0. 오프닝
위코드에서 블로그 작성을 하는데, 처음에는 기술 블로그를 벨로그에서 작성했는데 아무리 생각해도 기술 설명을 블로그로 하는게 나랑은 잘 안 맞았다. 사실 블로그에 기록하는건 그 누구보다 나를 위한 경우가 많은데(글을 쓰며 한번 더 개념 정리를 하는 것과 나중에 기억이 안 났을 때 다시 보기 위해서), 글 형식으로 설명해주는건 그냥 공식 사이트를 가면 된다. 그게 아니라 빠르게 필요한 개념과 커맨드를 가져오기 위해서는 핵심만 남겨진 포스팅이 필요한데, 그건 벨로그 보다 노션이 훨씬 효과적이고 실제로 그렇기도 해서 벨로그는 기술 정리 보다는 '글'을 쓰기로 했다.
Notion:
https://www.notion.so/d1879b3336234ed69e671649e7648c7c?v=4048311cd102465496643d293c2a38ba
프로젝트 투표를 할 때는 내가 어느 정도 알고 경험해 본 브랜드들을 선택했었다. 대부분 추천 관련된 사이트들이었는데, 막상 투표를 끝내고 생각해 보니 이커머스 사이트를 안했다는 사실을 깨달았다. 보통 누군가가 사이트를 올리는 이유는 무언가 팔기를 위해 만드는 경우가 많을텐데, "이커머스도 투표해볼걸"이라는 찰나의 생각이 결국 현실로 됐다.
1. 프로젝트 소개
T2gether - t2tea.com
1차 프로젝트로 하게된 호주 티 브랜드 사이트 T2이다. 프로젝트를 통해서 처음 알게 됐고 앞으로 호주를 가지 않는 이상 구매를 할 기회가 없을 것 같지만 그래도 이제 호주 하면 나름 떠오르는 이미지 중 하나가 됐다 :)
우리 팀은 총 프론트엔드 4명 & 백엔드 2명으로 구성됐다.
프론트 깃허브: https://github.com/wecode-bootcamp-korea/11-t2gether-frontend
백엔드 깃허브: https://github.com/wecode-bootcamp-korea/11-t2gether-backend
첫 프로젝트 미팅 때 2주 안에 구현할 수 있는 범위를 같이 정했는데, 사이트 안에 워낙 다양한 카테고리가 있어서 실제 차와 관련된 상품들만 하기로 했고, 처음 사이트에 들어와서 회원가입 - 로그인 - 차 상품 조회&검색 - 위시리스트에 추가 - 장바구니에 추가까지 하는 플로우로 결정을 하고 이에 맞는 작업들을 하기로 했다.
2. 사용된 기술
백엔드에서 사용된 기술들을 모두 나열하자면,
(초록색이 들어간 부분은 개인적으로 사용한 부분이다)
- Scrapy
- Beautiful Soup
- Python
- Django
- CORS Headers
- JWT, Bcrypt
- Git, Github
- AWS EC2, RDS
- Elasticsearch
3. 내가 맡은 역할/부분
내가 해야했던 역할 중 가장 큰 부분은 일단 상품 크롤링이었다. 상품 크롤링을 맡다 보니 자연스럽게 상품과 관련된 모델링도 하게 됐는데, 그렇게 어려울거 같지 않았던 모델링이 이어폰 꽂고 3-4시간 정도 집중한 끝에 어느 정도 끝이 났다. 만들고 나서 테이블이 너무 많아서 이게 제대로된게 맞나? 싶은 생각이 계속 들어서 빨리 피드백을 받고 싶었었다. 결국 전체 모델링한 결과가 애라와 같은데,

차와 관련해서 나눌수 있는 모든 테이블은 다 나눈거 같다. 처음 봤을 때 좀 복잡하다는 생각이 들지만 사실 필터링이라는 기능 떄문에 테이블이(오른쪽 상단쯤에 있는 노란색 비슷한) 늘어나서 그렇지, 사실 그것만 빼면 몇가지의 기능들을 합쳐주면 그렇게 많을 것도 없다. 그리고 실제로 이대로 장고에 반영하지는 않은게, 우리 팀이 구현하기로 한 범위 내에 없는 부분들도 많아서, 필터링 테이블을 몇개를 빼서 하나로 묶었고, 아래 리뷰는 안하는걸로 했고 민욱님이 하시려던 결제/오더 기능도 빠졌다.
모데링을 하고 나서는 제품과 관련된 장고 앱이 두개가 나왔는데, 제품 & 리뷰이다.
제품에서는 모든 제품에 대한 정보(위에 에이쿼리에 하늘색인 테이블들)를 크롤링해서 각 제품과 연관시켜 데이터베이스에 집어넣고, 1) 차 전체 앤드포인트, 2) 차 상세 앤드포인트, 3) 차 필터링 앤드포인트, 4), 차 검색 앤드포인트, 5) 차 리뷰 전체 앤드포인트, 6) 차 상세 앤드포인트 이렇게 만들게 됐다.
4. 잘한점 & 아쉬운 점 & 해결/개선 방법
프로젝트 시작하기 전에 scrapy를 배워뒀다는게 잘했고 또 다행이다. 물론 bs로도 전부 실행 가능한 작업들이었지만, scrapy의 가장 큰 장점 중 하나가 캐쉬가 된다는 부부인데, 한번 방문한 사이트는 스크래피 내부에서 저장이 돼서 다시 크롤링할때 여러 사이트를 방문해도 엄청난 속도로 작업을 끝낸다. URL만 알면 서드파티인 scarpy-selenium으로 동적인 사이트들까지 크롤링이 가능한데, 이것도 캐쉬가 되서 굳이 selenium으로 일일히 webdriver열고 기다리고 할 필요없는게 놀라웠다. 특히 발표 전날에 상품 대표이미지를 작은 사이즈만 크롤링을 해서 크게 보여줬을 때 깨지는 현상 때문에 하드코딩을 해야 되는 상황이 왔는데, 스크래피의 재활용성 덕분에 1-2시간 안에 다시 크롤링해서 디비에 넣고 앤드포인트에 해당 사이즈들 추가할 수 있을 수 있어서 비록 깊게는 아직 못 들어갔지만 2차에도 유용하게 쓰일 거 같다.
그리고 elasticsearch를 통해 검색기능을 구현했는데, 장고 자체적인 icontains기능이 있기는 하지만, 2020 백엔드 개발자 로드맵에 나온 검색기능 보라색 표시된 elasticsearch를 시작 전부터 해야겠다는 목표가 있었다. 이 것도 프로젝트 전에 한번 해봐야겠다고 주말에 나와서 해봤는데, 설치를 하고 9200 포트에서 반응이 오기까지 하루가 걸렸다. Elasticsearch 장점이 NoSQL이기 때문에 모든 관계를 한 필드(sql로 치면 칼럼)에 저장한다는 장점이 있는데, 자연스럽게 아쉬운 점으로 넘어간다면 막판 필터링 기능 때문에 애를 먹어서 결국 차와 관련된 관계들을 저장하지는 못하고 이름만 저장했다. 따라서 결국 차의 다른 정보들을 보여주기 위해서는 기본 mysql 디비를 어쩔 수 없이 히트할 수 밖에 없어서 시간이 엄청나게 단축되지는 않았던게 아쉽다. 하지만 테스트한 결과 이름만 보여준다고 했을 때도 elasticsearch가 3배 가량 빠른 속도를 보여준건 좀 놀라웠다.
또 다른 아쉬운 점은 필터링 기능인데, 처음 모델링할 때 너무 많다고 생각했던 테이블들을 줄인 것이 결국 상황을 더 복잡하게 만들었다. 지금까지도 테이블을 묶은게 잘한 것일까 나눈게 잘한 것일까 고민이 되는데, 이건 실제 서비스에서 어떤 기능을 원하는지가 중요한거 같다. 물론 항상 정잡이 없지는 않다. 묶어도 되는데 나누면 잘못된 거고, 나눠야 하는데 묶으면 잘못된 모델링이다. 하지만 두개 다 가능한 경우에는 어떤 서비스를 생각하고 있는지가 굉장히 중요해진다.
5. 기록하고 싶은 코드/함수/로직
테이블이 하나로 묶여 있어서 나에게 가장 힘든 시간을 준 필터링 기능,
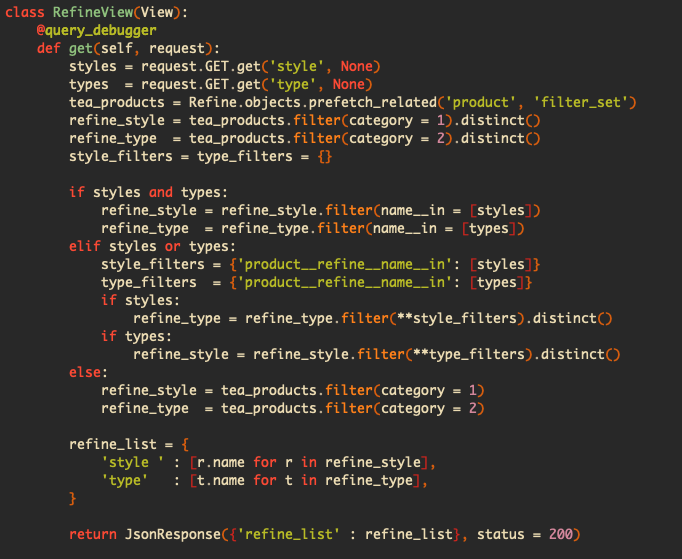
기록하고 싶은 이유는 만약에 나중에 실력이 더 늘어서 이 코드를 보고 어떻게 하면 더 빠르게 잘 접근할 수 있을 지 궁금해서이다. 나는 지금 Refine이라는 테이블에 여러개의 필터링 기준들을 넣어놨고(loose leaf tea, black breakfast tea, chinese green tea...)그 기준들은 각자 하나의 카테고리에 속하는데, 이 카테고리를 여러개의 테이블로 안 나누고 Refine안에 category라는 칼럼에 넣어놓은 상태이다.
그런데 사이트에서 1번 카테고리에 속한 필터링 기준을 하나 클릭하면, 1번 카테고리의 필터링 기준들은 남겨 놓는 대신 2번 카테고리 기준들 중에 클릭한 1번 기준에도 속하는 기준들을 남겨놔야 한다(교집합). 여기서 문제는 클릭한 기준, 예를 들어 loose leaf tea(1번 카테고리)에 해당하는 제품들이 2번 카테고리 어떤 기준들에 들어가는지 알려면 제품을 거쳐서 갖고와야 한다. 그 이유는 장고는 self inner join이 안되기 때문이다.
6. 엔딩
프로젝트 하기 전에는 과연 난이도가 어느 정도일까 궁금했다. 2주가 지난 지금, 기본적인 난이도 설정은 있지만 그 외에 내가 추가로 하는 거에 따라서 달라지기도 한다. Redis까지 추가를 하고 싶었었고 하루만 있었으면 했을텐데 공휴일 때문에 하루 쉰게 아쉽다. 그리고 Logging과 Query_Debugger를 통해 백엔드에게 필수적인 데이터 응답 시간 단축 & ORM에 가려진 SQL문법 익숙해지는 시간을 가진게 정말 좋았고, 가장 좋았던 점은 이제 공식 문서에 대한 거부감이 많이 사라졌다. 구글 검색에서 나오는 미디엄, 유튜브, 스택오버플로우등 다양한 사이트에 올라온 글들이 도움이 많이 되지만, 무언가 새로운 걸 시도할 때는 공식 문서만한게 없다. 이제 다음주 월요일 부터는 2차가 시작되는데, 사회적 거리두기 2.5단계 때문에 첫주는 온라인으로 진행을 해야 한다. 많은 답답함이 예상되기는 하지만 한편으로 학원 가는 시간 세이브가 되고 또 개발이라는 직군이 재택근무가 많을 수 있기 때문에 좋은 경험이 될거 같다. 혼자 있어서 좀 나태해질 수도 있지만, 상황에 연연하지 않고 목표를 좀 더 높게 잡아서 잘 마무리하고 마지막 한달을 보낼 수 있기를 :)
