The Effect of Non-Independence on Regression
Non-Independence of Observations in Regression Analysis
회귀 분석(Regression Analysis)에서 독립성(Independence of Observations) 가정이 위배되면, 추정치의 정확성(precision) 과 표준 오차(standard error) 가 영향을 받는다. 이 문제는 주어진 표본의 유효 크기를 감소시키며, 잘못된 통계적 추론을 초래할 수 있다.
1. 독립성(Independence of Observations) 가정과 그 위반
- 회귀 분석의 기본 가정 중 하나는 관측값이 독립적이어야 한다는 것이다.
- 하지만 클러스터링(clustering) 이 존재하면 이 가정이 위배된다.
- 예: 100개의 관측값이 실제로는 5명의 개체(클러스터)에서 각각 20회 반복 측정된 경우
- 이 경우, 100개의 관측값이 존재하지만, 실질적으로는 5개의 독립적인 데이터만 존재하는 것과 동일한 효과를 가짐.
Intraclass Correlation (ICC, 군내 상관)
- 클러스터 내에서 관측값들이 서로 유사할수록(intraclass correlation이 높을수록) 독립적인 정보의 양이 줄어든다.
- 즉, 첫 번째 관측값은 중요한 정보를 제공하지만, 같은 클러스터에서 추가되는 값들은 새로운 정보를 적게 제공한다.
- 극단적인 경우(ICC = 1)에는, 클러스터 내 모든 값이 동일하여, 하나의 클러스터에 대해 단 하나의 데이터만 존재하는 것과 동일한 효과를 갖는다.
2. 클러스터링이 평균 추정(Mean Estimation)에 미치는 영향
- 100개의 독립적인 관측값이 있는 경우, 표본 평균(sample mean)의 오차는 작고 정밀도가 높다.
- 하지만 클러스터링이 증가하면, unbiased, consistent 하지만 표본 평균의 오차가 커지고 정확성이 떨어짐. 데이터의 양이 적어진 것과 같은 효과를 가져오기 때문.
- 예제:
- 독립적인 표본(ICC = 0): 100개의 고유한 관측값 존재 → 정확한 추정
- 극단적인 경우(ICC = 1): 다섯 개의 클러스터에 각각 20개의 데이터가 존재한다면: 5개의 고유한 값만 존재하는 것과 같음 같은 클러스터 내의 또다른 데이터는 새로운 정보를 제공하지 않음. → 정확도가 떨어지는 추정
표본 크기의 감소
- 클러스터링이 증가하면, 표본 크기가 줄어드는 것과 같은 효과를 갖는다.
- 예:
- 위 에시처럼 100개의 강하게 클러스터된 데이터는 실질적으로 5개의 독립적인 데이터와 같은 정보량을 가짐.
- 5개의 클러스터일지라도, correlation 정도가 비교적 적을 경우, 100개의 관측값이 있지만 실제 정보량은 20개 정도에 해당할 수도 있음.
3. 클러스터링이 회귀 분석(Regression Analysis)에 미치는 영향
-
동일한 100개의 데이터를 사용하여 회귀 분석을 수행할 때, 클러스터링이 존재하면 추정치의 정확성이 낮아진다. Unbiased, consistent 하지만 less precise함.
-
예제:
-
ICC = 0 (독립적 데이터)
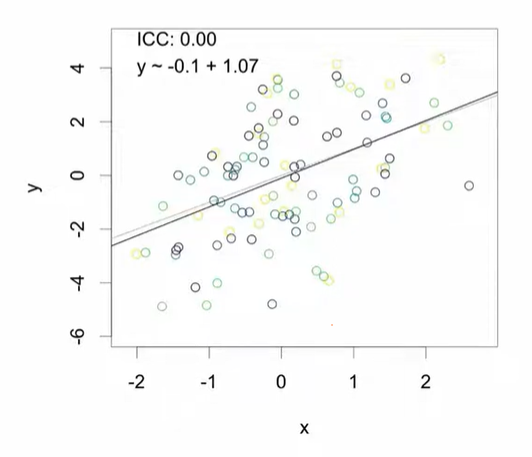
- 실제 기울기(Slope) = 1
- 추정된 기울기 = 1.07 (정확한 추정)
-
ICC 증가 (클러스터링 증가)
- 클러스터가 강해질수록, 기울기 추정의 변동성이 증가.
-
ICC = 1 (완전한 클러스터링)
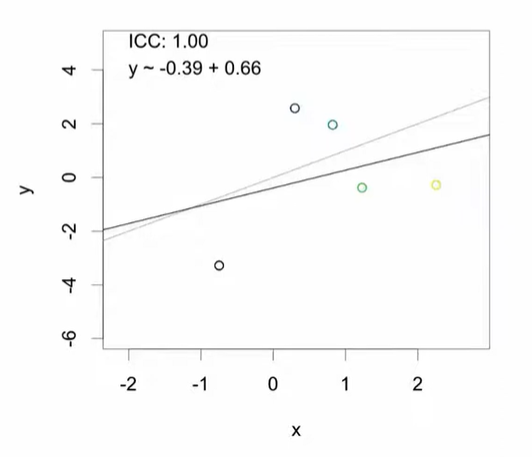
- 사실상 5개의 데이터만 존재
-
클러스터링이 회귀 분석의 유효 표본 크기에 미치는 영향
- 클러스터링이 강할수록 유효 표본 크기가 감소하여, 결과적으로 회귀 계수의 정밀성이 감소한다.
- 예:
- 100개의 클러스터된 데이터 → 실제 정보량 = 5개
- 100개의 독립적인 데이터 → 실제 정보량 = 100개
클러스터링의 유형에 따른 영향
1) X와 Y가 모두 클러스터링된 경우
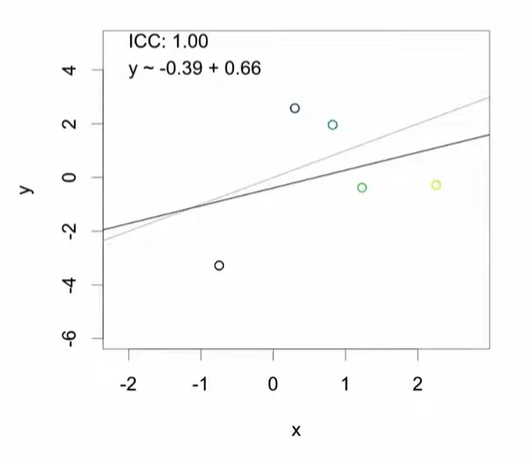
- consistent, unbiased but less precise
2) X만 클러스터링된 경우
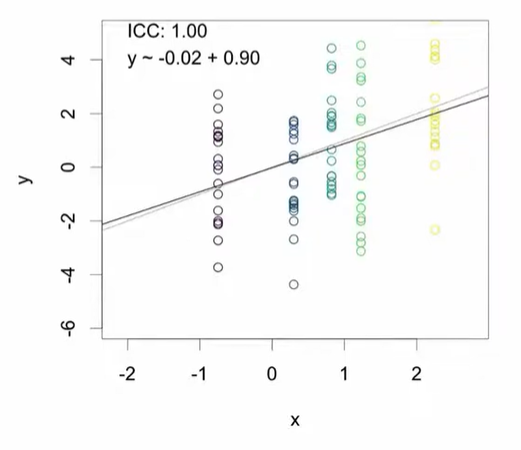
-
X는 클러스터링되었지만 Y(또는 오차항)는 독립적이면, 회귀 분석 결과에는 큰 영향이 없음.
-
다시 말해 회귀 추정치에 체계적인(systematic) 영향을 미치지 않음.
-
그 이유는 회귀 분석(Regression Analysis)이 독립 변수 에 대해 어떠한 확률적 가정을 하지 않으며, 모든 것이 관측된 값(Observed Values)을 기준으로 조건부(Conditionally) 추정되기 때문.
회귀 분석에서는 독립 변수 가 주어진 상태에서 종속 변수( 가 어떻게 변화하는지를 분석한다. 즉, 모든 추정은 주어진
𝑋값에 조건(conditioned)하여 수행된다. 이를 조건부 추정(conditional estimation) 이라고 한다.
다시 말해, 일반적인 회귀 분석에서는 "주어진
𝑋 값에서 𝑌가 어떻게 변하는가?" 에 초점을 맞춘다. -
실험적 맥락에서의 예시
- 연구자가 실험에서 특정 집단을 처리 그룹(Treatment Group) 과 대조군(Control Group) 으로 직접 할당하는 경우, 값은 연구자가 설정한 것이므로 랜덤 변수가 아님.
- 따라서, 값이 클러스터링된다고 해도 회귀 분석 결과에 체계적인 영향을 미치지 않으며, 문제를 일으키지 않음.
3) Y(오차항)만 클러스터링된 경우
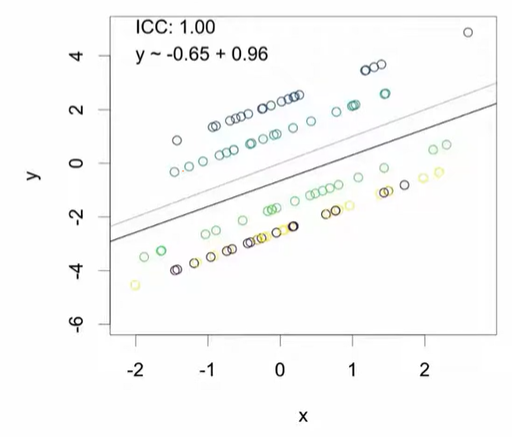
- 오차항이 클러스터링되면 회귀선의 기울기는 비교적 정확하게 추정되지만, 절편(intercept)의 추정이 부정확해짐.
- 클러스터 내에서 오차항의 변동이 거의 없으면, 절편(Intercept)을 추정하는 데에 있어서 필요한 데이터 양이 줄어드는 것과 같은 상황이 됨.
- 하지만 기울기(Slope)을 위한 데이터 양에는 변화가 없기 때문에 기울기 추정의 정확도에는 영향이 없음.
- 일반적으로 발생하는 경우: 오차항만 클러스터링되는 경우는 흔하지 않음. 일반적으로, 오차항이 클러스터링 되면, 독립 변수 𝑋도 클러스터링되는 경우가 많기 때문.
- 학교별 교육 효과 분석: 같은 학교에 속한 학생들은 비슷한 환경(오차 요인)을 공유할 가능성이 높다.
- 지역별 소득 분석: 특정 지역 내에서는 경제적 요인이 비슷하게 영향을 미칠 수 있다.
4. 클러스터링이 표준 오차(standard errors)에 미치는 영향
- 클러스터링이 존재하면, 표준 오차의 공식이 잘못된 결과를 제공할 수 있음.
- 일반적인 OLS 표준 오차 공식은 다음과 같다:
- 이 공식은 클러스터링을 고려하지 않으며, 샘플 크기가 실제보다 더 크다고 가정하는 오류를 범함.
- 결과적으로, 표준 오차가 과소 추정(underestimated)되고, 유의성 검정(p-value)이 잘못 계산될 가능성이 있음.
잘못된 표준 오차가 초래하는 문제
- 과소 추정된 표준 오차 → 신뢰구간이 너무 좁아짐
- 잘못된 p-value → 유의성이 없는 변수를 유의미하다고 잘못 판단(False Positive)
- 귀무가설(H0)이 부적절하게 기각될 가능성 증가 → 연구 오류 발생
6. 결론
- 클러스터링이 존재하면 유효 표본 크기가 감소하고, 추정치의 정확성이 낮아짐.
- 클러스터링은 편향(bias)을 유발하지 않지만, 표준 오차가 과소 추정되고 신뢰구간이 잘못 설정될 위험이 있음.
- Cluster-Robust Standard Errors를 적용하면 클러스터링의 영향을 보정하여 보다 정확한 결과를 얻을 수 있음.
- 잘못된 표준 오차 추정은 연구 오류(False Positive)를 초래할 수 있으므로, 반드시 적절한 보정 방법을 적용해야 함.
