[crawling]_크롤링기초

크롤링
- 웹에서 원하는 자료를 컴퓨터에게 수집해오도록 하는 기술
- requests 라이브러리를 활용한 브라우저 없는 크롤링 (속도빠름)
- selenuim 라이브러리를 활용한 물리 드라이버 크롤링 (시각적 이해도)
- urllib 라이브러리를 활용한 api 크롤링 등이 있다.
- 크롤러의 역할은 원하는 정보를 포함한 자료를 수집해오는 것까지이며
- 실제로 원하는 데이터를 용도에 맞게 처리하는 것은 beautifulsoup가 담당한다.
# 크롤링 작업을 위한 라이브러리 임포트
from bs4 import BeautifulSoup
from selenium import webdriver
import requests
# 코드 진행 지연을 위한 time 임포트
import time
# 2022년도 7월 이후 selenium 업데이트로 인한 xpath 추적시 임포트
from selenium.webdriver.common.by import Byselenium 설치
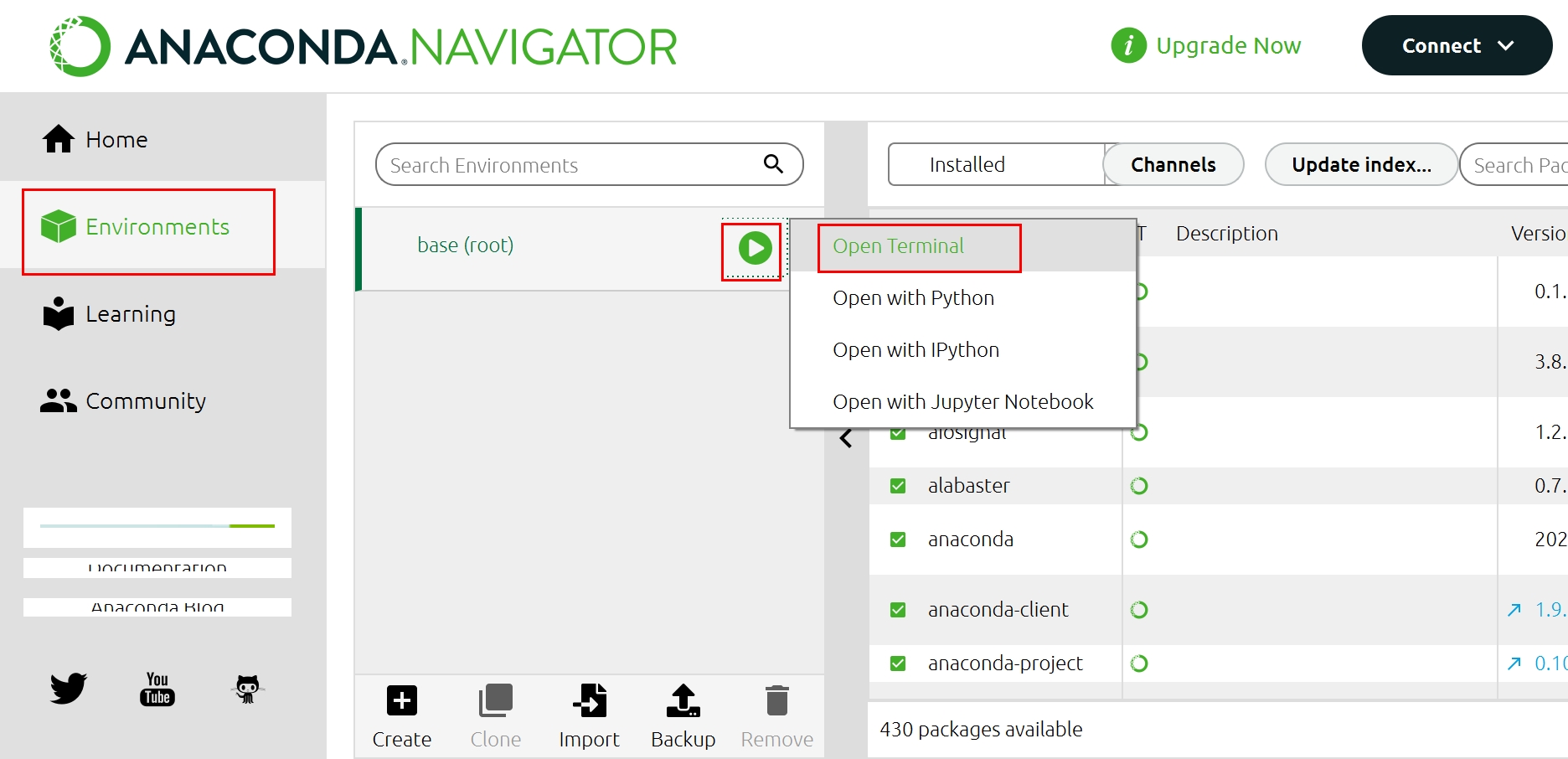
- anaconda navigator에서 좌측 envionments를 선택합니다
- 중간에 base(root)우측에 붙어있는 재생버튼 클링 -> open terminal을 선택합니다
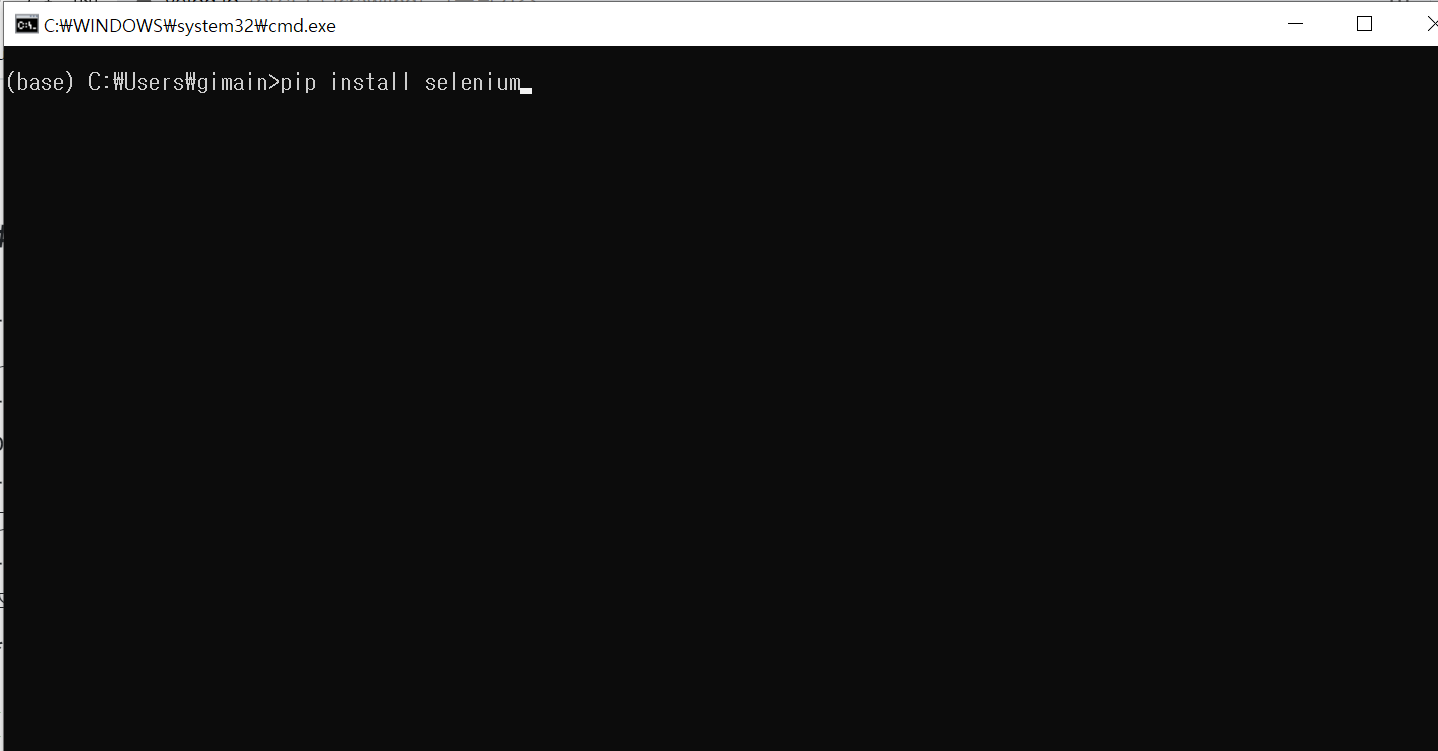
- 열리는 cmd창에서 pip install selenium을 입력합니다.
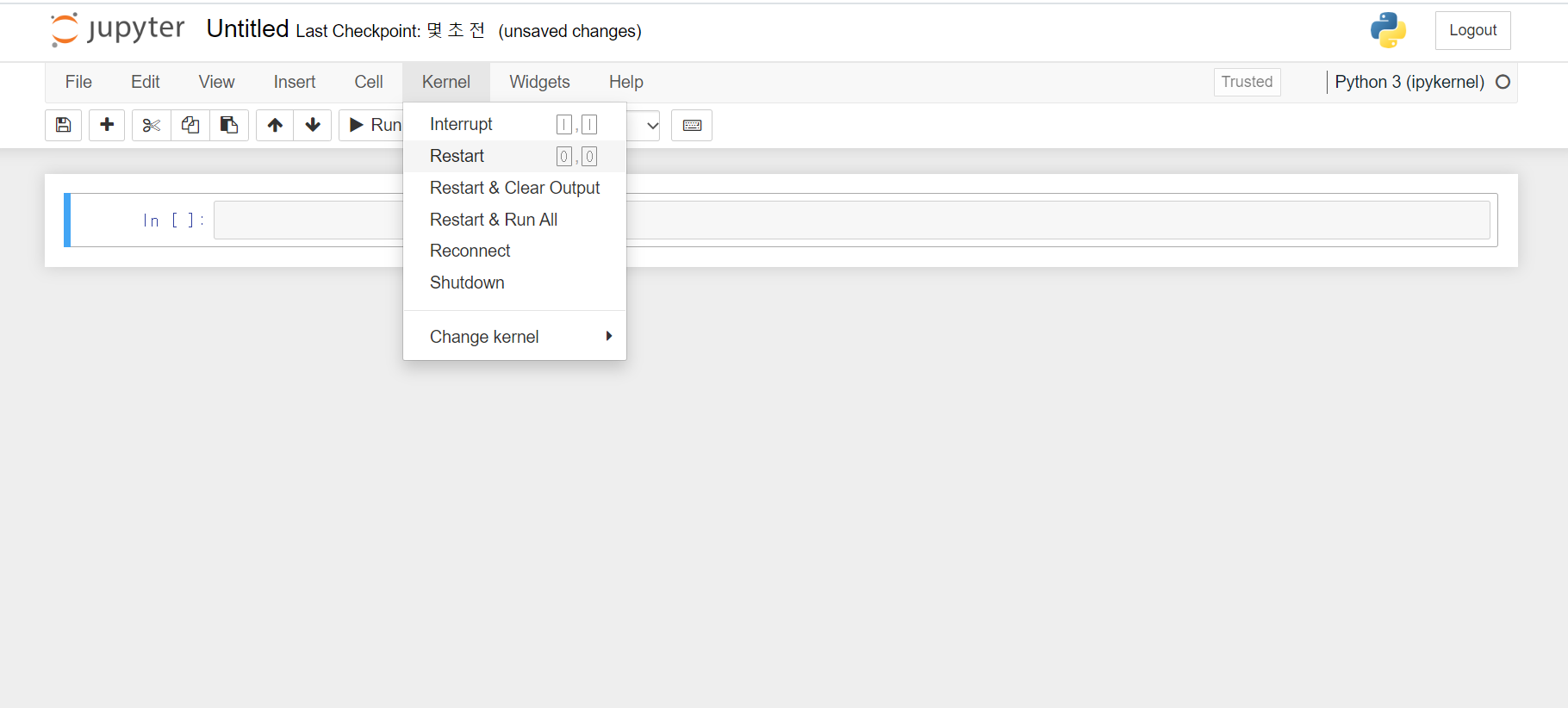
- jupyter notebook > kernel > restart 를 눌러야 적용된다.
크롬드라이버 다운받기
- 크롬창 우측 상단 메뉴 클릭
- 밑에서 두 번째에 있는 "도움말" 항목에 마우스 갖다대기
- Chrome정보 클릭하기
- Chrome정보에 나온 버전(강사 컴퓨터는 현재 크롬 101버전 사용중) 확인하기
- https://chromedriver.chromium.org/downloads
위 주소로 접속해서 버전에 맞는 다운로드 링크로 가기- chromedriver zip파일 받아서 내부 chromedriver.exe파일에 대한 압축을 주피터노트북 코드가 있는 쪽에 풀기
(window -> win32, 리눅스 맥 등은 맞는버전으로)
코드
# driver 라는 변수를 이용해 물리 브라우저를 제어합니다.
driver = webdriver.Chrome('chromedriver')
# 딜레이 1초
# time.sleep(지연시간(초)) 입력시 해당 시간만큼 코드 실행이 지연됩니다.
time.sleep(1)
# .get(접속주소)를 입력하면 브라우저가 해당 주소로 접속합니다.
driver.get("https://naver.com")
time.sleep(2)
# 네이버 로그인버튼의 xpath를 따온다음 클릭시키기
## xpath 복사해오기 : 크롬창에서 F12(DecTool실행) > 좌측상단에 영역선택 아이콘 클릭
## > 로그인버튼 클릭 > 파란색 영역 마우스 우클릭 > copy > copy xpath)
# driver.find_element(by.xpath, '//*[@id="account"]/a').click() 현재 안돌아가는 코드
driver.find_element(By.XPATH, '//*[@id="account"]/a').click()
# 로그인창 아이디입력칸 (폼) xpath를 따서 지정해주세요. .click()은 쓰지 않으셔도 됩니다.
# 키 입력은 변수로 저장해놓고, send_keys('전송문자열')을 입력해줍니다.
driver.find_element(By.XPATH, '//*[@id="id"]').send_keys('abcd1234')
# 비번은 직접 해주세요.(대충 아무 문자열이나 전송해주세요.) ### \n하면 엔터쳐짐
driver.find_element(By.XPATH, '//*[@id="pw"]').send_keys('garlic**\n')
time.sleep(15)
# 밑에 로그인 버튼을 다시 눌러주세요.
# driver.find_element(By.XPATH, '//*[@id="log.login"]').click()
# 로그인 되었을때 카페로 접속
driver.get("https://cafe.naver.com/specup")
time.sleep(3)
# 글쓰기 버튼 클릭
driver.find_element(By.XPATH, '//*[@id="cafe-info-data"]/div[4]/a').click()
time.sleep(3)
# ( 코드-> 컴퓨터가 보는 화면 )(랜더링화면->우리가 보는 화면)
# 브라우저를 다 쓰면 닫아줘야 메모리 절약이 됩니다.
driver.close()
교보문고 사이트 접근 실습
- 네이버 검색창에 "교보문고" 키워드로 검색
- 검색 결과로 나온 창에서 "교보문고" 이동 링크 클릭
# 네이버 접속
driver = webdriver.Chrome('chromedriver')
driver.get("https://naver.com")
time.sleep(1)
# 검색창에 교보문고 입력
driver.find_element(By.XPATH, '//*[@id="query"]').send_keys('교보문고')
driver.find_element(By.XPATH, '//*[@id="search_btn"]/span[2]').click()
# 검색결과에서 교보문고 클릭
driver.find_element(By.XPATH, '//*[@id="main_pack"]/section[1]/div/div/div[1]/div/div[1]/a/span[2]').click()
time.sleep(3)
driver.close()특정 url로 접근했을때 바로 원하는 정보를 얻을 수 있는 경우
- 그냥 바로 접근하면 된다
- 그러나 페이스북 같이 특정 조건을 만족해야 추가적인 자료를 보여주는 사이트도 있고
- 로그인해야만 자료에 접근할 수 있는 사이트도 있기 때문에
- 어떻게 접근해야 원하는 자료를 얻어올 수 있는지는 신중하게 고려해야함
driver = webdriver.Chrome()
time.sleep(1)
driver.get('https://product.kyobobook.co.kr/bestseller/online?period=001')
time.sleep(1)
# 브라우저가 특정 페이지에 접근했을때, 해당 페이지 소스코드 전체 긁어오기
# 여기까지가 셀레니움의 역할이다. 가져온 소스코드는 뷰티불수프로 저장한다
# driver.page_source는 source 변수에 전체 페이지 소스를 문자로 저장한다
source = driver.page_source
print(type(source))
print(source)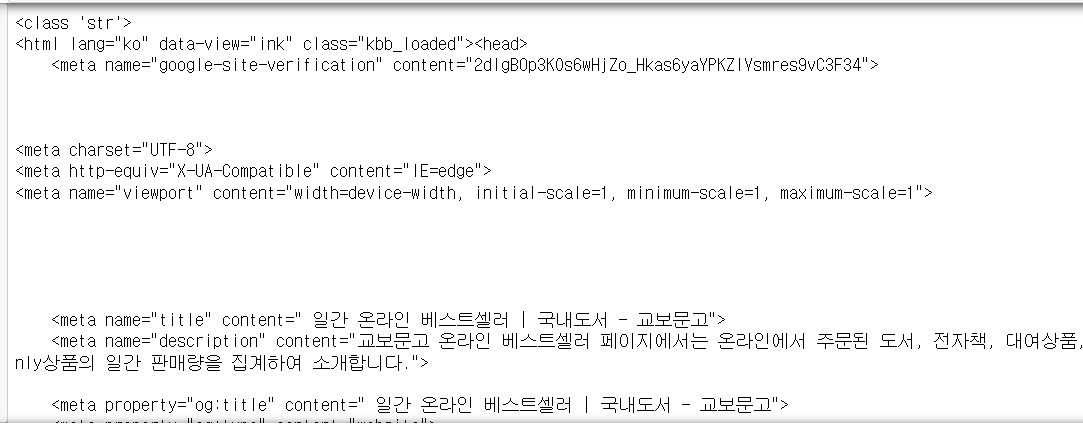
# 위에 가져온 문자들을 컴퓨터가 읽어서 이해하는 작업이 필요하다(파싱)
# BeautifulSoup(소스코드, "html.parser") 로 입력시 해당 코드를 html 형식으로 인식한다
# BeautifulSoup는 이해할 수 있는 코드로 가공해주는 역할이다
# 해당 str(문자열) 자료를 html형식으로 인식시키는것을 "파싱" 이라고 한다.
# 책을 소유하고 있다고 그 책에 대해 반드시 이해하고 있는건 아니듯 책 내용을 읽어서 이해하고
# 지식을 구조화해야 비로소 책을 이해하고 있다고 할 수 있는데
# 뷰티플수프도 소스코드가 단순 문자로 존재할때는 기능을 쓸 수 없지만
# 파싱을 통해 소스코드 구조를 이해하면 정제를 매우 빠르고 쉽게 처리해준다.
# (source: 컴퓨터에게 이해시킬 소스, "html.parser":어떤 코드로 이해할지 )
parsed_source = BeautifulSoup(source, "html.parser")
print(type(parsed_source))
print(type(source))
# 책 제목만 가져오기
# 파싱된코드.find_all("태그명", class_="클래스명", ed="아이디명")
# 입력시 해당 태그나 클래스에 대한 데이터만 가져올 수 있다
span_title_list = parsed_source.find_all("span", class_="prod_name")
span_title_list

# 기본적으로 .find_all()로 얻어온 태그 요소들은 0개가 잡히든
# 1개가 잡히든, 2개 이상이 잡히든 무조건 <<리스트>> 형식으로 리턴됩니다.
# 내부 자료들을 핸들링하고 싶다면, 하나하나 인덱싱 등으로 끄집어내야 합니다.
# 태크 요소 "하나"에 대해서 .text를 붙이면 태그가 제거된 문장이 나옵니다.
span_title_list[0].text
[0] + [1]
# [리스트][인덱싱] + [리스트][인덱싱]
[1][0] + [2][0]
[1,2,3][0] + [4,5,6][0]
# 이와 같이 인덱싱으로 필요한 자료를 끄집어 내는 것이다
# 반복문을 이용해서 span_title_list 내부의 태그 요소들을
# 전부 태그를 제거하고 print()로 찍어주세요
title_list = []
for title in span_title_list:
print(title.text)
title_list.append(title.text)
# span_title_list가 "리스트"이고
# 리스트 내부 요소를 하나하나 반복해서 title 에 대입해주기 때문에
# 내부 요소 하나하나가 개별적으로 작동하는 title에 .text를 걸어야 합니다.
type(span_title_list)
# 리스트는 아니지만 유사리스트이다
# 가격만 가져오기
source = driver.page_source
parsed_source = BeautifulSoup(source, "html.parser")
span_price_list = parsed_source.find_all("span", class_="val")
span_price_list
price_list = []
for price in span_price_list:
print(price.text)
price_list.append(price.text)
# 저자만 가져오기
source = driver.page_source
parsed_source = BeautifulSoup(source, "html.parser")
span_writers_list = parsed_source.find_all("span", class_="prod_author")
span_writers_list
writers_list = []
for writer in span_writers_list:
print(writer.text.split("·")[0])
writers_list.append(writer.text.split("·")[0])
# .append() 를 이용해서 가격만 20개, 저자만 20개, 제목만 20개가 든 리스트 3개를
# 만들어주세요.
print(title_list)
print(price_list)
print(writers_list)
# find_all로 가져온 태그요소에 다시 .find_all을 추가로 걸 수 있습니다.
# ex) 전체코드에서 특정 dic를 가져오라고 한 결과에 다시 -> span을 가져와codecs 라이브러리
- 파이썬 3.5버전 들어서 내장 라이브러리로 바뀜(예전에는 pip로 설치해야 했었음)
- 파이썬으로 텍스트파일을 제어할 수 있도록(읽어오기, 쓰기) 도와줌
- 콘솔창에 출력된 내용을 txt파일로 옮겨서 출력할때 사용
- 특이사항
- 개행은 \r\n으로 처리함
- mode => w(기존에 있던 자료 없애고 새 파일 입력)
- mode => a(기존에 있던 자료에 이어서 계속 입력)
- mode => r(텍스트파일에 있던 내용 읽어오기)
라이브러리 임포트
import codecs# f 변수가 텍스트파일 그 자체처럼 사용함
# .open(파일경로(파일이 존재하지 않으면 새 텍스트 파일 생성),
# encoding="인코딩방식", mode="모드")
# mode ="w"의 w는 새로쓰기이다 10번 실행해도 100번쓰이는게 아니라 10번 쓰임
# mode ="a"는 100번 쓰임
f = codecs.open("C:/Users/Playdata/Untitled Folder/test.txt", mode="w")
# .write("적을내용") 을 실행하면 텍스트파일 내부에 작성이 됩니다.
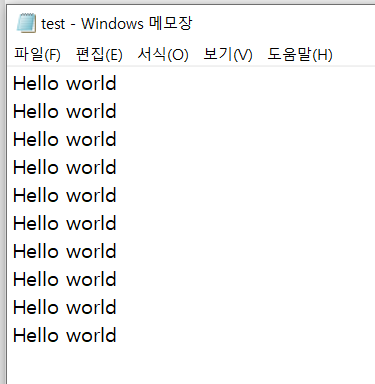
# "Hello world"를 10번 작성해주세요.
for i in range(10):
f.write("Hello world\n")
# 반드시 종료를 해주셔야 합니다
f.close()
# 기존에 작성된 텍스트자료를 읽어오기
f = codecs.open("C:/Users/Playdata/Untitled Folder/test.txt", mode="r")
# 아래 자료 읽어오는 명령어는 한 번에 하나만 실행가능
# 명령을 두 개 이상 실행시 맨 첫번째만 수행
# 줄 단위로 하나하나의 자료를 나누기
# f.readlines()
# 맨 윗줄 한 줄만 읽어오기
print(f.readline())
# 전체 데이터를 단일 문자열로 가져오기
# f.read()
# 반드시 종료를 해주셔야 합니다.
f.close()
# 오늘의 과제 : result.txt파일로 위의 교보 베스트 20개를 순위별로
# 1위 책제목, 1위 책가격, 1위 책저자
# 2위 책...
# 마지막 책제목...
# 위의 형식으로 반복문 등을 이용해서 저장해주세요.f = codecs.open("C:/Users/Playdata/Untitled Folder/result.txt", mode="w")
for i in range(20):
f.write(str(i+1)+"위 " + title_list[i]+" ")
f.write(str(i+1)+"위 " + price_list[i]+" ")
f.write(str(i+1)+"위 " + writers_list[i]+"\n")
f.close()# 저장된 result.txt의 내용을 다시 이쪽 셀에서 읽어오세요.
f = codecs.open("C:/Users/Playdata/Untitled Folder/result.txt", mode="r")
print(f.read())
f.close()

파이썬초짜의 기록