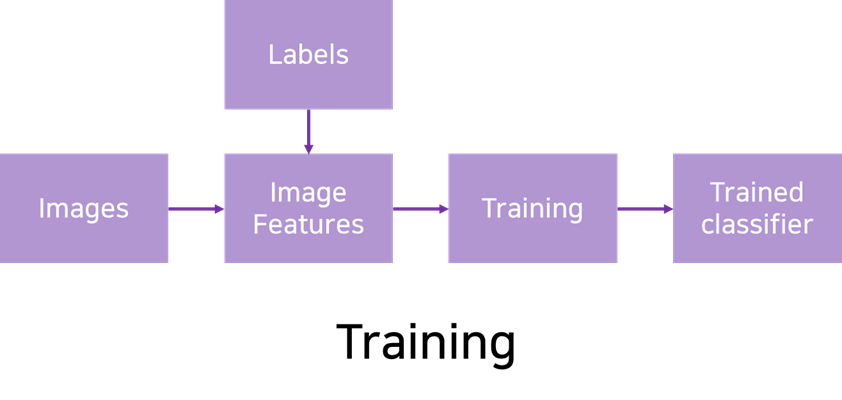
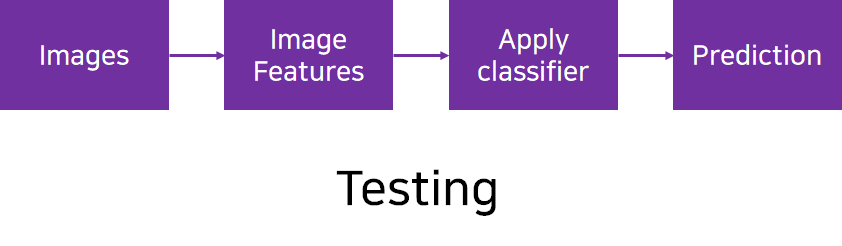
Testing을 진행할 때는 Training Dataset에 없는 이미지로 진행해야 합니다.
K-nearest neighbor classifier
K-nearest neighbor classifier란 근처에 있는 K개의 데이터를 바탕으로 분류하는 것을 의미합니다.
장점
- 간단합니다.
- 선형으로 분류할 필요가 없습니다.
- parameter가 필요하지 않습니다.
단점
- 좋은 거리계산 함수가 필요합니다.
- 거리를 계산해야 하므로 test시 연산이 필요합니다.
Linear classification
Linear classification란 선형(wx+b)으로 분류하는 것을 의미합니다.
장점
- 낮은 차원의 parameter로 표현이 가능합니다. (w,b)
- test시 빠릅니다.
단점
- linear function을 어떻게 학습시킬지 선택해야 합니다.
- 데이터가 선형으로 분류되지 않으면 사용할 수 없습니다.
Multilayer classifier
낮은 차원의 특징을 추출한 후, 높은 차원의 특징들을 만들어냅니다.
Unsupervised Learning
Clustering
Image에서 의미있거나 시각적으로 유사한 지역으로 구분합니다.
예) Image segmentation
K-means algorithm
point들을 가까운 cluster center에 반복적으로 할당해주는 방법입니다.
- K개의 cluster center를 랜덤으로 선택합니다.
- point를 가까운 cluster center의 값으로 할당합니다.
- 각 cluster의 평균을 계산하여 새로운 cluster center를 반환합니다.
- 2-3을 변화가 없을 때까지 반복합니다.
장점
- 간단합니다.
단점
- K의 값을 직접 지정해야 합니다.
- outlier에 민감합니다.
- local minima에 빠질 수 있습니다.
Mean shift segmentation
K-means algorithm의 발전된 기술입니다.
장점
- 성능이 좋습니다.
- region의 개수를 알고리즘이 결정합니다.
- outlier의 영향을 적게 받습니다.
단점
- Kernel size의 값을 직접 지정해야 합니다.
