
Optimization
최적화, optimization
주어진 상황에서 원하는 가장 알맞은 결과를 얻을 수 있도록 처리하는 과정.
컴퓨터 공학에서의 최적화는 가능한 적은 리소스를 소모하면서 가능한 한 빠르게 원하는 결과를 얻을 수 있도록 하는 것을 의미합니다.
알고리즘 문제를 푸는 것을 생각하면 이해하기 쉽습니다. 원하는 결과가 나온다면, 메모리를 조금이라도 덜 소모하거나 연산 횟수가 한 번이라도 더 적은 코드가 더 효율적이고 최적화된 코드입니다. 더 적은 비용, 더 적은 시간을 소모하기 때문입니다. 물론 컴퓨터 성능을 업그레이드하면 같은 코드를 사용하더라도 더 빠르게 결과를 얻을 수 있습니다. 하지만 알고리즘 문제의 결과를 빠르게 확인하기 위해 부품을 업그레이드하는 것은 비용도 많이 들고, 업그레이드한 상태에서도 최적화되지 않은 코드보다 최적화된 코드가 더 빠를 테니, 기본적으로 더 효율적인 코드를 작성하기 위해서 노력하는 것이 좋습니다.
최적화의 필요성 및 효과
-
이탈률 감소
웹 개발에서의 최적화는 화면을 최대한 빠른 속도로 표시하게 하는 것이라고 했습니다. 이는 최적화가 잘되지 않은 웹 페이지는 화면 로딩에 시간이 걸린다는 뜻으로도 볼 수 있습니다. 화면을 불러오는 시간이 길어지면 사용자가 페이지를 이탈할 확률이 높아집니다. 여기서 이탈이란 방문자가 웹 사이트의 첫 페이지에서 아무런 상호작용도 하지 않고 종료하는 것을 의미합니다. 웹 사이트의 성능 최적화를 통해 페이지 로딩 속도를 줄이면, 사용자의 이탈률을 효과적으로 줄일 수 있다는 의미이기도 합니다. 여기서 최적화의 필요성을 엿볼 수 있습니다. -
전환율 증가
이탈률이 줄어들면, 전환율이 높아질 확률도 커집니다. 여기서 전환율이란, 웹 사이트를 방문한 사용자 중 회원가입, 상품 구매, 게시글 조회, 다운로드 등의 행위를 한 방문자의 비율을 의미합니다. 너무나 당연한 이야기입니다. 화면이 로딩되느라 제대로 뜨지도 않는 상태에서는 회원 가입은 고사하고 버튼 하나 클릭하는 것도 불가능하기 때문입니다. 물론 화면이 제대로 표시된다고 해도 방문자를 실제 서비스 이용자로 전환하게 하는 일은 어려운 일입니다. 하지만 이탈해버린 사용자의 전환율은 0%입니다. 전환율을 늘려 서비스 사용자를 늘리기 위해서는 이탈률을 줄여야 합니다. -
수익 증대
빠른 웹 사이트 로딩 속도는 수익 증대까지 이어질 수 있습니다. 이탈률 감소, 전환율 증가는 트래픽 증대 및 회원 수 증가로 이어지고, 이는 곧 수익 증대를 의미합니다. 실제로 로딩 속도가 1초 빨라졌을 때 아마존 판매량은 1%, 구글 검색량은 0.2%, 월마트의 전환율은 2% 증가했다고 합니다. 퍼센티지로 보면 크지 않아 보이지만, 이 수치를 돈으로 환산하면 각각 68억 달러, 4억 5천만 달러, 2억 4천400만 달러의 매출 증가라고 합니다. 1초 차이로 어마어마한 수익이 왔다 갔다 하는 것입니다. 꼭 아마존이나 월마트처럼 규모가 크지 않은 서비스라도, 로딩 속도의 차이는 이처럼 유의미한 수익 차이를 낼 수 있습니다. -
사용자 경험(UX) 향상
최적화는 효과적인 UX 개선 수단입니다. 페이지 로딩이 빠를수록 UX는 향상되기 때문에 이미 페이지 로드 속도가 빠른 편이라고 해도 최적화를 통해 UX가 더욱 향상할 수 있습니다. 만약 로딩이 오래 걸릴 경우, 스피너, 프로그레스 바, 스켈레톤과 같이 로딩 중임을 알려주는 UI를 먼저 표시하여 방문자가 조금 더 인내심을 갖고 기다리게 하는 방법도 있습니다. 하지만 이러한 방법은 최적화를 통해 페이지 로드 속도 자체를 최대한 빠르게 하는 것보다 UX에 좋다고 볼 수는 없습니다. 또한 방문자의 체류 시간이 좀 더 늘어날 뿐, 페이지 로드 속도가 개선되지 않는다면 이탈률 개선까지 이어지기는 어렵습니다. 따라서 이탈률 감소와 UX 향상 효과를 동시에 보기 위해서는 웹 사이트 성능 최적화를 진행하는 것이 가장 좋습니다.
Optimization 기법
화면을 렌더링할 때는 HTML 파일과 CSS 파일이 필요합니다. HTML 파일은 DOM 트리를, CSS 파일은 CSSOM 트리를 만들고 두 트리를 결합하여 렌더링할 때 사용하게 됩니다. 이 두 트리 중에서 하나라도 변경되면 리렌더링을 유발하는데, 이때 트리의 크기가 크고 복잡할수록 더 많은 계산이 필요하기 때문에 리렌더링에 소모되는 시간도 길어집니다. 따라서 HTML, CSS 코드를 최적화함으로써 렌더링 성능을 향상시킬 수 있습니다.
1. HTML 최적화 방법
(1) DOM 트리 가볍게 만들기
DOM 트리가 깊을수록, 자식 요소가 많을수록 DOM 트리의 복잡도는 커집니다. 복잡도가 클 수록 DOM 트리가 변경되었을 때 계산해야 하는 것도 많아집니다. HTML 요소들의 관계를 잘 살펴보고, 불필요하게 깊이를 증가시키는 요소가 있다면 삭제하세요.
// 수정 전
<div>
<ol>
<li> 첫 번째 </li>
<li> 두 번째 </li>
<li> 세 번째 </li>
</ol>
</div>
// 수정 후 : 불필요한 div 요소 제거
<ol>
<li> 첫 번째 </li>
<li> 두 번째 </li>
<li> 세 번째 </li>
</ol>(2) 인라인 스타일 사용하지 않기
인라인 스타일은 개별 요소에 스타일 속성을 작성해주는 것이기 때문에, 클래스로 묶어서 한 번에 작성해도 될 스타일 속성을 중복으로 작성하게 되는 경우가 생깁니다. 이처럼 불필요한 코드 중복은 가독성을 떨어뜨릴 뿐 아니라 파일 크기를 증가시킵니다. 또한 CSS 파일을 따로 작성하면 단 한 번의 리플로우만 발생하는 것과 달리, 인라인 스타일은 리플로우를 계속해서 발생시켜 렌더링 완료 시점을 늦춥니다. 애초에 인라인 스타일은 웹 표준에 맞지 않으므로 지양해야 합니다.
//수정 전
<div style="margin: 10px;"> 마진 10px </div>
<div style="margin: 10px;"> 이것도 마진 10px </div>
//수정 후 : class와 CSS로 대체
<div class="margin10"> 마진 10px </div>
<div class="margin10"> 이것도 마진 10px </div>
.margin10 {
margin: 10px;
}2. CSS 최적화 방법
(1) 사용하지 않는 CSS 제거하기
CSS 파일의 모든 코드의 분석이 끝난 후에 CSSOM 트리가 생성됩니다. 그만큼 불필요한 CSS 코드가 있다면 CSSOM 트리의 완성이 늦어집니다. 따라서 사용하지 않는 CSS 코드가 있다면 제거하는 것이 좋습니다. 보통 해당 CSS 코드를 사용하던 요소를 삭제하면서 CSS 코드만 남게 되는 경우가 많습니다. 요소를 삭제할 일이 생기면, CSS 코드만 남지는 않는지 확인하고 함께 삭제하면 이런 상황을 방지할 수 있습니다.
(2) 간결한 셀렉터 사용하기
셀렉터가 복잡할수록 스타일 계산과 레이아웃에 시간을 더 많이 소모하게 됩니다. 따라서 최대한 간결한 CSS 셀렉터를 사용하는 것이 좋습니다.
// 복잡한 CSS 셀렉터 예시
.cart_page .cart_item #firstItem { ... }
// 필요한 경우에는 어쩔 수 없지만, 가능한 한 간결하게 작성해줍니다.
.cart_item { ... }리소스 로딩 최적화하기
HTML 파일에서 JavaScript 파일을 불러올 땐 script 요소를, CSS 파일을 불러올 땐 link 요소를 사용하게 됩니다. 이때 파일을 불러오는 위치가 어디인가에 따라서 렌더링 완료 시점이 달라질 수 있습니다.
- CSS 파일 불러오기
화면을 렌더링할 때는 DOM 트리와 CSSOM 트리가 필요하다고 했습니다. DOM 트리는 HTML 코드를 한 줄 한 줄 읽으면서 순차적으로 구성할 수 있지만, CSSOM 트리는 CSS 코드를 모두 해석해야 구성할 수 있습니다. 따라서 CSSOM 트리를 가능한 빠르게 구성할 수 있도록 HTML 문서 최상단에 배치하는 것이 좋습니다.
// CSS 파일은 HTML 파일 상단의 head 요소 안에서 불러오는 것이 좋습니다.
<head>
<link href="style.css" rel="stylesheet" />
</head>- JavaScript 파일 불러오기
JavaScript는 DOM 트리와 CSSOM 트리를 동적으로 변경할 수 있습니다. HTML 코드 파싱 중에 script 요소를 만나는 순간 해당 스크립트가 실행되며, script 요소 이전까지 생성된 DOM까지만 접근할 수 있습니다. script 요소를 HTML 코드 중간에 넣는다면, 해당 요소 이후에 생성될 DOM을 수정하는 코드가 있는 경우에는 화면이 의도한 대로 표시되지 않게 됩니다.
또한 스크립트 실행이 완료되기 전까지 DOM 트리 생성이 중단됩니다. JavaScript 파일을 다운로드해서 사용하는 경우에는 다운로드 및 스크립트 실행이 완료될 때까지 DOM 트리 생성이 중단됩니다. DOM 트리 생성이 중단된 시간만큼 렌더링 완료 시간은 늦춰지게 됩니다. 이러한 이유로 JavaScript 파일은 DOM 트리 생성이 완료되는 시점인 HTML 문서 최하단에 배치하는 것이 좋습니다.
<body>
<div>...</div>
...
// JavsScript 파일은 body 요소가 닫히기 직전에 작성하는 것이 가장 좋습니다.
<script src="script.js" type="text/javascript"></script>
</body>브라우저 이미지 최적화하기
페이지의 대부분의 용량은 HTML/CSS/JS와 같은 코드 데이터가 아닌 이미지 파일과 같은 미디어 파일이 차지합니다. (전체 페이지 용량의 약 51% 차지)그래서 이미지의 용량을 줄이거나 요청의 수를 줄이는 것을 우선적으로 고려할 시, 사용자 경험을 빠르게 개선할 수 있습니다.
- 이미지 스프라이트
클라이언트에서 서버 요청이 증가할수록 로딩 시간은 점점 늘어납니다. 따라서 웹 페이지를 로드하는 데 필요한 서버 요청 수를 줄이기 위해 이미지 스프라이트 기법을 사용할 수 있습니다.
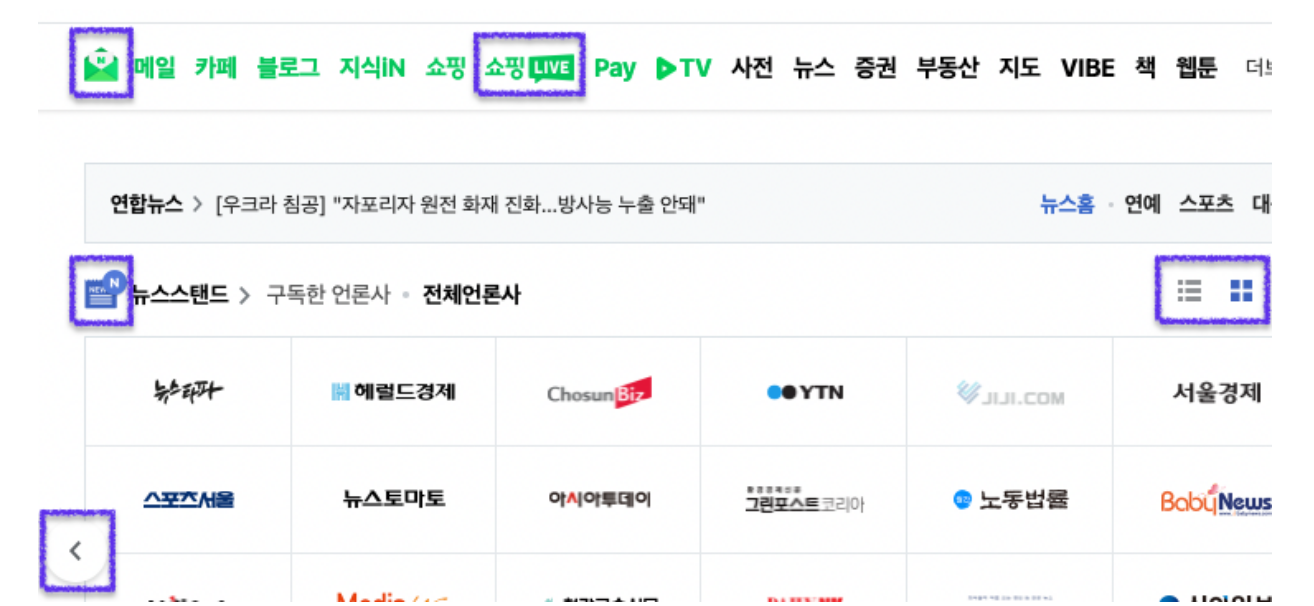
다음은 여러분에게 친숙한 네이버의 메인 화면의 일부입니다. 박스에 표시한 아이콘 이미지의 경우 각각의 이미지를 서버에 요청할 경우 웹사이트의 로딩 시간이 늘어나게 됩니다. 이를 해결하기 위해 사용하는 기법이 이미지 스프라이트입니다.
이미지 스프라이트 기법은 여러 개의 이미지를 모아 하나의 스프라이트 이미지로 만들고 CSS의 background-position 속성을 사용해 이미지의 일정 부분만 클래스 등으로 구분하여 사용하는 방법입니다.
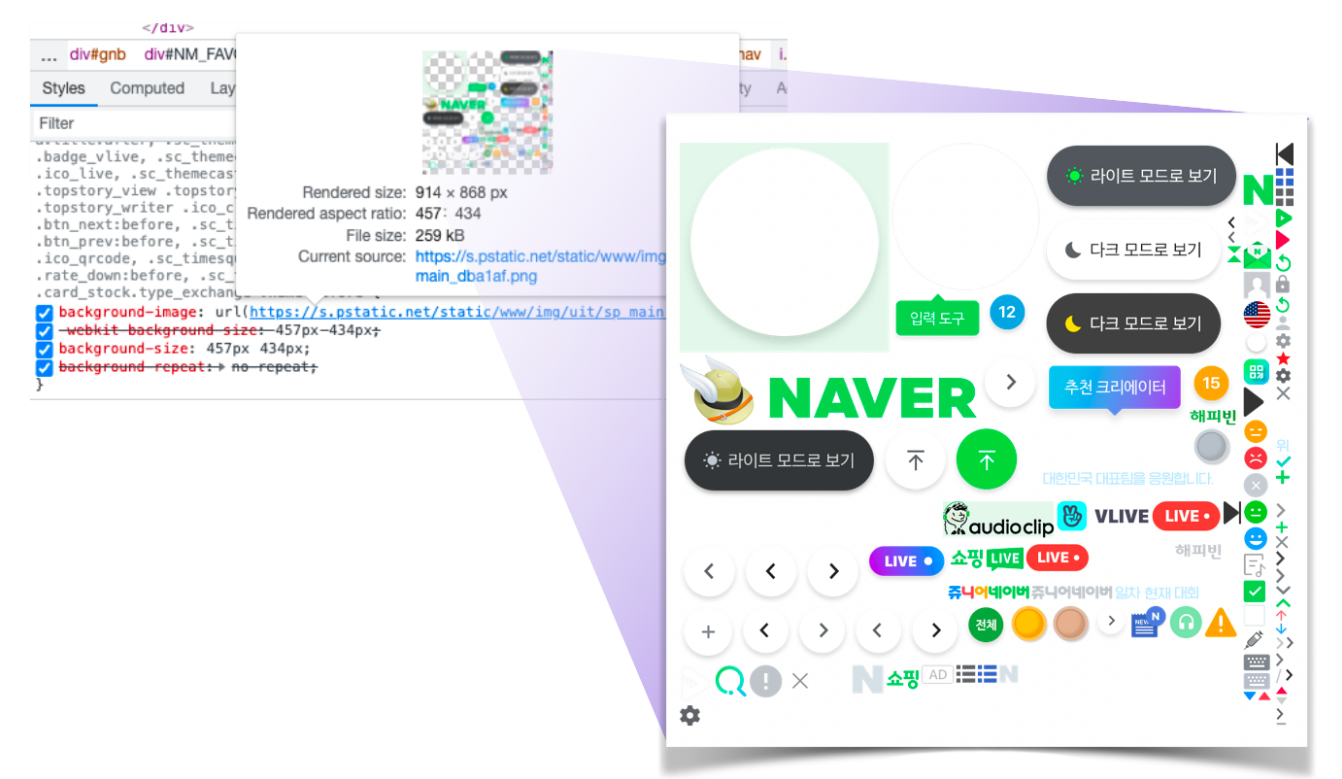
실제로 네이버에 접속한 후 개발자 도구를 이용해 아이콘 컴포넌트를 살펴보면 다음과 같이 스프라이트 이미지가 적용되어 있는 것을 직접 확인할 수 있습니다.
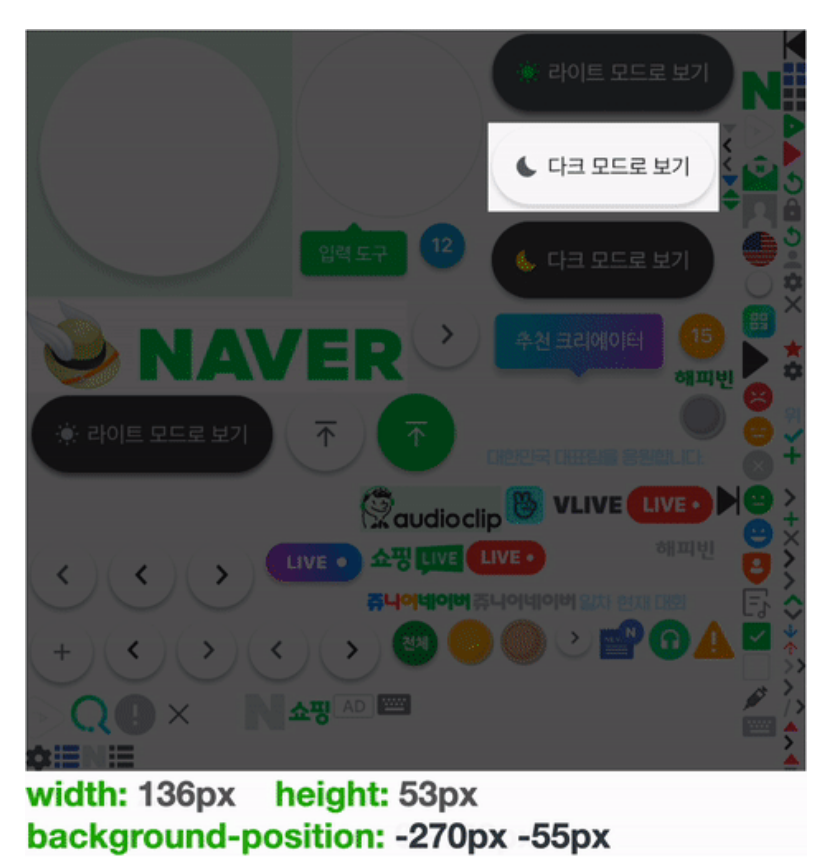
하나의 이미지를 배경 이미지로 사용하되, 표시하고 싶은 부분에 맞춰 width, height, background-position 속성을 주어 아이콘을 만듭니다. 위 이미지를 보면서 CSS 속성값에따라 어떤 부분이 보이는지 확인하면서 이해해보세요.
해당 기법을 이용하면 한번의 이미지 요청으로 대부분의 개별 이미지를 사용할 수 있기 때문에 네트워크 로딩 시간을 줄일 수 있습니다. 또한, 많은 이미지 파일을 개별로 관리할 필요없이 특정 스프라이트 이미지 파일만을 관리하면 되므로 관리가 용이하다는 장점이 있습니다. 네이버 예시만 해도 이미지 스프라이트를 통해 120여개의 아이콘을 하나의 이미지로 모두 사용할 수 있게 되었습니다.
- 아이콘 폰트 사용하기
아이콘 사용이 많을 때에는, 모든 아이콘을 이미지로 사용하는 것이 아니라 아이콘 폰트를 사용하여 용량을 줄일 수 있습니다. 대표적인 아이콘 글꼴 서비스로는 Font Awesome이 있습니다. Font Awesome의 사용 방법에는 두 가지가 있습니다.
(1) CDN으로 사용하기
Font Awesome에 가입하면 키트를 발급해주는데, 이 키트를 HTML 파일에서 head 요소에 넣어주기만 하면 CDN으로 Font Awesome을 사용할 준비가 완료됩니다.
Font Awesome 사이트에서 사용하고 싶은 아이콘을 찾아서 사용할 환경(HTML, React, Vue)에 맞는 코드를 복사하고 붙여넣기만 하면 사용할 수 있습니다.
(2) Font Awesome 모듈 설치하기
Font Awesome을 다른 라이브러리처럼 설치해서 사용하는 방법도 있습니다. React 환경에서 사용할 경우에는 다음과 같은 패키지들을 설치하면 됩니다.
// 핵심 패키지 설치
npm i --save @fortawesome/fontawesome-svg-core
// 아이콘 패키지 설치 (해당 코드는 무료 아이콘들입니다. 유료 아이콘을 사용할 경우 추가로 설치가 필요합니다.)
npm i --save @fortawesome/free-solid-svg-icons
npm i --save @fortawesome/free-regular-svg-icons
npm i --save @fortawesome/free-brands-svg-icons
// Font Awesome React 구성 요소 설치
npm i --save @fortawesome/react-fontawesome@latest설치 후에는 Font Awesome 사이트에서 사용하고 싶은 아이콘의 정보를 확인한 후에, 알맞게 불러와서 사용하면 됩니다. 이때 아이콘 이름은 camelCase로 작성해야 합니다.
이렇게 불러온 아이콘은 클래스명을 직접 붙이거나 Font Awesome이 정해준 방법을 사용하여 스타일링해줄 수 있습니다.
- WebP 또는 AVIF 이미지 포맷 사용하기
이미지 최적화를 위해 전통적으로 사용하는 JPEG 또는 PNG 형식이 아닌 새롭게 등장한 이미지 포맷인 WebP 또는 AVIF를 사용하여 용량을 더욱 감소시킬 수 있습니다. WebP는 PNG와 비교해 26% 용량이 감소되며 JPEG와 비교했을 땐 25-35% 더 감소됩니다. AVIF는 JPEG와 비교했을 때 무려 용량의 50%가 감소되며 WebP와 비교했을 땐 20% 감소됩니다.
하지만 WebP와 AVIF 모두 비교적 최근에 등장한 이미지 포맷이기 때문에 JPEG 포맷처럼 모든 브라우저에서 호환되지 않는다는 단점이 있습니다. WebP의 경우 비교적 최근에 브라우저 지원이 되었으므로 구버전의 브라우저에서는 지원이 안될 수 있으며 Safari 브라우저에서도 지원하지 않습니다. AVIF의 경우에는 Chrome, Opera 등 소수의 브라우저만 지원하고 있습니다. (참고 - Can I use WebP?, Can I use AVIF?)
그럼 개발자가 각 브라우저의 이미지 호환성을 파악해서 이미지 파일을 분기해야 할까요? 다행히도 HTML의 picture 태그를 이용하면 각 브라우저의 호환에 맞도록 분기를 대체할 수 있습니다.
picture: img 요소의 다중 이미지 리소스(multiple image resources)를 위한 컨테이너를 정의할 때 사용한다.
다음과 같이 HTML 태그를 작성할 시, 만약 접속한 브라우저에서 source태그 내의 srcset에 정의한 WebP 포맷을 지원하지 않는다면 해당 source 태그는 무시됩니다. 이와 같은 속성을 이용하여 각 브라우저에 따라 이미지 포맷을 최적화할 수 있습니다.
<picture>
<source srcset="logo.webp" type="image/webp">
<img src="logo.png" alt="logo">
</picture>CDN 사용하기
CDN은 콘텐츠를 좀 더 빠르고 효율적으로 제공하기 위해 설계되었습니다. 네트워크 지연(latency)은 유저와 호스팅 서버간의 물리적 거리의 한계가 존재하기 때문에 발생할 수 밖에 없습니다. 유저와 서버의 거리가 멀다면 지연(latency) 또한 늘어납니다. CDN은 이를 해결하고자 세계 곳곳에 분포한 분산된 서버에 콘텐츠를 저장합니다.
간단히 말해, CDN은 유저가 가까운 곳에 위치한 데이터 센터(서버)의 데이터를 가져옵니다. 그러므로 데이터가 전달되기 위해 거쳐야하는 서버의 갯수가 크게 줄기 때문에 로딩 속도가 빨라집니다.
지금은 CDN을 사용하는 방법을 구체적으로 알지 않아도 괜찮습니다. 추후에 CDN을 사용해보고싶다면, CloudFront, Cloudflare와 같은 CDN 서비스들에 대해서 알아보세요.
캐시 관리
캐시 사용하기
캐시(Cache)는 다운로드 받은 데이터나 값을 미리 복사해 놓는 임시 장소를 뜻하며, 데이터에 접근하는 시간이 오래 걸리는 경우나 값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용합니다. 우선 캐시를 사용하지 않을 때의 예시를 들어보겠습니다.
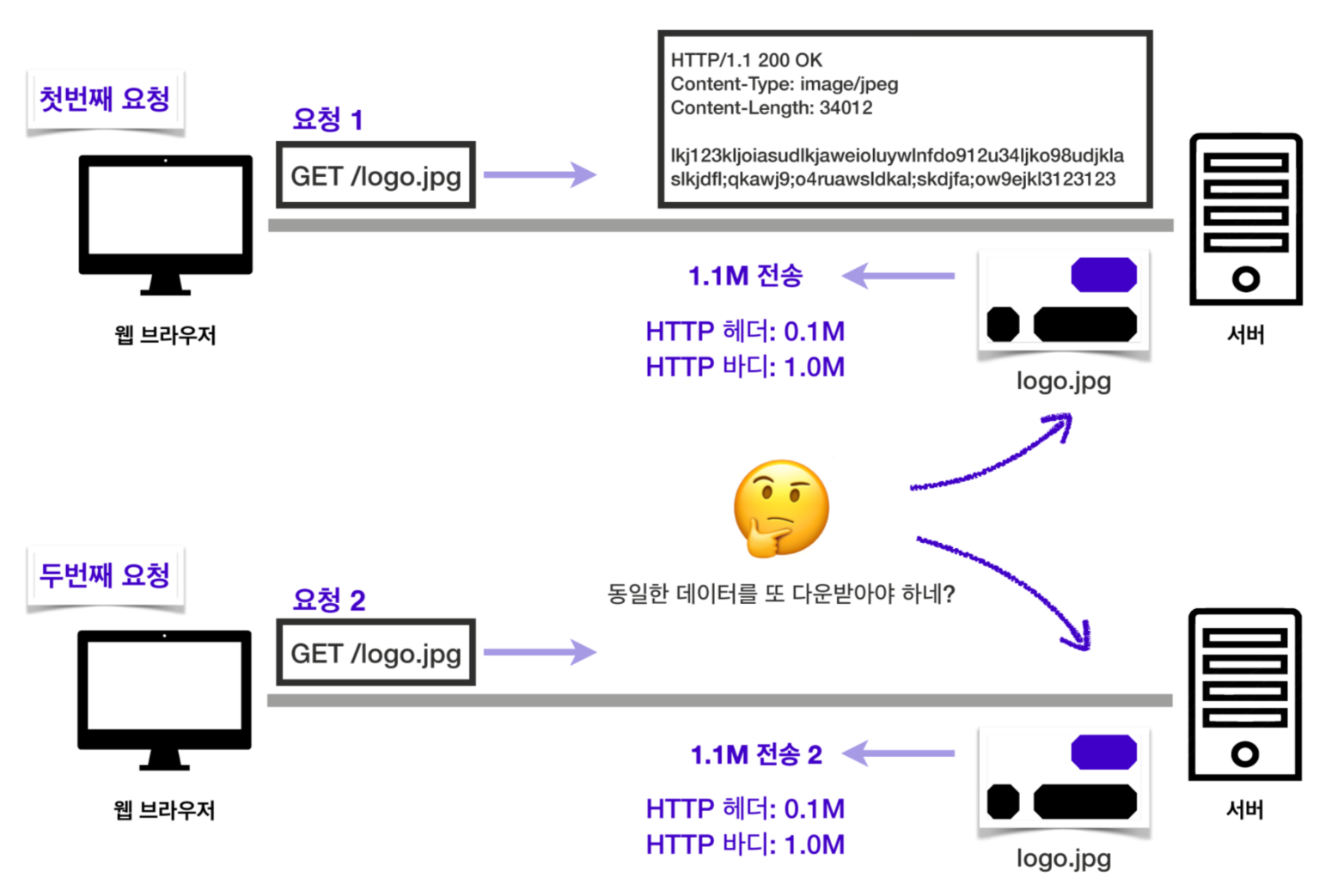
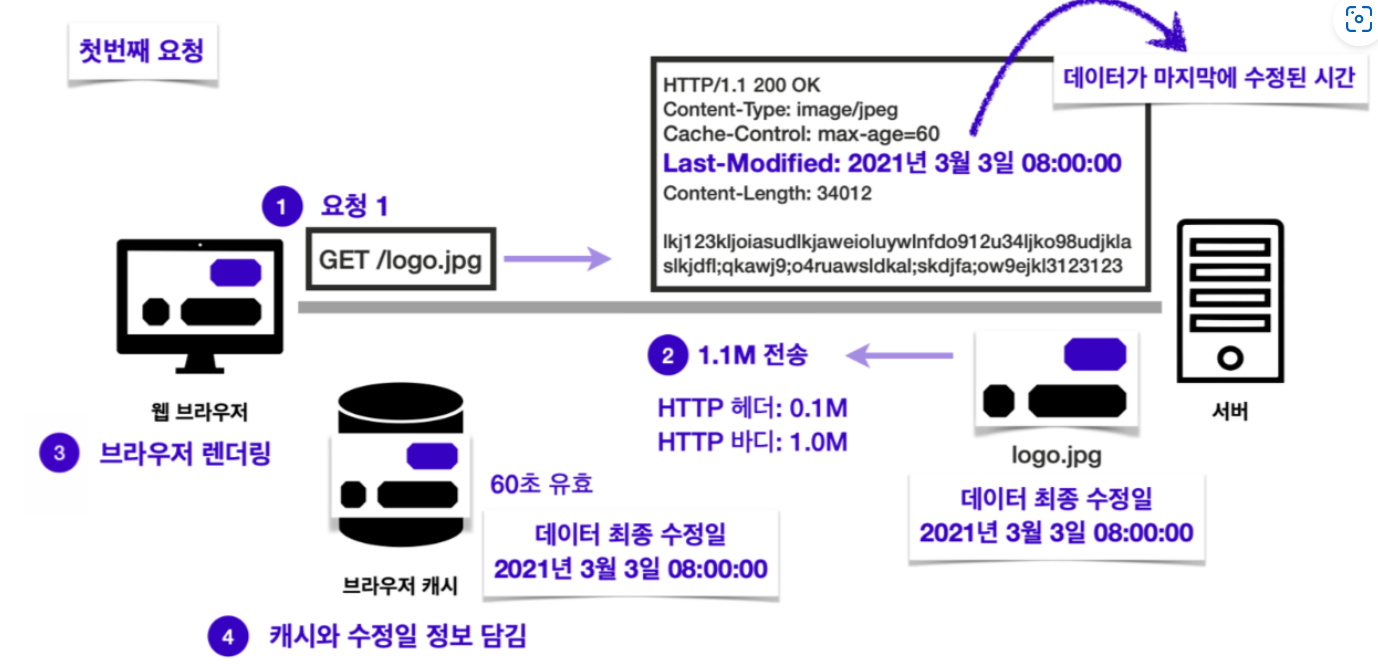
서버에서 logo.jpg라는 이미지를 받아오는 요청을 보낸다고 해봅시다. 첫 번째 요청에서는 이미지를 통째로 받아오게 됩니다. 해당 이미지를 받아온 적이 없으니까요. 이때 HTTP 헤더의 용량이 0.1M, 이미지의 용량이 1.0M라면 응답의 총 용량은 1.1M이 될겁니다.
문제는 두 번째 요청부터입니다. 완전히 똑같은 파일을 또 다시 받아오는 일이 발생하기 때문입니다. 똑같은 데이터를 굳이 다시 받을 필요가 있을까요? 전에 받아두었던 파일을 재사용할 수 있다면, 첫 번째 요청을 보냈을 때처럼 1.1M의 응답을 통째로 받아올 필요없이 HTTP헤더의 용량인 0.1M만 받아도 될 것 같은데 말이죠.
한 두번은 그렇다고 쳐도, 100번, 1000번의 요청을 보내는 동안 똑같은 파일을 받아온다고 생각해봅시다. 똑같은 파일을 받느라 100M, 1000M의 네트워크 리소스를 낭비하게 될 것입니다. 이럴 때 캐시를 활용하면 이러한 리소스 낭비를 막을 수 있습니다. 캐시를 사용하게 되면 어떤 일이 일어나는지 확인해봅시다.
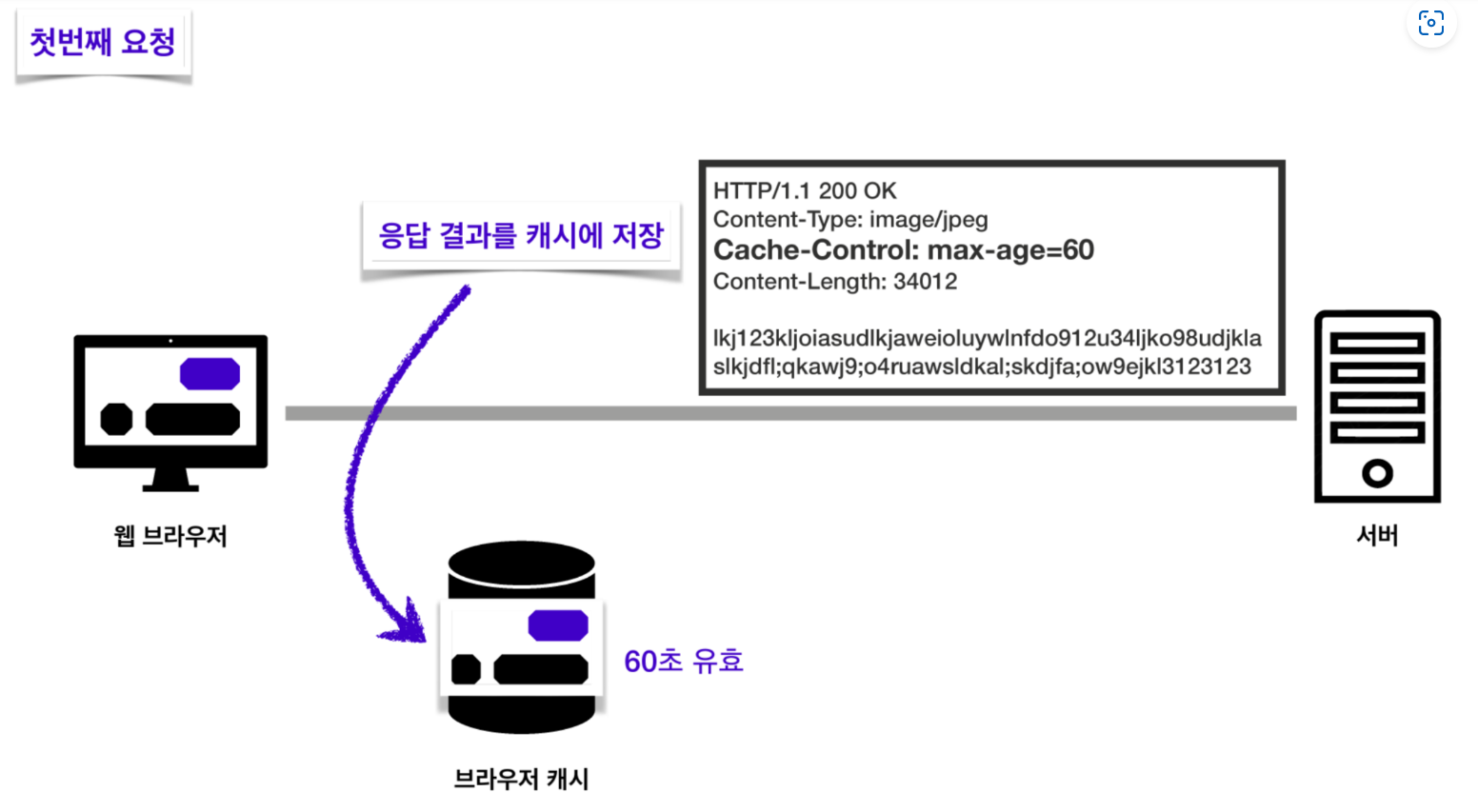
이번에는 서버에서 응답을 보내줄 때 이미지 파일과 함께 헤더에 Cache-Control 을 작성해서 보내준 것을 볼 수 있습니다. 값은 60으로, 해당 이미지 파일이 60초동안 유효하다는 것을 의미합니다.
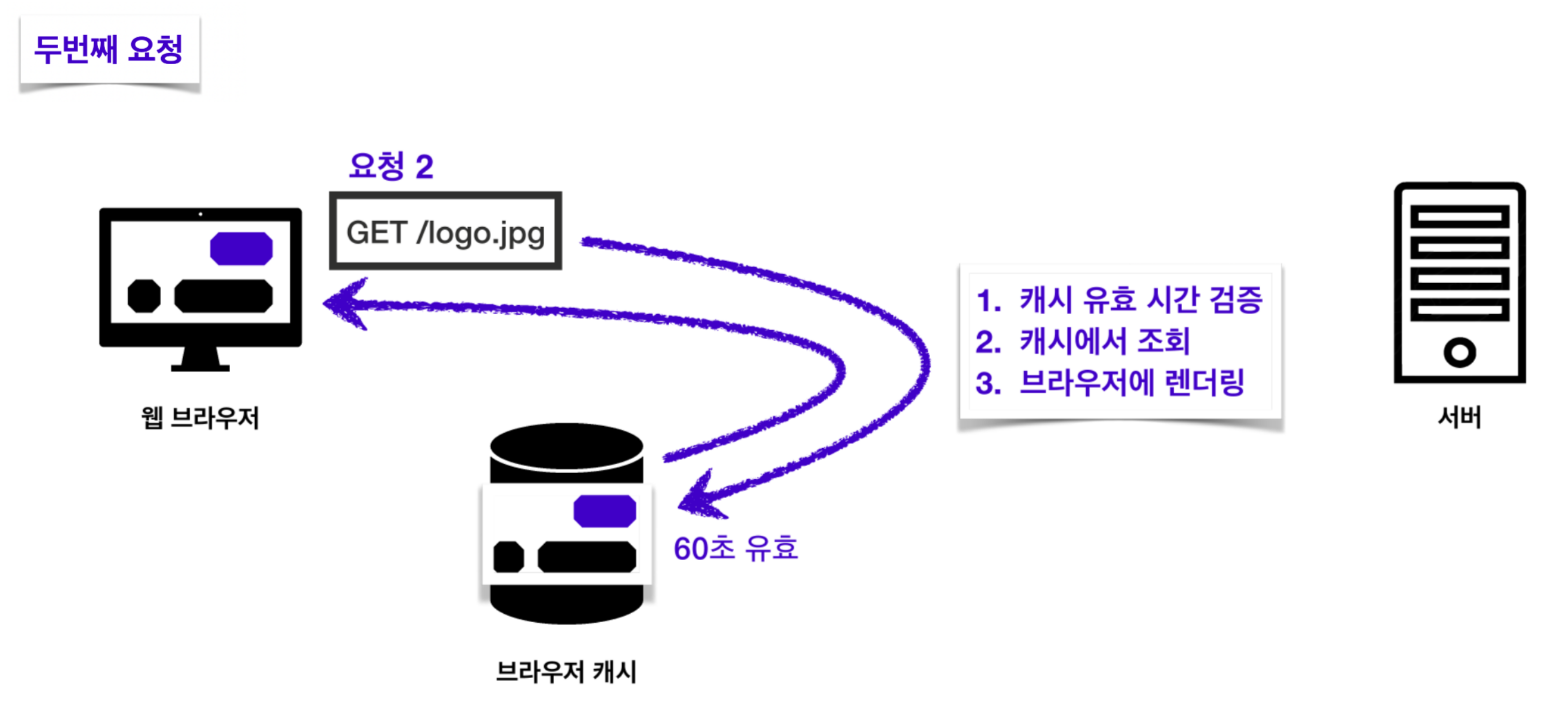
이제 두 번째 요청부터는 캐시를 우선 조회하게 됩니다. 캐시에 데이터가 존재하면서 아직 60초가 지나지 않아 유효하다면 캐시에서 해당하는 데이터를 가져와서 사용하게 됩니다.
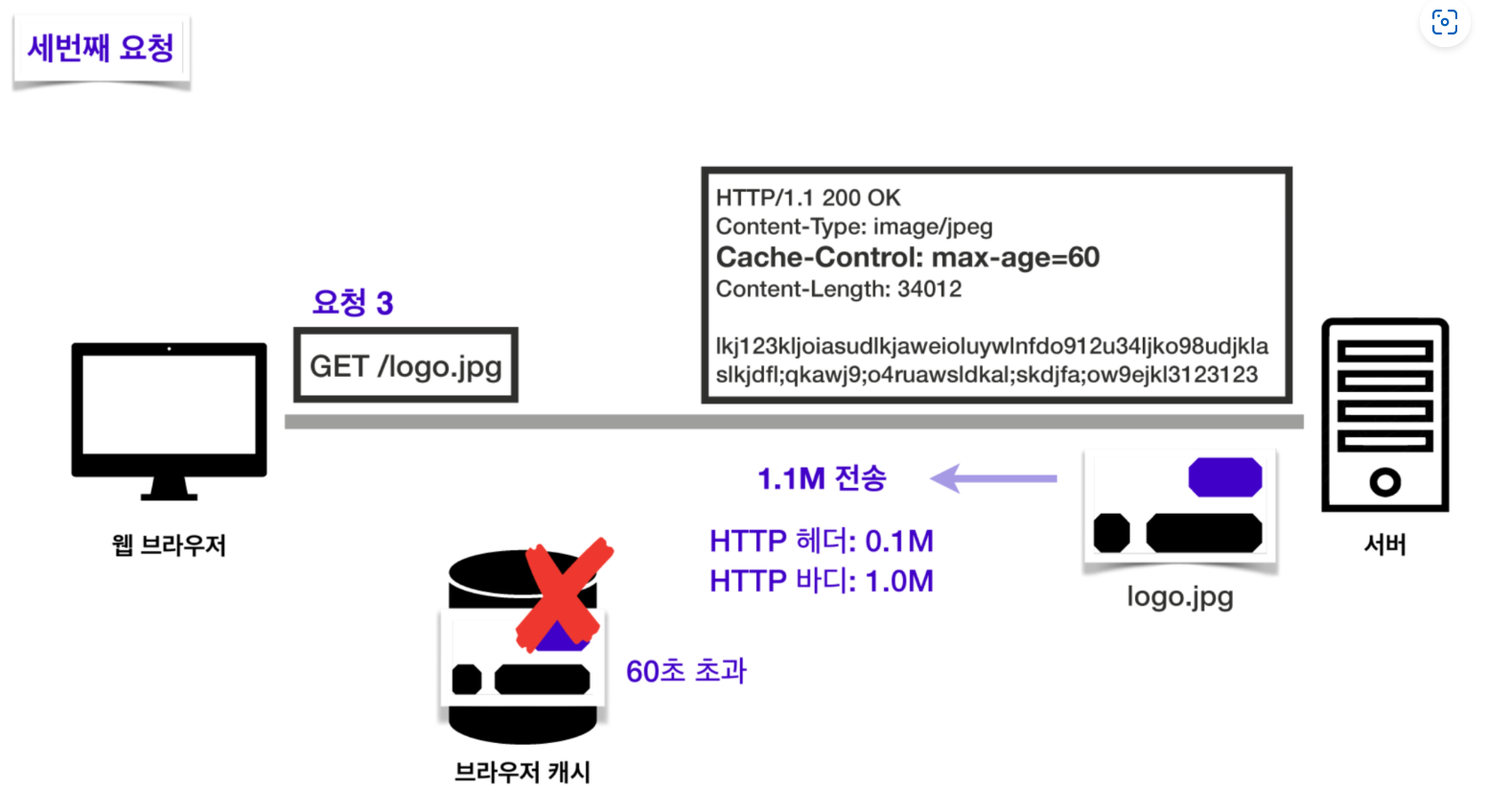
만약 유효 시간이 60초가 지났다면? 서버에서 다시 이미지를 받아오게 됩니다. 캐시 유효 시간 동안은 똑같은 데이터를 다시 받아올 필요가 없어지는 것이죠.
이렇게 브라우저 캐시를 활용하면 다음과 같은 효과를 볼 수 있습니다.
캐시가 유효한 시간 동안 네트워크 리소스를 아낄 수 있음
파일을 다시 받아올 필요가 없기 때문에 브라우저 로딩이 빨라짐
로딩이 빨라진 만큼 빠른 사용자 경험 제공 가능
캐시 검증 헤더와 조건부 요청
캐시를 활용하면 캐시가 유효한 시간 동안은 캐시에 저장해놓은 데이터를 재활용할 수 있다는 것을 알게 되었습니다. 하지만 다음과 같은 경우는 어떨까요?
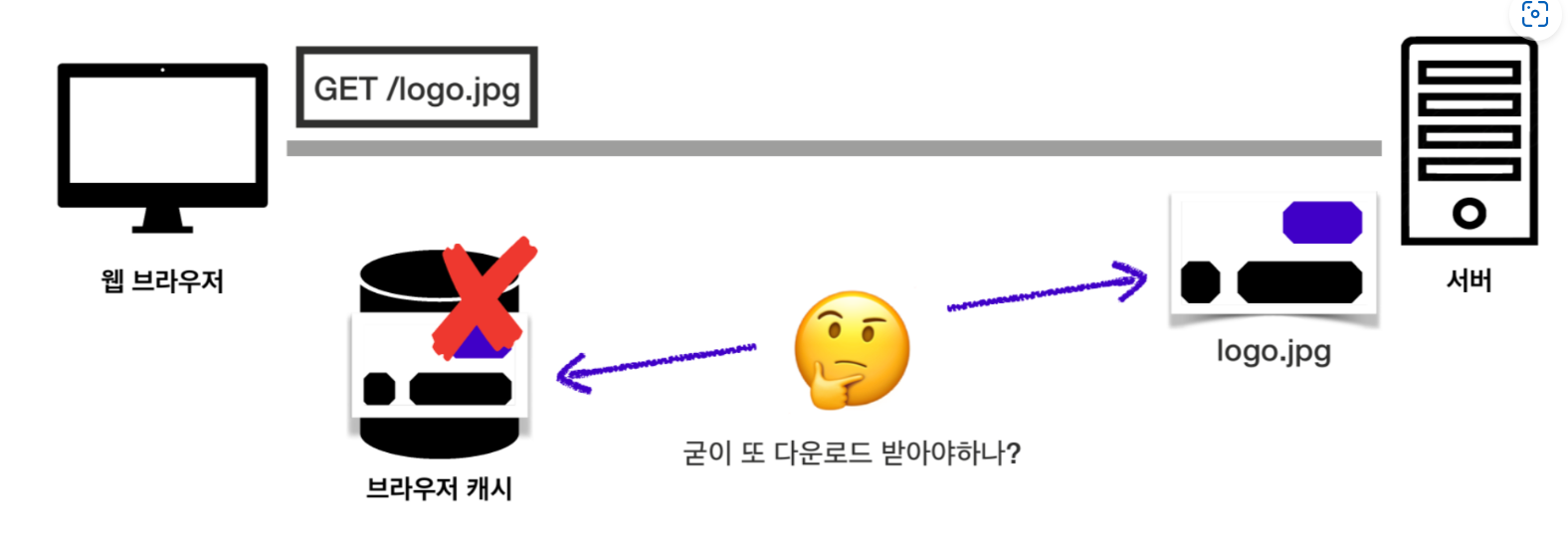
캐시 유효 시간은 지났지만, 서버에서 다시 받아와야하는 파일이 캐시에 저장되어 있는 파일과 완전히 동일한 경우를 생각해보세요. 이때도 똑같은 파일을 다시 받아와야하는 경우가 발생합니다. 이럴 땐 유효 시간이 지났다고해도 굳이 똑같은 파일을 다시 받아올 필요 없이 서버의 파일과 캐시의 파일이 동일한지 확인해서 재사용하면 더 효율적이지 않을까요?
다행히도 이런 상황에서 사용할 수 있는 HTTP 헤더들이 존재합니다. 바로 캐시 검증 헤더와 조건부 요청 헤더입니다.
캐시 검증 헤더
캐시에 저장된 데이터와 서버의 데이터가 동일한지 확인하기 위한 정보를 담은 응답 헤더
Last-Modified : 데이터가 마지막으로 수정된 시점을 의미하는 응답 헤더로, 조건부 요청 헤더인 If-Modified-Since 와 묶어서 사용합니다.
Etag : 데이터의 버전을 의미하는 응답 헤더로, 조건부 요청 헤더인 If-None-Match 와 묶어서 사용합니다.
조건부 요청 헤더
캐시의 데이터와 서버의 데이터가 동일하다면 재사용하게 해달라는 의미의 요청 헤더
If-Modified-Since : 캐시된 리소스의 Last-Modified 값 이후에 서버 리소스가 수정되었는지 확인하고, 수정되지 않았다면 캐시된 리소스를 사용합니다.
If-None-Match : 캐시된 리소스의 ETag 값과 현재 서버 리소스의 ETag 값이 같은지 확인하고, 같으면 캐시된 리소스를 사용합니다.
캐시 검증 헤더와 조건부 요청 헤더를 어떻게 사용하는지 조금 더 자세히 살펴보겠습니다.
Last-Modified 와 If-Modified-Since
첫 번째 요청을 보내고 응답을 받으면서 캐시 유효 시간이 60초인 이미지 파일을 같이 받아옵니다. 이 때, 서버의 파일이 마지막으로 수정된 시간을 의미하는 Last-Modified 헤더에 담긴 내용도 캐시에 함께 저장합니다.
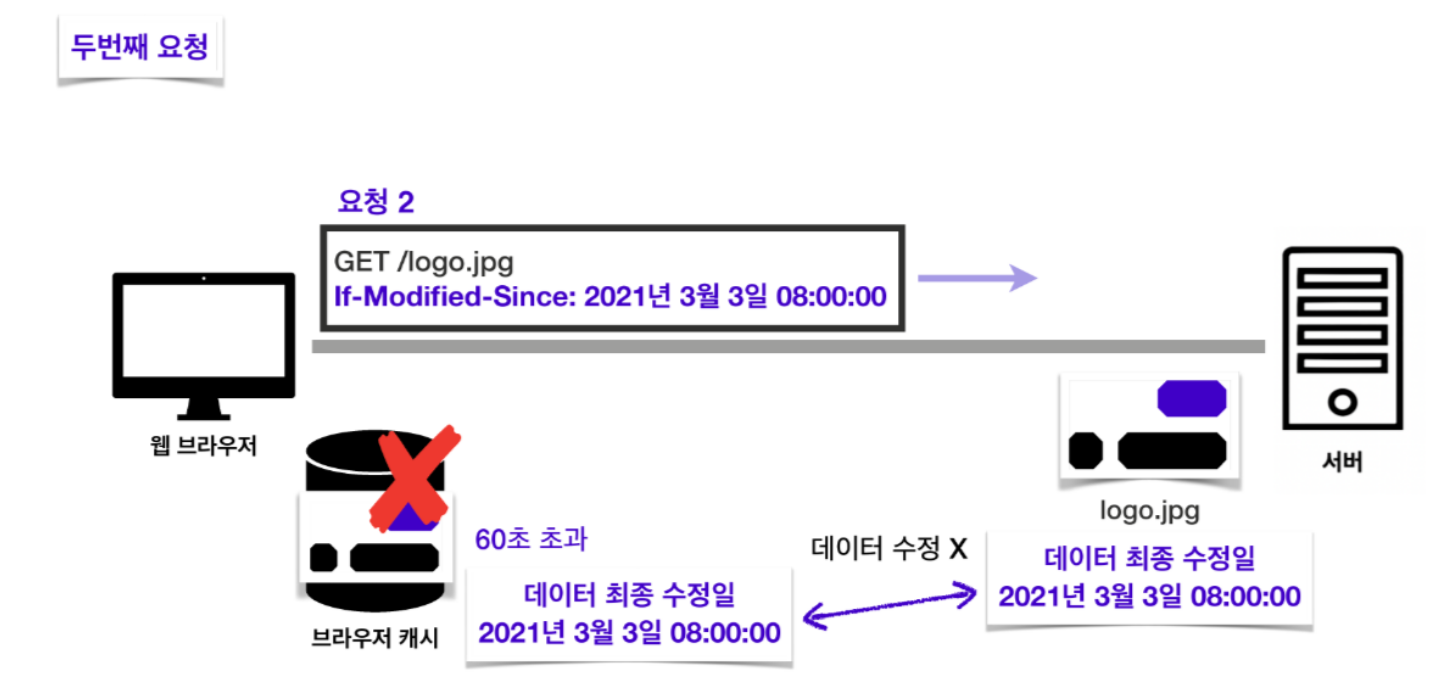
캐시 유효 시간인 60초를 초과한 후에 두 번째 요청을 보낸다고 해봅시다. 비록 유효 시간이 지났어도 해당 데이터를 재사용해도 되는지 확인하기 위해서 “이 날짜 이후로 데이터 수정이 있었니? 없었다면 캐시에 저장해놓은 데이터를 재사용해도 괜찮을까?”라는 뜻의 요청 헤더 If-Modified-Since 를 작성하고 캐시에 함께 저장해놓았던 Last-Modified 값을 담아 요청을 보냅니다. 이 값을 이용해 서버 데이터의 최종 수정일과 캐시에 저장된 데이터의 수정일을 비교합니다. 두 데이터가 동일한 데이터라면 최종 수정일이 같아야 합니다.
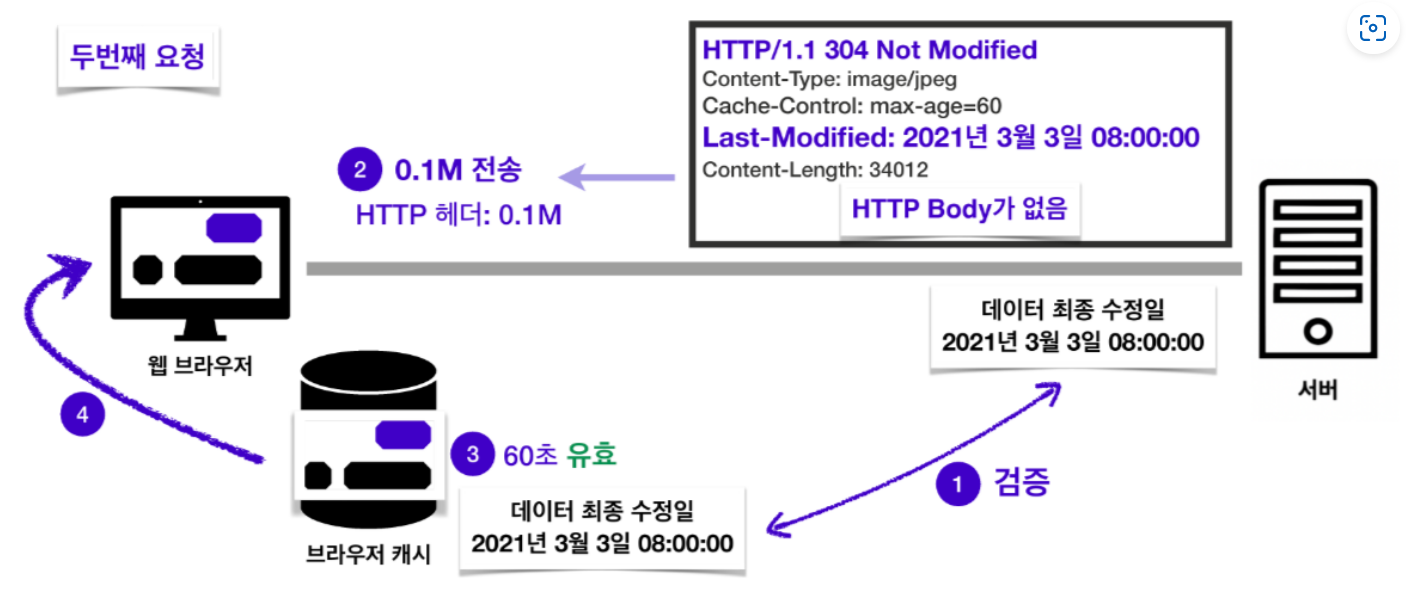
서버와 캐시의 데이터가 동일한 데이터임이 검증되었다면 서버는 “데이터가 수정되지 않았음”을 의미하는 304 Not Modified 라는 응답을 보내주고, 캐시 데이터의 유효 시간이 갱신되면서 해당 데이터를 재사용할 수 있게 됩니다.
Etag 와 If-None-Match
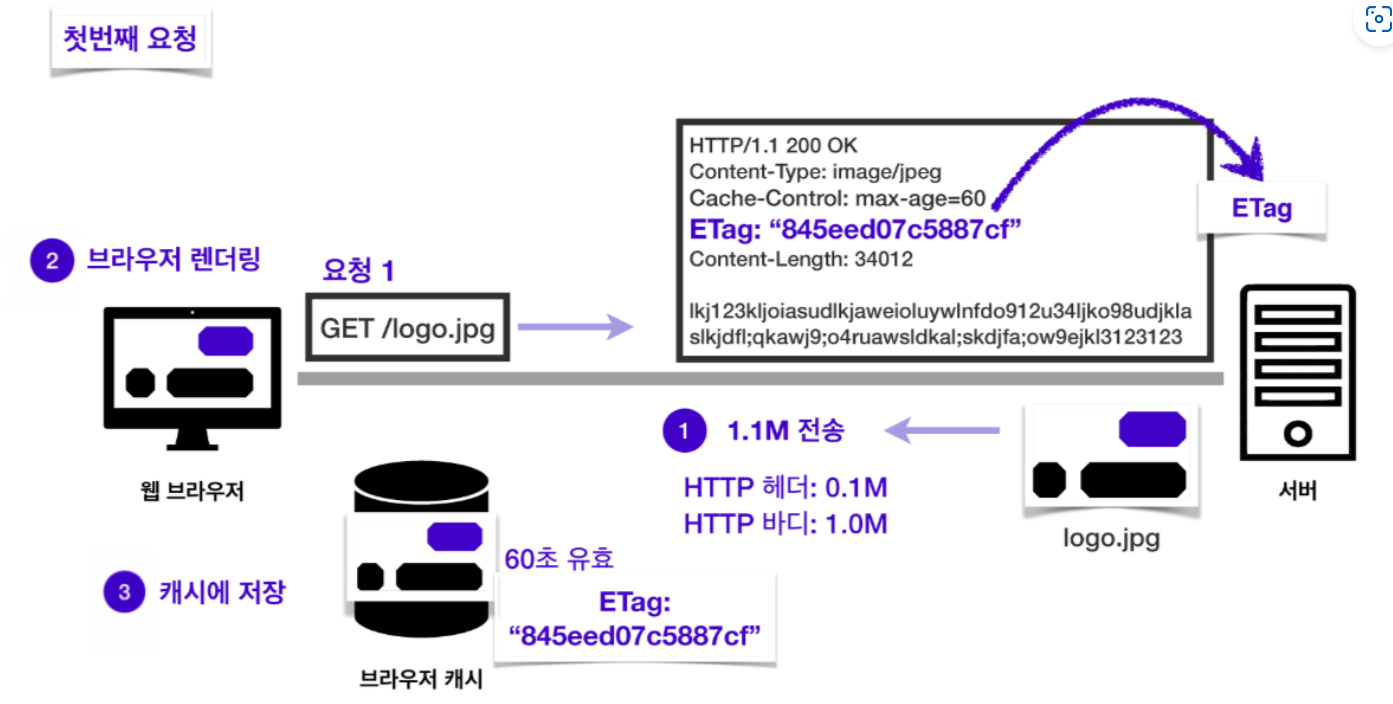
첫 번째 요청을 보내고 응답을 받으면서 캐시 유효 시간이 60초인 이미지 파일을 같이 받아옵니다. 이 때, 서버의 파일 버전을 의미하는 Etag 헤더에 담긴 내용도 캐시에 함께 저장합니다.
캐시 유효 시간인 60초를 초과한 후에 두 번째 요청을 보낸다고 해봅시다. 비록 유효 시간이 지났어도 해당 데이터를 재사용해도 되는지 확인하기 위해서 “내가 캐시에 저장해놓은 데이터 버전이랑 서버 데이터 버전이랑 일치하니? 일치한다면 캐시에 저장해놓은 데이터를 재사용해도 괜찮을까?”라는 뜻의 요청 헤더 If-None-Match 를 작성하고 캐시에 함께 저장해놓았던 Etag 값을 담아 요청을 보냅니다. 이 값을 이용해 서버 데이터의 Etag 와 캐시에 저장된 데이터의 Etag 를 비교합니다. 두 데이터가 동일한 데이터라면 두 Etag 값이 같아야 합니다.
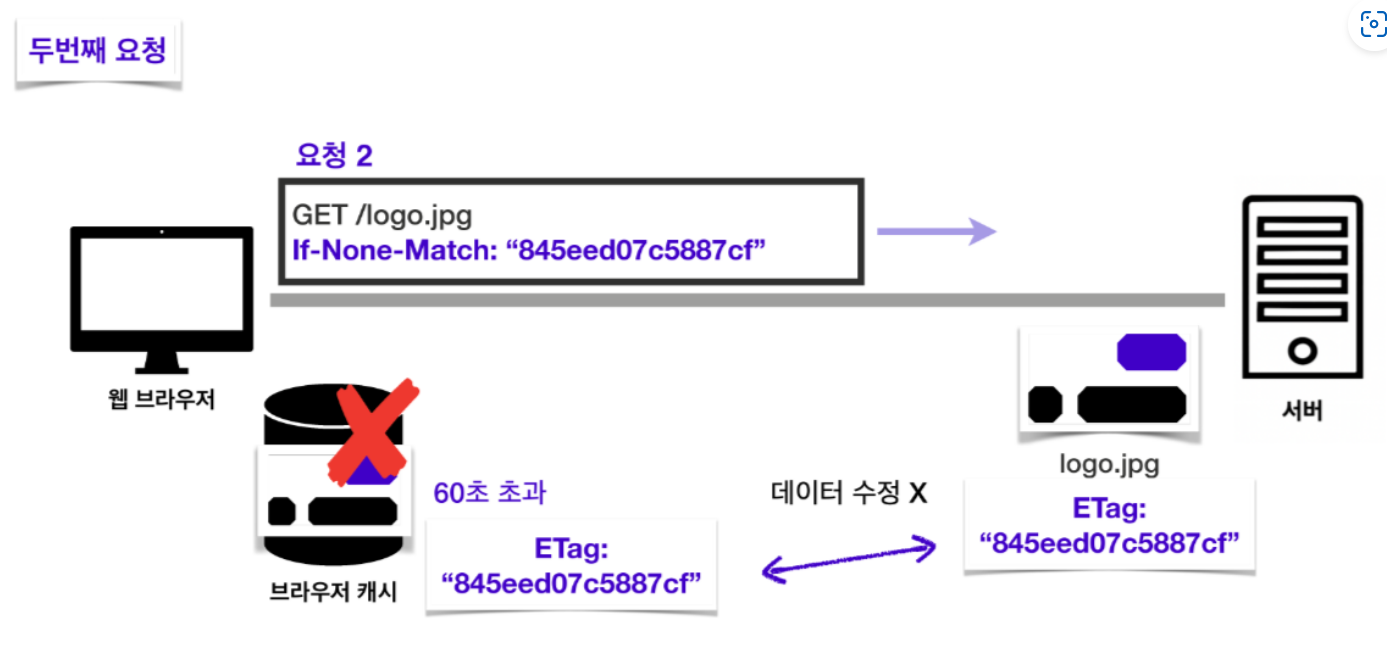
서버와 캐시의 데이터가 동일한 데이터임이 검증되었다면 서버는 “데이터가 수정되지 않았음”을 의미하는 304 Not Modified 라는 응답을 보내주고, 캐시 데이터의 유효 시간이 갱신되면서 해당 데이터를 재사용할 수 있게 됩니다.
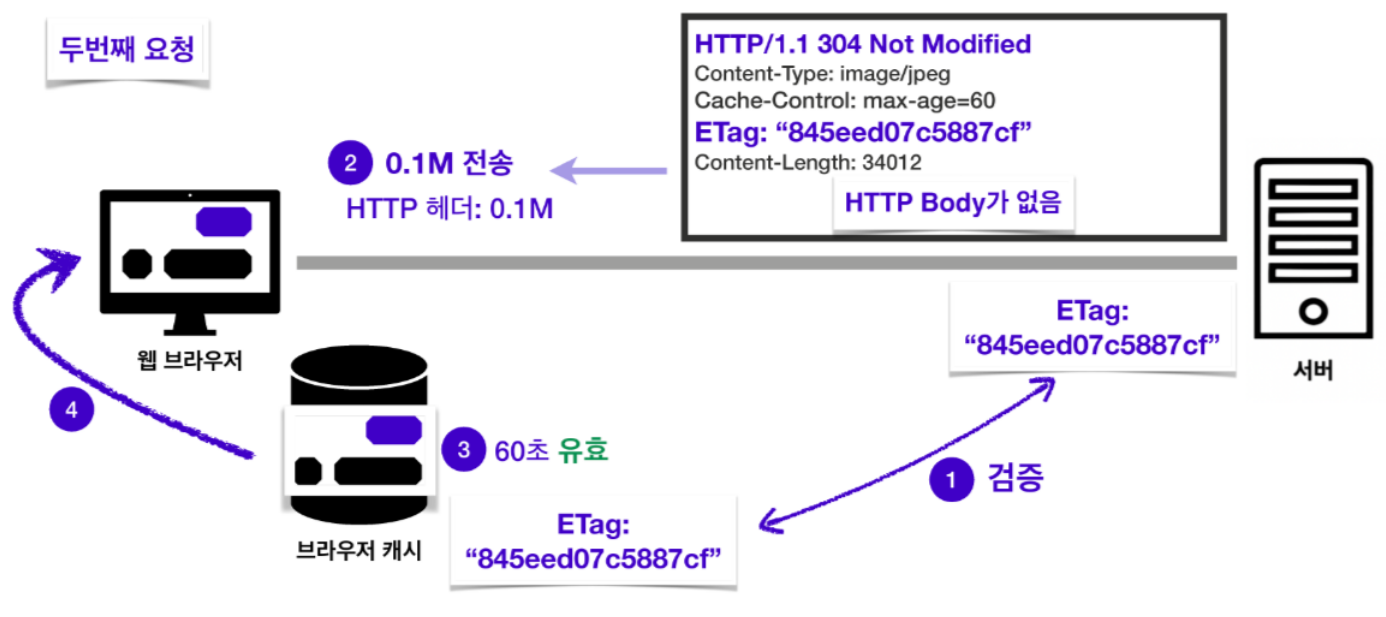
여기까지 두 쌍의 캐시 검증 헤더와 조건부 요청 헤더를 알아보았습니다. 두 쌍중의 헤더 중 한 쌍만 사용할 수도 있지만, 보통 두 종류를 동시에 사용합니다. 둘 중 하나만 사용했다가 매칭되는 응답 헤더가 없는 경우에는 재사용할 수 있는 경우에도 리소스를 다시 받아와야 하는 경우가 생길 수 있기 때문입니다.
Tree Shaking
트리쉐이킹(Tree Shaking)은 말 그대로 나무를 흔들어 잔가지를 털어내듯 불필요한 코드를 제거하는 것을 의미합니다. 웹 개발을 할 때, 애플리케이션의 규모가 커지면서 코드의 양이 방대해지고, 다양한 라이브러리를 가져다 사용하게 되면 불필요한 코드를 그대로 가져가는 경우가 생각보다 많이 생깁니다. 이런 불필요한 코드들을 찾아내어 제거하면 웹 사이트 성능 최적화에 큰 도움이 됩니다. 특히 JavaScript는 다음과 같은 이유로 가능하면 트리쉐이킹을 해주는 것이 좋습니다.
- JavaScript 파일의 크기
요즘은 과거 HTML 위주의 단순한 웹 페이지와는 비교도 안 될 정도로 규모 있고 화려한 인터랙션을 자랑하는 웹 애플리케이션들이 많습니다. 웹 사이트에서 인터랙션이 많아졌다는 것은 그만큼 JavaScript의 비중이 높아졌다는 뜻이기도 합니다. 실제로 http archive의 자료를 보면, 2011년도에 비해 웹 애플리케이션의 JavaScript 파일 크기의 중윗값이 데스크톱에서는 478.6% 증가했고, 모바일에서는 무려 796.6%나 증가했습니다.
JavaScript 파일의 크기만 커진 것이 아닙니다. JavaScript 파일을 요청하는 HTTP 요청 수 또한 데스크탑에서 155.6%, 모바일에서 425.0% 증가했습니다. 크기가 훨씬 커진 JavaScript 파일이 늘어난 요청 횟수만큼 더 오가는 것이니, 네트워크 리소스 소모가 그만큼 커졌다는 것을 알 수 있습니다.
JavaScript 파일 크기의 증가, 요청 횟수의 증가는 그만큼 파일이 오고 가는 동안 화면 표시가 늦어진다는 것을 뜻하고, 네트워크 속도가 느린 환경에서는 더 큰 병목현상을 유발합니다. 따라서 트리쉐이킹을 통해 파일 크기를 가능한 줄이는 것이 최적화에 도움이 됩니다.
- JavaScript 파일의 실행 시간
JavaScript 파일이 실행되기 위해서는 여러 과정을 거치게 됩니다. 다운로드부터 필요한 경우에는 우선 요청을 보내어 파일을 다운받아 온 다음 압축을 해제해야 합니다. 그다음에는 JavaScript 코드를 파싱하여 DOM 트리를 생성합니다. 파싱이 끝나면 컴파일하여 컴퓨터가 이해할 수 있는 언어로 바꿔줘야 합니다. 이 컴파일 과정까지 거쳐야지 비로소 코드를 실행할 수 있습니다. 이처럼 코드 실행까지 거쳐야 하는 과정이 많기 때문에 JavaScript는 다른 리소스에 비해서 실행까지 상대적으로 많은 시간을 소모하게 됩니다.
실제로 JavaScript 파일의 크기가 커진 만큼, 파일의 실행 시간 또한 증가한 것을 알 수 있습니다. 데스크톱에서는 측정한 기간이 얼마 되지 않아 확인하기 어렵지만, 모바일에서는 222.2%만큼 실행 시간이 길어져 2.9초의 시간이 소요되는 것을 확인할 수 있습니다.
JavaScript 파일의 실행은 CPU에 크게 영향을 받는데, 그렇다 보니 사양이 천차만별인 모바일 환경에서 그 영향이 더욱 두드러집니다. 실제로 휴대폰의 사양에 따라 소모 시간이 크게 차이 나는 것을 아래 도표를 통해 확인할 수 있습니다.
앞서 공부한 최적화의 개념에서, 페이지 로드 시간이 3초를 넘어가면 53%의 사용자가 이탈한다고 했습니다. JavaScript 파일을 요청하고 다운받아 오는 시간을 제외하고서 파일을 실행하는 데만 2.9초가 걸린다면 파일을 실행하는 동안에만 이미 50% 이상의 사용자가 이탈할 것이라고 예상할 수 있습니다. 기기 환경에 따라서 2.9초의 몇 배의 시간을 파일 실행에만 사용할 수도 있는 만큼 이탈률은 그만큼 커질 수 있습니다. 이러한 상황을 최대한 줄이기 위해서라도 트리쉐이킹을 통한 최적화가 필요합니다.
JavaScript 트리쉐이킹
웹팩 4버전 이상을 사용하는 경우에는 ES6 모듈(import, export를 사용하는 모듈)을 대상으로는 기본적인 트리쉐이킹을 제공합니다. Create React App을 통해 만든 React 애플리케이션도 웹팩을 사용하고 있기 때문에 트리쉐이킹이 가능합니다. 웹팩을 사용하는 환경에서 효과적으로 트리쉐이킹을 수행하는 방법에 대해서 알아봅시다.
-
필요한 모듈만 import 하기
import 구문을 사용해서 라이브러리를 불러와서 사용할 때, 라이브러리 전체를 불러오는 것이 아니라 필요한 모듈만 불러오면 번들링 과정에서 사용하는 부분의 코드만 포함시키기 때문에 트리쉐이킹이 가능해집니다.
불러오지 않은 코드는 빌드할 때 제외되므로 코드의 크기를 줄일 수 있게 됩니다. -
Babelrc 파일 설정하기
Babel은 자바스크립트 문법이 구형 브라우저에서도 호환이 가능하도록 ES5 문법으로 변환하는 라이브러리입니다. 이 때 ES5문법은 import를 지원하지 않기 때문에 commonJS 문법의 require로 변경시키는데, 이 과정은 트리쉐이킹에 큰 걸림돌이 됩니다. require는 export 되는 모든 모듈을 불러오기 때문입니다. 1번에서 작성한 것처럼 필요한 모듈만 불러오기 위한 코드를 작성해도 소용이 없어지는 것입니다.
이를 방지하기 위해서 Barbelrc 파일에 다음과 같은 코드를 작성해주면 ES5로 변환하는 것을 막을 수 있습니다.
{
“presets”: [
[
“@babel/preset-env”,
{
"modules": false
}
]
]
}반대로, modules 값을 true로 설정하면 항상 ES5 문법으로 변환하므로 주의해서 작성해야 합니다.
- sideEffects 설정하기
웹팩은 사이드 이펙트를 일으킬 수 있는 코드의 경우, 사용하지 않는 코드라도 트리쉐이킹 대상에서 제외시킵니다.
const crews = ['kimcoding', 'parkhacker']
const addCrew = function (name) {
crews.push(name)
}위 코드에서 addCrew 함수는 함수 외부에 있는 배열인 crews를 변경시키는 함수입니다. 해당 함수는 외부에 영향을 주지도 받지도 않는 함수, 순수 함수가 아니기 때문에 트리쉐이킹을 통해 제외하는 경우 문제가 생길 수도 있다고 판단해 웹팩은 이 코드를 제외시키지 않습니다.
이럴 때 package.json 파일에서 sideEffects를 설정하여 사이드 이펙트가 생기지 않을 것이므로 코드를 제외시켜도 됨을 웹팩에게 알려줄 수 있습니다. 다음과 같이 작성하면 애플리케이션 전체에서 사이드 이펙트가 발생하지 않을 것이라고 알려줍니다.
{
"name": "tree-shaking",
"version": "1.0.0",
"sideEffects": false
}혹은 아래와 같이 작성하여 특정 파일에서는 발생하지 않을 것임을 알려줄 수 있습니다.
{
"name": "tree-shaking",
"version": "1.0.0",
"sideEffects": ["./src/components/NoSideEffect.js"]
}- ES6 문법을 사용하는 모듈 사용하기
보통 3번까지 작성하면 트리쉐이킹이 잘 작동합니다. 그런데 트리쉐이킹이 적용되지 않는 라이브러리가 있다면, 해당 라이브러리가 어떤 문법을 사용하고 있는지 확인해볼 필요가 있습니다. 모듈에 따라서 ES5로 작성된 모듈이 있을 수도 있기 때문입니다. ES5 문법을 사용하는 모듈을 통째로 사용하는 상황이라면 상관없지만, 일부만 사용하는 경우라면 해당 모듈을 대체할 수 있으면서 ES6를 지원하는 다른 모듈을 사용하는 것이 트리쉐이킹에 유리합니다. ES6 문법을 사용하는 모듈을 사용하면 해당 모듈에서도 필요한 부분만 import 해서 사용하지 않는 코드는 빌드할 때 제외되기 때문입니다.
Lighthouse
사이트를 검사하여 성능 측정을 할 수 있는 도구인 Lighthouse는 다양한 지표를 이용하여 웹페이지의 성능 검사를 해줄 뿐만 아니라 그에 대한 개선책도 제공해줍니다.
Lighthouse는 구글에서 개발한 오픈소스로서 웹 페이지의 품질을 개선할 수 있는 자동화 툴입니다. Lighthouse는 성능, 접근성, PWA, SEO 등을 검사하며 이를 이용해 사용자는 어떤 웹페이지든 품질 검사를 할 수 있습니다.
Lighthouse는 Chrome DevTools부터 CLI, 노드 모듈 등 다양한 경로를 통해 사용할 수 있습니다. 검사할 페이지의 url을 Lighthouse에 전달하면 Lighthouse는 해당 페이지에 대한 여러 검사를 실행합니다.
그 후, 위 이미지처럼 검사 결과에 따른 리포트를 생성하고 개발자는 해당 리포트를 통해 점수가 낮은 지표에 대해 개선을 꾀할 수 있습니다. 또한 각각의 지표가 왜 중요한지, 어떻게 개선할 수 있는 지에 대한 레퍼런스도 리포트에서 참고할 수 있습니다.
Lighthouse 시작하기
Chrome 개발자 도구에서 실행하기
1.크롬에서 검사하고 싶은 페이지의 url을 입력합니다.
2.개발자 도구를 엽니다.
3.lighthouse 탭을 클릭합니다.
Generate report를 클릭합니다. Categories에서 특정한 지표만 선택하여 검사할 수도 있습니다.
대략 30-60초간 검사가 실행됩니다. 그 후 아래와 같이 리포트가 해당 페이지의 개발자 도구내에 생성됩니다.
Node CLI에서 실행하기
Lighthouse를 설치합니다. 이때-g 옵션을 사용하여 Lighthouse를 전역 모듈로 설치하는 것이 좋습니다.
npm install -g lighthouse다음의 명령어로 검사를 실행할 수 있습니다.
lighthouse <url>다음의 명령어로 모든 옵션을 볼 수 있습니다.
lighthouse --help Lighthouse 노드모듈을 이용해 동적으로 프로그래밍하여 페이지 검사 리포트를 생성할 수도 있습니다. 이를 이용해 성능 테스트를 자동화할 수 있습니다.
Lighthouse 분석 결과 항목
-
Performance
Performance 항목에서는 웹 성능을 측정합니다. 화면에 콘텐츠가 표시되는데 시간이 얼마나 걸리는지, 표시된 후 사용자와 상호작용하기 까진 얼마나 걸리는지, 화면에 불안정한 요소는 없는지 등을 확인합니다. -
Accessibility
Accessibility 항목에서는 웹 페이지가 웹 접근성을 잘 갖추고 있는지 확인합니다. 대체 텍스트를 잘 작성했는지, 배경색과 콘텐츠 색상의 대비가 충분한지, 적절한 WAI-ARIA 속성을 사용했는지 등을 확인합니다. -
Best Practices
Best Practices 항목에서는 웹 페이지가 웹 표준 모범 사례를 잘 따르고 있는지 확인합니다. HTTPS 프로토콜을 사용하는지, 사용자가 확인할 확률은 높지 않지만 콘솔 창에 오류가 표시 되지는 않는지 등을 확인합니다. -
SEO
SEO 항목에서는 웹 페이지가 검색 엔진 최적화가 잘 되어있는지 확인합니다. 애플리케이션의 robots.txt가 유효한지, 요소는 잘 작성되어 있는지, 텍스트 크기가 읽기에 무리가 없는지 등을 확인합니다. -
PWA (Progressive Web App)
PWA 항목에서는 해당 웹 사이트가 모바일 애플리케이션으로서도 잘 작동하는지 확인합니다. 앱 아이콘을 제공하는지, 스플래시 화면이 있는지, 화면 크기에 맞게 콘텐츠를 적절하게 배치했는지 등을 점수가 아닌 체크리스트로 확인합니다.
Lighthouse의 Performance 측정 메트릭
- First Contentful Paint
First Contentful Paint, 줄여서 FCP는 성능(Performance) 지표를 추적하는 메트릭입니다.
FCP는 사용자가 페이지에 접속했을 때 브라우저가 DOM 컨텐츠의 첫 번째 부분을 렌더링하는 데 걸리는 시간을 측정합니다. 즉 사용자가 감지하는 페이지의 로딩속도를 측정할 수 있습니다. 우수한 사용자 경험을 제공하려면 FCP가 1.8초 이하여야 합니다.
페이지의 이미지와 canvas 요소, SVG 등 모두 DOM 콘텐츠로 구분되며 iframe 요소의 경우 이에 포함되지 않습니다.
이때 FCP처럼 일부 콘텐츠의 첫 번째 렌더링 시점을 측정하는 것이 아닌 주요 콘텐츠 로딩이 완료된 시점을 측정하는 것을 목표로 한다면 Large Contentful Paint, 줄여서 LCP 지표로 확인할 수 있습니다.
- Largest Contentful Paint
Largest Contentful Paint, 줄여서 LCP는 뷰포트를 차지하는 가장 큰 콘텐츠(이미지 또는 텍스트 블록)의 렌더 시간을 측정합니다. 이를 이용해 주요 콘텐츠가 유저에게 보이는 시간까지를 가늠할 수 있습니다.
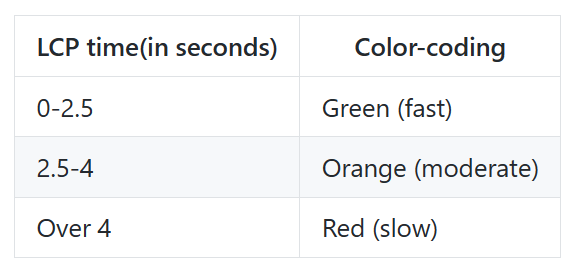
다음의 표를 기준으로 LCP 점수를 해석할 수 있습니다.
- Speed Index
Speed Index는 성능(Performance) 지표를 추적하는 메트릭입니다. Speed Index는 페이지를 로드하는 동안 얼마나 빨리 컨텐츠가 시각적으로 표시되는 지를 측정합니다.
Lighthouse는 먼저 브라우저의 페이지 로딩과정을 각 프레임마다 캡쳐합니다. 그리고 프레임 간 화면에 보이는 요소들을 계산합니다. 그 후 Speedline Node.js module을 이용하여 Speed Index 점수를 그래프의 형태로 나타냅니다.
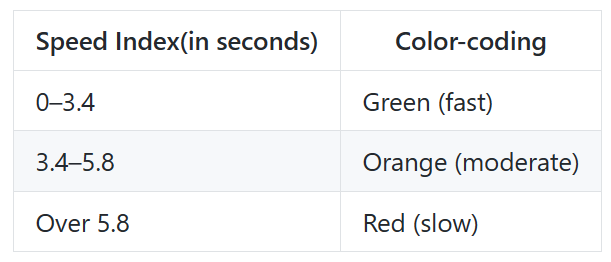
점수에 따라 다음의 기준으로 성능을 분류합니다.
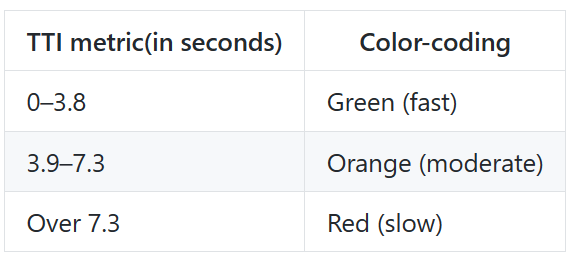
- Time to interactive
Time to interactive, 줄여서 TTI는 페이지가 로드되는 시점부터 사용자와의 상호작용이 가능한 시점까지의 시간을 측정합니다.
TTI는 페이지가 완전히 상호 작용 가능하기까지의 시간을 측정합니다. 그 기준은 다음과 같습니다.
페이지에 FCP로 측정된 컨텐츠가 표시되어야 합니다.
이벤트 핸들러가 가장 잘 보이는 페이지의 엘리먼트에 등록됩니다.
페이지가 0.05초안에 사용자의 상호작용에 응답합니다.
TTI 점수는 아카이브된 HTTP 데이터를 기반으로 백분위 단위로 점수를 측정합니다. 다음의 표를 기준으로 점수를 해석할 수 있습니다.
- Total Blocking Time
대부분의 사용자는 0.05초가 넘는 작업에는 응답이 올때까지 계속 키보드를 두드리거나 마우스를 클릭하기 때문에 페이지가 느리다고 인식합니다. 이를 개선하기 위한 지표가 TBT입니다.
Total Blocking Time, 줄여서 TBT는 페이지가 유저와 상호작용하기까지의 막혀있는 시간을 측정합니다. Lighthouse에서는 FCP와 TTI 사이에 긴 시간이 걸리는 작업들을 모두 기록하여 TBT를 측정합니다.
- Cumulative Layout Shift
온라인 기사를 읽다가 갑자기 페이지 일부분이 바뀐 경험이 있으신가요? 아무런 경고 없이 텍스트가 움직이며 읽던 부분을 놓치게 되거나, 더 심한 경우 링크나 버튼을 탭하기 직전 갑작스레 링크가 움직이는 바람에 의도하지 않은 것을 클릭할 수도 있습니다.
대부분의 경우 이러한 경험은 짜증스러운 정도에서 그치지만, 경우에 따라 실제 피해를 겪게 될 수 있습니다. 위 예시처럼 결제와 관련된 경우가 그렇습니다. 이런 상황을 측정하기 위한 지표가 CLS입니다.
Cumulative Layout Shift, 줄여서 CLS는 사용자에게 컨텐츠가 화면에서 얼마나 많이 움직이는지(불안정한 지)를 수치화한 지표입니다. 이 지표를 통해 화면에서 이리저리 움직이는 요소(불안정한 요소)가 있는 지를 측정할 수 있습니다.
개선 방향 잡기
Lighthouse는 성능을 측정할 뿐 아니라 무엇이 시간을 많이 소모하는지, 어떻게 개선하여 최적화를 할 수 있을지 해결책도 제시해줍니다. Opportunities 항목을 확인하면 각 메트릭별 문제를 확인할 수 있습니다.
Lighthouse는 웹 성능 최적화 뿐만 아니라 웹 접근성, 웹 표준, SEO 관련 항목도 확인하고 해결책을 제시해줍니다. Lighthouse를 이용해서 웹 사이트 성능 최적화 뿐만 아니라, 웹 표준, 웹 접근성, SEO도 개선시켜 보세요.
