[Deploy] CI/CD
개발 프로세스
개발 프로세스란 소프트웨어 시스템이나 애플리케이션 개발 및 유지보수할 목적으로 수행되는 활동의 절차를 뜻합니다. 개발 프로세스의 목적은 개발에 대한 전체적인 가이드라인을 제공하는 데에 있습니다. 절차가 있는 개발과 그렇지 않은 개발은 큰 차이가 있을 것입니다.
개발 프로세스, 즉 소프트웨어 개발 프로세스 모델은 소프트웨어 개발 생명주기(SDLC, Software Develpment Life Cycle)을 기반으로 만들어졌습니다.
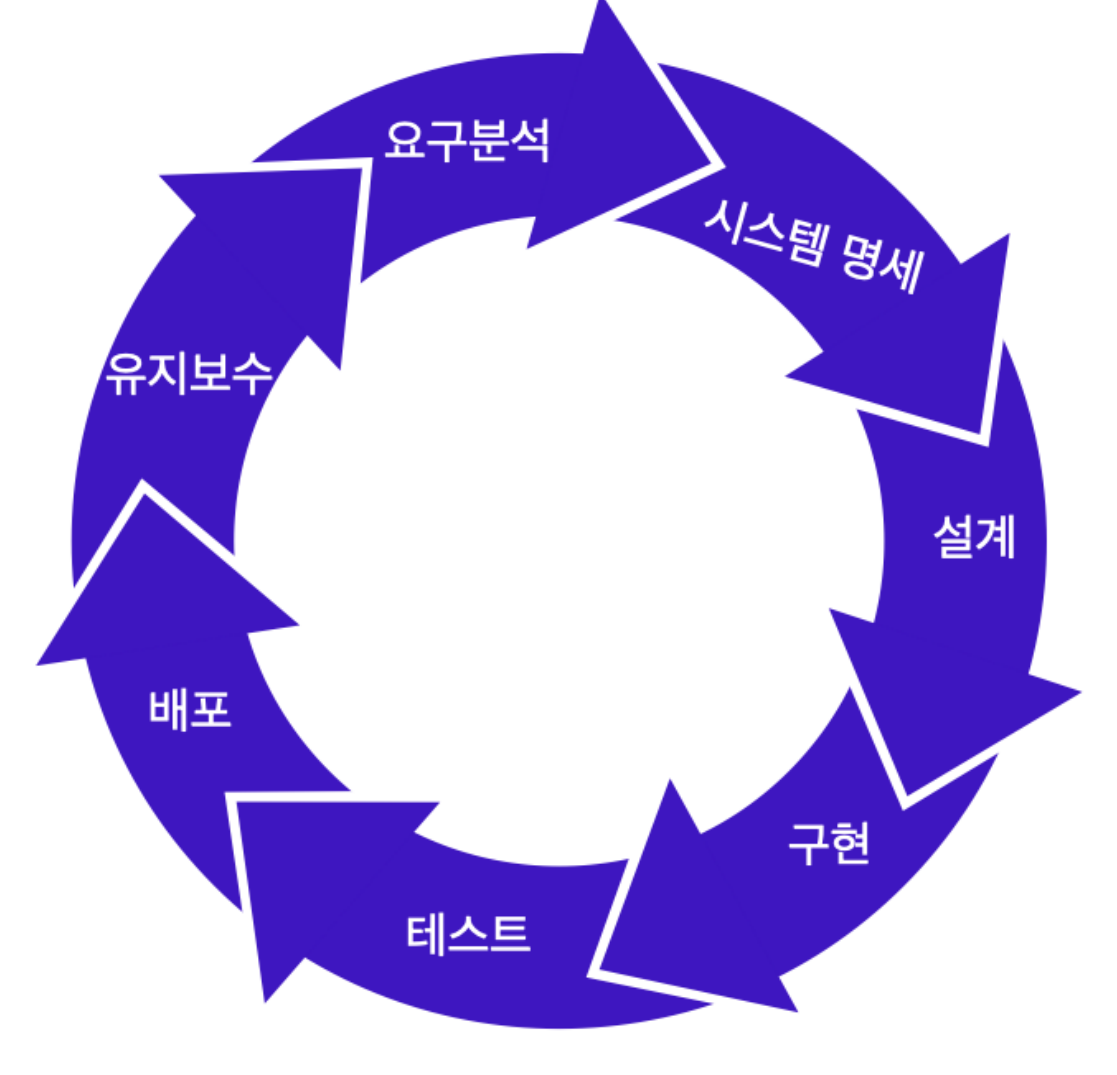
요구분석 및 시스템 명세 작성
문제분석 단계라고도 하며, 개발할 소프트웨어의 기능과 제약조건, 목표 등을 사용자와 함께 정확히 정의하는 단계입니다. 개발하고자 하는 소프트웨어의 성격을 정확히 이해하여 이를 토대로 개발 방법과 필요한 자원 및 예산 예측 후 요구명세를 작성합니다.
설계
설계단계에서는 앞서 정의한 기능을 실제로 수행하기 위한 방법을 논리적으로 결정합니다. 크게 시스템, 프로그램, UI(User Interface) 설계로 나뉘며, 시스템 구조설계는 시스템을 구성하는 내부 프로그램이나 모듈 간의 관계와 구조를 설계하고, 프로그램설계는 프로그램 내의 각 모듈에서의 처리 절차나 알고리즘을 설계합니다.UI(User Interface) 설계는 사용자 인터페이스 설계로, 사용자가 시스템을 사용하기 위해 보이는 부분을 설계합니다.
구현
설계 단계에서 논리적으로 결정한 문제 해결 방법을 프로그래밍언어를 사용하여 실제 프로그램을 작성합니다. 이때 프로그래밍 기법은 구조화 프로그래밍과 모듈러 프로그래밍 두 개로 나뉩니다.
- 구조화 프로그래밍 : 조건문, 반복문을 사용하여 프로그램을 작성하고, 순차구조, 선택구조, 반복구조의 세 가지 제어구조로 표현하며, 구조가 명확하여 정확성 검증과 테스트 및 유지보수가 쉬운 장점이 있습니다.
- 모듈러 프로그래밍 : 프로그램을 여러 개의 작은 모듈로 나누어 계층 관계로 구성하는 프로그래밍 기법으로, 모듈별로 개발과 테스트 및 유지보수 가능하며, 모듈의 재사용 가능하다는 장점이 있습니다.
테스트
테스트 단계에서는 개발한 시스템이 요구사항을 만족하는지, 실행 결과가 예상한 결과와 정확하게 맞는지를 검사하고 평가하는 일련의 과정입니다. 미처 발견하지 못한 오류를 발견할 수 있기 때문에 매우 중요한 과정입니다.
배포 및 유지보수
배포와 유지보수 단계는 시스템이 인수되고 설치된 후(배포) 일어나는 모든 활동을 지칭합니다. 이후 일어나는 커스터마이징, 구현, 테스트 등 모두 이 단계에 포함되므로 소프트웨어 생명주기에서 가장 긴 기간을 차지합니다. 유지보수의 유형에는 수정형, 적응형, 완전형, 예방형 총 네 가지가 있습니다.
- 수정형 유지보수 : 사용 중에 발견한 프로그램의 오류 수정 작업을 진행합니다.
- 적응형 유지보수 : 시스템과 관련한 환경적 변화에 적응하기 위한 재조정 작업을 합니다.
- 완전형 유지보수 : 시스템의 성능을 향상하기 위한 개선 작업을 합니다.
- 예방형 유지보수 : 앞으로 발생할지 모를 변경 사항을 수용하기 위한 대비 작업을 수행합니다.
무엇을 개발할지 결정하고 요구사항들을 구현 작업에 적합하게 명확하고 조직화된 구조로 바꾸는 과정을 거쳐, 실제 개발에 착수하는 단계는 ‘구현’부터입니다. 현재 그림 상으로는 이 단계들이 계속 꼬리를 물고 도는 순환 구조로 되어 있지만, 실제 개발 환경에서는 환경에 따라 각각의 단계가 또 세밀하게 나뉘어져 있기도 하며, 각 단계가 계속해서 반복되기도 합니다.
이러한 개발 프로세스는 다양한 모델이 있는데 어느 정도 규모의 앱을 개발하는 지, 혹은 어떤 종류의 앱을 개발하는 지를 고려하여 모델을 선택해 사용합니다.
개발 프로세스의 발전
전통적인 개발 프로세스
기존에 존재하고 있던 개발 프로세스는 워터폴(Waterfall) 방식이 있습니다. 영어에서 주는 직관적인 느낌 그대로, 폭포와 같이 한 방향으로만 프로세스가 진행되는 개발 과정을 뜻합니다. 실제로 한국어로도 “폭포수 개발 방식” 이라고도 합니다.
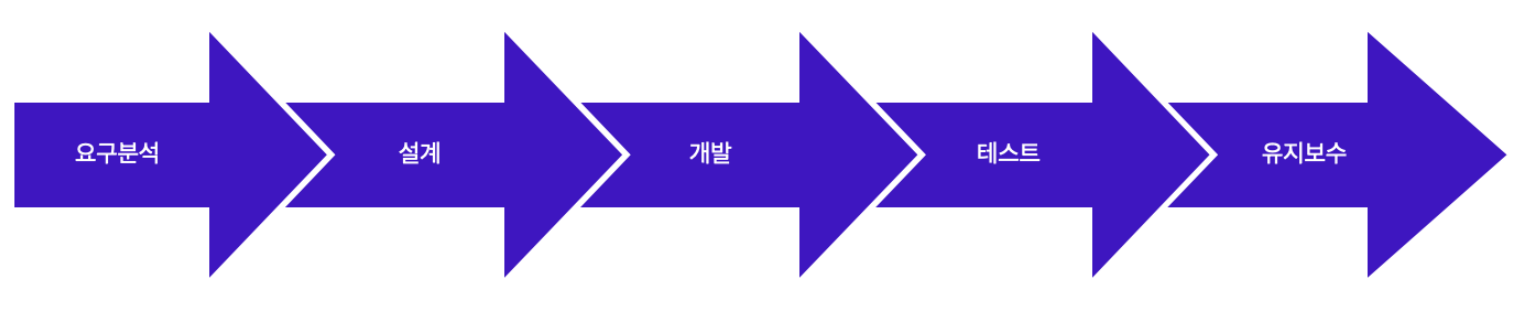
보통 이런 사이클을 가지고 있으며, 유지보수까지 끝나면 다시 처음의 단계로 돌아가 시작하는 것이 가장 기본적인 모델이라고 볼 수 있습니다. 여기서 변형된 모델들이 나오나 보통은 프로세스가 기본 모델에서 추가가 되거나 하나의 프로세스가 세부적으로 나뉘거나 하는 수준에서 그칩니다.
이런 워터폴 개발 방식은 실제 출시 기한을 정해놓고 순차적으로 프로세스가 진행시켜 어플리케이션(소프트웨어)를 완성해 배포하기 때문에 실제로 배포되어 유저에게 전달되는 시간이 오래 걸립니다. 또한 실제 디자인 또는 개발된 화면을 시각적으로 확인할 수 있는 단계는 이미 많은 단계가 지나온 시점이기 때문에 어떤 버그나 수정 사항이 생기면 다시 처음으로 돌아가 수정되기 때문에 일정과 비용 등 많은 부분에서 에로 사항이 생기게 됩니다. 대부분 그래서 출시 시점에 소프트웨어의 신뢰성 및 안정성을 보장 받기가 힘들며, 배포 직후에도 수많은 버그를 마주하게 될 가능성이 있습니다.
그래서 전통적인 소프트웨어 개발 프로세스에서는 소프트웨어의 안정성 개선을 위해 테스트 단계에 다양한 테스트들을 도입하기도 합니다.
- 시스템 테스트 : 모든 모듈을 통합한 후 최종적으로 완성된 시스템이 요구사항을 만족하는지 확인합니다. 요구사항을 만족하지 않는다면 다시 요구분석 단계로 돌아가 새로 개발을 하기도 합니다.
- 알파 테스트 : 완전히 개발된 시스템을 개발 현장에서 비공개로 테스트하는 것으로, 주문형 제품의 경우 개발진과 클라이언트 사이에서 동의가 이루어질 때까지 수행됩니다. 대기업의 경우 이 업무를 주로 하는 전문 QA팀이 존재합니다.
- 베타 테스트 : 고객의 실제 사용 환경에서 수행되는 테스트로, 미리 선별된 유저들이 해당 제품을 사용해 봅니다. 이 과정에서 에러나 버그가 발견되면 수정하는 식으로 진행됩니다.
이 외에도 다양한 테스트가 존재합니다.
모던 개발 프로세스
이런 전통적인 개발 프로세스에서 벗어나기 위해 만들어진 프로세스 중 하나가 애자일(Agile) 방식입니다. 이 애자일 방식은 ‘스프린트(sprint)' 라고 불리는 짧은 주기의 개발 사이클을 계속해서 반복합니다.
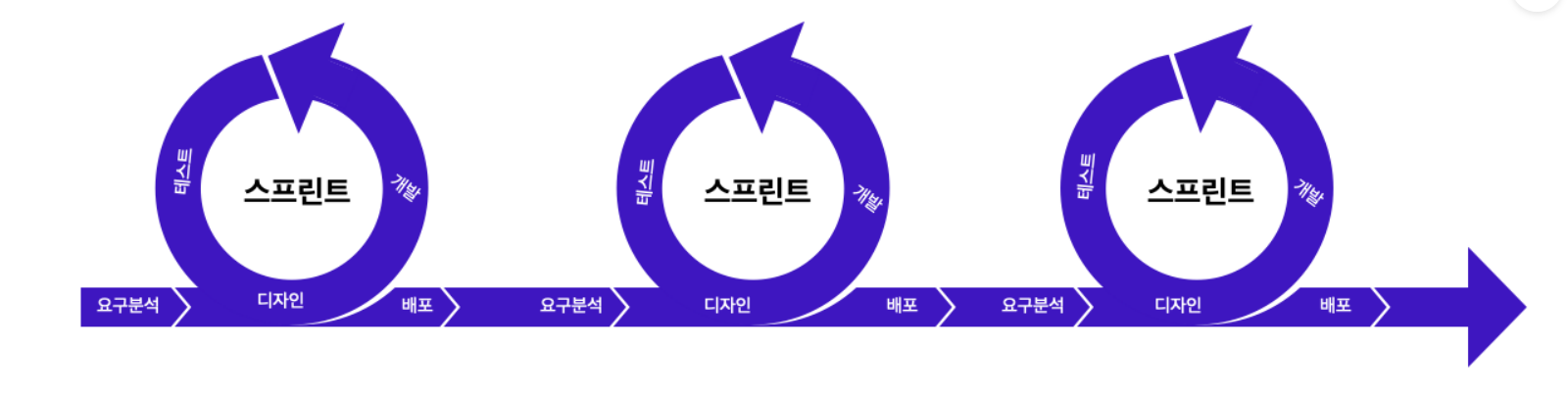
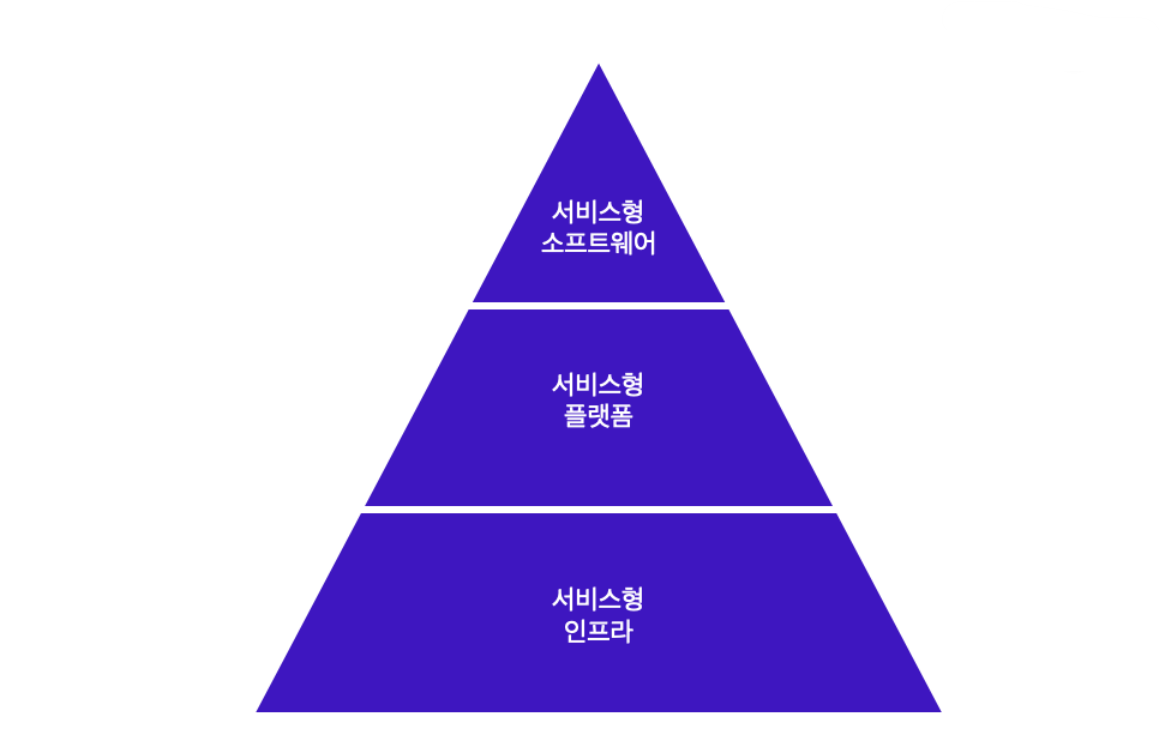
이 방식은 요구사항이 변하는 것을 당연한 전제로 두고 있습니다. 따라서 계획에 의존하여 형식적인 절차를 끝까지 따라야 하고 중간에 뒤로 회귀할 수 없는 전통적인 개발 프로세스보다는 훨씬 효율적으로 개발에 착수할 수 있습니다. 애자일 개발 프로세스를 적절히 사용하면 빠르게 문제를 해결해 하루에도 여러 번의 배포가 가능해집니다. 이러한 방식은 SaaS(Software as a Service, 서비스형 소프트웨어)를 개발하는 데에 적합합니다.
SaaS란?
SaaS는 클라우드 서비스의 한 방식으로, 브라우저에 접속하기만 해도 새 버전을 즉시 사용할 수 있는 서비스 방식입니다. 애플리케이션부터 서버, 가상화, 스토리지, 네트워킹까지 전부 공급자 쪽에서 관리하기 때문에 고객이 제어하거나 관리할 부분이 거의 없게 됩니다. 따라서 사용자 업데이트에 대한 걱정에서 벗어나며, 하루에 여러 번의 배포도 가능합니다. 또한 빠른 배포 속도도 보장 받을 수 있습니다.
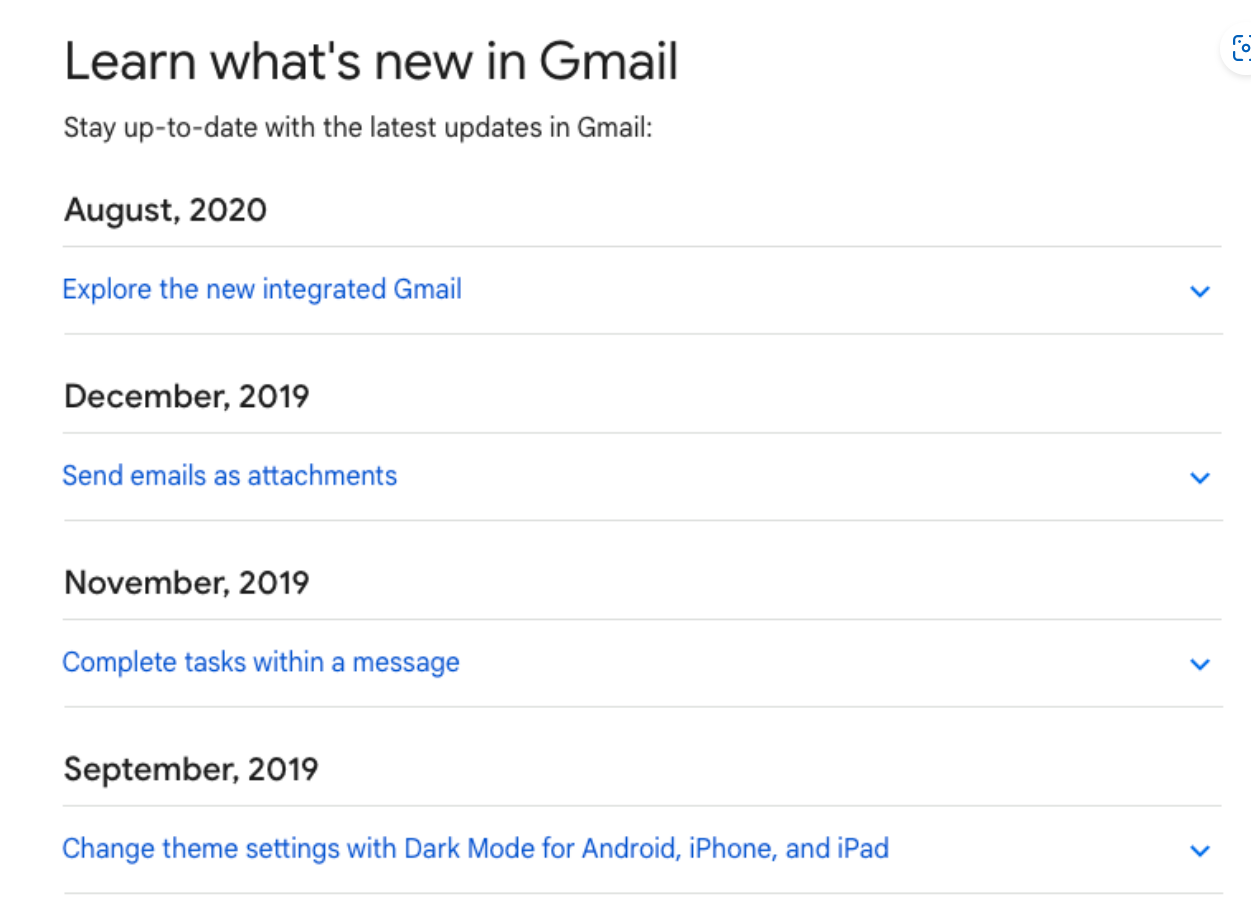
해당 그림은 구글의 Gmail 업데이트 로그입니다. 해당 기간 동안 Gmail은 잦은 업데이트를 했지만 Gmail은 SaaS 방식으로 서비스를 제공하기 때문에, 사용자는 업데이트를 했는지도 모르고 해당 애플리케이션을 사용했을 것임을 유추할 수 있습니다.
전통적인 개발 프로세스 VS 모던 개발 프로세스
그렇다면 전통적인 개발 프로세스는 모던 개발 프로세스에 비해 현저히 떨어지는 프로세스일까요? 그렇지는 않습니다. 모던한 개발 프로세스를 따른다 해도 “제대로" 따르지 않는다면 하느니만 못하기 때문입니다. 아래의 표는 전통적인 개발 프로세스인 워터폴과 모던 개발 프로세스인 애자일의 장점 및 단점을 정리한 표입니다.

또한 앞서 이야기했듯, 어느 정도 규모의 앱을 개발하는 지, 혹은 어떤 종류의 앱을 개발하는 지를 고려하여 모델을 선택해 사용하기 때문에, 오히려 어떤 상황에서는 체계적인 계획과 문서를 만들고 시작하는 전통적인 개발 프로세스가 더 적합할 수도 있다는 점을 알아둬야 합니다. 밑의 표는 해당 프로세스가 적합한 조직을 나열한 표입니다.
DevOps
DevOps란?
전통적인 IT 조직 구조로는 개발팀(Dev)과 운영팀(Ops)이 소프트웨어의 개발과 관리 및 유지보수를 담당해왔습니다.

개발팀이 잦은 업데이트를 통해 제품에 변화를 만들어야 한다면, 운영팀은 이런 서비스의 구성의 변경을 최소화해 안정성을 확보하는데, 이 부분은 꽤 상충이 되는 부분이기 때문에 갈등을 야기하기도 합니다. 이런 갈등이 빚어지는 구조는 현대 IT 시장에는 맞지 않을 뿐더러, 제품의 릴리즈 주기를 길어지게 만들기도 합니다.
그렇기 때문에 DevOps라는 개념이 만들어졌습니다. DevOps는 소프트웨어 개발(Development)과 IT 운영(Operations)의 합성어입니다. 소프트웨어를 자주, 빨리 그리고 안전하게 배포하는 것을 목표로 하며, 그렇기 때문에 애자일 개발 프로세스를 기반으로 한 것이라고 볼 수 있습니다.
DevOps 문화
DevOps는 특정한 업무라던지 부서가 아닌 일종의 개발 문화입니다. 만약 서비스가 중단된다면, 누구든지 문제점을 진단하고 시스템을 복구하여 운영할 수 있는 절차를 알고 있어야 합니다. 이를 위한 기술과 지식이 제공되기 위해서 훈련과 효과적인 협업체계를 마련하는 것이 매우 중요합니다.그러나 실제 실무에서는 업무의 분리를 위해 DevOps팀, 혹은 부서를 두고 있을 수 있습니다.
DevOps 특징
DevOps는 개발에서 운영까지 하나의 통합된 프로세스로 묶어내고 사용하는 툴과 시스템을 표준화하여 의사소통의 효율성을 확보하고 일련의 작업들을 자동화합니다. 즉 코드 통합, 테스트, 배포 과정을 자동화 시키는 것입니다. 이 부분은 지속적으로 유지되어야 할 필요가 있는데, 지속적 통합 및 배포(CI/CD)라고 하며 DevOps의 핵심 원칙이라고 해도 과언이 아닙니다. 잘 구축된 CI/CD는 애플리케이션의 배포 시간을 크게 단축시킵니다.
DevOps 사례
실제 인터넷 상에서 스트리밍이나 사진과 같은 엄청난 트래픽과 다양한 사용자 환경 및 요구에 빠르게 대응하기 위해 배포가 많은 기업 중에 Devops를 활용하여 성공한 기업 들이 많습니다.
- 미국 최대 온라인 스트리밍 서비스를 제공하고 있는 넷플릭스(Netflex)는 2012년 기준으로 3천만 명이 넘는 가입자를 보유하며 엄청난 스트리밍 트래픽을 아마존 웹 서비스(AWS)에서 10,000여개 이상의 인스턴스를 10여명 정도의 Devops팀으로 관리하고 있습니다.
- 사진 SNS 서비스로 야후에 합병된 Flickr는 초당 40,000 장의 사진이 업로드 되는데 Devops를 통하여 모든 배포 및 운영을 자동화하여 하루에도 10여 번 씩 이상의 배포를 하곤 합니다.
- 음악 스트리밍 서비스로 최근 각광을 받고 있는 Spotify도 강력한 Devops 개발문화를 갖추고 오픈소스 도구를 활용하여 배포와 운영을 자동화하여 관리합니다.
이렇게 Devops를 통하여 새로운 기능을 시장에 보다 자주 그리고 빨리 출시할 수 있고, 장애발생시 보다 대응과 시스템의 안정성을 향상시킬 수 있음을 알 수 있습니다.
CI/CD
CI/CD란
CI/CD는 약어로, 몇 가지의 다른 의미를 가지고 있습니다. CI/CD의 "CI"는 개발자를 위한 자동화 프로세스인 지속적인 통합(Continuous Integration)을 의미합니다. CI를 성공적으로 구현할 경우 애플리케이션에 대한 새로운 코드 변경 사항이 정기적으로 빌드 및 테스트되어 공유 리포지토리에 통합되므로 여러 명의 개발자가 동시에 애플리케이션 개발과 관련된 코드 작업을 할 경우 서로 충돌할 수 있는 문제를 해결할 수 있습니다.
CI/CD의 "CD"는 지속적인 서비스 제공(Continuous Delivery) 및/또는 지속적인 배포(Continuous Deployment)를 의미하며 이 두 용어는 상호 교환적으로 사용됩니다. 두 가지 의미 모두 파이프라인의 추가 단계에 대한 자동화를 뜻하지만 때로는 얼마나 많은 자동화가 이루어지고 있는지를 설명하기 위해 별도로 사용되기도 합니다.
CI/CD의 단계
일반적인 앱의 개발 및 유지보수 단계는 아래와 같음을 우리는 앞서 배웠습니다. 여기서 지속적 통합 및 지속적 전달을 단계별로 꾀할 수 있습니다.
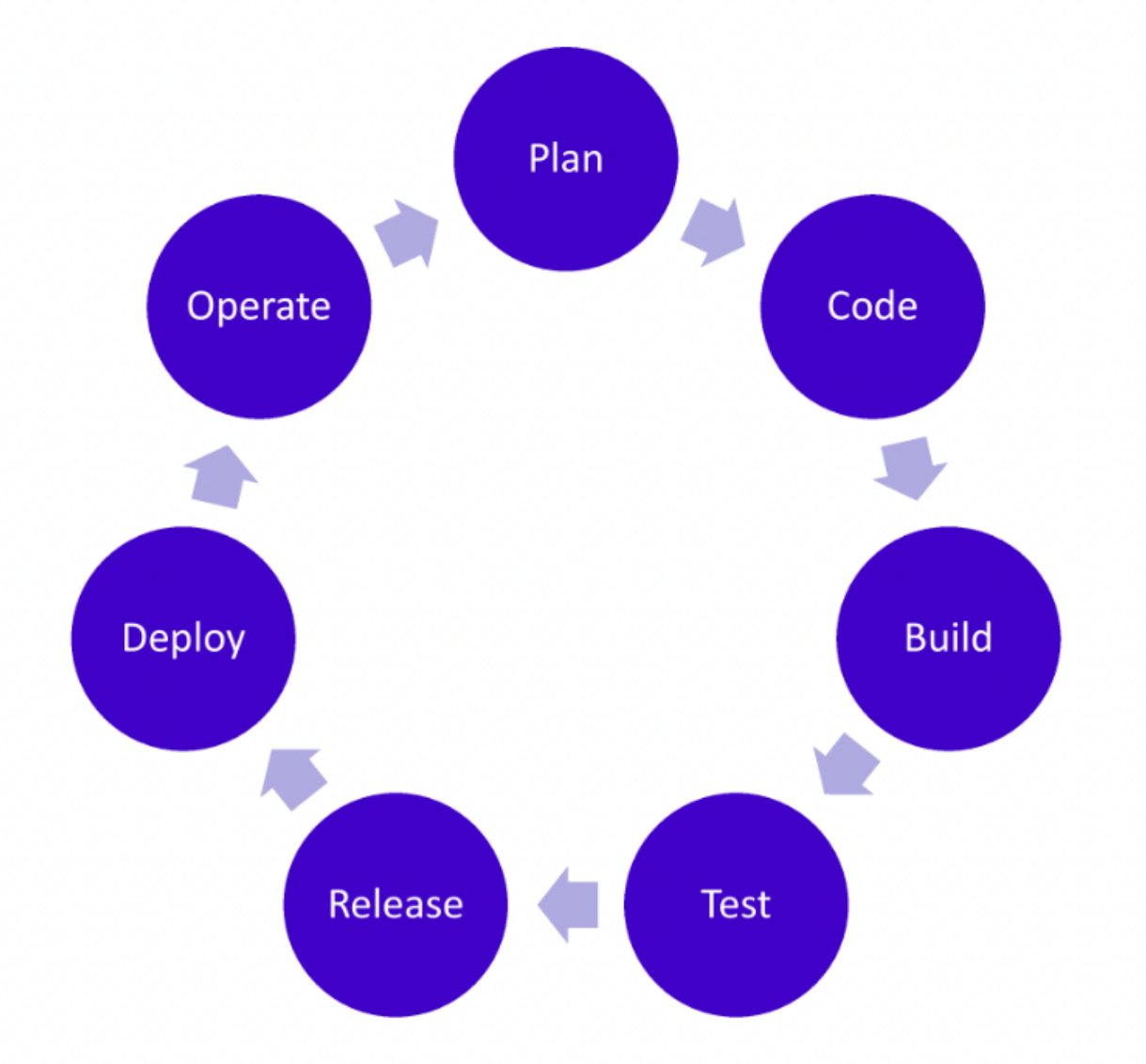
지속적 통합
(Continuous Integration, CI)
개발자를 위한 자동화 프로세스라고 볼 수 있으며, Code - Build - Test 단계에서 꾀할 수 있습니다.
Code : 개발자가 코드를 원격 코드 저장소 (Ex. github repository)에 push하는 단계입니다.
Build : 원격 코드 저장소로부터 코드를 가져와 유닛 테스트 후 빌드하는 단계입니다.
Test : 코드 빌드의 결과물이 다른 컴포넌트와 잘 통합되는 지 확인하는 과정입니다.
이 과정에서 개발자는 코드를 잦게 원격 코드 저장소에 push하고, 테스트 및 빌드를 하며 빌드 결과를 통해 빌드가 성공했는지 실패했는지 확인을 하고, 통합 테스트 결과를 통해 개선 방안을 찾습니다. 이 지속적인 통합 과정을 통해 개발자는 버그를 일찍 발견할 수 있고, 테스트가 완료된 코드에 대해 빠른 전달이 가능해지며 지속적인 배포가 가능해집니다.
지속적 통합은 모든 코드 변화를 하나의 리포지토리에서 관리하는 것 부터 시작합니다. 모든 개발팀이 코드의 변화를 확인할 수 있기 때문에, 투명하게 문제점을 파악할 수 있습니다. 그리고 잦은 풀 리퀘스트(pull request)와 머지(merge)로 코드를 자주 통합합니다. 이 때, 기본적인 테스트도 작동시킬 수 있습니다. 이렇게 지속적 통합을 통해 개발팀은 각자 개발한 코드를 이른 시점에 자주 합치고 자주 테스트 해볼 수 있습니다.
지속적 통합으로 보안 이슈, 에러 등을 쉽게 파악할 수 있어 해당 이슈를 빠르게 개선할 수 있습니다. 이전에는 각자 개발자가 작성한 코드를 합치고 난 후, 모두 모여서 빌드를 시작하고 나서야 문제점을 파악할 수 있었습니다. 지속적 통합이 적용된 개발팀은 코드를 머지하기 전, 이미 빌드 오류나 테스트 오류를 확인하여 훨씬 더 효율적인 개발을 할 수 있게 됩니다.
지속적 배포
(Continuous Delivery/Deployment, CD)
지속적인 서비스 제공(Continuous Delivery) 및 지속적인 배포(Continuous Deployment)를 의미하며 이 두 용어는 상호 교환적으로 사용됩니다. 이 부분은 Release - Deploy - Operate 단계에서 꾀할 수 있습니다.
Release : 배포 가능한 소프트웨어 패키지를 작성합니다.
Deploy : 프로비저닝을 실행하고 서비스를 사용자에게 노출합니다. 실질적인 배포 부분입니다.
Operate : 서비스 현황을 파악하고 생길 수 있는 문제를 감지합니다.
지속적 배포의 경우, 코드 변경 사항의 병합부터 프로덕션에 적합한 빌드 제공에 이르는 모든 단계로, 테스트 자동화와 코드 배포 자동화가 포함됩니다.
이 프로세스를 완료하면 프로덕션 준비가 완료된 빌드를 코드 리포지토리에 자동으로 배포할 수 있기 때문에 운영팀이 보다 빠르고 손쉽게 애플리케이션을 프로덕션으로 배포할 수 있게 됩니다.
최근에는 클라우드 기술 발전과 맞물려 지속적 통합과 지속적 배포가 빠른 속도로 진행되면서 CI/CD를 하나로 묶어서 다루는 경우가 점차 증가하고 있습니다. 예를 들어, 이전에는 배포 자체가 상당히 오래 걸리고 힘든 일이어서 배포 이전 단계에서 많은 고민을 하곤 했습니다. 서버를 전부 재시작해야 한다거나, 일부 기능을 제공하지 못하는 경우도 많았기 때문입니다. 요즘은 고객의 피드백을 빨리 받기 위해서라도, 서비스를 중단하지 않기 위해서라도 릴리즈만 잘 기록해두고 바로바로 배포하는 사례가 증가하고 있습니다.
실리콘밸리 테크 기업들은 다양한 모니터링 툴과 장애 대응 프로세스를 마련해 배포에 대한 자신감을 높여 조직의 비즈니스 역량을 키우고 있습니다. 처음에 소개한 듯이 “하루에 1,000번의 배포를 할 수 있는가?” 는 조직의 기술적 확장 역량을 판단할 수 있는 중요한 지표입니다.
뱅크셀러드 - 하루에 1000번 배포하는 조직 되기
지속적 배포 사례
지속적 배포의 가장 흔한 사례가 Github Page입니다. 지정해둔 디렉터리에 정해진 방식에 따라 잘 커밋하기만 하면, Github Page가 알아서 해당 index.html 파일과 해당 디렉터리에 있는 파일을 잘 번들링해서 Github Page 서버에 업로드합니다. 이렇게 자동으로 인터넷에 배포가 되었고, 주변 가족이나 친구들에게 쉽게 만든 결과물을 공유할 수 있었습니다. (틀린 부분이 있다면 빠르게 피드백도 받을 수 있었습니다.) 이전 솔로 프로젝트에서 Github Page 배포에 성공했다면, 이미 지속적 배포를 경험해봤다고 볼 수 있습니다.
CI/CD의 영역
CI/CD는 지속적 통합 및 지속적 제공(CD, Continuous Delivery)의 구축 사례만을 지칭할 때도 있고, 지속적 통합, 지속적 제공, 지속적 배포라는 3가지 구축 사례 모두를 의미하는 것일 수도 있습니다.
좀 더 복잡하게 설명하면 "지속적인 서비스 제공"은 때로 지속적인 배포의 과정까지 포함하는 방식으로 사용되기도 합니다.
결과적으로 CI/CD는 파이프라인으로 표현되는 실제 프로세스를 의미하고, 애플리케이션 개발에 지속적인 자동화 및 지속적인 모니터링을 추가하는 것을 의미합니다. 이 용어는 사례별로 CI/CD 파이프라인에 구현된 자동화 수준 정도에 따라 그 의미가 달라집니다.
대부분의 기업에서는 CI를 먼저 추가한 다음 클라우드 네이티브 애플리케이션의 일부로서 배포 및 개발 자동화를 구현해 나갑니다.
CI/CD 파이프라인
배포 자동화
배포 자동화란 한번의 클릭 혹은 명령어 입력을 통해 전체 배포 과정을 자동으로 진행하는 것을 뜻합니다. 배포 자동화가 왜 필요할까요?
먼저 수동적이고 반복적인 배포 과정을 자동화함으로써 시간이 절약됩니다.
휴먼 에러(Human Error)를 방지할 수 있습니다.
여기서 휴먼 에러란 사람이 수동적으로 배포 과정을 진행하는 중에 생기는 실수들을 뜻합니다. 그 전에 했던 배포 과정과 비교하여 특정 과정을 생략하거나 다르게 진행하여 오류가 발생하는 것이 휴먼 에러의 예로 볼 수 있습니다.
배포 자동화를 통해 전체 배포 과정을 매번 일관되게 진행하는 구조를 설계하여 휴먼 에러 발생 가능성을 낮출 수 있습니다.
CI/CD 파이프라인
앞서 우리는 전통적인 개발 프로세스와 모던 개발 프로세스에 대해 배웠습니다. 그리고 SaaS가 모던 개발 프로세스로 개발하기 적합한 소프트웨어임도 확인했습니다.
그렇다면 이번에는 이렇게 생각해볼까요? 사용자 업데이트에 대한 걱정에서도 벗어났고, 하루에 여러 번의 배포도 가능해졌습니다. 그렇다면 어떻게 빠른 배포 속도를 보장 받을 수 있을까요? 개발자가 배포할 때마다 일일히 빌드하고 배포하는 과정을 진행하는 것은 한두 번이면 충분하겠지만, 이러한 과정이 수없이 진행된다면 일일히 이 과정을 수행하는 것이 번잡스럽고 지루할 것입니다.
그래서 이 수없이 진행되는 배포 과정을 자동화시키는 방법을 구축하게 되는데, 그것을 CI/CD 파이프라인이라고 합니다.
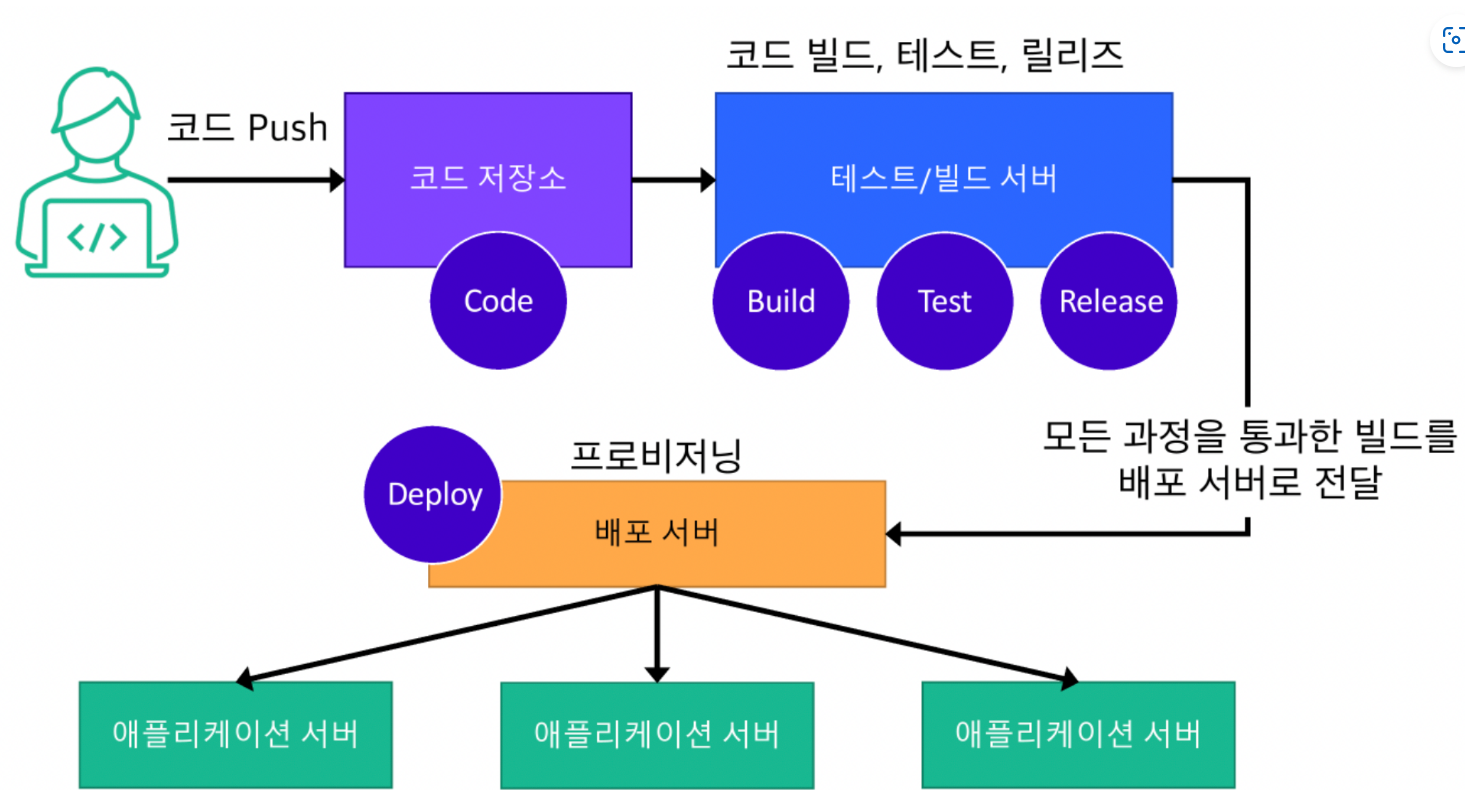
해당 그림은 배포 과정을 도식화한 것입니다. 개발자가 코드를 원격 저장소에 올리면, 그 코드가 빌드 및 테스트와 릴리즈를 거쳐 배포 서버로 전달 됩니다. 배포 서버에 도달한 빌드된 코드는 애플리케이션 서버로 최종 배포가 완료 되고, 그 결과물을 유저가 직접 확인하게 되는 것입니다.
여기서 자동화를 꾀하는 부분은 보통 코드가 빌드되면서 최종적으로 배포가 되는 단계까지입니다. 이 부분을 지속적인 통합 및 배포를 위하여 일련의 자동화 단계로 만드는데, 이것을 파이프라인을 구축한다고 표현합니다.
CI/CD 파이프라인을 구성하는 기본 단계와 수행 작업
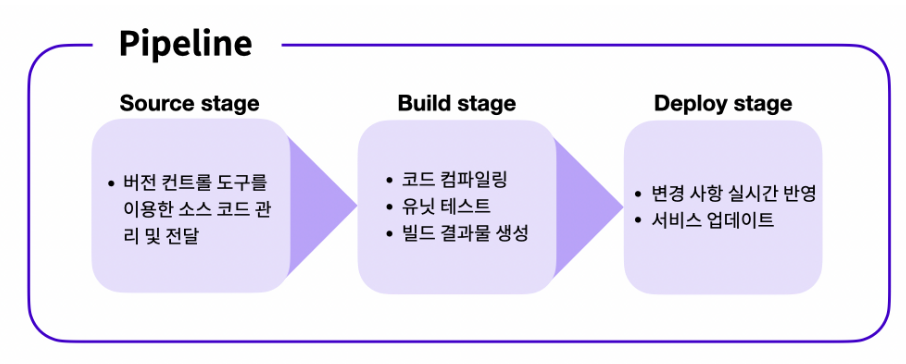
배포에서 파이프라인(Pipeline)이란 용어는 소스 코드의 관리부터 실제 서비스로의 배포 과정을 연결하는 구조를 뜻합니다. 파이프라인은 전체 배포 과정을 여러 단계(Stages)로 분리합니다. 각 단계는 파이프라인 안에서 순차적으로 실행되며, 각 단계마다 주어진 작업(Actions)들을 수행합니다.
파이프라인을 여러 단계로 분리할 때, 대표적으로 쓰이는 세 가지 단계가 존재합니다. 각 단계의 이름 및 수행하는 작업에 대해서 알아보겠습니다.
- Source 단계: Source 단계에서는 원격 저장소에 관리되고 있는 소스 코드에 변경 사항이 일어날 경우, 이를 감지하고 다음 단계로 전달하는 작업을 수행합니다.
- Build 단계: Build 단계에서는 Source 단계에서 전달받은 코드를 컴파일, 빌드, 테스트하여 가공합니다. 또한 Build 단계를 거쳐 생성된 결과물을 다음 단계로 전달하는 작업을 수행합니다.
- Deploy 단계: Deploy 단계에서는 Build 단계로부터 전달받은 결과물을 실제 서비스에 반영하는 작업을 수행합니다.
파이프라인의 단계는 필요에 따라 더 세분화되거나 간소화될 수 있습니다. DevOps를 전문으로 학습하는 경우 아래와 같이 파이프라인의 단계를 세분화해서 나누기도 합니다. 또한, 해당 툴을 소개하는 업체에 따라 용어를 미묘하게 다르게 사용하기도 합니다.
CI/CD 파이프라인 구성 요소 및 장점
- 빌드 (소프트웨어 컴파일)
- 테스트 (호환성 및 오류 검사)
- 릴리스 (버전 제어 저장소의 애플리케이션 업데이트)
- 배포 (개발에서 프로덕션 환경으로의 변환)
- 규정 준수 및 유효성 검사
이 과정이 실무에서는 반복적인 프로세스이기 때문에 이 부분을 일련의 자동화 단계로 만든다고 볼 수 있습니다.
이렇게 구축된 파이프라인은 최신 버전의 소프트웨어 애플리케이션을 업데이트하고 제공하려는 일련의 처리 단계에 걸리는 시간을 수동으로 하는 것보다 더 빠르고 안정적이며 효과적으로 줄여주고 CI/CD 인프라와의 호환성과 효율성을 높여줍니다.
Github Action
GitHub Action은 Github 레포지토리에서 바로 소프트웨어 개발 워크플로우를 자동화, 사용자 지정 및 실행할 수 있게 합니다. CI/CD를 포함하여 원하는 작업을 수행하기 위한 작업을 검색, 생성 및 공유하고 완전히 사용자 정의된 워크플로에서 작업을 결합할 수 있습니다.
GitHub Actions는 Github가 공식적으로 제공하는 빌드, 테스트 및 배포 파이프라인을 자동화할 수 있는 CI/CD 플랫폼입니다.
레포지토리에서 Pull Request 나 push 같은 이벤트를 트리거로 GitHub 작업 워크플로(Workflow)를 구성할 수 있습니다. 워크플로는 하나 이상의 작업이 실행되는 자동화 프로세스로, 각 작업은 자체 가상 머신 또는 컨테이너 내부에서 실행됩니다.
워크플로는 .yml (혹은 .yaml ) 파일에 의해 구성되며, 테스트, 배포 등 기능에 따라 여러개의 워크플로도 만들 수 있습니다. 생성된 워크플로는 .github/workflows 디렉토리 이하에 위치합니다.
비공개 레포지토리의 경우 Github Actions가 작동할 때의 용량과 시간이 제한되어있으며 공개 레포지토리는 무료로 사용 가능합니다. Github Actions에 대해 더 자세히 알고 싶은 경우 공식문서를 참고해주세요.
Github Action 실습
새로운 git repository 만들기 - practice2
git clone https://github.com/codestates-seb/fe-sprint-my-agora-states-server-reference.git
cd fe-sprint-my-agora-states-server-reference
git remote add myRepo https://github.com/hihijin/practice2.git
git push myRepo reference
Github Action은 Github의 특정 이벤트에 맞게 다양한 작업을 시킬 수 있는 CI/CD 플렛폼입니다. EC2와 같은 하나의 가상 인스턴스를 실행시켜서 원하는 작업을 시킬 수 있습니다. 그런데, 리포지토리를 push하기만 했는데, 왜 작동했을까요? ./.github/workflows/pullRequest.yml 파일을 읽어봅시다. 언제 어떤 job을 할지 명시되어 있습니다.
npm install은 빌드를 위한 준비과정으로 볼 수 있습니다. Node.js로 만든 서버 애플리케이션은 npm으로 관련 오픈소스를 모두 깔끔하게 설치해야 작동하기 때문입니다.
npm test는 유닛 테스트 과정입니다. 작성한 코드가 요구사항 충족을 위한 최소한의 조건을 만족했는지 확인하고 있습니다.
name: Bare Minimum Requirements
# 언제 job을 작동시킬지
on: [push, pull_request]
# 어떤 job을 할지
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Bare Minimum Requirements
uses: actions/setup-node@v1
with:
node-version: '16'
- run: npm install
- run: npm test## .github/workflows/client.yml
name: client
on:
push:
branches:
- reference
jobs:
build:
runs-on: ubuntu-20.04
steps:
- name: Checkout source code.
uses: actions/checkout@v2
- name: Install dependencies
run: npm install
working-directory: ./my-agora-states-client
- name: Build
run: npm run build
working-directory: ./my-agora-states-client
- name: SHOW AWS CLI VERSION
run: |
aws --version
- name: Sync Bucket
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_EC2_METADATA_DISABLED: true
run: |
aws s3 sync \
--region ap-northeast-2 \
build s3://fe-41-hihijin-s3 \
--delete
working-directory: ./my-agora-states-clientYAML
Yet Another Markup Language의 약자로, 사람이 읽을 수 있는 데이터 직렬화 언어를 의미합니다. 여기서 YAML을 YAML ain’t markup language(재귀 약어)로 생각하는 사람도 있습니다. 후자는 YAML이 문서가 아닌 데이터용임을 강조하는 말이라고 생각하시면 됩니다. 파일로 작성시 확장자는 .yaml 혹은 .yml 확장자를 가집니다.
YAML은 사람이 읽을 수 있고 이해하기 쉬워 프로그래밍 언어 중에서도 인기가 높습니다. 또한 다른 프로그래밍 언어와 함께 사용할 수도 있습니다. YAML은 그 유연성과 접근성으로 인해 자동화 프로세스를 생성하는 데에도 사용됩니다.
JSON vs YAML
//Github actions 설정을 위해 작성된 YAML 파일
name: Bare Minimum Requirements
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Bare Minimum Requirements
uses: actions/setup-node@v1
with:
node-version: '16'
- run: npm install
- run: npm test위의 YAML 파일을 보면 다른 형식의 파일과는 조금 다른 점이 눈에 보입니다. 이번에는 MDN에 게시된 JSON 파일을 보도록 하겠습니다.
//MDN의 JSON 파일
{
"squadName": "Super hero squad",
"homeTown": "Metro City",
"formed": 2016,
"secretBase": "Super tower",
"active": true,
"members": [
{
"name": "Molecule Man",
"age": 29,
"secretIdentity": "Dan Jukes",
"powers": [
"Radiation resistance",
"Turning tiny",
"Radiation blast"
]
}
]
}JSON 파일과 YAML 파일은 key-value 형태로 작성된 파일이며, 계층 구조를 가지는 것에는 동일합니다.
그러나 YAML 파일은 "" (큰따옴표, double quotation marks) 없이 문자열 작성이 가능해, 설정을 위한 스펙이나 프로퍼티 값 등이 JSON 파일에 비해 한 눈에 들어온다는 점입니다. 또한 JSON 파일처럼 {} 형태로 감싸줄 필요도 없기 때문에 스코프의 압박(잘못 쓰면 일일이 어디가 처음이고 끝인지 찾아야 하는 등)에서 벗어날 수도 있습니다.
게다가 YAML 파일은 JSON 파일과 다르게 주석을 작성할 수 있다는 점도 굉장한 이점으로 작용합니다. JSON 파일은 주석을 작성할 수 없기 때문에 해당 파일 하나만 두고 커뮤니케이션 하기가 까다롭지만, YAML 파일은 애초에 파일 내에 주석을 작성할 수 있기 때문에 커뮤니케이션 하기가 훨씬 수월합니다.
그리고 YAML은 JSON의 상위 호환 격이므로, 기존 json문서를 그대로 yaml파일로 사용하거나 원하는 부분만 손볼 수 있습니다. 반대로 yaml을 json으로 변환해 사용할 수도 있다는 점이 장점으로 작용합니다.
YAML 문법
YAML도 일종의 프로그래밍 언어이기 때문에 문법이 있습니다. 해당 문법을 지켜 작성하지 않으면 YAML 파일로 읽지 못하기 때문에, 문법을 잘 지켜줘야 합니다.
#이런 식으로 주석을 작성할 수 있습니다.
--- #문서 시작
#이 사이에 내용이 들어갑니다.
... #문서 끝
#기본표현
key: value
#자료형
#int(숫자)
int_type: 1
#string(문자열)
string_type: "1"
#blooean(참/거짓)
boolean_true_type: true
boolean_false_type: false
#이외에 yes, no로 작성하기도 합니다.
yaml_easy: yes
yaml_difficult: no
#리스트(배열 형태)
person:
name: Chungsub Kim
job: Developer
skills:
- docker
- kubernetes
# JSON 형식의 "skill" : [docker, kubernetes]와 같습니다.
#객체
key:
key: value
key: value
#또는 이렇게도 작성합니다. 가독성을 위해 사용합니다.
key: {
key: value,
key: value
}
#Text
# |는 줄바꿈 표현입니다.
# JSON 형식의 "comment_line_break": "Hello codestates.\nIm kimcoding.\n"과 같습니다.
comment_line_break: |
Hello codestates.
Im kimcoding.
# >는 줄바꿈 무시 표현입니다.
# JSON 형식의 "comment_single_line": "Hello world my first coding."과 같습니다.
comment_single_line: >
Hello world
my first coding.
#문자열 따옴표
# error가 납니다.
windows_drive: c:
# 이렇게 써야 합니다.
windows_drive: "c:"
windows_drive: 'c:'YAML 사용법 및 실제 사용 사례
YAML은 일반적으로 설정 파일(configure file 등)에 사용하기에 좋습니다. 따라서 spring boot, github action 등 다양한 CI/CD 툴이나 프레임워크에서 사용되고 있습니다. YAML을 실제로 사용하고 있는 프레임워크 중 쿠버네티스 또한 대표적으로 뽑을 수 있습니다. 기본적인 팟, 레플리카, 디플로이먼트 등 모든 내부 오브젝트가 yml문서로 작성되어 있으며, yaml고유 기능 중 하나인 문서 스트림을 사용해 클러스터 전체의 설정을 파일 하나로 관리하기도 합니다.
