
# -*- coding: utf-8 -*- %matplotlib inline import pandas as pd import numpy as np import matplotlib.pyplot as plt from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from bs4 import BeautifulSoup import re def set_chrome_driver(): chrome_options = webdriver.ChromeOptions() driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options) return driver #윈도우용 크롬 웹드라이버 실행 경로 excutabel_path = "chromedriver.exe" # 크롤링할 사이트 주소 source_url = "https://movie.naver.com/movie/sdb/rank/rmovie.naver" # 크롬 드라이버 사용 driver = webdriver.Chrome(executable_path="C:/\chromedriver.exe") # 드라이버가 브라우징 할 페이지 소스를 입력합니다. driver.get(source_url) req = driver.page_source

# 사이트의 html구조에 기반하여 데이터를 파싱합니다. soup = BeautifulSoup(req, "html.parser") contents_table = soup.select(".title .tit3 a") contents_table
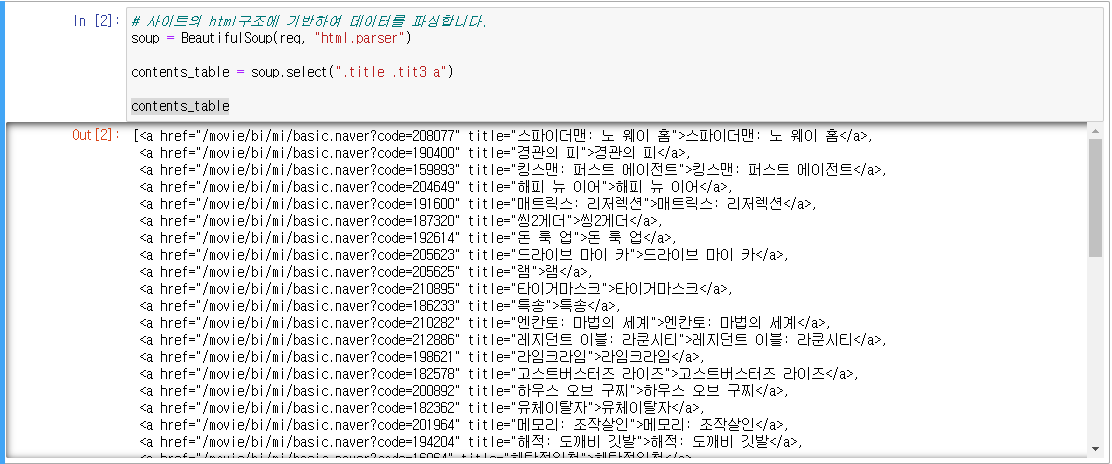
i = 0 for content in contents_table: title = content.attrs['title'] src = content.attrs['href'] i+=1 print("{}, {} => {}".format(i,title,src))
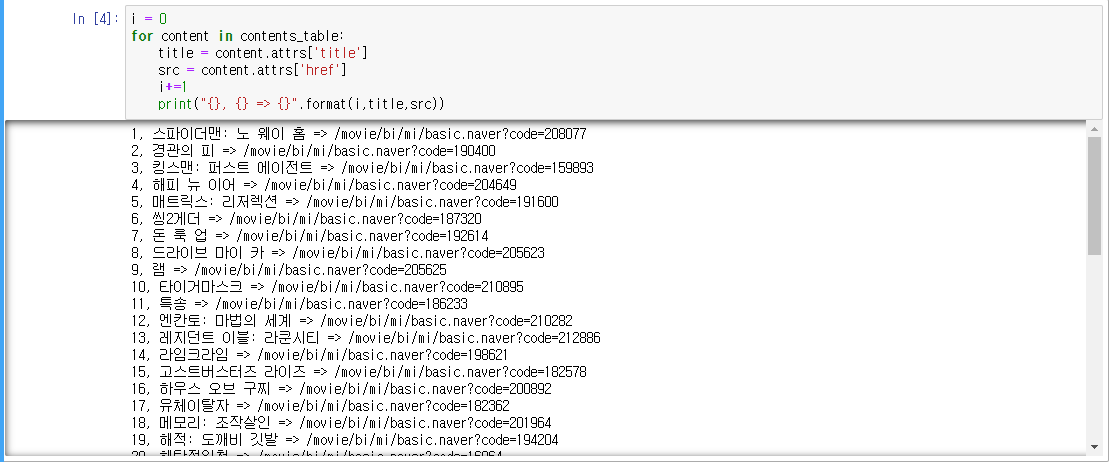

안녕하새우