카프카 프로듀서&컨슈머
acks 옵션
-
0,1,all(또는 -1) 값을 가질 수 있다.
-
프로듀서가 전송한 데이터가 카프카 클러스터에 얼마나 신뢰성 높게 저장할 지 지정하는것
-
카프카 복제 개수가 2 이상으로 운영하는 경우에만 의미가 있다.(1인경우 성능차이가 없음)
-
acks=0
-
프로듀서가
리더 파티션으로 데이터를 전송했을때 리더 파티션으로 데이터가 저장되었는지 확인하지 않겠다는 의미 -
프로듀서가 데이터를 전송한 후 이 데이터가 몇 번째 오프셋에 저장되었는지 확인할 수 없음
-
전송이 실패한 경우를 알 수 없기 때문에 재시도 옵션인 retries도 의미가 없음
-
데이터 전송 속도는 1,all 경우보다 훨씬 빠르다.
데이터 유실이 발생하더라도 전송 속도가 중요한 경우에 사용
-
-
acks=1
- 프로듀서는 보낸 데이터가 리더 파티션에만
정상적으로 적재되었는지 확인 - 리더 파티션에 데이터가 적재될 때까지 기다린 뒤 응답 값을 받기 때문에 acks=0에 비해서
전송 속도가 느림 - 복제 개수를 2 이상으로 운영하는 경우 리더 파티션에는 적재되었지만 아직 팔로워 파티션에는 데이터가 동기화되지 않는 경우, 동기화 과정에서 리더 파티션에 브로커 장애가 발생시 일부 동기화 되지 못한 데이터가 유실될 수 있기에
데이터는 유실될 수 있음
- 프로듀서는 보낸 데이터가 리더 파티션에만
-
acks=all 또는 acks=-1
- 프로듀서는 보낸 데이터가 리더 파티션에과 팔로워 파티션 모두
정상적으로 적재되었는지 확인 - 당연히 모두 적재되었는지 확인하기 때문에 0,1 옵션보다도 속도가 느리다
일부 브로커 장애가 발생하더라도 프로듀서는 안전하게 데이터를 전송하고 저장하고 있음을 보장할 수 있다.- 팔로워 파티션까지 세팅이 되어있어야 의미가 있기 때문에 min.insync.replicas 의 옵션 값을 2이상으로 설정해야한다.
- 프로듀서는 보낸 데이터가 리더 파티션에과 팔로워 파티션 모두
멱등성 프로듀서
- 멱등성이란? 여러 번 연산을 수행하더라도 동일한 결과를 나타내는 것을 뜻한다.
- 멱등성 프로듀서는
동일한 데이터를 여러번 전송하더라도 카프카 클러스터에단한 번만 저장됨을 의미한다. - 기본 프로듀서의 방식은 at least once delivery를 지원한다.
- 적어도 한번 전달이기 때문에 한번 이상 데이터를 적재할 수 있으므로 데이터가 유실되지 않음을 뜻하나 중복될 수는 있다.
- enble.idempotence 옵션을 true로 지정하면 exactly once delivery로 동작한다.
- exactly once delivery 경우 브로커는 PID(프로듀서 아이디)와 시퀀스 넘버를 함께 전달하여 이 값을 확인하여 중복을 확인한다.
트랜잭션 프로듀서
- 다수의 데이터를 동일 트랜잭션으로 묶음으로써 전체 데이터를 처리하거나 처리하지 않는 프로듀서를 뜻한다.
멀티 스레드 컨슈머
- 카프카는 처리량을 늘리기 위해 파티션과 컨슈머 개수를 늘려서 운영할 수 있다.
- 파티션을 여러개 운영하는 경우
데이터를 병렬처리하기 위해서 파티션 개수와 컨슈머 개수를 동일하게 맞추는 것이 가장 좋은 방법이다. - n개의 스레드를 가진 1개의 프로세스 또는 1개의 스레드를 가진 n개의 프로세스로 운영하는 방법이 있다.
- 멀티 스레드로 컨슈머를 운영할 경우
고려할 점이 매우 많지만안정/지속적으로 운영할 수 있는 경우 매우 효율적으로 운영할 수 있다. - 고려할점
- 하나의 프로세스 내부에 스레드가 여러개 생성되어 실행되는 경우 하나의 컨슈머에서 OutOfMemory예외 발생시 프로세스가 강제 종료되면 다른 컨슈머 스레드에도 영향을 끼친다.
- 컨슈머 스레드들이 비정상적으로 종료시, 데이터 처리에서 중복 및 유실이 발생할 수 있다.
멀티코어 CPU를 가진 서버 환경에서멀티 컨슈머 스레드를 운영하면제한된 리소스 내에서 최상의 성능을 발휘할 수 있다. 컨슈머를 멀티스레드로 활용하는 방식은 크게 2가지로 나뉜다.컨슈머 스레드는 1개만 실행하고 데이터 처리를 담당하는워커 스레드를 여러개 실행하는 방법(멀티 워커 스레드 전략)- 컨슈머 인스턴스에서 poll() 메서드를 호출하는 스레드를 여러개 띄워서 사용하는
컨슈머 멀티 스레드 전략
카프카 컨슈머 멀티 워커 스레드 전략
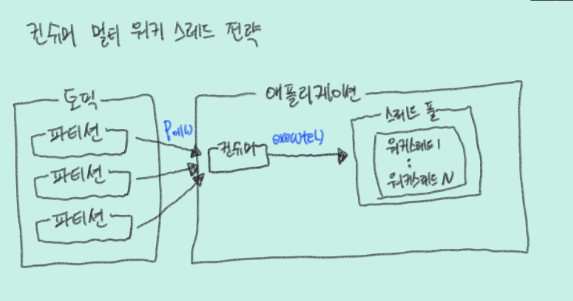
-
poll()을 통해 받은 데이터를
병렬처리함으로써 속도의 이점을 확실히 얻을 수 있다. -
데이터 처리가 스레드에서 진행 중임에도 불구하고 다음 poll() 메서드를 호출 시 커밋을 할 수 있기 때문에 리밸런싱, 컨슈머 장애 발생시
데이터 유실이 발생할 수 있다. -
스레드의 처리시간이 달라
레코드의 순서가 뒤바뀌는 현상이 발생할 수도 있다. -
데이터 순서 상관없이 빠른 처리 속도가 필요한 데이터 처리에 적합
ex) 서버리소스 모니터링 파이프라인, IOT 서비스의 센서 데이터 수집 파이프라인
public class ConsumerWorker implements Runnable {
private final static Logger logger = LoggerFactory.getLogger(ConsumerWorker.class);
private String recordValue;
ConsumerWorker(String recordValue){
this.recordValue = recordValue;
}
@Override
public void run(){
logger.info("thread:{}\trecord:{}", Thread.currentThread().getName(), ` recordValue)
}
}
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(configs);
consumer.subscribe(Arrays.asList(TOPIC_NAME));
ExecutorService executorService = Executors.newCachedThreadPool();
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(10));
for(ConsumerRecord<String, String> record : records){
ConsumerWorker worker = new ConsumerWorker(record.value());
executorService.execute(worker);
}
}카프카 컨슈머 스레드 전략
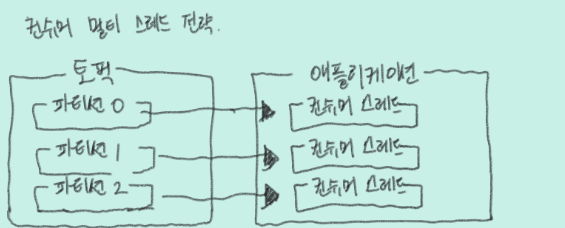
-
하나의 파티션은 동일 컨슈머 중 최대 1개까지 할당된다.이런 특징을 가장 잘 살리는 방법은 1개의 애플리케이션에 구독하고자 하는토픽의 파티션 개수만큼 컨슈머 스레드 개수를 늘려서 운영하는 것이다. -
컨슈머 스레드가 파티션 개수보다 많아지면 할당할 파티션 개수가 더는 없으므로 파티션에 할당되지 못한 컨슈머 스레드는 데이터 처리를 하지 않게된다.
public class ConsumerWorker implements Runnable {
private final static Logger logger = LoggerFactory.getLogger(ConsumerWorker.class);
private Properties prop;
private String topic;
private String threadName;
private KafkaConsumer<String, String> consumer;
ConsumerWorker(Properties prop, String topic, int number){
this.prop = prop;
this.topic = topic;
this.number = number;
}
@Override
public void run(){
consumer = new ConsumerWorker<(prop);
consumer.subscribe(Arrays.asList(topic));
while(true){
ConsumerRecord<String, String>records = consumer.poll(Duration.ofSeconds(1));
for(ConsumerRecord<String, String> record : records){
logger.info("{}", record);
}
}
}
}
public class MultiConsumerThread {
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "my-kafka:9092";
private final static String GROUP_ID = "test-group";
private final static String CONSUMER_COUNT = "3";
public static void main(String[] args){
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
ExecutorService executorService = Executors.newCachedThreadPool();
for(int i=0; i<CONSUMER_COUNT; i++){
ConsumerWorker worker = new ConsumerWorker(configs, TOPIC_NAME, i);
executorService.execute(worker);
}
}
}컨슈머 랙
