
김영한 님의 스프링 DB 2편 - 데이터 접근 활용 기술 강의를 보고 작성한 내용입니다.
https://www.inflearn.com/course/%EC%8A%A4%ED%94%84%EB%A7%81-db-2/dashboard
1. SQL 중심 개발의 문제점
1-1. 객체와 관계형 DB
- 어플리케이션은 객체 지향 언어를 사용하고 데이터베이스는 주로 관계형 DB 를 사용하는데 객체를 관계형 DB에 관리할 때 여러 문제가 발생한다
-
관계형 DB 는 SQL 만 알아들을 수 있다 ➜ SQL 중심 개발이 발생 ➜ 반복적인 코드 작성
-
객체를 SQL로 변환하는 것을 개발자가 직접 한다 : 객체 ➜ SQL 변환 ➜ 관계형 DB
-
JdbcTemplate이나 MyBatis는 개발자가 SQL을 직접 작성하기 때문에 객체에 필드가 추가되면 직접 모든 SQL에 추가해주어야함
1-2. 객체와 관계형 DB의 차이
1-2-1. 상속
-
객체에서는 상속이 있는데 관계형 DB에는 상속 관계가 존재하지 않고 슈퍼-서브타입이 객체의 상속과 유사
-
but> 상속 관계에 있는 객체를 저장하기 위해 관계형 DB의 슈퍼타입, 서브타입에 각각 저장 해야한다
-
즉, 슈퍼 타입에 저장하는 쿼리와 서브 타입에 저장하는 쿼리 총 2개가 필요
-
조회를 하는 경우에도, 슈퍼 타입과 서브 타입을 join 하고 각각의 객체를 생성하는 등 복잡한 과정을 거쳐야함
1-2-2. 연관관계
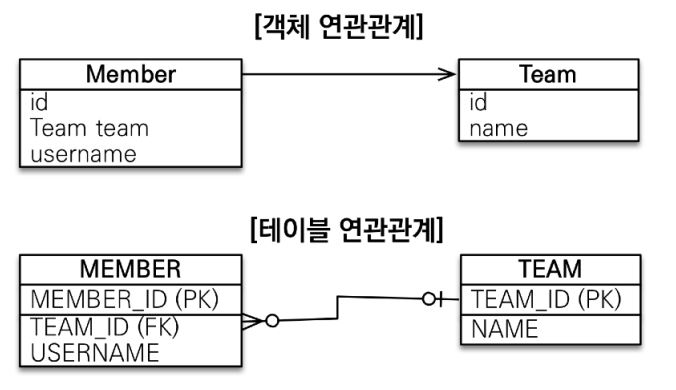
-
객체는 참조를 사용하고 테이블은 외래키를 사용한다
-
연관 관계의 객체를 조회하려면 테이블을 join 해야한다
-
편하게 저장하기 위해 객체를 테이블에 맞추어 모델링할 수 있다
- ex> Member에 외래키를 위해 Team이 아닌 Long 타입을 사용
-
but> 객체다운 방법은 아님
1-2-3. 엔티티 신뢰 문제

-
객체는 대부분의 상황에서 자유롭게 객체 그래프를 탐색할 수 있어야한다
-
but> 처음 실행하는 SQL에 따라 탐색 범위가 결정된다
- ex> Member에서 Team과 Order를 조회할 수 있어야하는데 SQL에서 Order에 관한 부분이 없으면 Order를 조회할 수 없다
-
즉, 조회하려는 정보가 객체에 있는지 없는지 알 수 없고 이를 알려면 어떤 SQL이 실행되는지 직접 확인해야한다
-
연관된 모든 객체를 미리 로딩하려면 불필요한 join이 발생
-
상황에 따라 Member와 Team을 조회하는 메서드, Member와 Team과 Order를 조회하는 메서드처럼 여러 개 생성하는 것도 비현실적
➡️JPA는 위의 문제들을 모두 해결해준다
2. JPA 소개
2-1. JPA
-
Java Persistence API
-
자바 진영의 ORM 기술 표준
-
JPA 는 인터페이스의 모음이며 3가지 구현체가 존재
- Hibernate, EclipseLink, DataNucleus
2-2. ORM
-
ORM( Object-Relational Mapping ) : 객체 관계 매핑
-
객체는 객체대로, 관계형 DB는 관계형 DB대로 설계
-
ORM 프레임워크가 객체와 관계형 DB 중간에서 매핑
2-3. JPA 동작
2-3-1. 흐름
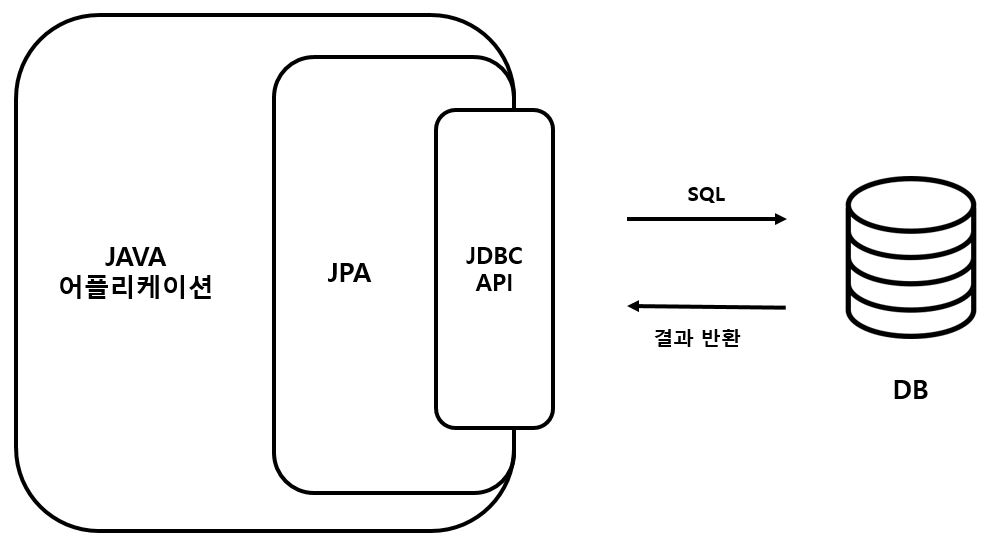
-
JPA 는 어플리케이션과 JDBC 사이에서 동작
-
어플리케이션에서 JDBC 를 직접 사용하는 것이 아니라 JPA 를 사용하면 JPA가 내부에서 JDBC API를 사용
2-3-2. 저장
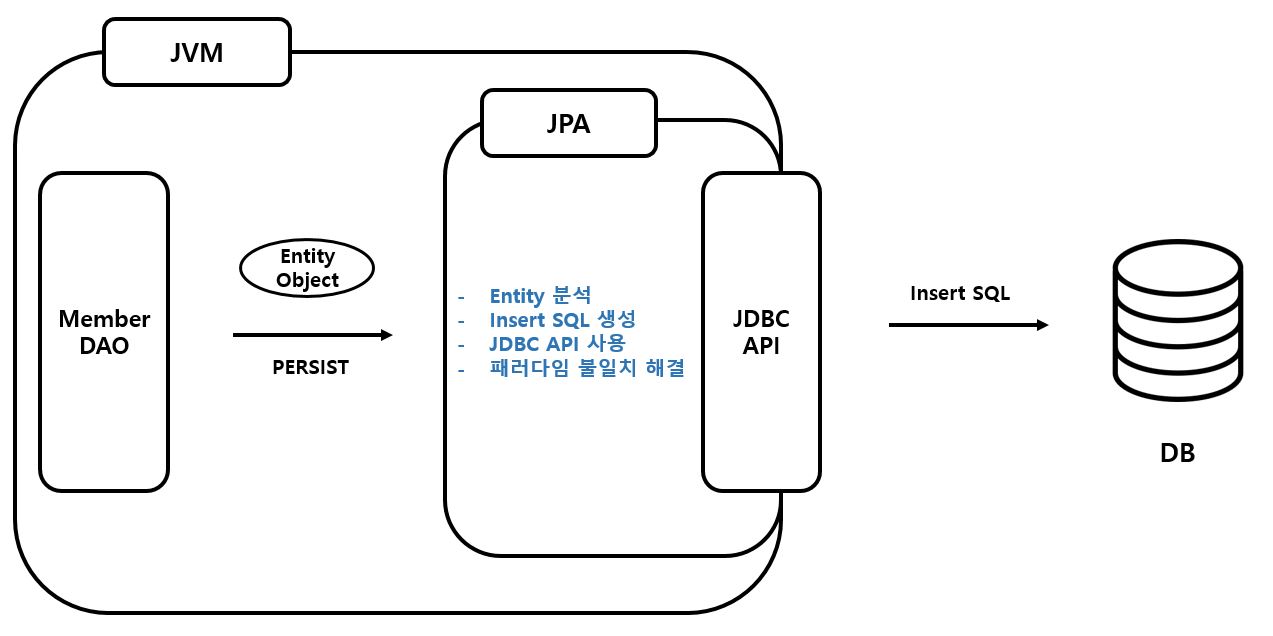
- JPA 에 객체를 넘겨주면 JPA가 위에 적힌대로 동작
2-3-3. 조회
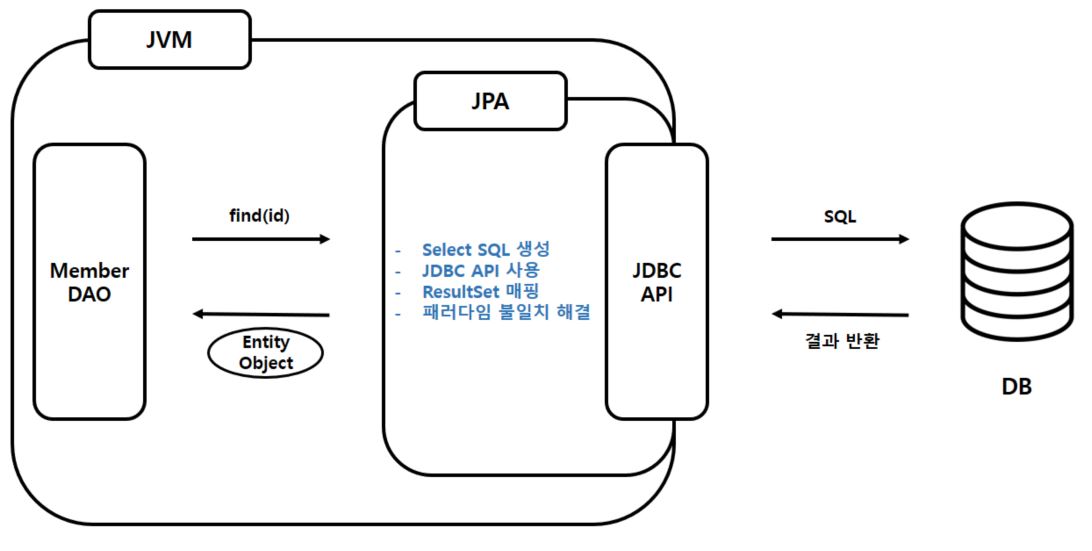
-
find(id)를 하면 위의 과정을 거친 후 알맞은 객체를 생성해서 반환해준다 -
개발자는 자바 컬렉션에 조회하듯이 조회할 수 있다
2-4. JPA 성능 최적화 기능
2-4-1. 1차캐시와 동일성 보장
String memberId = "100";
Member m1 = jpa.find(Member.class, memberId); // SQL
Member m2 = jpa.find(Member.class, memberId); // 캐시
println(m1 == m2) // true-
같은 트랜잭션 안에서는 같은 엔티티를 반환한다
-
동일한 식별자로 조회하면 자동으로 캐시가 적용된다
-
즉, SQL을 1번만 실행하기 때문에 약간의 조회 성능이 향상된다
2-4-2. 쓰기 지연
-
트랜잭션을 커밋할 때까지 Insert SQL을 모은다
-
JDBC BATCH SQL 기능을 사용해서 한 번에 SQL을 전송한다
2-4-3. 지연 로딩과 즉시 로딩
-
지연 로딩 : 객체가 실제 사용될 때 DB 에서 조회해서 반환해준다
-
즉시 로딩 : JOIN SQL로 한번에 연관된 객체까지 미리 조회
2-5. JPA 설정
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
-
spring-boot-starter-data-jpa는spring-boot-starter-jdbc도 함께 포함하기 때문에 해당 의존관계를 제거해도 된다 -
의존관계를 추가하면 아래 라이브러리들이 추가된다
-
hibernate-core: JPA 구현체인 하이버네이트 라이브러리 -
jakarta.persistence-api: JPA 인터페이스 -
spring-data-jpa: 스프링 데이터 JPA 라이브러리
-
3. JPA 사용하기
3-1. 객체와 테이블 매핑
-
JPA가 제공하는 어노테이션을 통해 객체와 테이블을 매핑한다
-
@Entity: 테이블이랑 매핑돼서 관리되는 객체 -
@Id: 테이블의 PK와 해당 필드를 매핑 -
@GeneratedValue(strategy = GenerationType.IDENTITY): DB에서 값을 생성하는 IDENTITY 방식을 사용 -
@Column: 객체의 필드를 테이블의 컬럼과 매핑-
필드명이랑 칼럼명이랑 같으면 생략 가능
-
@Column생략 시, 스프링부트와 통합해서 사용하면 필드 이름을 테이블 컬럼 명으로 변경할 때 객체 필드의 카멜 케이스를 테이블 컬럼의 언더스코어로 변환해준다
-
-
@Table: 클래스 레벨에name=item처럼 테이블 이름 지정 가능- 객체명과 테이블명이 같으면 생략 가능
-
JPA는 public 또는 protected 의 기본 생성자가 필수
3-2. Repository
3-2-1. EntityManager
@Repository
@Transactional
public class JpaItemRepository implements ItemRepository {
private final EntityManager em;
public JpaItemRepository(EntityManager em) {
this.em = em;
}
}-
JPA의 모든 데이터 변경은 트랜잭션 안에서 이루어지기 때문에
@Transactional이 필요 -
JPA를 사용할 때는
EntityManager를 주입받는다-
JPA의 모든 동작은
EntityManager를 통해 이루어진다 -
EntityManager는 내부에 데이터 소스를 가지고 있고, DB에 접근할 수 있다
-
3-2-2. save
public Item save(Item item) {
em.persist(item);
return item;
}-
persist(): 객체를 테이블에 저장할 때 사용하는 메서드 -
@Entity가 붙은 객체의 매핑 정보를 가지고 insert 쿼리를 만들어 DB에 저장 -
Item객체의 id 값을 DB에서 생성한 값으로 사용하는데 이것까지 처리해준다
3-2-3. update
public void update(Long itemId, ItemUpdateDto updateParam) {
Item findItem = em.find(Item.class, itemId);
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}-
JPA가 처음 조회하는 시점에 내부에 원본 객체를 복사한 스냅샷을 가지고 있다
-
트랜잭션 커밋 시점에 findItem 객체와 원본 객체가 동일한지 체크
-
변경사항이 있다면 update 쿼리 전달
-
수정 시, 저장하지 않아도 트랜잭션이 커밋되는 시점에 DB에 update 쿼리가 전달
3-2-4. 단일 데이터 조회
public Optional<Item> findById(Long id) {
Item item = em.find(Item.class, id);
return Optional.ofNullable(item);
}find(객체타입, PK): 엔티티 객체를 PK 기준으로 조회할 때 사용
3-2-5. 여러 데이터 조회
public List<Item> findAll(ItemSearchCond cond) {
String jpql = "select i from Item i";
...
// 뒤의 Item은 반환타입
TypedQuery<Item> query = em.createQuery(jpql, Item.class);
...
return query.getResultList();
}-
PK가 아니라 복잡한 조건으로 데이터를 조회할 때 jpql을 사용
-
jpql은 엔티티 객체를 대상으로 검색하는 객체지향 쿼리
-
jpql에서 파라미터 바인딩은
:이름으로 한다 -
JPA의 경우 동적 쿼리 문제를 해결하지 못함 ➜ Querydsl로 해결 가능
4. JPA 예외 변환
4-1. 예외
-
EntityManager는 순수한 JPA 기술이기 때문에 JPA 관련 예외를 발생시킨다 -
JPA는
PersistenceException과 그 하위 예외를 발생시킨다 -
그 외에도
IllegalStateException,IllegalArgumentException을 발생시킨다 -
@Repository가 JPA 예외를 스프링 예외 추상화(DataAccessException)로 변환해준다
4-2. @Repository
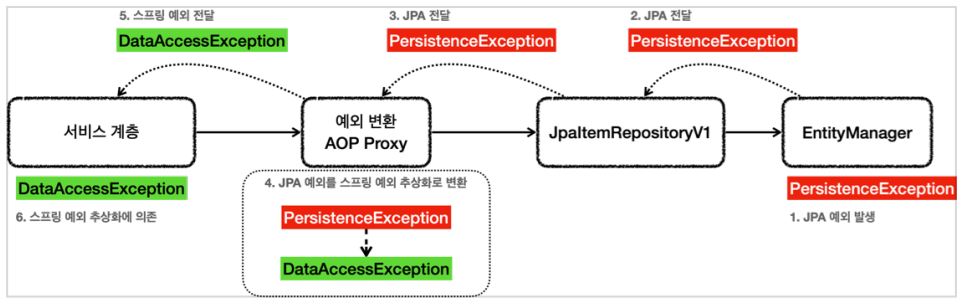
-
@Repository어노테이션이 있으면 스프링이 예외 변환을 처리하는 AOP를 만들어준다 -
스프링과 JPA를 함께 사용하면 스프링은 JPA 예외 변환기를 등록한다
PersistenceExceptionTranslator
-
예외 변환 AOP 프록시는 JPA 관련 예외가 발생하면 JPA 예외 변환기를 통해 발생한 예외를 스프링 데이터 접근 예외로 변환한다
