0504
-
GridSearchCV -> 지정된 조합만 보기 떄문에 해당 그리드를 벗어나는 곳에 좋은 성능을 내는 하이퍼파라미터가 있다면 찾지 못하는 단점이 있음
-
RandomSearchCV -> 랜덤한 값을 넣고 하이퍼파리미터를 찾음.
처음에는 범위를 넓게 지정하고 그 중에 좋은 성능을 내는 범위를 점점 좁혀가면서 찾음 -
처음/오랜만에 쓰는 함수 -> 함수?
-
bestestimator
-> 어떤 분류기가 가장 좋은 성능을 내는지 알려줌 -
bestscore
-> 가장 좋은 성능을 낸 점수를 알려줌 -
cvresults
-> cv는 cross validation의 약자로 어떤 조각이 어떤 성능을 냈는지를 알려줌(기본값이 5) -
Fitting 5 folds for each of 5 candidates, totalling 25 fits => 5 fold 는 cv 조각 5개를 의미하며 5 candidates 는 n_iter를 의미
❗️랜덤포레스트 안에 트리의 개수가 100개가 기본값이라면 그 내부에서도 트리를 100개를 만들기 때문에 디시전트리를 사용할 때보다 속도가 더 걸린다는 점도 함께 알기❗️ -
7:3 이나 8:2 로 나누는 과정은 hold-out-validation
hold-out-validation 은 중요한 데이터가 train:valid 가 7:3이라면 중요한 데이터가 3에만 있어서 제대로 학습되지 못하거나 모든 데이터가 학습에 사용되지도 않음. 그래서 모든 데이터가 학습과 검증에 사용하기 위해 cross validation을 함. -
cross validation은 속도가 오래걸린다는 단점이 있기도 하지만 validation의 결과에 대한 신뢰가 중요할 때 사용. 예를 들어 사람의 생명을 다루는 암여부를 예측하는 모델을 만든다거나 하면 좀 더 신뢰가 있게 검증을 해야겠죠.
-
hold-out-validation 은 한번만 나눠서 학습하고 검증하기 때문에 빠르다는 장점. 하지만 신뢰가 떨어지는 단점. hold-out-validation 은 당장 비즈니스에 적용해야 하는 문제에 빠르게 검증해보고 적용해 보기에 좋음.
-
cross validation 이 너무 오래 걸린다면 조각의 수를 줄이면 좀 더 빠르게 결과를 볼 수 있고 신뢰가 중요하다면 조각의 수를 좀 더 여러 개.
0601
- cross_val_predict는 예측한 predict값을 반환하여 직접 계산해 볼 수 있음.
- cross_val_score, cross_validate는 스코어를 조각마다 직접 계산해서 반환
MAE
- 모델의 예측값과 실제 값 차이의 절대값 평균
- 절대값을 취하기 때문에 가장 직관적임
MSE
- 모델의 예측값과 실제값 차이의 면적의(제곱) 평균
- 제곱을 하기 때문에 특이치에 민갑
RMSE
- MSE에 루트를 씌운 값
- RMSE를 사용하면 지표를 실제 값과 유사한 단위로 다시 변환하는 것이기 때문에 MSE보다 해석이 더 쉽움
- MAE보다 특이치에 Robust(강하다)-
MAE
-> abs(y_train - y_valid_pred).mean()
-> from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_train, y_valid_pred) -
RMSLE
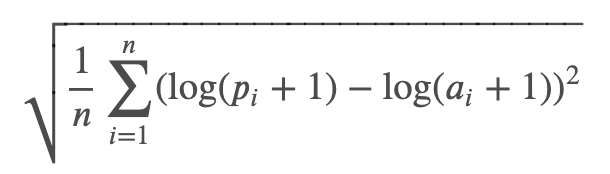
-
로그를 취하면 skewed 값이 덜 skewed(찌그러지게), 분포가 좀 더 정규분포에 가까워지기도 함.
✔️ RMSLE에서 log + 1을 하는 이유는?
-> x가 1보다 작으면 음수가 나오기 때문에 1을 더해서 1이하의 값이 나오지 않게 하기위해
✔️ 로그를 취하기 전에 모든 값에 1을 더해서 가장 작은 값이 될 수 있는 0이 1이 되도록 더해주는 이유는 마이너스 값이 나왔는데 MSE를 계산한다면?
-> 의도치 않은 큰 오차가 나올 수 있기 때문에 가장 작은 값이 될 수 있는 0에 1을 더해서 마이너스 값이 나오지 않게 함.
-> train 의 최솟값은 1이지만 test 의 예측값이 0이 나올 수도 있기 때문
-> RMSLE는 RMSE와 거의 비슷하지만 오차를 구하기 전에 예측값과 실제값에 로그를 취해주는 것만 다름
RMSLE는 예측과 실제값의 "상대적" 에러를 측정해줍니다.
예를 들어서
실제값: 90, 예측값: 100 일 때
RMSE = 10
RMSLE = 0.1042610...
실제값: 9,000, 예측값: 10,000 일 때
RMSE = 1,000
RMSLE = 0.1053494...
RMSLE의 한계는 상대적 에러를 측정하기 때문에
예를 들자면 1억원 vs 100억원의 에러가 0원 vs 99원의 에러와 같다 라고 나올 수 있습니다.
그리고 RMSLE는 실제값보다 예측값이 클떄보다, 실제값보다 예측값이 더 작을 때 (Under Estimation) 더 큰 패널티를 부여합니다.
배달 시간을 예측할때 예측 시간이 20분이었는데 실제로는 30분이 걸렸다면 고객이 화를 낼 수도 있을겁니다. 이런 조건과 같은 상황일 때 RMSLE를 적용할 수 있을 것입니다. - np.log(x+1) == np.log1p(x)
부동산 가격으로 예시를 들면
1) 2억원짜리 집을 4억으로 예측
2) 100억원짜리 집을 110억원으로 예측
Absolute Error 절대값의 차이로 보면 1) 2억 차이 2) 10억 차이
Squared Error 제곱의 차이로 보면 1) 4억차이 2) 100억차이
Squared Error 에 root 를 취하면 absolute error 하고 비슷해짐
비율 오류로 봤을 때 1)은 2배 잘못 예측, 2)10% 잘못 예측RMSE: 오차가 클수록 가중치를 주게 됨(오차 제곱의 효과)
RMSLE: 오차가 작을수록 가중치를 주게 됨(로그의 효과)
MAE: 가중치 없음(제곱, 로그 둘 다 없음)- RMSLE 는 최솟값과 최댓값의 차이가 큰 값에 주로 사용. 대표적인 예가 부동산 가격 등. 그런데 측정 공식은 이 분야에는 이 공식이 딱 맞다라기 보다는 보통 해당 도메인에서 적절하다고 판단되는 공식을 선택해서 사용.
