출처 : 텐서플로와 머신러닝으로 시작하는 자연어 처리, https://wikidocs.net/31767
단어표현이란
단어 표현은 모든 자연어 처리 문제의 기본 바탕이 되는 개념이다. 기존에 컴퓨터는 텍스트를 유니코드 혹은 아스키 코드 방식으로 인식했다. 이 방법을 사용하면 텍스트를 이진화 된 값으로 인식한다. 이 경우 언어적인 특성이 전혀 없이 컴퓨터가 문자를 인식하기 위해 만들어진 값이므로 자연어 처리를 위해 만드는 모델에 적용하기에 부적합하다.
어떤 방식으로 텍스트를 표현해야 자연어 처리 모델에 적용할 수 있을까?
단어의 표현 방법은 크게 두 가지가 있다.
1. 국소 표현 (Local Representation)방법
- 이산 표현 (Discrete Representation)
- 각 단어에 숫자를 맵핑하여 단어를 표현하는 방법
2.분산 표현(Distributed Representation)방법
- 연속 표현 (Continuous Representation)
- 주변 단어로 하나의 단어를 정의.
ex.'깜찍한', '독립적인', '고양이' 라는 단어가 있을때 '고양이'라는 단어를 '깜찍한', '독립적인' 이라는 단어로 정의하는 것을 말한다.
.png)
Local Representation
여기서는 국소표현방법으로 one-hot-encoding만 다루도록 하겠다.
원-핫 인코딩
단어를 표현하는 가장 기본적인 방법은 원-핫 인코딩(one-hot encoding) 방식이다. 각 단어의 인덱스를 정한 후 각 단어의 벡터를 그 단어에 해당하는 인덱스의 값을 1로 표현하는 방식이다.
예시
(포도,딸기,수박,레몬,망고) 라는 단어를 알려야 한다고 했을 때 원-핫 인코딩 방식으로 표현하면 각 단어를 표현하는 벡터의 크기는 5가 된다.각 단어는 이 중에서 하나만 1이 된다.
포도는 [1,0,0,0,0], 딸기는 [0,1,0,0,0],수박은 [0,0,1,0,0], 레몬은 [0,0,0,1,0], 망고는 [0,0,0,0,1]으로 표현한다.
코드
토큰화된 단어들에 대해서 고유의 인덱스를 부여한다.
token = ['포도', '딸기', '수박', '레몬', '망고']
word2index={}
for voca in token:
if voca not in word2index.keys():
word2index[voca]=len(word2index)
print(word2index)결과
{'포도': 0, '딸기': 1, '수박': 2, '레몬': 3, '망고': 4}
토큰을 입력하면 해당 토큰에 대한 원-핫 벡터를 만들어내는 함수를 만든다.
def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index))
index=word2index[word]
one_hot_vector[index]=1
return one_hot_vectorone_hot_encoding("포도",word2index)결과
[1, 0, 0, 0, 0]
이 밖에도 케라스의 to_categorical()을 이용해 원-핫 인코딩을 할 수 있다. (참고 https://wikidocs.net/22647)
장점
- 방법 자체가 매우 간단하고 이해하기 쉽다.
단점
- 단어의 벡터의 크기가 매우 크고, 값이 희소(sparse)하다는 문제.
실제 자연어 처리 문제를 해결할 땐 위의 예시처럼 5개의 단어가 아니라 수십만, 수백만 개의 단어를 표현해야 한다.또한 큰 공간에 비해 실제 사용하는 값은 1이 되는 값 하나 뿐이므로 매우 비효율적이다. - 단어 벡터가 단어의 의미나 특성을 전혀 표현할 수 없다는 문제.
단순히 단어가 무엇인지만을 표현하고, 벡터값 자체에는 단어의 의미나 특성 같은 것들이 전혀 표현되지 않는다. - 각 단어간 유사성을 표현할 수 없다.
이 문제를 해결하기 위해 벡터의 크기가 작으면서도 벡터의 단어의 의미를 표현할 수 있는 방법들이 제안되었다. 이러한 방법들은 분포가설(Distributed hypothesis)을 기반으로 한다.
Continuous Representation
분포가설이란 "같은 문맥의 단어, 즉 비슷한 위치에 나오는 단어는 비슷한 의미를 가진다."라는 개념이다.
분포가설을 기반으로 하는 벡터의 크기가 작으면서도 단어의 의미를 표현할 수 있는 방법은 크게 두 가지 방법으로 나뉜다.
- 카운트 기반 (count-base) 방법 : 특정 문맥 안에서 단어들이 동시에 등장하는 횟수를 직접 세는 방법
- 예측(predictive) 방법 : 신경망 등을 통해 문맥 안의 단어들을 예측하는 방법
카운트 기반 방법
카원트 기반 방법은 기본적으로 동시 출현 행렬(Co-occurence Matrix)을 만들고 그 행렬들을 변형하는 방식을 사용한다.
여기서는 동시 출현 행렬까지만 다루도록 하겠다.
동시출현(공기, Co-occurrence) : 단어들이 동시에 등장하는 횟수
동시 출현 횟수를 하나의 행렬로 나타낸 뒤 그 행렬을 수치화해서 단어 벡터로 만드는 방법
동시 출현 행렬 (Co-occurrence Matrix)
아래의 예시문장으로 동시 출현 행렬을 만들어보자.
나의 취미는 영화 보기 입니다.
내 취미는 넷플릭스 보기이다.
나의 취미는 유튜브 보기 입니다.
| 나의 | 내 | 취미는 | 영화 | 넷플릭스 | 유튜브 | 보기 | 입니다. | 이다. | |
|---|---|---|---|---|---|---|---|---|---|
| 나의 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 내 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 취미는 | 2 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 |
| 영화 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 넷플릭스 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 유튜브 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 보기 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 2 | 1 |
| 입니다. | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 이다. | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
이렇게 만들어진 동시 출현 행렬을 토대로 특이값 분해를 하거나 단어 벡터를 만든다.
장점
- 빠르다. 적은 시간으로 단어 벡터를 만들 수 있다.
예측 방법
예측 기반 방법은 신경망 구조 혹은 어떠한 모델을 사용해 특정 문맥에서 어떤 단어가 나올지를 예측하면서 단어를 벡터로 만드는 방식이다.
- Word2vec
- NNLM (Nenural Netwrok Language Model)
- RNNLM (Recurrent Neural Netwrok Language Model)
참고 : <한국어 임베딩> 이기창
임베딩이란
벡터 공간Vector으로 + 끼워넣는다embed = Embedding
단어난 문장 각각을 벡터로 변환하는 일련의 과정 전체를 가리키는 용어이다.
임베딩이 중요한 이유는 전이학습 transfer learning 때문이다. 대규모 말뭉치 corpus를 미리 학습 pretrain한 임베딩을 모델의 입력값으로 사용하고, 모델이 task를 잘 수행할 수 있도록 업데이트 fine-tuning하는 방식을 썼을때 성능이 좋다.
임베딩의 역할
- 단어/문장 유사도 계산
- 의미적/문법적 정보 함축
- 전이학습
여기서는 Word2vec만 다루도록 하겠다.
Word2vec
Word2vec는 워드 임베딩 방법중 하나이다. 임베딩은 단어를 밀집 표현(희소 표현과 반대되는 표현)으로 변환하여 벡터화 한다. Word2vec은 CBOW(Continuous Bag of Words) 와 Skip-Gram 두가지 모델로 나뉜다.
원-핫 벡터는 단어 간 유사도를 계산할 수 없지만 Word2vec을 사용하면 단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화 할 수 있다.
희소 표현(Sparse Representation)
벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법. (각 단어간 유사성을 표현할 수 없음.)
ex. 원-핫 벡터 = 희소 벡터(sparse vector)
분산 표현(Distributed Representation)
단어의 '의미'를 다차원 공간에 벡터화하는 방법
-
분산 표현을 이용하여 단어의 유사도를 벡터화하는 작업은 워드 임베딩(embedding) 작업에 속함.
-
분포 가설을 이용하여 단어들의 셋을 학습하고, 벡터에 단어의 의미를 여러 차원에 분산하여 표현
-
저차원에 단어의 의미를 여러 차원에다가 분산하여 표현
-
단어 간 유사도를 계산 가능
CBOW vs Skip-Gram
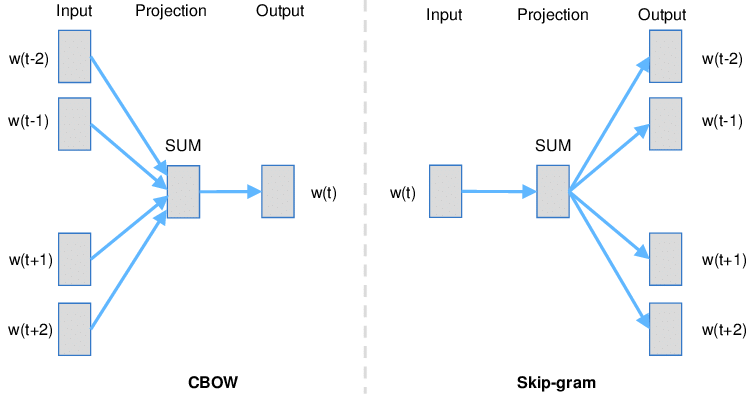
-
CBOW
: 어떤 단어를 문맥 안의 주변 단어들을 통해 예측하는 방법<고양이가
생선을 먹는다.> 라는 문장에서 주변 단어를 통해 <생선>이라는 하나의 단어를 예측하는 모델이다.학습 방법
- 입력층 : 각 주변의 단어들을 원-핫 벡터로 만들어 입력층 벡터로 사용
- N-차원 은닉층 : 가중치 행렬을 각 원-핫 벡터에 곱해 n-차원 벡터를 만든다.
- 출력층 : 만들어진 n-차원 벡터를 모두 더한 후 개수로 나누어 평균 n-차원 벡터로 만든다.
4.n-차원 벡터에 다시 가중치 행렬을 곱해서 원-핫 벡터와 같은 차원의 벡터로 만든다. - 만들어진 벡터를 실제 예측하려고 하는 단어의 원-핫 벡터와 비교해서 학습한다.
-
Skip-Gram
: 어떤 단어를 가지고 특정 문맥 안의 주변 단어들을 예측하는 방법<
고양이가생선을 먹는다.>
<생선>이라는 단어를 가지고 주변에 올 단어를 예측하는 모델이다.학습 방법
- 입력층 : 하나의 단어를 원-핫 벡터로 만들어서 입력값으로 사용
- N-차원 은닉층 : 가중치 행렬을 원-핫 벡터에 곱해서 n-차원 벡터를 만든다.
- 출력층 : n-차원 벡터에 다시 가중치 행렬을 곱해서 원-핫 벡터와 같은 차원의 벡터로 만든다.
- 만들어진 벡터를 실제 예측하려는 주변 단어들 각각의 원-핫 벡터와 비교해서 학습한다.
