[네트워크] 심화
네트워크
네트워크의 시작
네트워크의 시작은 회선교환 방식!
회선교환 방식 : 발신자와 수신자 사이에 데이터를 전송할 전용선을 미리 할당하고 둘을 연결합니다.
그래서 내가 연결하고 싶은 상대가 다른 상대와 연결중이라면, 상대방은 이미 다른 상대와의 전용선과 연결되어 있기 때문에 그 연결이 끊어지고 나서야 상대방과 연결할 수 있습니다.
또한 특정 회선이 끊어지는 경우에는 처음부터 다시 연결을 성립해야합니다.
패킷교환 방식 : 회선교환 방식의 문제 해결을 위해 패킷교환 방식의 네트워크를 고안했습니다.
패킷교환 방식은 패킷이라는 단위로 데이터를 잘게 나누어 전송하는 방식입니다.
각 패킷에는 출발지와 목적지 정보가 있고 이에 따라 패킷이 목적지를 향해 가장 효율적인 방식으로 이동할 수 있습니다.
이를 이용하면 특정 회선이 전용선으로 할당되지 않기 때문에 빠르고 효율적으로 데이터를 전송할 수 있습니다.
그래서 인터넷 프로토콜, 줄여서 IP는 출발지와 목적지의 정보를 IP 주소라는 특정한 숫자값으로 표기하고 패킷단위로 데이터를 전송하게 되었습니다.
IP/IP Packet
인터넷 통신의 기본! IP(인터넷 프로토콜)?
복잡한 인터넷 망 속에서 클라이언트와 서버가 통신하는 방법 ?
= 출발지에서 목적지까지 데이터가 무사히 전달되기 위해서는 규칙이 필요하다.
-> IP(인터넷 프로토콜) 주소를 컴퓨터에 부여하여 이를 이용해 통신합니다.
IP는 지정한 IP 주소(IP Address)에 패킷(Packet)이라는 통신 단위로 데이터 전달을 합니다.
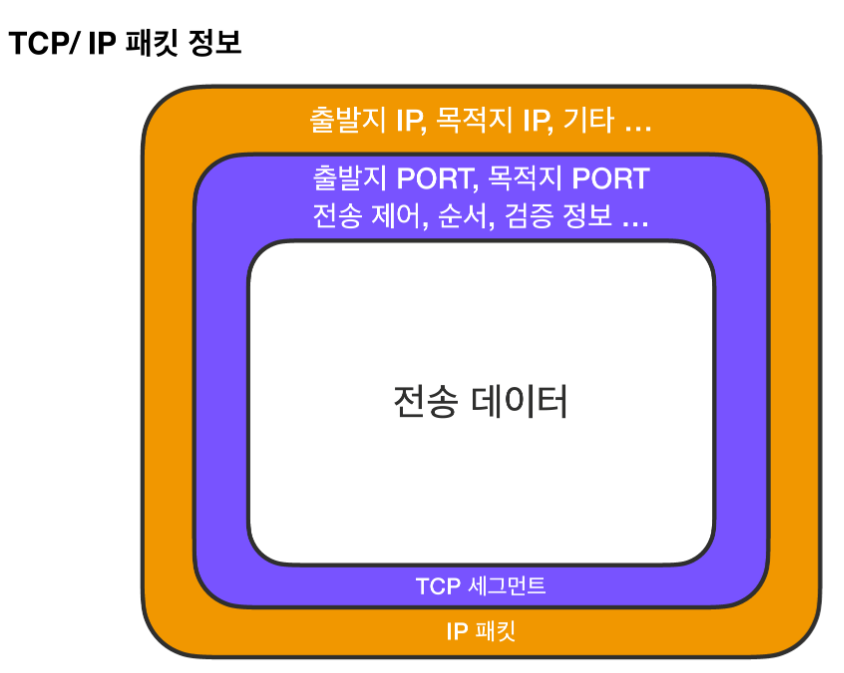
IP 패킷은 우체국 송장처럼 전송 데이터를 무사히 전송하기 위해 출발지 IP, 목적지 IP와 같은 정보가 포함되어 있습니다.
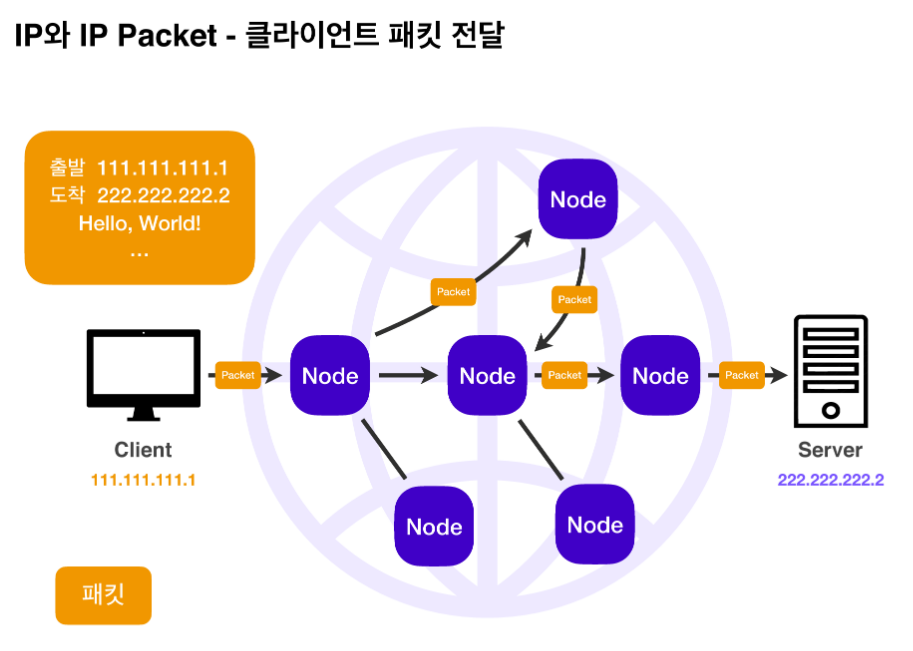
패킷 단위로 전송을 하면 노드들은 목적지 IP에 도달하기 위해 서로 데이터를 전달합니다.
이를 통해 복잡한 인터넷 망 사이에서도 정확한 목적지로 패킷을 전송할 수 있습니다.
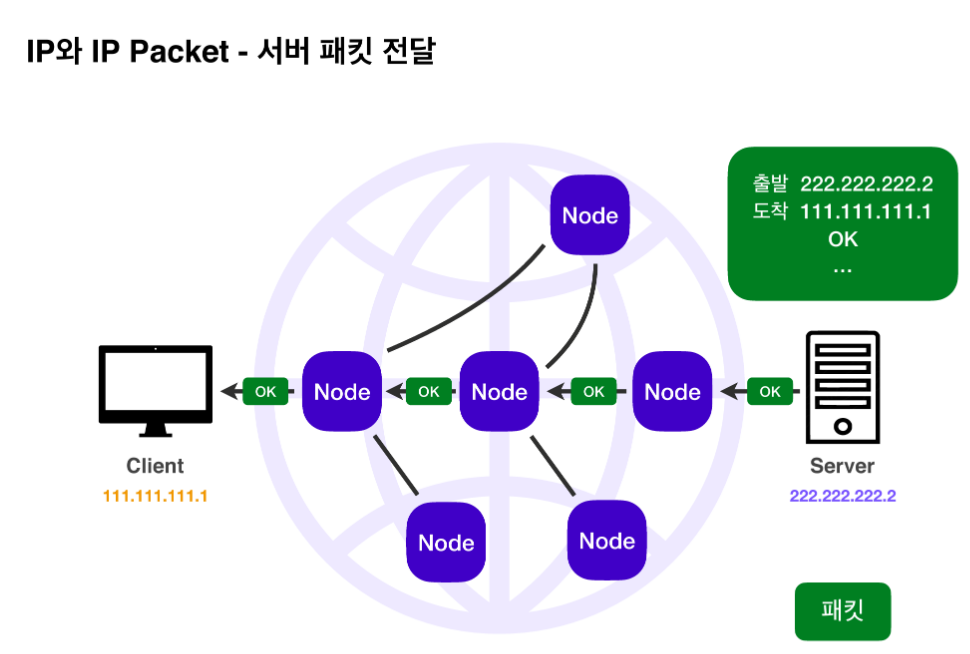
서버에서 무사히 데이터를 전송받는다면 서버도 이에 대한 응답을 돌려줘야 합니다.
서버 역시 IP 패킷을 이용해 클라이언트에 응답을 전달합니다.
IP/IP Packet 한계
정확한 출발지와 목적지를 파악할 수 있다는 점에서 인터넷 프로토콜은 적절한 통신 방법으로 보이지만, IP에도 한계가 존재합니다.
- 비연결성 : 패킷 받을 대상이 없거나 서비스 불능 상태여도 패킷 전송
- 비신뢰성 : 중간에 패킷이 사라질 수 있음, 패킷의 순서를 보장 할 수 없음
TCP/UDP Packet
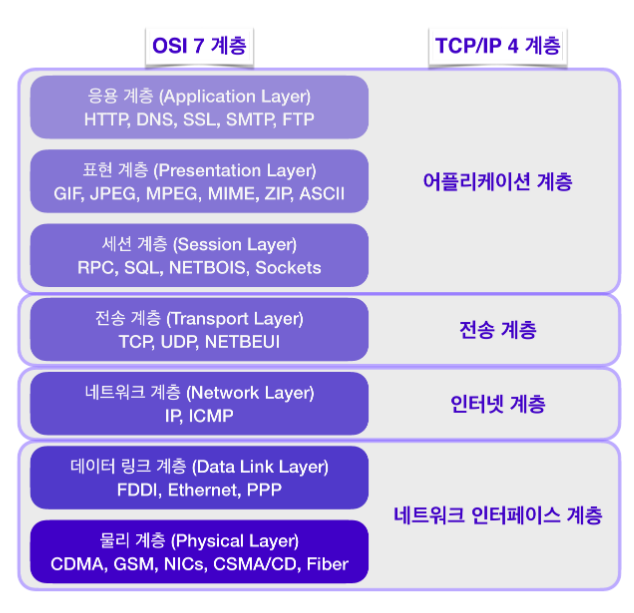
네트워크 프로토콜 계층은 OSI 7계층과 TCP/IP 4 계층으로 나눌 수 있습니다.
IP 프로토콜 보다 더 높은 계층에 TCP 프로토콜이 존재하기 때문에 앞서 다룬 IP 프로토콜의 한계를 보완할 수 있습니다.
TCP/IP 4 계층은 OSI 7 계층보다 먼저 개발되었으며 TCP/IP 프로토콜의 계층은 OSI 모델의 계층과 정확하게 일치하지는 않습니다. 실제 네트워크 표준은 업계표준을 따르는 TCP/IP 4 계층에 가깝습니다.
예) 채팅 프로그램에서 메시지를 보낼 때
먼저 HTTP 메시지가 생성되면 Socket을 통해 전달됩니다.
네트워크 소켓 : 프로그램이 네트워크에서 데이터를 송수신할 수 있도록, “네트워크 환경에 연결할 수 있게 만들어진 연결부“
그리고 IP 패킷을 생성하기 전 TCP 세그먼트를 생성합니다.
이렇게 생성된 TCP/IP 패킷은 LAN 카드와 같은 물리적 계층을 지나기 위해 이더넷 프레임 워크에 포함되어 서버로 전송됩니다.
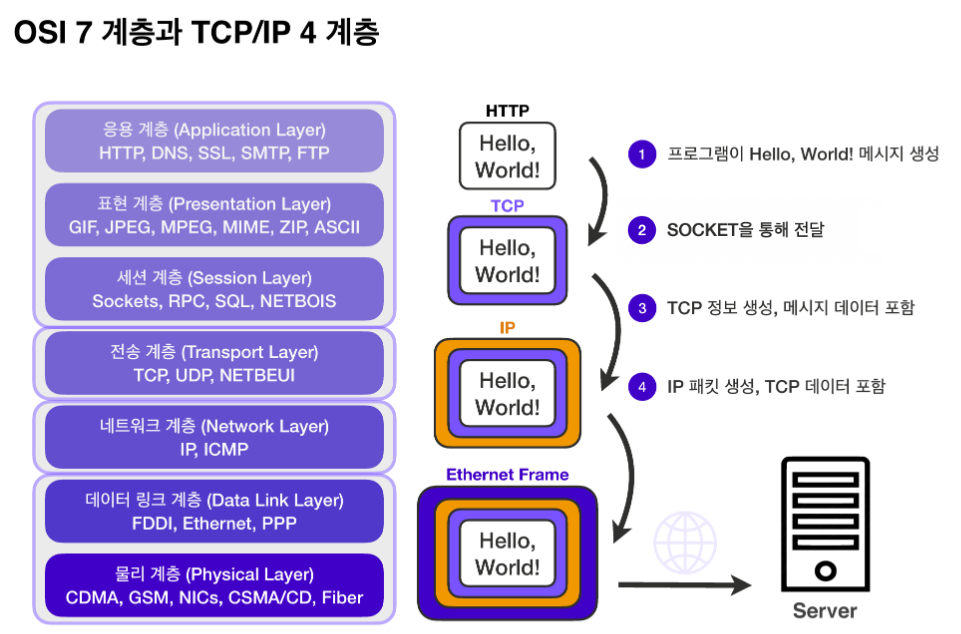
TCP/IP 패킷 : TCP 세그먼트에는 IP 패킷의 출발지 IP와 목적지 IP 정보를 보완할 수 있는 출발지 PORT, 목적지 PORT, 전송 제어, 순서, 검증 정보 등을 포함합니다.
TCP 특징(좋은 기능이 다 들어있는 무거운 라이브러리)
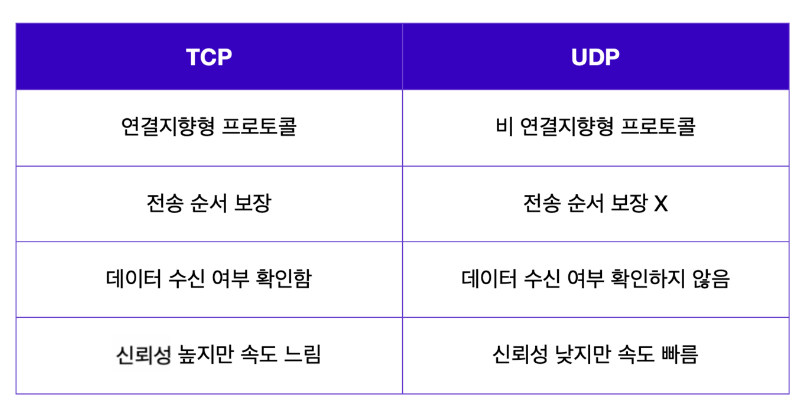
- 전송 제어 프로토콜(데이터 전송이 성공적으로 이루어진다면 이에 대한 응답을 돌려주므로 IP 패킷의 한계인 비연결성을 보완)
- 연결 지향 - TCP 3 way handshake(가상 연결)(장치들 사이에 논리적인 접속을 성립하기 위해)
- 순서 보장(만약 패킷이 순서대로 도착하지 않는다면 TCP 세그먼트에 있는 정보를 토대로 다시 패킷 전송 요청 가능, IP 패킷의 한계인 비신뢰성(순서를 보장하지 않음)을 보완)
- 같은 계층에 속한 UDP에 비해 상대적으로 신뢰할 수 있는 프로토콜
UDP 특징(필요한 기능만 들어있는 가벼운 라이브러리)
- UDP는 IP에 PORT, 체크섬 필드 정보만 추가된 단순한 프로토콜
- 사용자 데이터그램 프로토콜
- 하얀 도화지에 비유(기능이 거의 없음, 커스터마이징이 가능)
- 비 연결지향 - TCP 3 way handshake X
- 데이터 전달 보증 X
- 순서 보장 X
- 데이터 전달 및 순서가 보장되지 않지만, 단순하고 빠름
- 신뢰성 보다는 연속성이 중요한 서비스(ex.실시간 스트리밍)에 자주 사용됨.
네트워크 계층 모델
OSI 7계층 모델
ISO(International Organization for Standardization)라고 하는 국제표준화기구에서 1984년에 제정한 네트워크의 표준 규격
옛날에는 같은 회사에서 만든 컴퓨터끼리만 통신이 가능했던 시절이 있었는데,
다른 회사의 시스템이라도 네트워크 유형에 관계없이 상호 통신이 가능한 규약, 즉 프로토콜(Protocol)이 필요했습니다.
그래서 ISO에서는 제조사에 상관없이 공통으로 사용할 수 있는 네트워크 표준 규격을 정의했습니다.
OSI 7계층 모델은 네트워크를 이루고 있는 구성요소들을 7단계로 나누고, 각 계층의 표준을 정하였습니다.
OSI 7계층 모델의 목적은 표준화를 통하여 포트, 프로토콜의 호환 문제를 해결하고, 네트워크 시스템에서 일어나는 일을 해당 계층 모델을 이용해 쉽게 설명할 수 있습니다.
또한 네트워크 관리자가 문제가 발생 했을 때 이것이 물리적인 문제인지, 응용 프로그램과 관련이 있는지 등 원인이 어디에 있는지 범위를 좁혀 문제를 쉽게 파악할 수 있습니다.
즉 사이트에 접속되지 않는다고 해서 무작정 컴퓨터를 껐다 키는 일을 피할 수 있습니다.
OSI 7계층 모델은 각 컴퓨터간 데이터를 전송할 때 하드웨어 및 소프트웨어가 수행하는 기능에 따라 이를 7개의 계층으로 구분!
1계층 - 물리 계층: OSI 모델의 맨 밑에 있는 계층으로서, 시스템 간의 물리적인 연결과 전기 신호를 변환 및 제어하는 계층입니다. 주로 물리적 연결과 관련된 정보를 정의합니다. 주로 전기 신호를 전달하는데 초점을 두고, 들어온 전기 신호를 그대로 잘 전달하는 것이 목적입니다.
e.g. 디지털 또는 아날로그로 신호 변경
2계층 - 데이터링크 계층: 네트워크 기기 간의 데이터 전송 및 물리주소(e.g. MAC 주소)를 결정하는 계층입니다. 물리 계층에서 들어온 전기 신호를 모아 알아 볼 수 있는 데이터 형태로 처리 합니다. 이 계층에서는 주소 정보를 정의하고 출발지와 도착지 주소를 확인한 후, 데이터 처리를 수행합니다.
e.g. 브리지 및 스위치, MAC 주소
3계층 - 네트워크 계층: OSI 7 계층에서 가장 복잡한 계층 중 하나로서 실제 네트워크 간에 데이터 라우팅을 담당합니다. 이때 라우팅이란 어떤 네트워크 안에서 통신 데이터를 짜여진 알고리즘에 의해 최대한 빠르게 보낼 최적의 경로를 선택하는 과정을 라우팅이라고 합니다.
e.g. IP 패킷 전송
4계층 - 전송 계층: 컴퓨터간 신뢰성 있는 데이터를 서로 주고받을 수 있도록 하는 서비스를 제공하는 계층입니다. 하위 계층에서 신호와 데이터를 올바른 위치로 보내고 신호를 만드는데 집중했다면, 전송 계층에서는 해당 데이터들이 실제로 정상적으로 보내지는지 확인하는 역할을 합니다. 네트워크 계층에서 사용되는 패킷은 유실되거나 순서가 바뀌는 경우가 있는 데, 이를 바로 잡아주는 역할도 담당합니다.
e.g. TCP/UDP 연결
5계층 - 세션 계층: 세션 연결의 설정과 해제, 세션 메시지 전송 등의 기능을 수행하는 계층입니다. 즉, 컴퓨터간의 통신 방식에 대해 결정하는 계층이라고 할 수 있습니다. 쉽게 말해, 양 끝 단의 프로세스가 연결을 성립하도록 도와주고, 작업을 마친 후에는 연결을 끊는 역할을 합니다.
6계층 - 표현 계층: 응용 계층으로 전달하거나 전달받는 데이터를 인코딩 또는 디코딩하는 계층입니다. 일종의 번역기 같은 역할을 수행하는 계층이라고 볼 수 있습니다.
e.g. 문자 코드, 압축, 암호화 등의 데이터 변환
7계층 - 응용 계층: 최종적으로 사용자와의 인터페이스를 제공하는 계층으로 사용자가 실행하는 응용 프로그램(e.g. Google Chrome)들이 해당 계층에 속합니다.
e.g. 이메일 및 파일 전송, 웹 사이트 조회
데이터 캡슐화
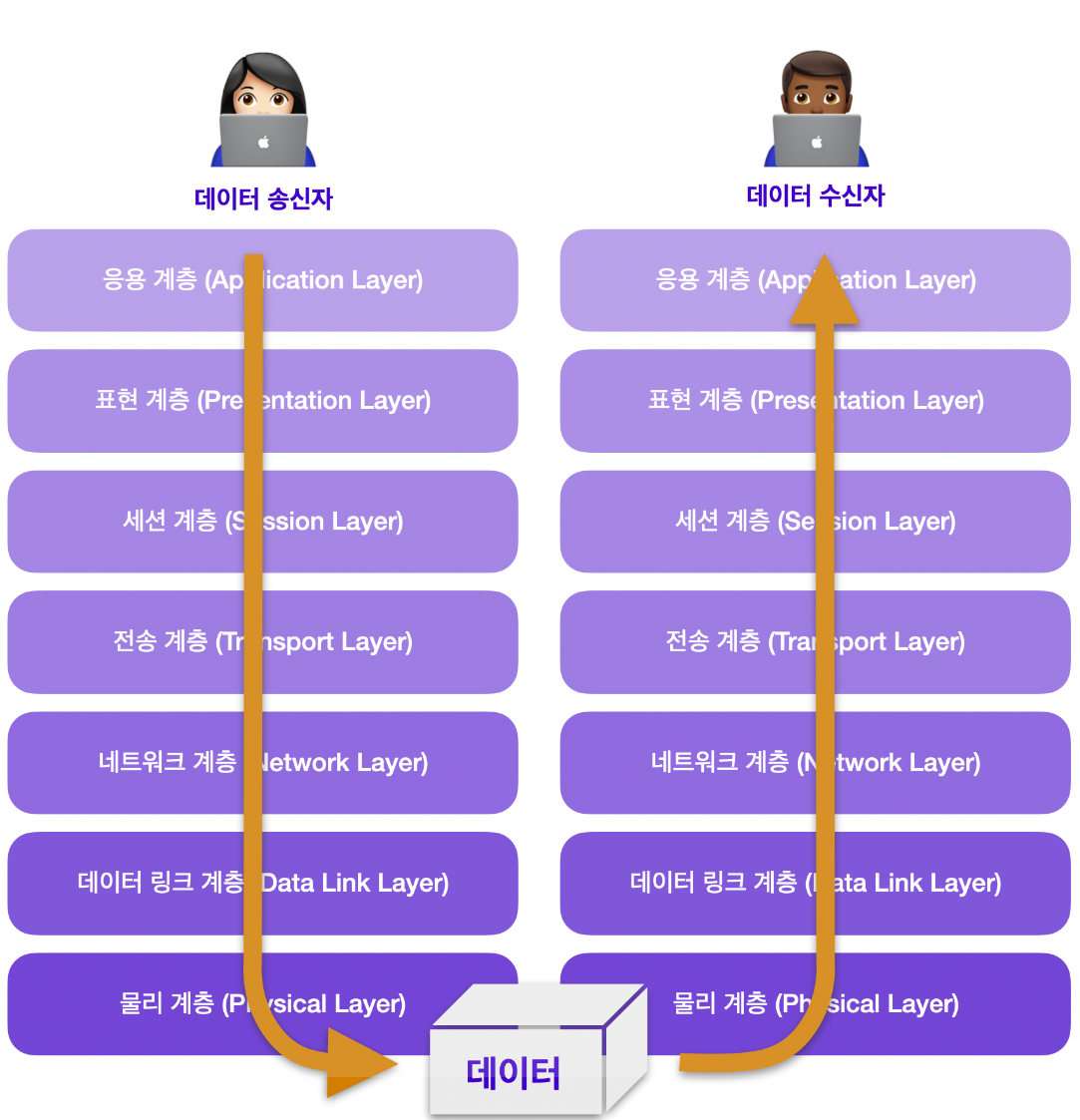
OSI 7계층 모델은 송신 측의 7계층과 수신 측의 7계층을 통해 데이터를 주고 받습니다.
각 계층은 독립적이므로 데이터가 전달되는 동안에 다른 계층의 영향을 받지 않습니다.
데이터를 전송하는 쪽은 데이터를 보내기 위해서 상위 계층에서 하위 계층으로 데이터를 전달합니다.
이때 데이터를 상대방에게 보낼 때 각 계층에서 필요한 정보를 데이터에 추가하는데 이 정보를 헤더(데이터링크 계층에서는 트레일러)라고 합니다. 그리고 이렇게 헤더를 붙여나가는 것을 캡슐화라고 합니다.
마지막 데이터가 전기 신호로 변환되어 수신 측에 전송됩니다.
데이터를 받는 쪽은 하위 계층에서 상위 계층으로 각 계층을 통해 전달된 데이터를 받게됩니다. 이때 상위 계층으로 데이터를 전달하며 각 계층에서 헤더(데이터링크 계층에서는 트레일러)를 제거해 나가는 것을 역캡슐화라고 합니다. 역캡슐화를 거쳐 마지막 응용 계층에 도달하면 드디어 전달하고자 했던 원본 데이터만 남게 됩니다.
TCP/IP 4계층 모델
TCP/IP 4계층 모델은 OSI 모델을 기반으로 실무적으로 이용할 수 있도록 현실에 맞춰 단순화된 모델입니다.
OSI 7계층 이론을 실제 사용하는, 즉 실용성에 기반을 둔 현대의 인터넷 표준이 TCP/IP 4계층이라고 할 수 있습니다.
TCP/IP 4계층 모델은 그림과 같이 응용 계층, 전송 계층, 인터넷 계층, 네트워크 접속 계층으로 이루어져 있습니다.
4계층: 어플리케이션 계층: OSI 계층의 세션 계층, 표현 계층, 응용 계층에 해당하며 TCP/UDP 기반의 응용 프로그램을 구현할 때 사용합니다.
e.g. FTP, HTTP, SSH
3계층: 전송 계층: OSI 계층의 전송 계층에 해당하며 통신 노드간의 연결을 제어하고, 신뢰성 있는 데이터 전송을 담당합니다.
e.g. TCP/UDP
2계층: 인터넷 계층: OSI 계층의 네트워크 계층에 해당하며 통신 노드 간의 IP 패킷을 전송하는 기능 및 라우팅을 담당합니다.
e.g. IP, ARP, RARP
1계층: 네트워크 인터페이스 계층: OSI 계층의 물리 계층과 데이터 링크 계층에 해당하며 물리적인 주소로 MAC을 사용합니다.
e.g. LAN, 패킷망 등에 사용됨
응용 계층
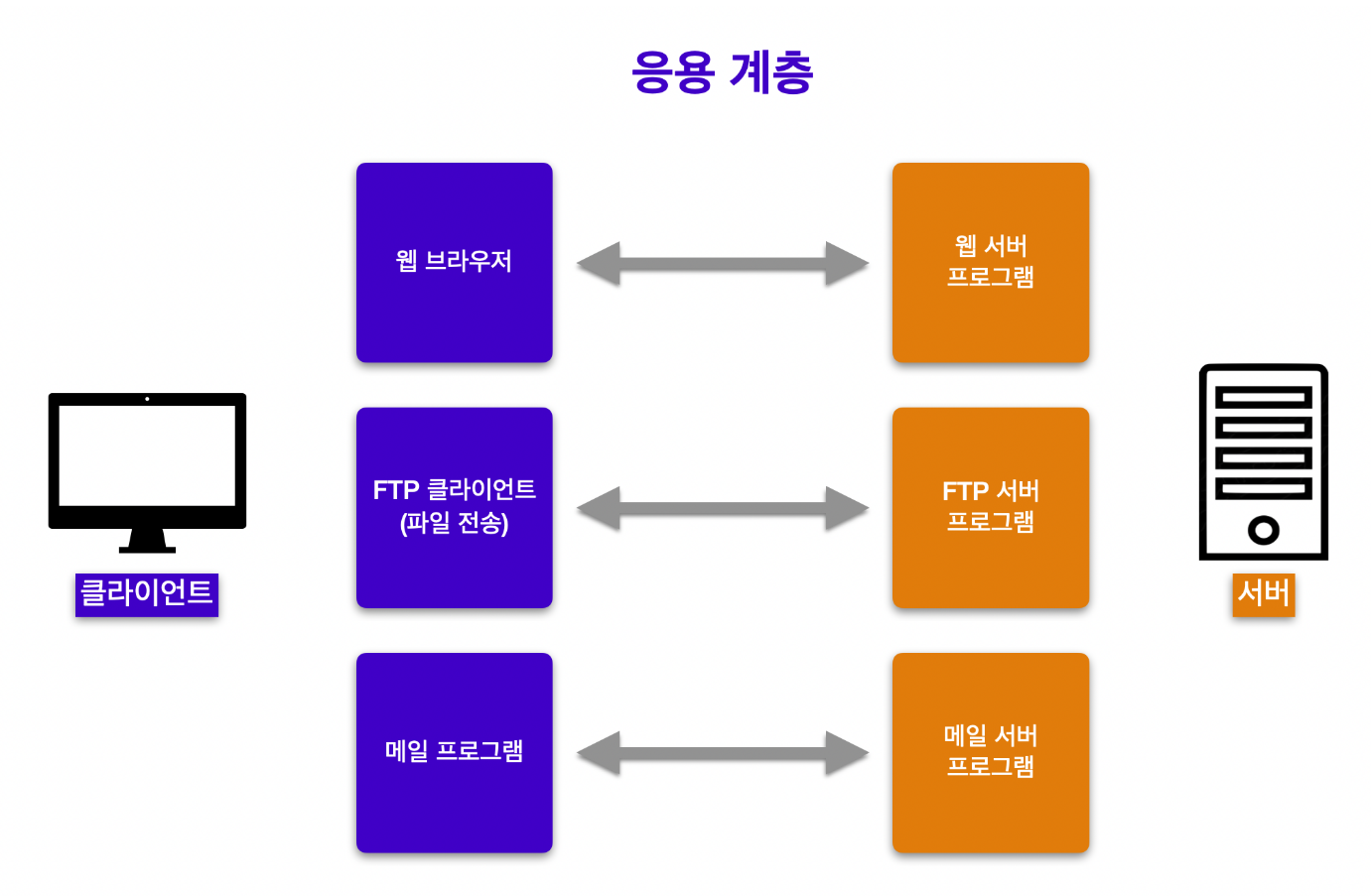
응용 계층은 네트워크 모델의 최상위 계층으로 최종적으로 사용자와의 인터페이스를 제공하는 계층입니다.
이메일, 파일 전송, 웹 사이트 조회 등 어플리케이션에 대한 서비스를 사용자에게 제공하는 계층입니다.
이때 어플리케이션은 서비스를 요청하는 측(사용자 측)에서 사용하는 어플리케이션과 서비스를 제공하는 측의 어플리케이션으로 분류됩니다. 일반적으로 서비스를 요청하는 측을 클라이언트, 서비스를 제공하는 측을 서버라고 합니다. 웹 브라우저(e.g. Google Chrome)나 메일 프로그램(e.g. Outlook)은 사용자 측에서 사용하는 어플리케이션이니 클라이언트에 속하는 반면, 서비스를 제공하는 측인 서버에는 웹 서버 프로그램과 메일 서버 프로그램 등이 있습니다. 클라이언트와 서버 모두 응용 계층에서 동작합니다.
HTTP
HTTP의 특징
HTTP/1.1, HTTP/2는 TCP 기반이며 HTTP/3는 UDP 기반 프로토콜입니다.
-
클라이언트가 서버에 요청을 보내면 서버는 그에 대한 응답을 보내는 클라이언트 서버 구조
-
HTTP에서는 서버가 클라이언트의 상태를 보존하지 않는 무상태 프로토콜
(장점은 서버확장성이 높음, 단점은 클라이언트가 추가 데이터 전송)상태유지 : 중간에 다른 점원으로 바뀌면 안됨(바뀐다면 상태 정보를 미리 알려줘야 함)
무상태 : 중간에 다른 점원으로 바뀌어도 된다.
갑자기 클라이언트 요청이 증가해도 서버를 대거 투입할 수 있다.
무상태는 응답 서버를 쉽게 바꿀 수 있다. -> 무한한 서버 증설 가능무상태의 실무한계
모든 것을 무상태로 설계할 수 있는 경우도 없는 경우도 있다.
무상태 - 로그인이 필요없는 단순한 서비스 소개 화면
상태유지 - 로그인
로그인한 사용자의 경우 로그인했다는 상태를 서버에 유지(브라우저쿠키, 서버세션, 토큰 등을 이용해 상태 유지한다.)
상태 유지는 최소한만 사용 -
비연결성
TCP/IP의 경우 기본적으로 연결을 유지합니다.
연결을 유지하는 모델에서는 클라이언트 1, 2는 요청을 보내지 않더라도 계속 연결을 유지해야 합니다.
이러한 경우 연결을 유지하는 서버의 자원이 계속 소모가 됩니다.
비연결성을 가지는 HTTP에서는 실제로 요청을 주고받을 때만 연결을 유지하고 응답을 주고 나면 TCP/IP 연결을 끊습니다.
이를 통해 최소한의 자원으로 서버 유지를 가능하게 합니다.HTTP는 기본이 연결을 유지하지 않는 모델
트래픽이 많지 않고, 빠른 응답을 제공할 수 있는 경우, 비연결성의 특징은 효율적으로 작동합니다.
예를 들어, 한 시간 동안 수천 명이 서비스를 사용해도, 실제 서버에서는 초당 처리 요청 개수는 수십 개에 불과합니다.
하지만 트래픽이 많고, 큰 규모의 서비스를 운영할 때에는 비연결성은 한계를 보입니다.비연결성의 한계
웹 브라우저로 사이트를 요청하면 HTML뿐만 아니라 자바스크립트, css, 추가 이미지 등 수많은 자원이 함께 다운로드됩니다.
해당 자원들을 각각 보낼 때마다 연결 끊고 다시 연결하고를 반복하는 것은 비효율적이기 때문에
지금은 HTTP 지속 연결(Persistent Connections)로 문제를 해결합니다.
HTTP 초기에는 각각의 자원을 다운로드하기 위해 연결과 종료를 반복해야 했습니다.
HTTP 지속 연결에서는 연결이 이루어지고 난 뒤 각각의 자원들을 요청하고 모든 자원에 대한 응답이 돌아온 후에 연결을 종료합니다. -
HTTP 메세지
-
단순함, 확장 가능
HTTP Headers의 종류와 특징
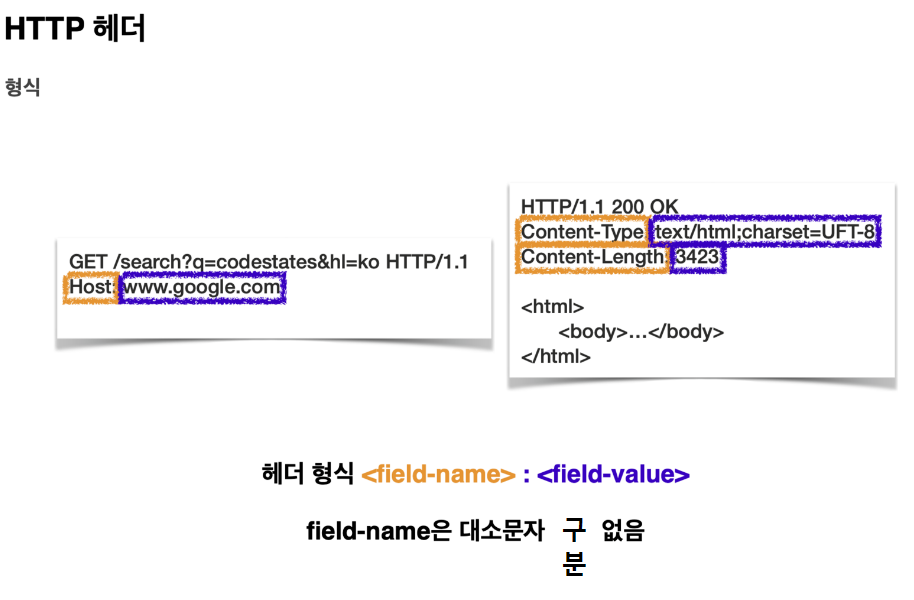
HTTP 메시지는 헤더와 바디로 구분할 수 있습니다.
HTTP 바디에서는 데이터 메시지 본문(Message body)을 통해서 표현(Representation) 데이터를 전달합니다.
여기서 데이터를 실어 나르는 부분을 페이로드(Payload)라 합니다.
표현은 요청이나 응답에서 전달할 실제 데이터를 뜻하며 표현 헤더는 표현 데이터를 해석할 수 있는 정보를 제공합니다.


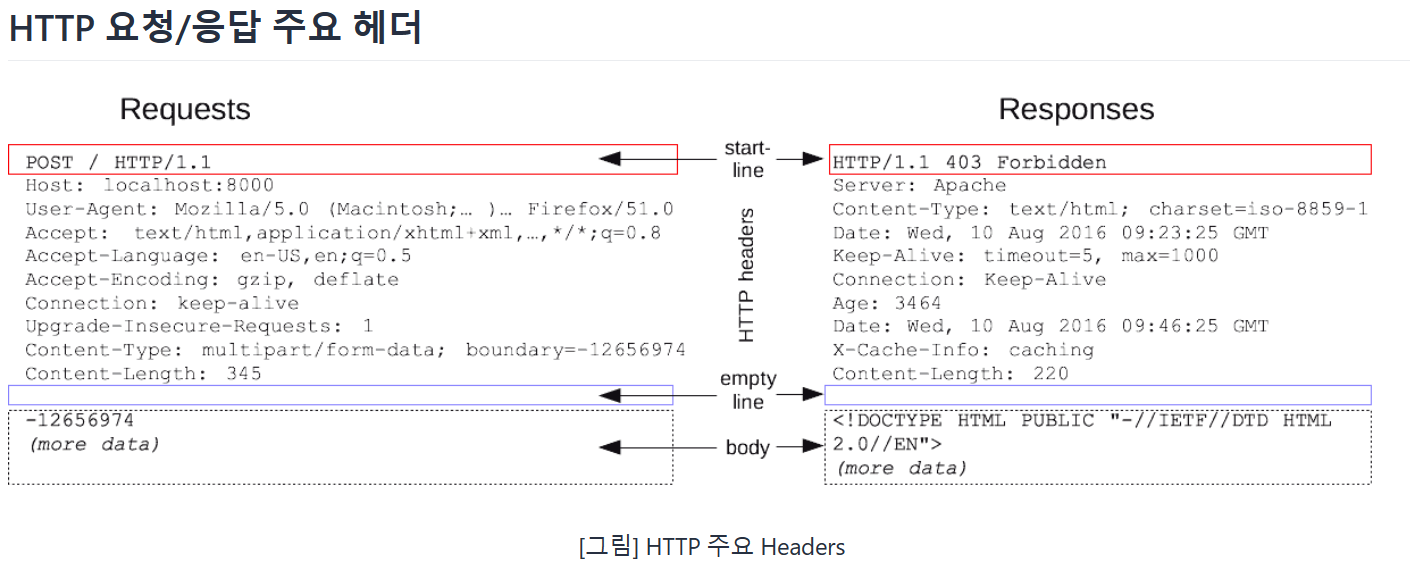
요청(Request)에서 사용되는 헤더
From: 유저 에이전트의 이메일 정보
일반적으로 잘 사용하지 않음
검색 엔진에서 주로 사용
요청에서 사용Referer: 이전 웹 페이지 주소
현재 요청된 페이지의 이전 웹 페이지 주소
A → B로 이동하는 경우 B를 요청할 때 Referer: A를 포함해서 요청
Referer를 사용하면 유입경로 수집 가능
요청에서 사용
referer는 단어 referrer의 오탈자이지만 스펙으로 굳어짐User-Agent: 유저 에이전트 애플리케이션 정보
클라이언트의 애플리케이션 정보(웹 브라우저 정보, 등등)
통계 정보
어떤 종류의 브라우저에서 장애가 발생하는지 파악 가능
요청에서 사용
e.g.
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/
537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36Host: 요청한 호스트 정보(도메인)
요청에서 사용
필수 헤더
하나의 서버가 여러 도메인을 처리해야 할 때 호스트 정보를 명시하기 위해 사용
하나의 IP 주소에 여러 도메인이 적용되어 있을 때 호스트 정보를 명시하기 위해 사용Origin: 서버로 POST 요청을 보낼 때, 요청을 시작한 주소를 나타냄
여기서 요청을 보낸 주소와 받는 주소가 다르면 CORS 에러가 발생한다.
응답 헤더의 Access-Control-Allow-Origin와 관련Authorization: 인증 토큰(e.g. JWT)을 서버로 보낼 때 사용하는 헤더
“토큰의 종류(e.g. Basic) + 실제 토큰 문자”를 전송
e.g.
Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
응답(Response)에서 사용되는 헤더
Server: 요청을 처리하는 ORIGIN 서버의 소프트웨어 정보
응답에서 사용
e.g.
Server: Apache/2.2.22 (Debian)
Server: nginxDate: 메시지가 발생한 날짜와 시간
응답에서 사용
e.g.
Date: Tue, 15 Nov 1994 08:12:31 GMTLocation: 페이지 리디렉션
웹 브라우저는 3xx 응답의 결과에 Location 헤더가 있으면, Location 위치로 리다이렉트(자동 이동)
201(Created): Location 값은 요청에 의해 생성된 리소스 URI
3xx(Redirection): Location 값은 요청을 자동으로 리디렉션하기 위한 대상 리소스를 가리킴Allow: 허용 가능한 HTTP 메서드
405(Method Not Allowed)에서 응답에 포함
e.g.
Allow: GET, HEAD, PUTRetry-After: 유저 에이전트가 다음 요청을 하기까지 기다려야 하는 시간
503(Service Unavailable): 서비스가 언제까지 불능인지 알려줄 수 있음
e.g.
Retry-After: Fri, 31 Dec 2020 23:59:59 GMT(날짜 표기)
Retry-After: 120(초 단위 표기)
HTTPS
HTTPS는 HTTP Secure의 약자로, 단어 뜻 그대로 기존의 HTTP 프로토콜을 더 안전하게(Secure) 사용할 수 있음을 의미합니다.
HTTPS가 HTTP와 달리 요청과 응답으로 오가는 내용을 암호화합니다.
제 3자가 HTTP 요청 및 응답을 탈취한다면 전달되는 데이터의 내용을 그대로 확인할 수 있습니다.
HTTPS 요청 및 응답은 중간에 제 3자에게 데이터가 탈취되더라도 그 내용을 알아볼 수 없습니다.
암호화 방식
데이터를 암호화를 할 때에는 암호화할 때 사용할 키, 암호화한 것을 해석(복호화)할 때 사용할 키가 필요합니다. 이 때 암호화와 복호화할 때 사용하는 키가 동일하다면 대칭 키 암호화 방식, 다르다면 공개 키(비대칭 키) 암호화 방식이라고 합니다.

-
대칭 키 암호화 방식
대칭 키 암호화 방식은 하나의 키만 사용합니다. 암호화할 때 사용한 키로만 복호화가 가능합니다.
두 개의 키를 사용해야하는 공개 키 방식에 비해서 연산 속도가 빠르다는 장점이 있습니다. 하지만 키를 주고 받는 과정에서 탈취 당했을 경우에는 암호화가 소용없어지기 때문에 키를 관리하는데 신경을 많이 써야 합니다. -
공개 키(비대칭 키) 암호화 방식
비대칭 키 암호화 방식은 두 개의 키를 사용합니다. 암호화할 때 사용한 키와 다른 키로만 복호화가 가능합니다.
여기서 두 개의 키를 각각 공개 키, 비밀 키 라고 부릅니다. 여기서 공개 키는 이름 그대로 공개되어 있기 때문에 누구든지 접근 가능합니다. 누구든 이 공개 키를 사용해서 암호화한 데이터를 보내면, 비밀 키를 가진 사람만 그 내용을 복호화할 수 있습니다. 보통 요청을 보내는 사용자가 공개 키를, 요청을 받는 서버가 비밀 키를 가집니다. 이 때, 비밀 키는 서버가 해킹당하는 게 아닌 이상 탈취되지 않습니다.
이러한 공개 키 방식은 공개 키를 사용해 암호화한 데이터가 탈취 당한다고 하더라도, 비밀 키가 없다면 복호화할 수 없으므로 대칭 키 방식보다 보안성이 더 좋습니다. 하지만 대칭 키 방식 보다 더 복잡한 연산이 필요하여 더 많은 시간을 소모한다는 단점이 있습니다.
SSL/TLS 프로토콜
HTTPS는 HTTP 통신을 하는 소켓 부분에서 SSL 혹은 TLS라는 프로토콜을 사용하여 서버 인증과 데이터 암호화를 진행합니다.
여기서 SSL이 표준화되며 바뀐 이름이 TLS이므로 사실상 같은 프로토콜이라고 생각하시면 됩니다.
SSL/TLS는 특징
- CA를 통한 인증서 사용
- 대칭 키, 공개 키 암호화 방식을 모두 사용
<SSL/TLS 프로토콜의 서버 인증과 데이터 암호화를 진행하는 과정>
인증서와 CA(Certificate Authority)
HTTPS를 사용하면 브라우저가 서버의 응답과 함께 전달된 인증서를 확인할 수 있습니다. 이러한 인증서는 서버의 신원을 보증해줍니다. 이때 인증서를 발급해주는 공인된 기관들을 Certificate Authority, CA라고 부릅니다.
서버는 인증서를 발급받기 위해서 CA로 서버의 정보와 공개 키를 전달합니다. CA는 서버의 공개 키와 정보를 CA의 비밀 키로 암호화하여 인증서를 발급합니다. (이 비밀키가 해커에게 유출되어 파산한 CA도 있습니다.)
서버는 클라이언트에게 요청을 받으면 CA에게 발급받은 인증서를 보내줍니다. 이 때, 사용자가 사용하는 브라우저는 CA들의 리스트와 공개 키를 내장하고 있습니다. 우선 해당 인증서가 리스트에 있는 CA가 발급한 인증서인지 확인하고, 리스트에 있는 CA라면 해당하는 CA의 공개 키를 사용해서 인증서의 복호화를 시도합니다.
CA의 비밀 키로 암호화된 데이터(인증서)는 CA의 공개 키로만 복호화가 가능하므로, 정말로 CA에서 발급한 인증서가 맞다면 복호화가 성공적으로 진행되어야 합니다.
복호화가 성공적으로 진행 된다면, 클라이언트는 서버의 정보와 공개 키를 얻게 됨과 동시에 해당 서버가 신뢰할 수 있는 서버임을 알 수 있게 됩니다.
복호화가 실패한다면, 이는 서버가 보내준 인증서가 신뢰할 수 없는 인증서임을 확인하게 됩니다.
대칭 키 전달
이제 사용자는 서버의 인증서를 성공적으로 복호화하여 서버의 공개 키를 확보했습니다. 그럼 이 공개 키를 사용해서 데이터를 암호화하여 요청과 응답을 주고 받게 될까요? 안타깝게도, 이 공개 키는 해당 용도로는 사용할 수 없습니다. 공개 키 암호화 방식은 보안은 확실하지만, 복잡한 연산이 필요하여 더 많은 시간을 소모합니다. 따라서 모든 요청에서 공개 키 암호화 방식을 사용하는 것은 효율이 좋지 않습니다.
그렇다면 이 공개 키는 어디에 쓰는 걸까요? 바로 클라이언트와 서버가 함께 사용하게 될 대칭 키를 주고 받을 때 쓰게 됩니다. 대칭 키는 속도는 빠르지만, 오고 가는 과정에서 탈취될 수 있다는 위험성이 있었습니다. 하지만 클라이언트가 서버로 대칭 키를 보낼 때 서버의 공개 키를 사용해서 암호화하여 보내준다면, 서버의 비밀 키를 가지고 있는게 아닌 이상 해당 대칭 키를 복호화할 수 없으므로 탈취될 위험성이 줄어듭니다.
클라이언트는 데이터를 암호화하여 주고받을 때 사용할 대칭 키를 생성합니다. 대칭 키를 생성하는 데에는 더 복잡한 과정이 있지만, 일단은 대칭 키를 만든다는 것만 알아두세요. 클라이언트는 생성한 대칭 키를 서버의 공개 키로 암호화하여 전달합니다. 서버는 전달받은 데이터를 비밀 키로 복호화하여 대칭 키를 확보합니다. 이렇게 서버와 클라이언트는 동일한 대칭 키를 갖게되었습니다.
이제 HTTPS 요청을 주고 받을 때 이 대칭 키를 사용하여 데이터를 암호화하여 전달하게 됩니다. 대칭 키 자체는 오고 가지 않기 때문에 키가 유출될 위험이 없어졌습니다. 따라서 요청이 중간에 탈취 되어도 제 3자가 암호화된 데이터를 복호화할 수 없게 됩니다. HTTPS는 이러한 암호화 과정을 통해 HTTP보다 안전하게 요청과 응답을 주고받을 수 있게 해줍니다.
정리하자면, 이렇게 서버와 클라이언트간의 CA를 통해 서버를 인증하는 과정과 데이터를 암호화하는 과정을 아우른 프로토콜을 SSL 또는 TLS이라고 말하고, HTTP에 SSL/TLS 프로토콜을 더한 것을 HTTPS라고 합니다.
