안녕하세요! devNine 입니다.
시작
최근 메일링 서비스 를 오픈했어요! 둘러보시고 매일 올라오는 IT 기업 블로그, 유튜브 컨텐츠를 받아보세요! 이 외에도 매주 스택오버플로우의 Q&A들의 키워드를 분석해 분석 보고서를 제공하고있습니다.
동기
블로그와 유튜브, StackOverFlow 컨텐츠가 수십만개 가량 쌓였습니다. 그리고 유튜브와 블로그 컨텐츠 제공시 적용되는 페이징을 처리하는 쿼리에서
Select Count(*) from Table를 보고야 말았습니다. Spring Boot 내장 캐시를 적용해놓긴 했지만, 파라미터가 조금만 달라지면 Select Count(*)가 포함되어 쿼리가 수행되므로 이를 피하기 위해 MySQL에서의 Query Caching을 적용하려 했습니다.
하지만 MySQL 8.0부터는 deprecated되었다는 것과 생각보다 부정적인 시각이 많아 좀 더 근거를 갖고 실용적인 솔루션을 적용하고자 각 레이어에서 사용할 수 있는 캐싱들을 생각해보는 계기가 되었습니다.
서비스 특성상 자정 무렵 약 30분동안 크롤링, Insert되는 데이터 외에는 모두 Read라고 생각하셔도 무방할정도로 캐싱에 유리한 성격이라고 생각합니다. 따라서 WAS -> DB -> Browser순으로 할 수 있는 캐싱을 고려해보고 도입해볼 생각입니다.
먼저 오늘은 백엔드 어플리케이션(Spring Boot) 에서 수행할 수 있는 캐싱 방법들을을 살펴보고, 그 중에서 현재 서비스에 가장 적절한 방법을 선택할 예정입니다.
각 방법들에 대한 상세한 구현 방법들은 아주 자세하게 쓰여진 글들이 매우 많으므로 생략합니다.
많은 캐싱 관련 자료들 중 저는 토비님과 Redis 컨트리뷰터 강대명님의 토비의 봄 TV 스페셜 - 강대명 - 캐시의 모든 것 재밌게 봤습니다!
캐시 자체가 무엇인지에 대한 글또한 이미 수많은 고수분들이 써주셨습니다. 검색해보세요!
Spring Boot에서 할 수 있는 캐싱
1. Redis
Redis는 spring-data-redis로 활용할 수 있으며, 대표적인 InMemory DB입니다.
devNine이 프로젝트 단계일때도 활용했었고, 이미 구현이 완료되어있는 상태였음에도 Redis를 사용하지 않는 이유는 서비스 규모에 비해 과도한 리소스라고 생각했기 때문입니다.
레디스의 장점만 나열하자면 Key-Value 저장소, 다양한 데이터 타입, 마스터-슬레이브, 샤딩, 동기화 등.. 많은 장점이 있는만큼 알아야할 그리고 관리해야할 리소스가 굉장히 컸습니다.
리스크를 감당하기 위해 마스터-슬레이브 또는 샤딩을 구성했다면 그만큼의 인프라 비용을 감당해야하므로.. 아직까진 이렇게까지 절실할 만큼의 트래픽은 없으니 조금 더 간단한 캐싱을 구성하고 나서, 좀 더 단단한 근거와 지식 그리고 서버를 Scale Out할 정도의 트래픽을 가졌을 때, 도입하기로 결정합니다.
2. Spring Cache Abstraction(추상화)
캐싱에서 사용되는 기능들이 추상화되어있어 Spring Cache Abstraction이 지원하는 스토리지 내에서는 특정 스토리지에 종속되어 구현할 필요가 없습니다. 그렇지만 각 스토리지 라이브러리에서 구현된 구현체를 사용하는 경우도 있으니, 자세한 내용은 Docs를 확인하세요!
org.springframework.boot:spring-boot-starter-cache사실 속도 자체는 로컬 캐시가 가장 빠릅니다. Redis도 결국엔 네트워크를 거쳐야하기 때문 니다. 하지만 트래픽 규모가 큰 즉, 동일한 기능을 하는 다수의 서버가 구동될 때는 로컬 캐시가 동기화 문제로 까다로울 수 있습니다. 그 말은 단일 서버인 현재 상태에서 최적이라는 뜻이죠!
2-1. ConcurrentHashMap
자바 내 Multi-Thread 환경에서 사용할 수 있는 Map입니다. 이름부터 Concurrent해 안전한 느낌이 듭니다.
Spring-boot-starter-cache를 사용했을 때, 아무 설정을 하지 않으면(Default) ConcurrentHashMap을 통해 캐싱이됩니다.
사실 가장 쉽고 빠른 캐싱은 어플리케이션 내에서 변수로 저장하는 것이 가장 빠르니까요!
실제로 Multi-Thread 기반인 Spring-boot 내에서도 Map이 필요할 때 ConcurrentHashMap이 많이 사용됩니다.
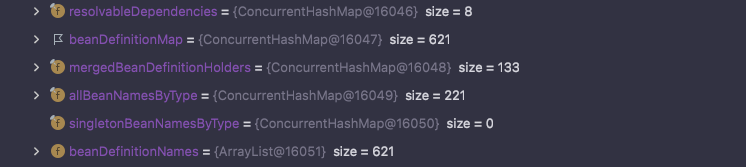
하지만, Map의 구현체이다보니 캐시 관리에서 필요한 다양한 기능들이 부족합니다..
대표적으로 TTL, TTI 등 쓰이지 않는 데이터들에 대한 관리 기법들이 구현된 Ehcache를 찾게됩니다.
(ConcurrentHashMap의 캐시 정리 자체가 불가능한 것은 아닙니다. 직접 호출하거나 구현해야 할 뿐 모두 가능합니다! )
2-2. Ehcache (https://www.ehcache.org/)
Java 기반 캐시입니다. ConcurrentHashMap과 차이점은 off-heap 을 설정할 수 있다는 것입니다.
위의 ConcurrentHashMap를 사용하면 on-heap 즉, Java 힙에 올라갑니다. 그렇게되면 ConcurrentHashMap은 힙에 올라가긴 하지만, 스스로 정리되지 않는다는 단점이 있습니다. 즉, 사용자가 직접 사용되지 않는 부분을 직접 삭제시켜주지 않는다면 메모리가 낭비될 수 있습니다.
Ehcahe는 이러한 부분을 위해 off-heap을 지원해 인메모리 처럼 RAM에 데이터를 저장 할 수 있도록 지원하고, TTL, expiry를 통해 만료기한을 설정할 수 있습니다. 하지만, RAM은 비싸고 보통 적기 때문에.. 할당을 신중하게 해주어야 합니다.
또한 Terracota라는 분산 캐시 서버를 활용하면, 여러 서버간의 동기화, Replication을 할 수 있습니다.
(참고 : https://www.nextree.co.kr/p3151/)
로컬 캐시로 사용가능하고, 이후 확장 시 코드 변경 없이 약간의 코드 추가만을 거쳐 분산 캐시도 구현해낼 수 있다는 것이 큰 장점이라고 생각했습니다. 또한 캐시마다 독립적인 세팅을 해줄 수 있고, 동일한 세팅의 경우 코드를 줄일 수 있기도 합니다.
(참고 : https://jaehun2841.github.io/2018/11/07/2018-10-03-spring-ehcache/#ehcache-%EC%84%A4%EC%A0%95-%EB%B0%A9%EB%B2%95)
3. JPA 2차캐시
스레드가 종료되면 사라지는 1차캐시와 달리 2차캐시는 상시 유지된다. 대부분의 요청은 데이터베이스를 거치기 때문에 2차 캐시를 사용하면 JPA가 더 빨라지지 않을까? 라는 생각을 했었지만, 김영한님께서 다음과 같이 말씀하신다.

결론 : 위에서 언급된 스프링 캐시를 사용하자!
마무리
저희 서비스는 결론적으로 Ehcache를 활용했습니다. 아직 off-HeapSize 설정 등에 대한 근거가 부족하긴 하지만, 여러 테스트를 통해 세부적인 설정을 적용해볼 예정입니다.
<config
xmlns:xsi='http://www.w3.org/2001/XMLSchema-instance'
xmlns='http://www.ehcache.org/v3'
xmlns:jsr107="http://www.ehcache.org/v3/jsr107"
xsi:schemaLocation="http://www.ehcache.org/v3 http://www.ehcache.org/schema/ehcache-core.xsd
http://www.ehcache.org/v3/jsr107 http://www.ehcache.org/schema/ehcache-107-ext-3.0.xsd">
<service>
<jsr107:defaults enable-management="true" enable-statistics="true"/>
</service>
<cache-template name="myDefaultTemplate">
<expiry>
<ttl unit="hours">4</ttl>
</expiry>
<resources>
<heap unit="entries">100</heap>
<offheap unit="MB">1</offheap>
</resources>
</cache-template>
<!-- 블로그 -->
<cache alias="blogContent" uses-template="myDefaultTemplate">
</cache>
</config>그리고 서비스 특성상 자정 경 데이터가 변경되고, 이것이 반드시 적용되어야 했는데 설정에 ttl, tti는 존재하지만 cron으로 특정 시간대에 캐시 삭제를 설정할수는 없었습니다. 따라서 저희는 @Secheduled를 활용해 정해진 시간에 모든 캐시를 클리어하도록 설정했습니다.
@Slf4j
@RequiredArgsConstructor
public class CachingConfig {
private final CacheManager cacheManager;
@Scheduled(cron = "0 0 2 * * *", zone = "Asia/Seoul")
public void evictAllCachesAtIntervals() {
for(String cacheNames : cacheManager.getCacheNames()){
cacheManager.getCache(cacheNames).clear();
}
log.info("[+] 모든 캐시 제거");
}
}모든 캐시를 제거하고 다시 쌓아나가는 것 자체가 많은 리소스가 필요로 되지만, 새로운 컨텐츠가 반드시 리프레시되어야 했으므로 현재는 필요한 작업이라고 생각하고 있습니다.
마지막으로 Select Count(*)은 아직 해결되지 않았습니다. 각각의 쿼리는 캐싱되지만, 캐싱 전 모든 페이지 그리고 기업 별, 유튜브 채널 별 쿼리가 달라 매번 COUNT(*)을 수행합니다. Count(*)를 분리해서 구현하고 캐싱할지 아니면 가장 처음 생각했던 해결책인 DB Query Caching를 적용할지는 좀 더 테스트해본 후 다음 편에서 소개드리겠습니다.
감사합니다.
번외
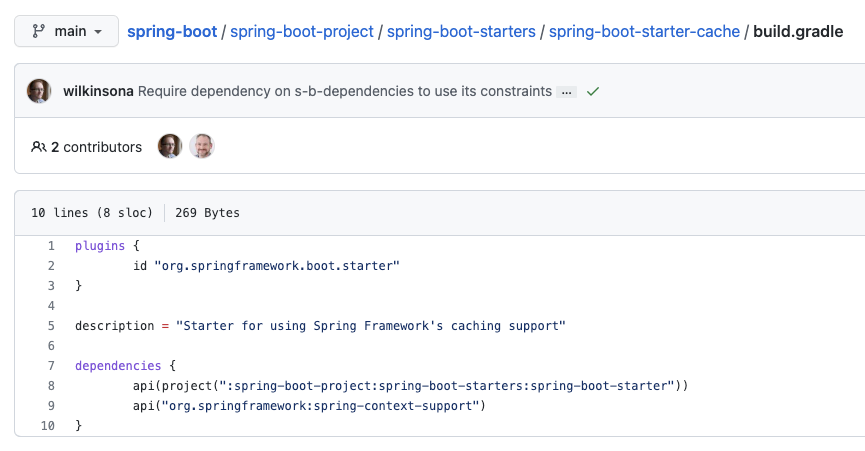
spring-boot-starter-cache는 spring-context-support에 구현된 내용들이 그대로 따라온겁니다!
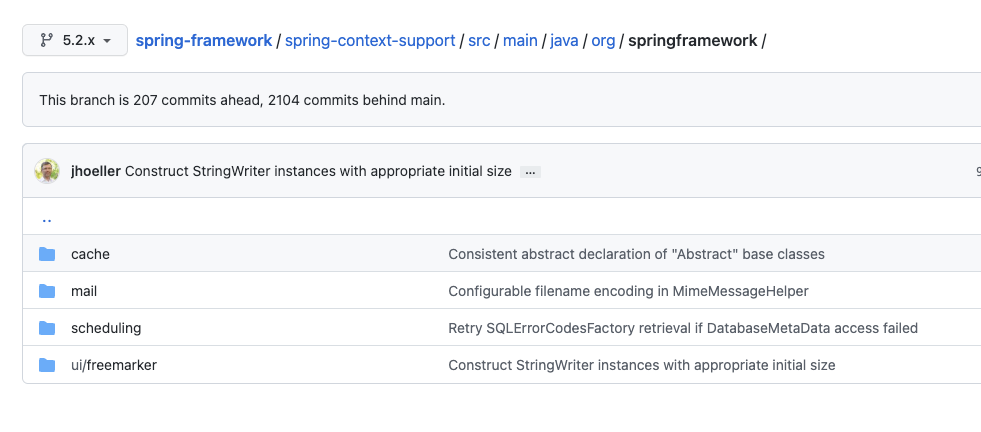
https://github.com/spring-projects/spring-framework/tree/5.2.x/spring-context-support/src/main/java/org/springframework
spring-context-support에는 위와 같이 cache 뿐만 아니라 mail, scheduling, freemarker가 함께 포함되어있습니다.'
그런데 사실, cache에 보면 ConcurrentHashMap은 찾아볼 수 없었습니다.
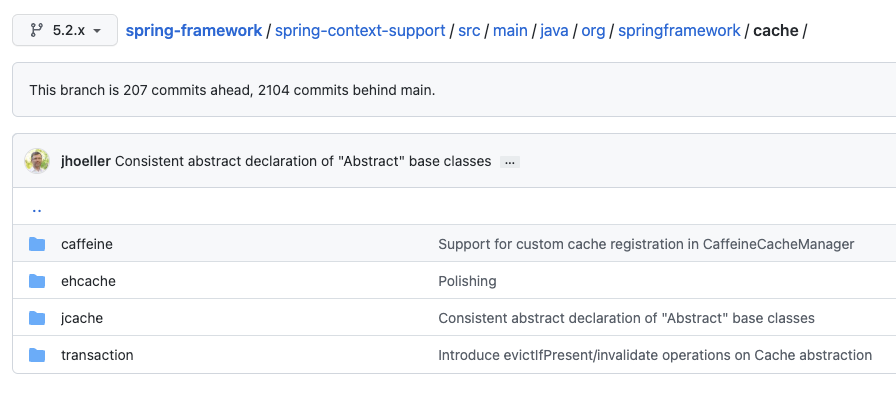
위처럼 concurrent외의 것들은 있는데.. 그래서 Intellij에서 클래스를 추적해본 결과
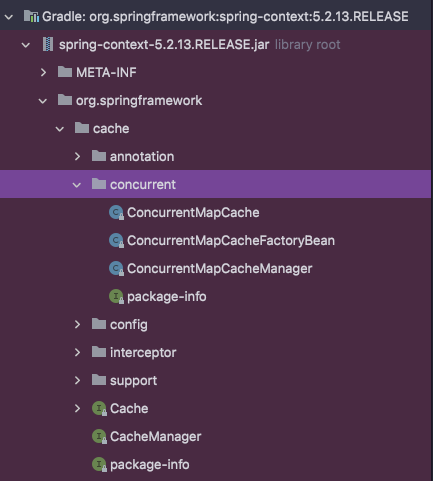
concurrent는 Spring-context에 구현되어있었습니다! 위 spring-starter-cache의 build.gradle을 보시면, spring-boot-starter도 사용하고 있습니다. 여기에 포함된 Spring-context의 ConcurrentHashMap을 사용하는 것으로 보여집니다.
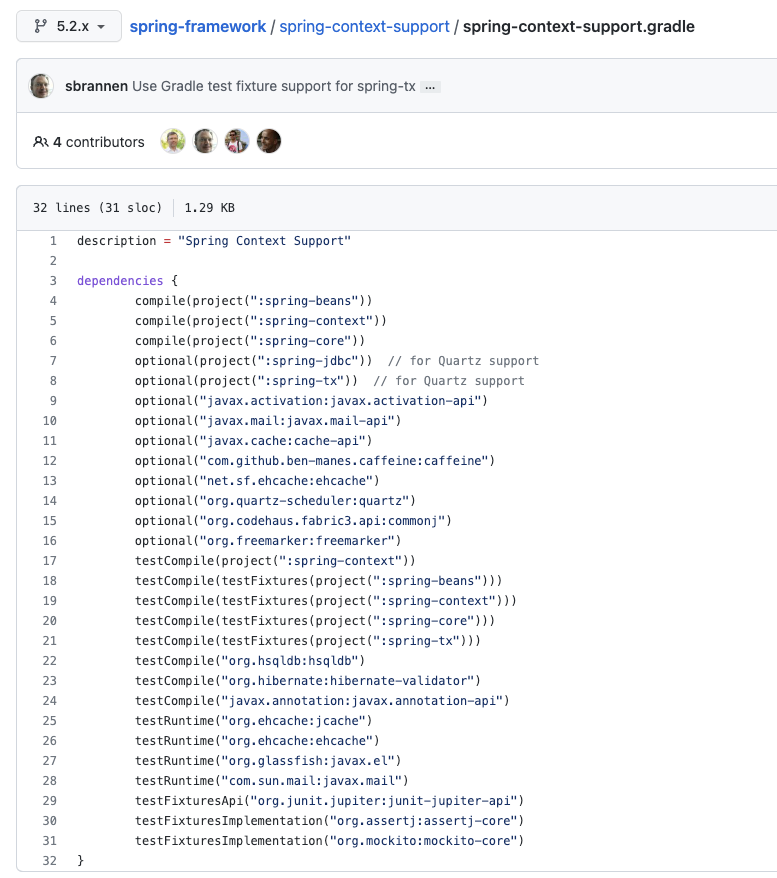
https://github.com/spring-projects/spring-framework/blob/main/spring-context-support/spring-context-support.gradle
그리고 위 spring-context-support의 gradle을 보시면, javax.cache:cache-api를 보실 수 있는데요!
이는 아까 Spring Cache Abstraction를 보신분들이라면 슬쩍 보셨을 JSR-107입니다. Spring Cache Abstraction 내에서 추상화된 기반이 JSR-107이 되었던 것을 코드로도 확인하실 수 있습니다. ( 참고 : JSR107 Git )
