[ 0106 ]
결측치 보기
df.isnull() # 결측치 확인(True, False)
df.isnull().sum() # 결측치의 수 확인
df.isnull().mean() #결측치 비율 구하기
count() # nan 값은 제외하고 카운트
sns.heatmap(df(), **cmap='gray'**) # colormap
plt.**figure(figsize=(12, 8))** # 출력되는 그래프의 사이즈 지정수치형 변수
plt.show() # = plt;
# 로그 제거(표만 보기)비대칭도(왜도)
.skew() # 왜도 구하기첨도
.kurt() # 첨도 구하기normal=0 에 가까울수록 정규분포에 가까움hist — 빈도, kde — 곡선(밀도) => 적분했을 때 1이 되는 값
hue(색으로 그룹핑) = group byecdf — 누적해서 그림스케일링 # 값의 수치와 범위가 다른 값을 비슷한 값을 갖도록 만들어주는 것
# 즉, 평균이 0이고 편차가 1이 되게 만들어주는 것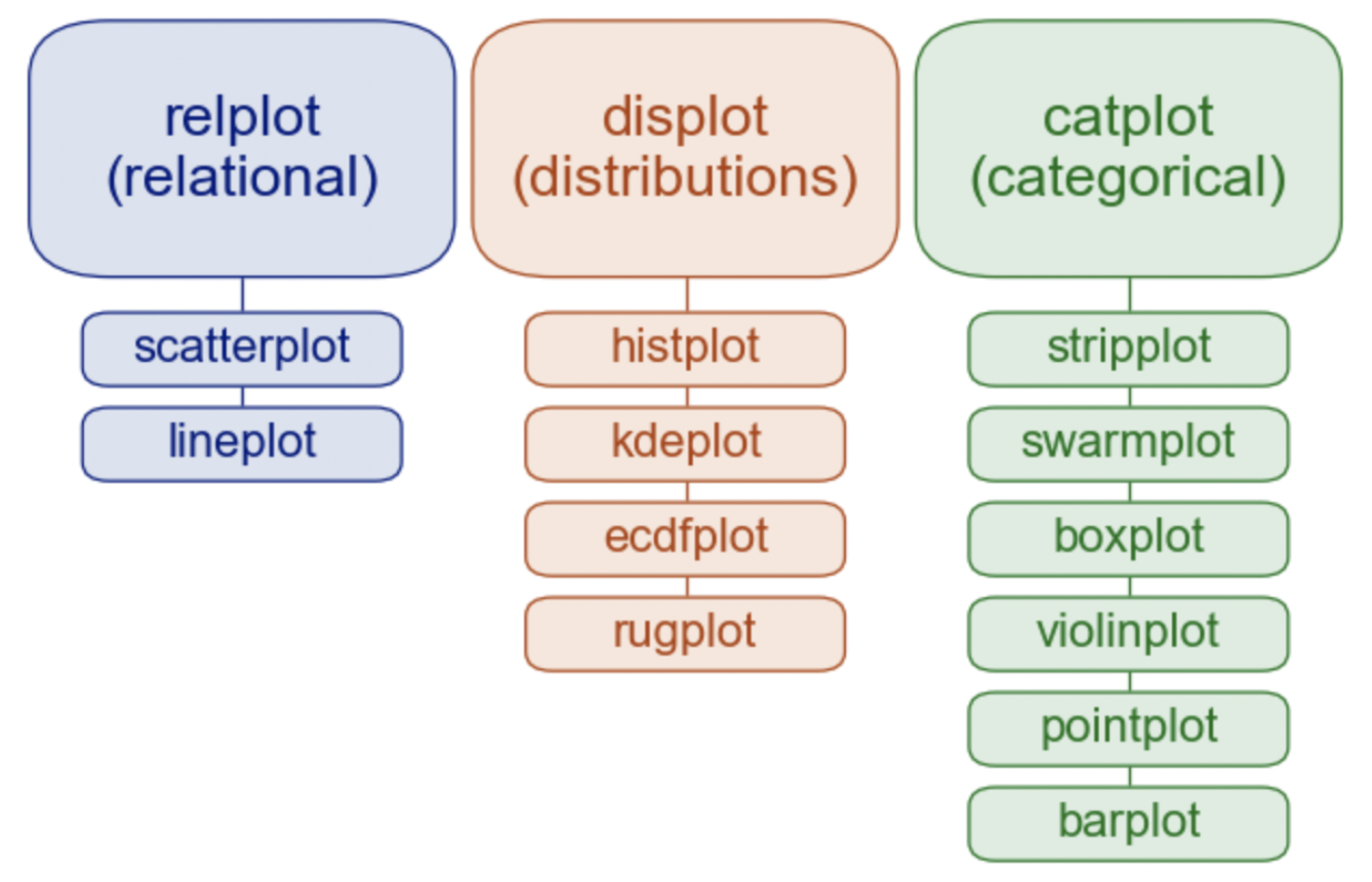
.boxplot() # 사분위 수
.scatterplot() # 2개의 수치변수 비교
.regplot() # 회귀선 시각화
# hue 지원X
.residplot() # 잔차 시각화
# 잔차 : 값의 차이(회귀선과 얼마나 멀리 떨어져 있는지의 값)
.lmplot() # regplot과 비슷 하지만, hue(색상)과 서브플롯을 그릴 수 있음
.jointplot() # 2개의 수치변수 표현
.pairplot() # x축과 y축의 쌍을 지어서 그래프로 표현
.lineplot()
.relplot() [ 0107 ]
기술통계
df.describe(include=“object”) 범주형 데이터
—> exclude=“object” 수치형 데이터범주형 변수
sns.countplot(data=df, x="origin") # x축이나 y 하나만 지정(나머지는 빈도수)
df["origin"].value_counts() # 1개 변수의 빈도수
pd.crosstab(index=df['origin'], columns=df['cylinders'])
# 시각화한 값 구하기
ci=errorbar # 신뢰구간 표시X
df.groupby('origin')[['mpg']].mean() # ['mpg']면 시리즈 [['mpg']]면 데이터프레임
pd.pivot_table() = groupby()와 거의 유사
# pivot_table은 직관적인 사용법, 기본값이 평균
# crosstab은 pivot_table을 사용하기 쉽게 만든 기능
groupby -> pivot_table -> crosstab
estimator=sum # 합계 값 구하기
# = estimator=np.sum
df.groupby(by=['origin', 'cylinders'])['mpg'].mean().unstack()
# 마지막 인덱스 값을 컬럼으로 끌어올림 <-> .stack() 컬럼값을 인덱스로 내림
pivot 과 pivot_table 차이 # -> 연산을 하는지의 여부(연산 O : pivot_table)
boxplot -> boxenplot -> violinplot # 점점 더 보완해서 표현(자세하게)
.scatterplot()
# 범주형 데이터를 scatterplot으로 그렸을 때 단점 : 점이 겹칠 수 있다.(빈도수를 알기 어렵다.)
# -> stripplot(위로 퍼져 보임) -> swarmplot(옆으로 퍼져 보임)
# 점점 더 보완해서 표현
.catplot() # 범주형 데이터를 서브플롯으로 사용하고자 할 때 사용
범주형, 수치형 구분법
#히스토그램을 잘게 나눠 쪼갰을 때 이가 빠져있으면 범주형에 가까움[ 0201 ]
웹데이터 수집—————————
라이브러리 불러오기
* import FinanceDataReader as fdr # 금융 데이터 수집 라이브러리 불러오기한국거래소 상장종목 전체 가져오기
df = fdr.StockListing() # ()의 전체 종목 가져오기
df.sort_values(by='ListingDate', ascending=False).head()
# 최근에 상장한 회사 확인파일로 저장하고 불러오기
df.to_csv('___.csv', index=False)
# 메모리에 있는 데이터프레임 데이터를 to_’’의 ‘’이름을 가진 파일로 바꿈
# index=False : unnamed 안보이게[ 0202 ]
**URL 보는 법**
소스코드 -> Network -> 지우기 -> 수집 할 페이지 들어가기 -> Header -> Request URLpandas만으로 데이터 수집하기
read_html로 수집하기
table = pd.read_html(url) # 특정 url 불러오기반복문으로 데이터 가져오기
display() # print()보다 보기좋게 출력
cols = df.columns
…….
news.columns = cols
# 일괄적으로 컬럼 이름이 똑같이 바뀜수집한 데이터 활용
pd.concat() # 수집한 데이터 합치기
.dropna() # 결측치 제거
df_news.reset_index(drop=True)
# 섞여있던 인덱스를 인덱스 번호 순차적으로 초기화,
# drop=True -> 인덱스가 기존, 새것 2개로 나오기 때문에 새로운 인덱스 하나만 표시하기 위해
얕은복사 => 원본의 값이 바뀜
깊은복사 => .copy() 원본에 영향X
df_news['A'].str.contains('B')
# A에서 B문구가 포함된 행 구하기 <-> ~df_news[‘A’].st……
from tqdm import trange # 반복분 진행상황을 알려줌
# range는 범위만 지정
<-> trange는 진행상태를 표시 (범위가 지정되어 있을 때만 사용)
time.sleep() # 데이터를 쉬었다 가져옴
pd.concat(news_list) # 하나의 데이터프레임으로 합치기
.to_csv(file_name, index=False) # csv 파일로 저장
pd.read_csv(file_name) # csv 파일 읽어오기[ 0203 ]
import requests # 작은 브라우저로 웹사이트를 읽어오는 목적의 라이브러리
* get — Query String, post — Form Data
* post 는 회원 가입할 때 적은 정보 폼, 물건이나 음식 주문할 때 메시지 입력하고 버튼 누를 때, 검색어 입력하고 버튼 눌러 전송했을 때 주로 사용BeautifulSoup 을 통한 table 태그 찾기
* from bs4 import BeautifulSoup as bs
— 문서가 보기 좋게 바뀌는 라이브러리
* html.a
— 태그 한줄
* html.find_all(‘a’)
— a 태그 모두
* html.select(‘a’)
— a 태그의 기능들을 다 가져옴
* 차이 :
- find_all은 attribute를 지정해서 사용할 수 있음(콕 찝어서 메인뉴스에 대한 링크만 가져와줘)
ex) class가 A인 B를 찾아라
- select는 구조로 지정해서 사용
ex) class > A > B수집 데이터 활용
.dropna() # 결측치 제거
for문 # 범위가 정해져 있을 때
while문 # 마지막이 뭔지 모를 때
BeautifulSoup을 사용하지 않은 이유
# pd.read_html 에 그 기능이 내장되어있어서중복데이터 제거
df_day.drop_duplicates() # 중복 데이터 제거**과학적 기수법**
: 너무 크거나 너무 작은 숫자들을 십진법으로 편하게 작성하여 표현하는 방법[ 0204 ]
**ETF(상장지수펀드)**
: 기초지수의 성과를 추적하는 것이 목표인 인덱스 펀드, 주식처럼 거래, 신속하고 투명JSON
: 비동기 통신을 통해 데이터를 내려받아 웹브라우저에 자바스크립트로 데이터를 표현.json() # JSON타입으로 데이터 받기
etf_json[“A”][“B”]
# A > B 의 하위 구조로 목록을 찾고자 하는 데이터를 가져옴
.str.split(expand=True) # 나누기
expand=True # 기본값은 리스트, True로 데이터프레임 형태로 가져옴
from datetime import datetime # 날짜 사용 라이브러리
datetime.today().strftime("%Y-%m-%d") # 오늘의 날짜
.strftime("%Y-%m-%d") # 오늘의 날짜를 년도-월-달 로 출력
pd.read_csv(file_name, dtype={"itemcode" : "object"})
# 맨 앞에 0이 안보이면 데이터타입 지정
# ex) 010-1234 -> 10-1234
Today I Learn