📝시작하기전에...
저희는 지난 포스팅에서 지역특징을 검출하는 방법에 대해 알아보았습니다. 그러나 지역특징만으로 매칭하기에는 특징의 정보가 부족합니다. 따라서 특징의 성질을 기술해주는 특징기술자를 사용하여 더 많은 정보를 얻은 후 매칭을 합니다.
- 지역특징을 검출한다.
- 특징을 기술한다.👨🏫
- 특징을 매칭시킨다.👨🏫
이번 포스팅에서는 특징을 기술하는 방법과 매칭하는 방법에 대해 알아보도록 하겠습니다.
특징기술자
특징 검출기를 통해 영상에서 코너 등의 특징을 찾아낼 수 있습니다. 특징을 검출했다고 해서 바로 매칭이 이루어지는 것은 아닙니다. 매칭을 하기에는 아직 특징에 대한 정보가 부족하기 때문이죠. 이러한 문제를 해결해주는 것이 바로 특징기술자입니다. 특징기술자는 특징에 대한 정보를 벡터 형태의 특징벡터로 기술해줍니다. 특징 벡터를 사용하여 매칭을 할 수 있게 되는 것이죠.
SIFT기술자
SIFT (Scale Invariant Feature Transform)는 window를 4x4의 16개의 블록으로 분할하고 각 블록에서의 gradient 방향(8방향) 히스토그램을 구현합니다. 따라서 4x4x8=128차원의 특징벡터를 갖게 됩니다.
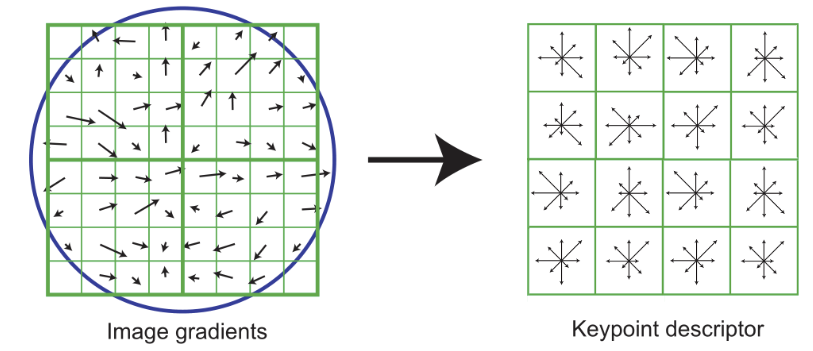
(출처: https://ai.stanford.edu/)
SIFT기술자 특징기술 과정
- 특징 근처의 16x16 window를 가져온다.
- 각 픽셀에서 gradient를 계산한다.
- gradient의 크기에 Gaussian function을 곱합니다.
- 16x16을 4x4의 영역으로 나누고 graient의 크기와 방향을 사용하여 히스토그램(8방향)을 만듭니다.(4x4x8=128차원의 벡터)
- 128차원 벡터를 unit length로 normalize합니다.
- threshold보다 작은 값은 0으로 만듭니다.
- 128-D vector로 Re-normalize합니다.
특징 매칭하기
특징기술자를 사용하여 특징 주변의 충분한 정보를 얻었으니 이제 두 영상의 특징들을 비교하여 매칭해야 합니다.
특징 매칭을 하기 위해서는 다음 과정이 필요합니다.
- 두 영상에서 구한 특징을 비교할 거리함수를 정의한다.
- 거리함수의 값을 비교하여 거리가 가장 짧은 것이 대응되는 특징이다.
Euclidean distance
Euclidean distance는 SSD에 root를 씌운 형태입니다. 따라서 SSD와 값의 크기만 다를뿐 같은 결과를 도출해냅니다.
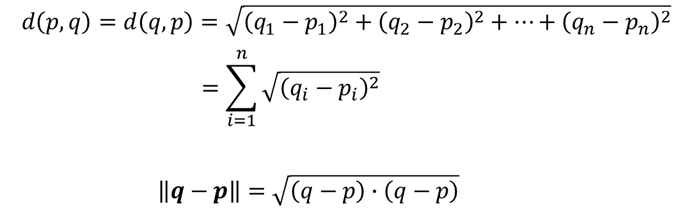
두 벡터를 Euclidean distance를 사용하여 거리를 계산하고 가장 짧은 거리의 Featrue가 매칭이 됩니다. 그러나 Euclidean distance를 사용하면 모호한 match에 대해서도 거리가 짧게 나올 수 있습니다. 따라서 새로운 거리함수를 정의해야 합니다.
Distance Ratio
Distance Ratio는 두 영상에서 가장 가까운 특징과 두번째로 가까운 특징을 비교합니다.
(SSD대신 Euclidean distance를 사용해도 됩니다.)
best SSD와 2nd bestSSD가 비슷하다면, 일 것입니다. 그러나 2nd bestSSD가 bestSSD에 비해 훨씬 크다면 일 것입니다.
즉, Distance Ratio가 0에 가까울 수록 높은 신뢰도를 가지고 Distance Ratio가 클수록 모호한 match임을 의미합니다.
2nd bestSSD가 bestSSD보다 항상 크기 때문에,
Distance Ratio의 값은 1을 넘지 않습니다.
모호한 매치를 제거하기 위해 Distance Ratio가 threshold보다 크면 매칭을 하지 않는 방법도 있습니다. 이때, threshold ratio는 trade-off이므로 적당한 값을 선택해야 합니다.
Distance Ratio의 과정
- 첫 번째 이미지의 모든 특징에 대해 두 번째 이미지의 모든 특징과의 SSD를 구합니다.
- 그 중에서 가장 짧은 거리와 두번째로 짧은 거리를 찾습니다.
- output의 첫번째 열에는 가장 가까운 코너의 index를 저장합니다.
- output의 두번째 열에는 distance ratio를 저장합니다.
