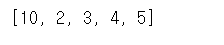
9. 리스트 복사하기
- 할당기호(=)
- copy() 메서드
- list()
- 슬라이싱
여기에선 자료구조를 알아야 한다.
자료를 저장하는 공간인 스택과 힙(stack ,heap)이 있다
스택이 용량이 작고 힙이 용량이 크다
스택에 자주쓰는 것들을 저장한다
스택에는 변수에 값 하나씩만 저장하고, 힙에다가 리스트 저장한다
(스택은 용량이 적어서 많은 데이터를 넣으면 터질 수 있다. 스택 오버플로우)
STACK :
- 속도 빠르다
- 용량 작다
- 스택에 저장된 변수에는 하나의 값만 저장 가능하다HEAP :
- 속도 느리다
- 용량 크다1. 할당기호(=)로 복사하기------->얕은 복사 shallow copy(주소값 복사됨)
a = [1, 2, 3, 4, 5]
b = a

print(a,b)
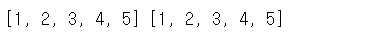
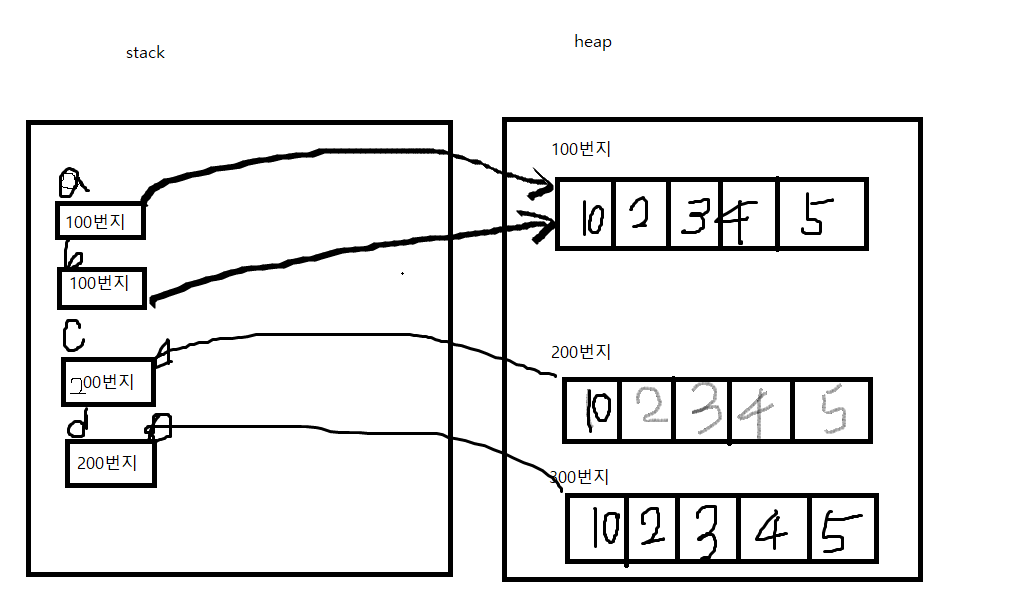
a는 [1, 2, 3, 4, 5]를 직접 들고 있는게 아니라 주소를 가지고 있다
리스트의 경우 리스트의 값들[1, 2, 3, 4, 5]은 힙에 저장되고 리스트의 주소값을 스택의 변수(a)에 할당한다
a = [1, 2, 3, 4, 5]
b = a
이렇게 하면 b에는 a에 100번지(주소값)이 할당된다, a와 b에는 주소값이 들어있다 => 이걸 얕은 복사 shallow copy라고 한다
주소를 찍고 싶다면 id(변수)를 쓰면 해당 자료가 저장된 주소를 조회할 수 있다.
print(id(a), id(b))
주소값을 보여준다. 주소값은 바꿀 수 없다
100번지로 갈 수 있는 방법이 두개(a와b) 인것
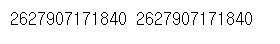
= 을 이용해 복사
a[0] = 10
100번지의 0번째 값를 10으로 바꾼다
a의 0번째 값을 바꾸고
b를 출력했는데 0번째 값이 10으로 바뀌어 출력된다.
b는 a의 주소값을 가지고 있기 때문이다.

2. copy() 매서드로 복사하기 -----> 깊은 복사
리스트가 복사되면서 c는 새로운 주소값을 얻는다
c= a.copy()
c


id를 이용해 a, b
그리고 a, c 주소를 각각 print()로 묶어서 찍어보세요
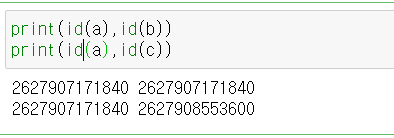
a를 변경해도 c는 영향을 받지 않는다.
a[2] = 20
print(a, b, c)

3. list() 로 복사하기 -----> 깊은 복사
list(자료)를 넣으면 그 자료를 새로 할당해 리스트화해준다.
d = list(c)

c, d도 주소가 다르다 => 깊은 복사

4. 슬라이싱으로 전체 범위 지정해 대입시---> 깊은 복사
e = d[:]
print(id(d), id(e))

<< 연습문제 >>
- a 리스트를 이용하여 다음과 같은 문자열을 출력하시오.
a = ['Life', 'is', 'too', 'short', 'you', 'need', 'python']
출력문 : you too
- a = ['Life', 'is', 'too', 'short', 'you', 'need', 'python']
print(a[4], a[2])
- a 리스트의 길이를 구하세요
- len(a)

- a 리스트의 첫번째 아이템에 길이를 추가하세요
- a.insert(0,len(a))
a

- 아래와 같이 크기 순서가 없는 리스트를 만들고 내림차순 정렬도 바꿔보세요.
- b = [1, 4, 9, 2, 6, 10]
b.sort()
b.reverse()
b

