Regularization
Overfitting이 발생할 때, model이 너무 복잡해지지 않도록 제약을 걸어 Overfitting을 줄입니다. Regularization은 적당히 큰 가설을 세운 후, 일반화 시키는 것이 목적입니다.
Overfitting(과적합)이란?
- input data의 noise까지 학습하여 일반화가 되지 않는 문제를 의미합니다.
- In-sample error에서는 낮은 값이 나오지만, Out-of sample은 큰 값이 나옵니다.
- model이 target보다 복잡할 때 발생합니다.
Regularizer
추가항을 도입하여 model에 제약을 겁니다. 손실함수에 regularizer를 도입합니다.
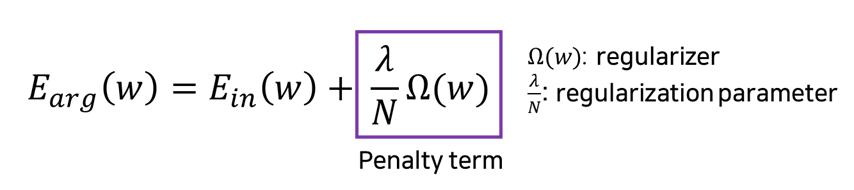
model의 복잡도를 측정하기 위해 ohm함수를 사용하고, 페널티에 가중치를 얼만큼 줄지로 를 사용합니다. 가 너무 작으면 overfitting이 발생할 수 있고, 너무 크면 underfitting이 발생할 수 있기 때문에 validation을 활용하여 적절한 값을 찾아야 합니다.
N은 학습데이터의 수로 과적합은 학습데이터의 수가 부족해서 발생하기 때문에 N이 크면, penalty term의 영향이 감소합니다.
bias를 Regularization할 경우, underfitting이 발생할 수 있으므로 가중치 만 Regularization을 진행합니다.
ohm함수를 어떻게 정의하느냐에 따라 regularizer가 달라집니다.
- l1, lasso
- l2, ridge (weight decay)
- elastic net
l1, lasso
ohm함수를 절대값으로 정의합니다.
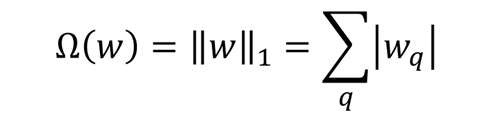
- 미분이 불가능 합니다.
- 변수의 크기를 줄일 수 있습니다. (variable shirinkage)
- 불필요한 가중치는 0으로 만들기 때문에 변수선택이 가능합니다.
l2, ridge (weight decay)
ohm함수를 제곱합으로 정의합니다.
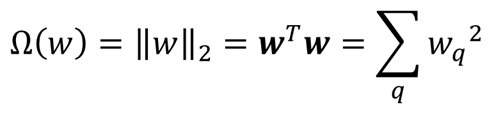
- 미분이 가능합니다.
- 변수의 크기를 줄일 수 있습니다. (variable shirinkage)
- 전체 가중치를 작게하여 모두 사용합니다. (선택하여 사용X)
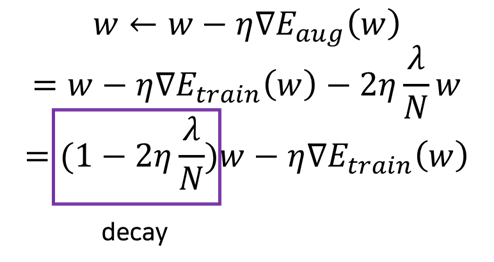
은 모두 양수이므로 decay는 항상 1보다 작은 값을 가진다. 따라서 기존의 를 감소시킨 채로 가중치 를 업데이트하게 된다.
elastic net
l1, l2를 조합한 것입니다.
- 변수 선택이 가능합니다.
- 모든 가중치를 조금씩 반영합니다.
Early stopping
Eval이 더이상 감소하지 않고 증가하면 학습을 멈춥니다. 즉, 과적합이 발생하기 전에 학습을 멈추는 것을 의미합니다. pocket algorithm과 비슷한 방식으로 동작합니다.
Early stopping의 장점
- 학습과정에서 변화없이 정규화됩니다.
- 학습이 일찍 종료되므로 연산이 감소됩니다.
- 남은 데이터로 model보완이 가능합니다.
Early stopping의 단점
- Eval을 추가로 계산해야합니다.
- 이전 단계 weight을 memory에 저장해야 합니다.
Ensemble Methods
여러 model들을 조합하여 새로운 model을 만든다.
bagging
복원추출 random sampling을 통해 k개의 dataset을 마련합니다. dataset으로 k번 학습을 진행하고 다수결의 원칙에 따라 통합합니다.
boosting
model을 연속해서 학습시킴으로써 분류능력을 키웁니다.
- 분류가 잘 되지 않았던 데이터에 대해서는 페널티를 크게 줍니다.
- Neural Network에서 layer를 추가합니다.
- layer에서 neuron을 추가합니다.
Dropout
output을 계산하는 forward pass에서 일부 neuron들을 확률 에 따라 값을 0으로 만든다. 이러한 방식을 반복하여 여러개의 model들을 만들고 이를 조합하여 하나의 model을 만듭니다. 조합시에는 를 사용하여 기댓값을 계산합니다.
Dropout의 장점
- 추가적인 항이 필요없이 확률만을 이용합니다.
- 계산이 간편합니다.
- 대부분의 model에서 적용가능한 방법입니다.
Dropout의 단점
- 처음에 설계한 neural network는 커야합니다.
- dataset이 작을 때는 사용할 필요가 없습니다.
Batch normalization
dropout방법을 사용하여 해결이 안될 경우 Batch normalization을 사용합니다
