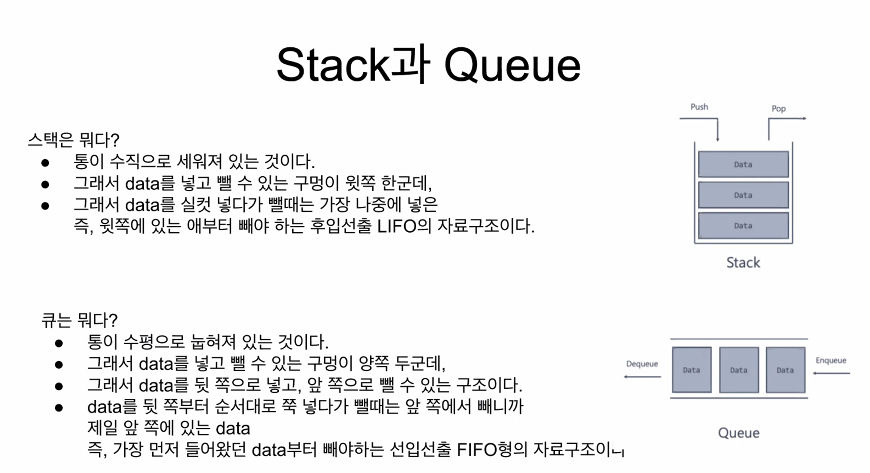
Stack
Stack의 정의
Stack은 쌓다, 쌓이다, 포개지다 와 같은 뜻을 가지고 있습니다. 마치 접시를 쌓아 놓은 형태와 비슷한 이 자료구조는 직역 그대로, 데이터(data)를 순서대로 쌓는 자료구조입니다.
ex. 동그란 원통에 차례대로 구슬을 넣는다고 상상해보세요. 우리는 원통의 맨 위에 뚫려있는 구멍을 통해 구슬을 넣을 수 있고, 구술을 뺄 때 또한 원통의 맨 위에 뚫려있는 구멍을 통해 맨 위에 있는 구슬을 먼저 뺄 수 있습니다.
Stack의 구조
원통을 자료구조 Stack, 구슬을 데이터(data)로 비유할 수 있습니다.
우리가 구슬을 차례대로 원통에 넣었을 때 가장 나중에 넣은 구슬이 원통의 가장 상단에 자리 잡고 있고,
그렇기 때문에 구슬을 빼는 경우에 가장 나중에 넣었던, 원통 상단에 위치한 구슬을 가장 먼저 뺄 수 있습니다.
자료구조 Stack의 특징은 입력과 출력이 하나의 방향, 즉 스택의 최상단에서만 이루어지는 제한적 접근에 있습니다.
이런 Stack 자료구조의 정책을 LIFO(Last In First Out) 혹은 FILO(First In Last Out)라고 부르기도 합니다.
Stack에 데이터를 넣는 것을 'PUSH', 데이터를 꺼내는 것을 'POP'이라고 합니다.
Stack의 특징
LIFO(Last In First Out)
1.먼저 들어간 데이터는 제일 나중에 나오는 후입선출의 구조로 되어 있습니다.
예1) 1, 2, 3, 4를 스택에 차례대로 넣습니다.
stack.push(데이터)
| 4 | <- top
| 3 |
| 2 |
| 1 |
들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됩니다.
예2) 스택이 빌 때까지 데이터를 전부 빼냅니다.
stack.pop()
| |
| |
| |
| |
4, 3, 2, 1
제일 마지막에 있는 데이터부터 차례대로 나오게 됩니다.이러한 특성으로 인해 스택 구조 내에서 특정 데이터를 조회할 수 없으며, 스택의 최상단에서만 데이터를 저장하고 꺼낼 수 있는 특징이 있습니다.
그 때문에 데이터를 저장할 때나 검색할 때 항상 스택의 최상단에서만 행위가 이루어지며 이에 따라 데이터를 저장하고 검색하는 프로세스가 매우 빠릅니다.
2. 하나의 입출력 방향을 가지고 있습니다.
Stack 자료구조는 데이터를 넣고 뺄 수 있는 곳이 스택의 가장 최상단, 한 군데입니다. 즉 데이터를 넣을 때도 스택의 가장 최상단으로 넣고(입력) 뺄 때 또한 스택의 가장 최상단으로 데이터를 뺄 수(출력) 있습니다.
3. 데이터는 하나씩 넣고 뺄 수 있습니다.
앞서 말했듯, Stack 자료구조는 데이터를 넣고 뺄 수 있는 경로가 스택의 최상단, 한 군데이기 때문에 스택 내부에 데이터를 넣을 때도 하나씩 최상단을 통해 넣고 데이터를 뺄 때 또한 항상 스택 최상단에서 하나씩 데이터를 뺄 수 있습니다.
즉, 스택에 한개 씩 여러 번 데이터를 넣어 스택 내부에 데이터가 여러 개 쌓여 있다고 하더라도, 데이터를 뺄 때는 스택의 가장 최상단에서 한 번에 한 개의 데이터만을 뺄 수 있습니다.
Stack 예제
대표적으로 우리가 브라우저의 뒤로 가기, 앞으로 가기 기능을 구현할 때 자료구조 Stack이 활용됩니다.
<브라우저에서 자료구조 Stack의 사용 순서>
1. 새로운 페이지로 접속할 때, 현재 페이지를 Prev Stack에 보관합니다.
2. 뒤로 가기 버튼을 눌러 이전 페이지로 돌아갈 때는, 현재 페이지를 Next Stack에 보관하고 Prev Stack에 가장 나중에 보관된 페이지를 현재 페이지로 가져옵니다.
3. 앞으로 가기 버튼을 눌러 앞서 방문한 페이지로 이동을 원할 때는, Next Stack의 가장 마지막으로 보관된 페이지를 가져옵니다.
4. 마지막으로 현재 페이지를 Prev Stack에 보관합니다.
이렇게 자료구조 Stack을 이용하면, 뒤로 가기와 앞으로 가기 버튼을 구현할 수 있습니다.
const stack = new Stack(); // Stack은 사전에 정의된 것으로 가정합니다.
stack.push(1);
stack.push(2);
console.log(stack.pop()); //2
stack.push(3);
consolt.log(stack.pop()); //3
stack.push(4);
console.log(stack.pop()); // 4
console.log(stack.pop()); //1Queue
Queue의 정의
큐(Queue)는 줄을 서서 기다리다, 대기행렬이라는 뜻을 가지고 있습니다. 어떤 구조로 되어 있는지 짐작할 수 있나요?
명절에는 고향으로 가기 위해 많은 자동차가 고속도로를 지납니다. 고속도로에는 톨게이트가 있고, 자동차는 톨게이트에 진입한 순서대로 통행료를 내고 톨게이트를 통과합니다.
톨게이트를 Queue 자료구조, 자동차는 데이터(data)로 비유할 수 있습니다.
가장 먼저 진입한 자동차가 가장 먼저 톨게이트를 통과합니다. 다시 말해, 가장 나중에 진입한 자동차는 먼저 도착한 자동차가 모두 빠져나가기 전까지는 톨게이트를 빠져나갈 수 없다는 말입니다.
Queue의 구조
자료구조 Queue는 Stack과 반대되는 개념으로, 먼저 들어간 데이터(data)가 먼저 나오는 FIFO(First In First Out) 혹은 LILO(Last In Last Out) 을 특징으로 가지고 있습니다. 티켓을 사려고 줄을 서서 기다리는 모습과 흡사한 이 자료구조는 입력의 방향과 출력의 방향이 각각 고정되어 있으며, 데이터를 입력할 시에는 큐의 끝에서(tail), 데이터를 출력할 때는 큐의 맨 앞에서(head) 진행됩니다.
Queue에 데이터를 넣는 것을 'enqueue', 데이터를 꺼내는 것을 'dequeue'라고 합니다.
자료구조 Queue는 데이터(data)가 입력된 순서대로 처리할 때 주로 사용합니다.
Queue의 특징
FIFO (First In First Out)
- 먼저 들어간 데이터가 제일 처음에 나오는 선입선출의 구조로 되어 있습니다.
예1) 1, 2, 3, 4를 큐에 차례대로 넣습니다.
queue.enqueue(데이터)
출력 방향(head) <---------------------------< 입력 방향(tail)
1 <- 2 <- 3 <- 4
<---------------------------<
들어간 순서대로, 1번이 제일 먼저 들어가고 4번이 마지막으로 들어가게 됩니다.
예2) 큐가 빌 때까지 데이터를 전부 빼냅니다.
queue.dequeue(데이터)
출력 방향(head) <---------------------------< 입력 방향(tail)
<---------------------------<
1, 2, 3, 4
제일 첫 번째 있는 데이터부터 차례대로 나오게 됩니다.-
두 개의 입출력 방향을 가지고 있습니다.
Queue 자료구조는 데이터의 입력, 출력 방향이 다릅니다.
데이터를 입력할 때는 큐의 맨 끝(tail)으로만 입력이 가능하며 데이터를 출력할 때는 큐의 맨 앞(head)으로만 출력이 가능합니다.
즉, 큐는 데이터를 입력하는 곳과 출력하는 곳이 각각 정해져 있으며 이렇게 총 2개의 입출력 방향을 가지고 있습니다.
만약 입출력 방향이 같다면 Queue 자료구조라고 볼 수 없습니다. -
데이터는 하나씩 넣고 뺄 수 있습니다.
앞서 말했듯, Queue 자료구조는 데이터를 넣을 때는 큐의 맨 뒷 부분에서 뺄 때는 큐의 맨 앞부분에서 처리를 진행합니다. 각 처리 시마다 한 개의 데이터를 넣거나 뺄 수 있습니다.
즉, 큐에 한 개 씩 여러 번 데이터를 넣어 큐 내부에 데이터가 여러 개 쌓여 있다고 하더라도, 데이터를 뺄 때는 큐의 맨 앞에서 한 번에 한 개의 데이터만을 뺄 수 있습니다.
Queue의 사용 예제
자료구조 Queue는 컴퓨터에서도 광범위하게 활용됩니다. 컴퓨터와 연결된 프린터에서 여러 문서를 순서대로 인쇄하려면 어떻게 해야 할까요?
우리가 문서를 작성하고 출력 버튼을 누르면 해당 문서는 인쇄 작업 (임시 기억 장치의) Queue에 들어갑니다.
프린터는 인쇄 작업 Queue에 들어온 문서를 들어온 순서대로 인쇄합니다.
컴퓨터(출력 버튼) - (임시 기억 장치의) Queue에 하나씩 들어옴 - Queue에 들어온 문서를 들어온 순서대로 인쇄
만약 Queue에 들어온 순서대로 출력하지 않는다면, 인쇄 결과물이 뒤죽박죽일 겁니다.
컴퓨터 장치들 사이에서 데이터(data)를 주고받을 때, 각 장치 사이에 존재하는 속도의 차이나 시간 차이을 극복하기 위해 임시 기억 장치의 자료구조로 Queue를 사용합니다. 이것을 통틀어 버퍼(buffer)라고 합니다.
대부분의 컴퓨터 장치에서 발생하는 이벤트는 파동 그래프와 같이 불규칙적으로 발생합니다. 이에 비해 CPU와 같이 발생한 이벤트를 처리하는 장치는 일정한 처리 속도를 갖습니다. 불규칙적으로 발생한 이벤트를 규칙적으로 처리하기 위해 버퍼(buffer)를 사용합니다.
컴퓨터와 프린터 사이의 데이터(data) 통신을 정리하면 다음과 같습니다.
일반적으로 프린터는 속도가 느립니다.
CPU는 프린터와 비교하여, 데이터를 처리하는 속도가 빠릅니다.
따라서, CPU는 빠른 속도로 인쇄에 필요한 데이터(data)를 만든 다음, 인쇄 작업 Queue에 저장하고 다른 작업을 수행합니다.
프린터는 인쇄 작업 Queue에서 데이터(data)를 받아 들어온 순서대로 일정한 속도로 인쇄합니다.
유튜브와 같은 동영상 스트리밍 앱을 통해 동영상을 시청할 때, 다운로드 된 데이터(data)가 영상을 재생하기에 충분하지 않은 경우가 있습니다. 이때 동영상을 정상적으로 재생하기 위해 Queue에 모아 두었다가 동영상을 재생하기에 충분한 양의 데이터가 모였을 때 동영상을 재생합니다.
원형 큐 (Circular Queue)
선형큐의 단점
1) 큐 사이즈에 데이터가 꽉 찼다면 데이터를 더 추가할 수 없습니다.
2)공간의 효율성을 고려해야합니다. 배열로 단순히 구현하면 front가 뒤로 계속 밀려 앞의 공간이 남게 되죠. 그러니까 하나의 원소가 빠져나가면 그 다음부터 모든 녀석들을 앞으로 당겨와야하니까 속도 측면에서 상당히 느립니다. 작은 데이터들이라면 물론 상관없지만, 요즘처럼 사이즈가 크고 많은 데이터를 처리하기에는 무리입니다.
선형큐의 단점을 보완할 수 있는 큐로는 바로 원형큐가 있습니다.
큐를 직선 형태로 놓는 것 보다 원형으로 생각해서 큐를 구현하는 것으로, 큐를 원형으로 생각해야되기 때문에 모듈러 연산(나머지 연산)을 해야합니다.
원형큐의 장점
dequeue시 shift 연산을 하지 않는다. 따라서 배열 인덱스를 재배치할 필요가 없기 선형 큐에 비해 메모리 사용량이 훨씬 적다.
//배열 생성
//사이즈가 5인 배열을 만들고, null로 해당 배열을 채운다.
const size = 5
const cq = Array(size).fill(null)
//enqueue시 삽입할 위치를 가르키는 포인터=head=front
//dequeue시 삭제할 위치를 가르키는 포인터=tail=rear
let front = 0;
let rear = 0
// front === rear 이면 원형 큐가 비어있음을 알 수 있다
const isEmpty = () => rear === front;
//enqueue하기 위해, 포인터들의 위치를 결정해야 하는데, 이때 나머지 연산자(%)를 사용한다.
//(정수 % queue의 size)의 연산을 하게되면, queue의 size안에서 순환하는 인덱스를 얻을수 있다.
//현재 rear의 위치에 a를 삽입하고 rear를 한칸 앞으로 옮긴다.
const enqueue = (item) => {
cq[rear] = item;
rear = (rear + 1) % size;
return item;
};
enqueue("a")
enqueue("b")
enqueue("c")
enqueue("d")
enqueue("e")
//dequeue는 front 포인터가 가르키는곳의 요소를 제거하고, front를 1칸 앞으로 이동시킨다.
const dequeue = () => {
const val = cq[front];
cq[front] = null;
front = (front + 1) % size;
return val;
};
dequeue()
//만약 dequeue를 한번도 하지않고 enqueue를 계속해서 실행하면, front와 rear의 위치는 같아지게 될것이다.
//const isEmpty = () => rear === front; 이 논리대로라면,
//배열이 꽉 차있는데도 Empty가 true가 된다.
//이를 방지하기 위한 테크닉으로, 배열 한칸을 추가해 항상 비워놓고 사용 하지 않는다.
//사이즈가 n인 원형큐를 만들고 싶다면, n+1의 배열을 생성하면 되는것이다.
const size = 6;
const cq = Array(size).fill(null);
...
enqueue("a")
enqueue("b")
enqueue("c")
enqueue("d")
enqueue("e")
//이렇게 구조를 변경한다면, 현재 상태가 Full인지 혹은 Empty인지 명확하게 알 수 있다.
const isFull = () => (rear + 1) % size === front;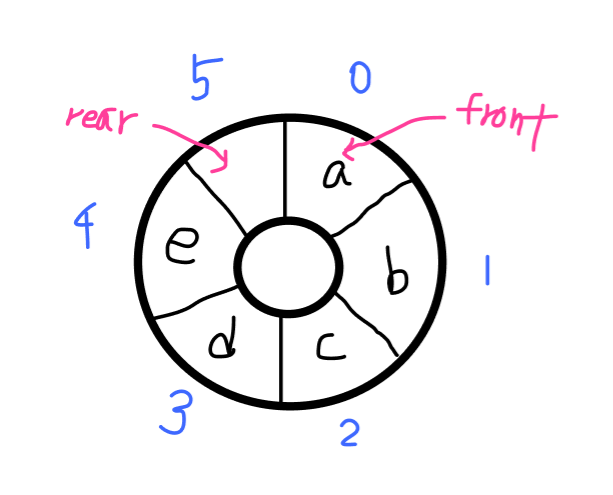
//전체 코드
const size = 6;
const cq = Array(size).fill(null);
let front = 0;
let rear = 0;
const isEmpty = () => rear === front;
const isFull = () => (rear + 1) % size === front;
const enqueue = (item) => {
if (isFull()) {
console.log("큐가 가득참");
return;
}
cq[rear] = item;
rear = (rear + 1) % size;
return item;
};
const dequeue = () => {
if (isEmpty()) {
console.log("큐가 비어있음");
return;
}
const item = cq[front];
cq[front] = null;
front = (front + 1) % size;
return item;
};
/* 큐의 가장 앞에있는 요소를 얻음 */
const peek = () => cq[front];
/* 큐의 모든 요소가 null이 될때까지 dequeue를 실행 */
const clear = () => {
while (true) {
if (!dequeue()) break;
}
front = rear;
};Using stack and queue as JavaScript array
직접 사용자 정의 데이터 타입을 구현해서 Stack과 Queue를 사용해도 좋습니다. 그러나 JavaScript에는 Array라는 훌륭한 자료형이 이미 있습니다. Array를 사용하면 사용자 정의 데이터 타입을 구현하는 시간을 절약할 수 있고, 몇 가지의 메서드로 Stack과 Queue처럼 동작하도록 사용할 수 있습니다.
자료구조로써 Stack과 Queue의 특성만 이해한다면, Array를 활용하여 Stack과 Queue로 사용할 수 있습니다.
다시 말해 자료구조는 자료(데이터)를 다루는 구조 그 자체를 뜻하며, 구현하는 방식에는 제약이 없습니다.
배열로 자료구조 Stack 구현하기
//const stack = new Array(); 미리 정의된 Array 객체를 사용할 수 있습니다.
const stack = [];
stack.push(1); // [1]
stack.push(2); // [1, 2]
stack.push(3); // [1, 2, 3]
stack.push(4); // [1, 2, 3, 4]
stack.push(5); // [1, 2, 3, 4, 5]
console.log(stack); // [1, 2, 3, 4, 5]
//제일 마지막에 들어간 요소부터 빼내기 위해 pop() 메소드를 사용합니다.
stack.pop(); // [1, 2, 3, 4]
stack.pop(); // [1, 2, 3]
console.log(stack); // [1, 2, 3]배열로 자료구조 Queue 구현하기
//const queue = new Array(); 미리 정의된 Array 객체를 사용할 수 있습니다.
const queue = [];
queue.push(1); // [1]
queue.push(2); // [1, 2]
queue.push(3); // [1, 2, 3]
queue.push(4); // [1, 2, 3, 4]
queue.push(5); // [1, 2, 3, 4, 5]
console.log(queue); // [1, 2, 3, 4, 5]
//제일 먼저 들어간 것부터 빼내기 위해 shift() 메소드를 사용합니다.
queue.shift(); // [2, 3, 4, 5]
queue.shift(); // [3, 4, 5]
console.log(queue); // [3, 4, 5]