
Project Reactor📝
Project Reactor는 Spring Reactive Web Application의 개발에 있어 핵심적인 역할을 한다.
Reactor
리액티브 스트림즈 표준 사양을 구현한 구현제 중 하나로, 리액티브 프로그래밍을 위한 라이브러리이다.
Reactor의 특징
Non-Blocking
Blocking의 개념은 함수를 호출하고 결과를 기다리는 동안 현재 스레드를 정지시켜, 결과 값을 받을 때 까지 아무것도 하지 않는 상태이다. Non-Blocking는 그 반대의 개념으로 요청 스레드가 차단되지 않고 결과 값을 기다리는 상태에도 다른 작업을 수행할 수 있다.
Publisher 타입 - Mono와 Flux
Reactor는 두가지의 Publisher 타입을 제공한다.
1. Mono[0][1] : 0건 또는 1건의 데이터를 emit할 수 있는 타입
2. Flux[N] : N건(0건 포함)의 데이터를 emit할 수 있는 타입
Backpressure
Publisher가 Subscriber에 데이터를 emit하는 속도에 비해 Subscriber가 데이터를 처리하는 속도가 느리면 처리되지 않은 데이터들이 쌓이거나 오버플로우가 발생하고 더 나아가 시스템이 다운되는 일이 발생한다.
이런 점들을 제어하기 위한 전략이 Backpressure이다.
Backpressure는 데이터를 적절하게 제어해 과부하가 발생하지 않도록 예방한다.
Reactor의 구성 요소
리액트 프로그래밍 기본 구조
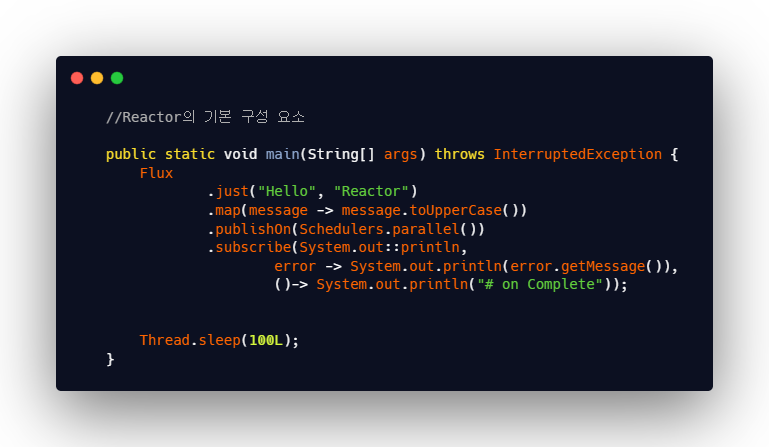
Reactor의 기본 구성 요소
-
just(): 원본 데이터 소스로부터 데이터를emit하는 Publisher 역할의 오퍼레이터 -
map():emit한 데이터를 전달 받아 가공하는 오퍼레이터 -
⭐
publishOn(Schedulers.parallel()):Reactor Sequence에서 쓰레드 관리자 역할을 하는 Scheduler를 지정하는 오퍼레이터.
Scheduler를 지정하면 해당 오퍼레이터 기준으로 Downstream의 스레드가 Scheduler에서 지정한 유형의 스레드로 변경된다. -
⭐
subscribe(): 3개의 람다 표현식을 가지고 있다.System.out::println: 전달 받은 데이터를 처리하는 표현식error -> System.out.println(error.getMessage(): 에러 발생 시, 해당 에러를 받아 처리하는 표현식()-> System.out.println("# on Complete"):Reactor Sequence가 정상적으로 종료된 후에 행할 표현식
-
Thread.sleep(100L) : Scheduler에서 지정한 스레드는 데몬 스레드이기 때문에 주 스레드인 main 스레드가 종료되면 동시에 종료된다. 따라서 main 스레드를 해당 코드로 일정 시간 동안 지연시켜 그 사이에 Scheduler에서 지정한 데몬 스레드를 통해
Reactor Sequence가 정상 동작하게 된다.
🧐 데몬 스레드
일반 스레드(LIKEmain 스레드)의 작업을 돕는 보조적인 역할을 수행하는 스레드.
보조 역할의 스레드이기 때문에 메인 스레드가 종료되면 데몬 스레드는 존재의 의미가 없어 같이 종료된다.
마블 다이어그램(Marble Diagram)
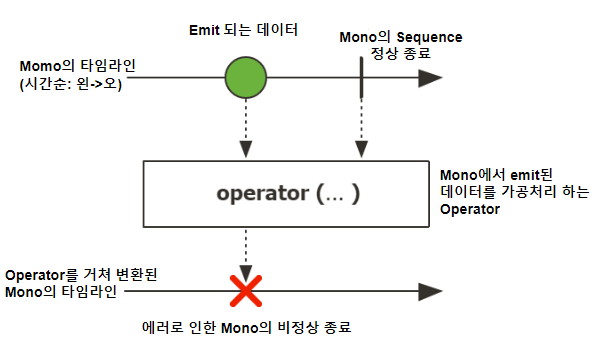
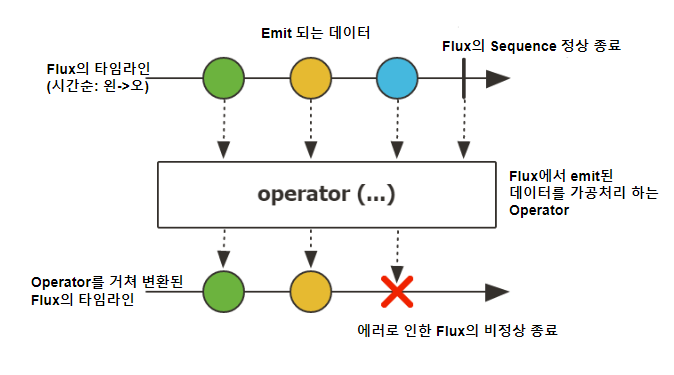
마블(Marble) = "구슬", 하나의 데이터를 의미한다.
마블 다이어그램은 이 하나의 구슬, 하나의 데이터가 시간의 흐름에 따라 변화하는 데이터의 흐름을 표현한 것이다.
🕒시간의 흐름은 왼쪽에서 오른쪽으로 흐른다.
Mono
0건 또는 1건의 데이터만 emit하는 Reactor 타입
Flux
여러 개(0 … N)의 데이터를 emit하는 Reactor 타입
Operater
공식 문서Reactor Docs에 나와 있는 수많은 Operator의 마블 다이어그램을 보면서 동작 방식 이해하기
스케줄러(Scheduler)
스레드를 관리하는 관리자의 역할!!
Reactor Sequence 상에서 처리되는 동작들을 하나 이상의 스레드에서 동작하도록 별도의 스레드를 제공해주는 역할을 한다.
⭐Non-Blocking 통신을 위한 비동기 프로그래밍을 위해 Scheduler는 중요한 역할을 한다.
별도의 스레드를 생성해 멀티 스레딩 프로세스를 구성하려면 아주 복잡한 로직을 거쳐 구현해야 하며, 구현하면서 수많은 문제점이 발생할 수 있다. 이 일을 Scheduler가 대신하면서 복잡한 처리를 할 필요가 없고 손쉽게 구현할 수 있게 된다.
Scheduler 전용 Operator
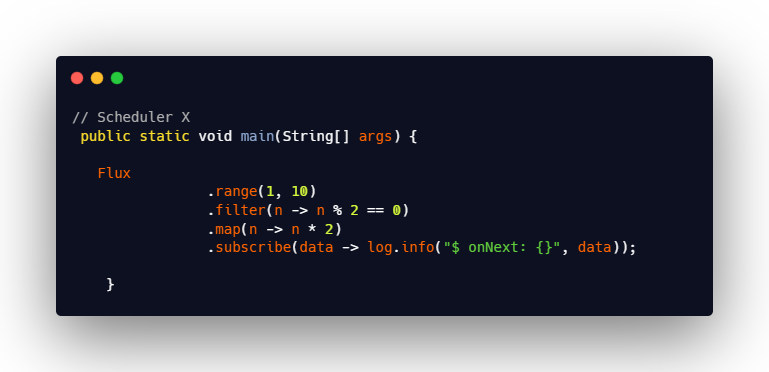
Scheduler를 추가하지 않은 Sequence는 모두 Main 스레드에서 실행된다.
⭐구독 직후에 원본 데이터를 생성하고, 생성한 데이터를 emit하는 작업이 제일 우선적으로 실행된다는 것을 잊지말자!
subscribeOn() Operator
⭐ 주로 Schedulers.boundedElastic() 사용한다.
subscribeOn()는 데이터 소스에서 데이터를 emit하는 원본 Publisher의 실행 스레드를 지정하는 역할을 한다.
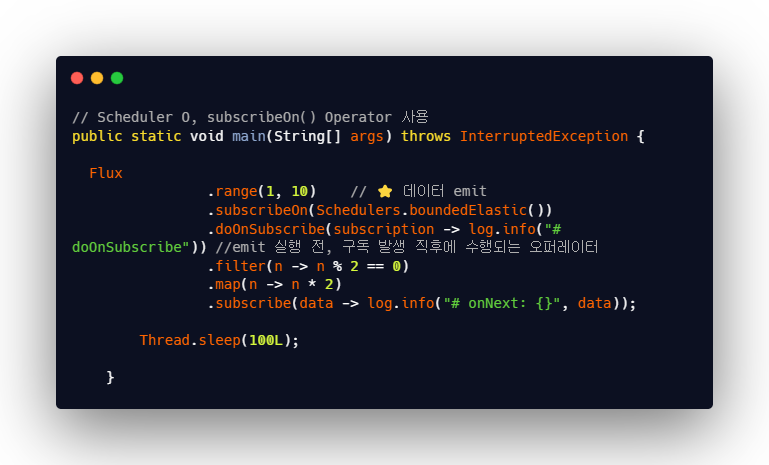
- doOnSubscribe() : 구독 발생 직후에 실행되는 Operator로, 구독 발생 직후에 어떤 동작을 수행할 것인지를 정한다. -> ⭐쓰레드 변경 직전에 먼저 실행됨
- subscribeOn() : 구독 직후에 실행되는 Operator 체인의 실행 쓰레드를 파라미터인 Scheduler가 지정한 쓰레드로 변경된다.
publishOn() Operator
⭐ 주로 Schedulers.parallel() 사용한다.
publishOn()는 전달 받은 데이터를 가공 처리하는 Operator 앞에 추가해 가공 처리들을 별도의 실행 스레드를 지정하는 역할을 한다.
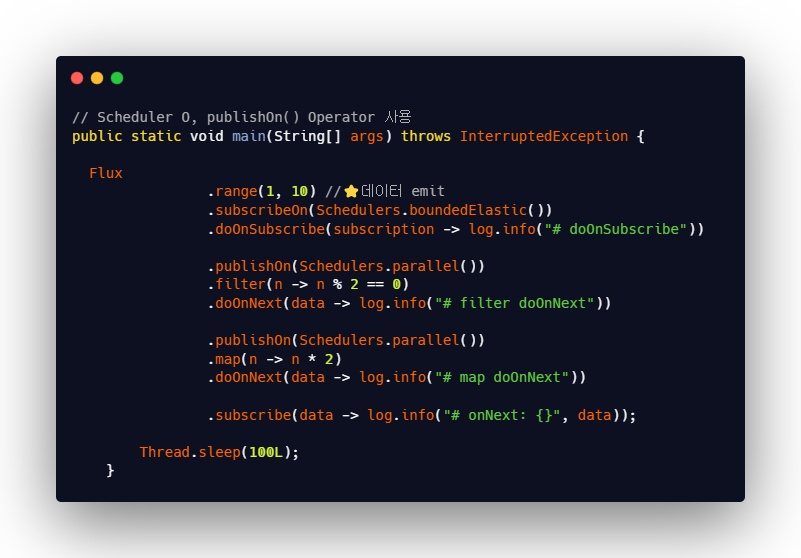
- publishOn() : publishOn()을 기준으로 Downstream 스레드가 publishOn()에서 Scheduler가 지정한 스레드로 변경된다.
🧐
subscribeOn()와publishOn()의 차이
subscribeOn()는 여러번 추가하더라도 하나의 스레드만 추가 생성되고publishOn()는 여러번 추가하면 추가한 만큼 별도의 스레드가 추가 생성된다.
