
해당 시리즈는 김영한님의 JPA 로드맵을 따라 학습하면서 내용을 정리하는 글입니다
데이터 베이스 방언
-
JPA는 특정 데이터베이스에 종속되지 않습니다 -
각각의 데이터베이스가 제공하는 SQL 문법과 함수는 조금씩 다른다는 문제가 생기게 되겠죠
- 가변 문자:
MySQL은VARCHAR,Oracle은VARCHAR2 - 문자열을 자르는 함수: SQL 표준은
SUBSTRING(),Oracle은SUBSTR() - 페이징:
MySQL은LIMIT,Oracle은ROWNUM
- 가변 문자:
-
방언: SQL 표준을 지키지 않는 특정 데이터베이스만의 고유한 기능
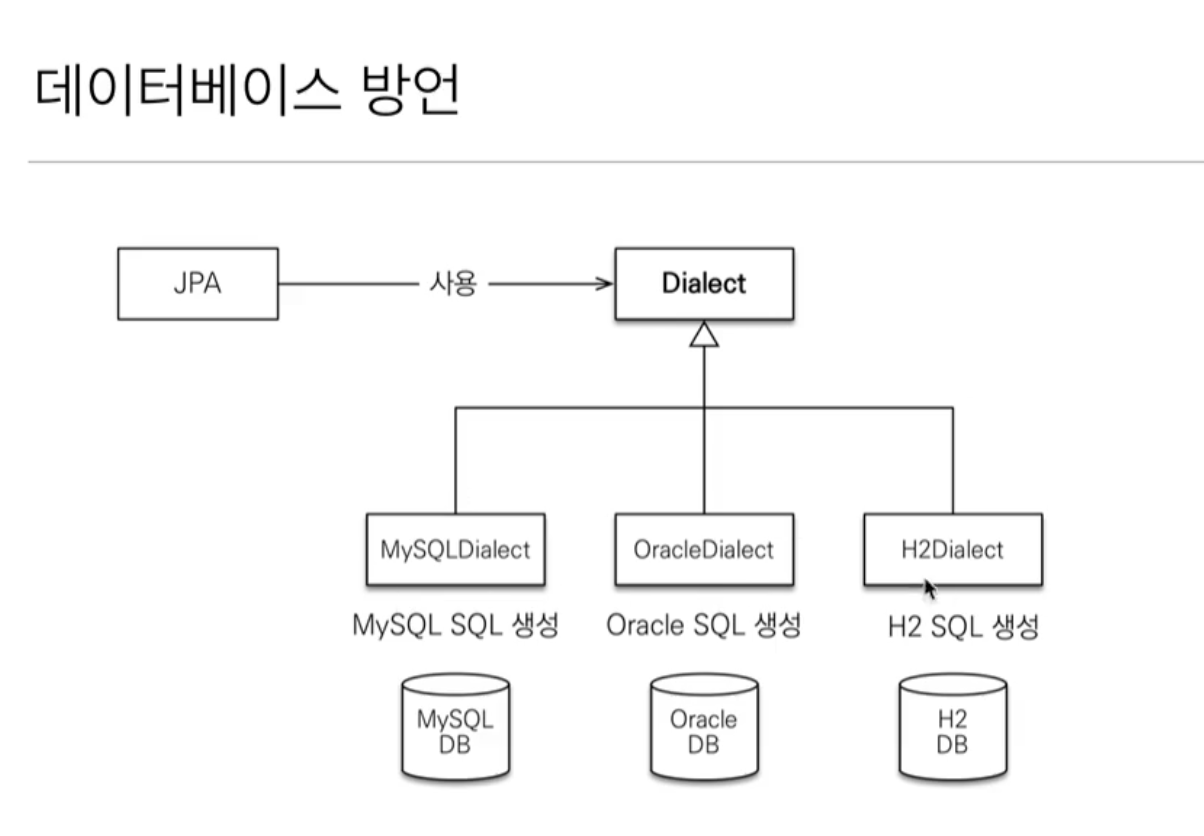
-
hibernate.dialect속성에 지정해서 사용합니다- H2: org.hibernate.dialect.H2Dialect
- Oracle 10g: org.hibernate.dialect.Oracle10gDielect
- MySQL: org.hibernate.dialect.MySQL5InnoDBDialect
-
하이버네이트는 40가지 이상의 데이터베이스 방언을 지원합니다(실무에서 사용되는 DB는 거의 지원된다고 생각하면 됩니다)
JPA 구동방식
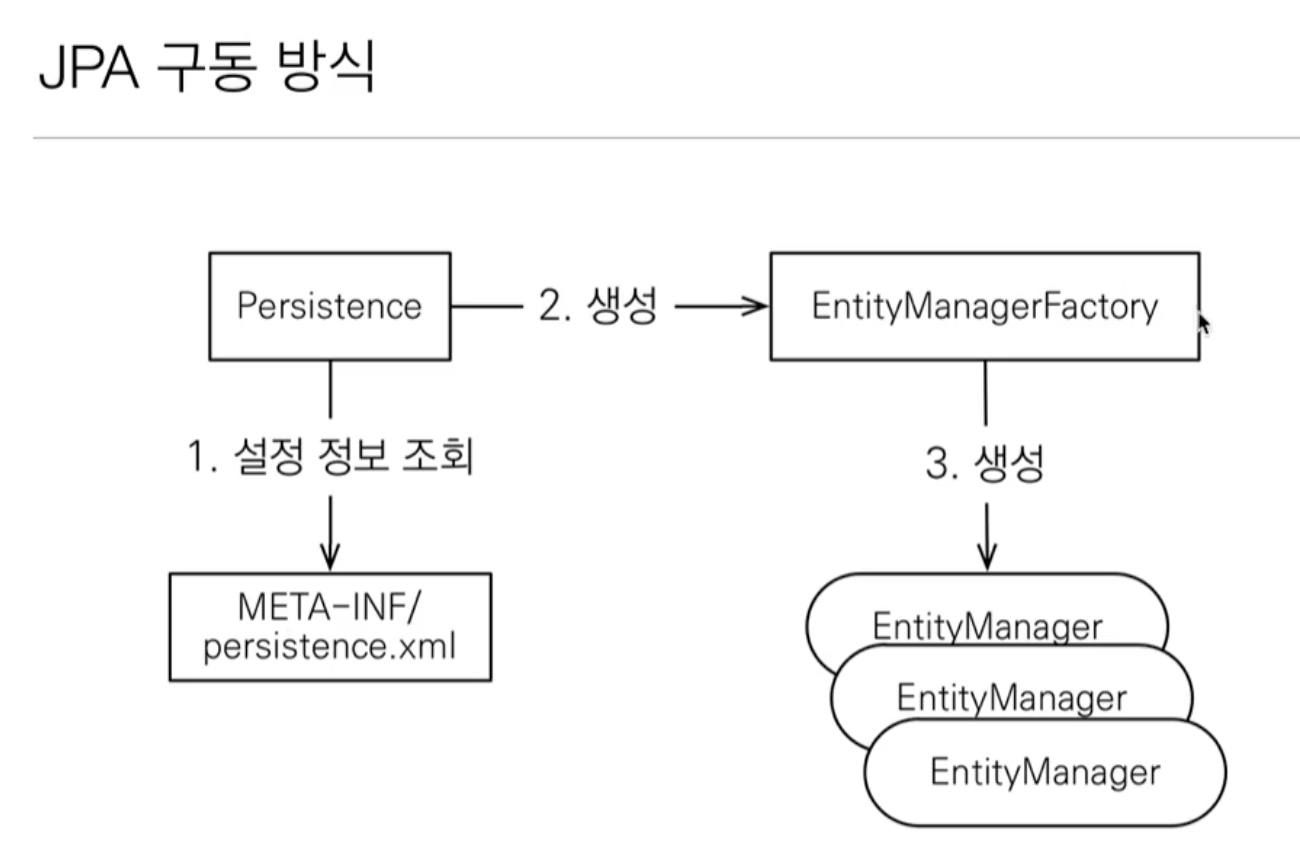
Persistence라는 클래스에서 설정 정보를 읽어서EntityManagerFactory라는 클래스를 생성합니다EntityManagerFactory에서 생성한EntityManager를 사용하게 됩니다EntityManagerFactory는 어플리케이션이 구동되는 시점에 한번만 생성되지만,EntityManager는 고객의 요청이 올 때마다 생성됩니다- 주의할 점은
EntityManager는 쓰레드간의 공유를 하면 안됩니다!! - JPA의 모든 데이터 변경은 트랜잭션 안에서 실행되어야 합니다
객체와 테이블을 생성하고 매핑하기
@Entity:JPA가 관리할 객체@Id: 데이터베이스PK와 매핑
JPA update query
JPA를 통해서Entity를 가져오면 해당Entity는JPA가 관리합니다JPA는 트랜잭션을 커밋하는 시점에 변경점이 있는지 확인합니다- 변경점이 발견되면 커밋하기 직전에
JPA가 업데이트 쿼리를 작성해주고 커밋을 날리게 됩니다 - 따라서 우리는 객체를 변경한 후에 따로 업데이트 쿼리를 작성할 필요가 없습니다
JPQL이란
- 테이블이 아닌 객체를 대상으로 검색하는 객체 지향 쿼리
SQL을 추상화해서 특정 데이터베이스SQL에 의존하지 않습니다JPQL을 한마디로 정의하면 객체 지향SQL
기존 JPA만으론?
- 기존 JPA만 가지고 단순한 조회 방법
EntityManager.find()- 객체 그래프 탐색(
a.getB().getC())
- 조건이 붙은 경우라면?
- ex) 나이가 18살 이상인 회원을 모두 검색하고 싶은 경우
JPQL 사용법
- 전체 조회를 할 경우
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
List<Member> result = em.createQuery("select m from Member as m", Member.class)
.getResultList();
- 사용하는 이점이 무엇일까?
- 예를 들면
Pagination에서 이점을 볼 수 있습니다
List<Member> result = em.createQuery("select m from Member as m", Member.class) .setFirstResult(1) .setMaxResults(10) .getResultList();- 위와 같은
JPQL을 작성했을 때,DB에 날아가는 쿼리문은
Hibernate: /* select m from Member as m */ select member0_.id as id1_0_, member0_.name as name2_0_ from Member member0_ limit ? offset ?- 이런식으로
limit와offset이 작성되어 날아갑니다 DB마다 페이징 처리하는 방법은 다르기 때문에JPQL이 없이 우리가 직접 페이징 처리를 하려면 그 많은 데이터베이스 방언을 외워야 하겠지만JPQL을 사용하면 신경쓰지 않아도 됩니다
- 예를 들면
JPQL 이점
JPA를 사용하면 엔티티 객체를 중심으로 개발하게 됩니다- 문제는 검색 쿼리가 되게 됩니다(수많은
JOIN등) - 검색을 할 때도 테이블이 아닌 엔티티 객체를 대상으로 검색을 하고 싶어집니다
- 모든
DB데이터를 객체로 변환해서 검색하는 것은 불가능합니다 - 애플리케이션이 필요한 데이터만
DB에서 불러오려면 결국 검색 조건이 포함된SQL이 필요합니다
JPQL 기능
JPA는SQL을 추상화한JPQL이라는 객체 지향 쿼리 언어를 제공합니다SQL과 문법이 유사하고,SELECT,FROM,WHERE,GROUP BY,HAVING,JOIN을 지원합니다JPQL은 엔티티 객체를 대상으로 쿼리,SQL은 데이터베이스 테이블을 대상으로 쿼리를 한다는 차이가 있습니다

Always be happy 😀