
김영한 님의 실전! 스프링 데이터 JPA 강의를 보고 작성한 내용입니다.
1. Spring Data JPA 구현체 분석
IDE 를 통해 JpaRepository 에서 찾아보면 보면 SimpleJpaRepository 가 나오는데 바로 이것이 Spring Data JPA 의 구현체입니다.
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private final JpaEntityInformation<T, ?> entityInformation;
private final EntityManager entityManager;
private final PersistenceProvider provider;
...
public SimpleJpaRepository(Class<T> domainClass, EntityManager entityManager) {
this(JpaEntityInformationSupport.getEntityInformation(domainClass, entityManager), entityManager);
}
...
@Override
public Optional<T> findById(ID id) {
...
if (metadata == null) {
return Optional.ofNullable(entityManager.find(domainType, id));
}
...
return Optional.ofNullable(type == null ? entityManager.find(domainType, id, hints) : entityManager.find(domainType, id, type, hints));
}
...
}[ EntityManager ]
해당 클래스를 살펴보면 내부적으로 EntityManager 를 가지고 있는 것을 볼 수 있으며, findById() 를 실행할 때도 em.find() 를 실행해서 가져오는 것을 볼 수 있습니다. 결국 Spring Data JPA 는 JPA 내부 기능들을 활용해서 동작하는 것입니다.
[ @Repository ]
또 @Repository 가 붙어있는 것을 볼 수 있는데 이로 인해 스프링 빈의 컴포넌트 스캔 대상이 되며, JDBC 나 JPA 는 다른 예외들이 발생하게 되는데 해당 어노테이션을 사용함으로써 예외가 발생했을 때 스프링에서 사용할 수 있는 예외로 변환됩니다.
그래서 스프링에서 제공하는 예외가 전달되기 때문에 JDBC, JPA 와 같은 하부 기술을 변경해도 Service 계층에서 예외를 처리하는 로직은 변경하지 않아도 됩니다.
[ @Transactional ]
그 다음에 @Transational 이 붙어있는데 Service 계층에서 @Transactional 을 사용했다면 해당 트랜잭션을 이어 받아서 동작하지만, 트랜잭션이 없어도 Spring Data JPA 는 자기 리포지토리 계층에서 트랜잭션을 시작합니다.
트랜잭션에 readOnly=true 로 되어 있는데, save 와 같은 메서드를 보면 별도로 readOnly 옵션 없이 트랜잭션 어노테이션이 사용되고 있습니다. 그래서 @Transactional 을 걸지 않아도 Spring Data JPA 가 트랜잭션을 걸고 시작하기 때문에 정상적으로 동작합니다.
하지만 save 를 하고 나오는 순간 영속성 컨텍스트가 사라지기 때문에 영속성 컨텍스트로 인해 사용할 수 있는 기능들을 사용할 수 없게 됩니다.
참고로 데이터를 단순히 조회만 하고 변경하지 않는 트랜잭션에서 readOnly=true 옵션을 사용하면 플러시를 생략해서( 변경감지가 일어나지 않음 ) 약간의 성능 향상을 얻을 수 있다고 합니다.
2. 새로운 엔티티를 구별하는 방법
2-1. save 메서드
SimpleJpaRepository 의 save 메서드를 보면 아래와 같습니다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (entityInformation.isNew(entity)) {
entityManager.persist(entity);
return entity;
} else {
return entityManager.merge(entity);
}
}전달 받은 엔티티가 새로운 엔티티라면 persist() 를 호출하고, 새로운 엔티티가 아니면 merge() 를 호출합니다. merge 에 대한 내용은 이전 게시글에서 확인할 수 있습니다.
그렇다면 새로운 엔티티인지를 판단하는 기준은 무엇일까요?
2-2. 새로운 엔티티인지 판단하는 기준
새로운 엔티티를 판단하는 기본 전략은 아래와 같습니다. 참고로 식별자는 persist() 를 하면 엔티티 안에 들어가게 됩니다.
식별자가 Long 과 같은 객체일 때
null로 판단식별자가 int 와 같은 기본 타입일 때
0으로 판단Persistable 인터페이스를 구현해서 판단 로직 변경 가능
[ @GeneratedValue 사용 ]
public class Member {
@Id @GeneratedValue
private Long id;
}예를 들면 Member 엔티티의 @Id 에 @GeneratedValue 를 사용하고 save 호출하면 아래처럼 동작합니다.
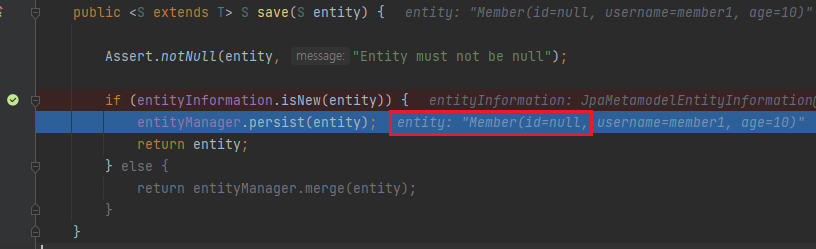
save 에 break point 를 찍고, repository.save() 를 호출하도록 한 뒤 디버깅을 돌리면 나오는 모습입니다. Member entity 의 id 값이 null 인 것을 볼 수 있습니다. 그래서 persist() 가 호출됩니다.
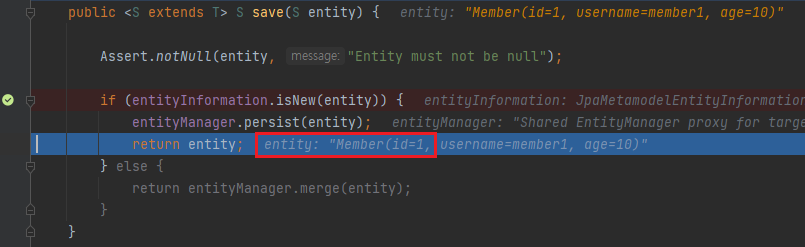
그 후 한 단계 더 실행하고 나면 Member 의 id 에 1 이라는 값이 들어간 것을 확인할 수 있습니다. 즉, 위에서 언급한 것첢 식별자는 persist() 이후에 엔티티에 들어가게 됩니다.
[ @GeneratedValue 미사용 ]
public class Item {
@Id
private String id;
}
// ----------------------------
@Test
void save() {
Item item = new Item("1");
itemRepository.save(item);
}만약 위처럼 Id 값을 직접 지정하고 save() 를 호출한다면 결과는 아래와 같습니다.
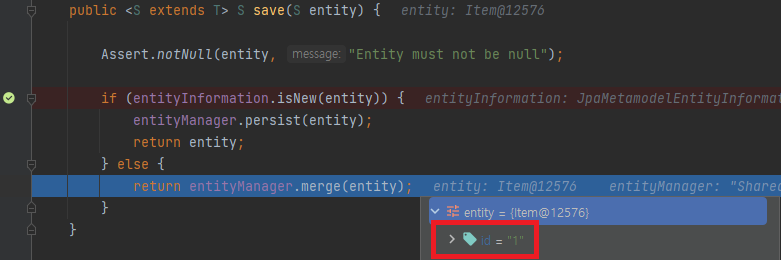
동일하게 save 임에도 불구하고 이전과는 다르게 persist() 가 아닌 merge() 를 호출합니다. 왜냐하면 이미 Item 은 객체이고, 이미 객체에 id 값이 들어있기 때문에 새로운 객체라고 판단하지 않은 것입니다.
merge()는 우선 DB를 호출해서 값을 확인하고, DB에 값이 없으면 새로운 엔티티로 인지하므로 매우 비효율적입니다. 따라서 Persistable 을 사용해서 새로운 엔티티 확인 여부를 직접 구현하게는 좋습니다.
2-3. Persistable
@Entity
@EntityListeners(AuditingEntityListener.class)
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Item implements Persistable<String> {
@Id
private String id;
@CreatedDate
private LocalDateTime createdDate;
public Item(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public boolean isNew() {
return createdDate == null;
}
}Persistable 에는 PK 의 타입을 지정합니다. 그리고 getId 와 isNew 를 오버라이딩 해야 하는데 isNew() 메서드에 어떤 기준으로 새로운 객체인지 판단할 것인지를 작성하면 됩니다.
강사님이 자주 사용하는 방식은 @CreatedDate 를 사용하는 것이라고 합니다. @CreatedDate 도 JPA 의 이벤트인데, persist 되기 전에 호출됩니다. 그래서 이 값이 null 인지를 기준으로 새로운 객체인지를 판단할 수 있게 됩니다.
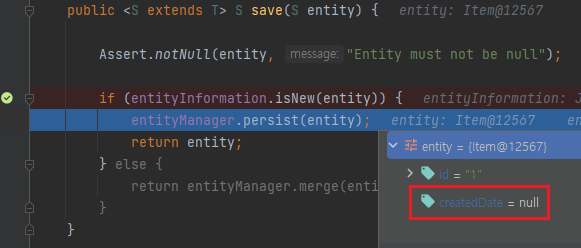
그래서 아까와 동일한 테스트를 실행시켰을 때 createdDate 가 null 이기 때문에 새로운 객체라고 판단해서 persist 가 실행됩니다.
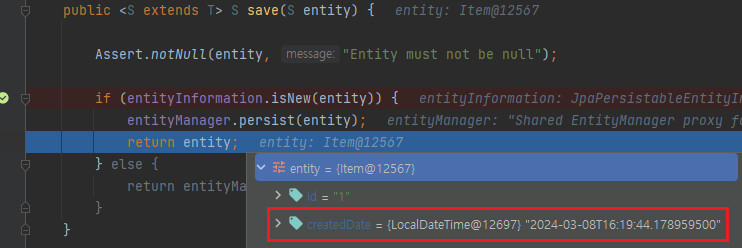
persist 이후에 값을 확인해보면 createdDate 에 값이 정상적으로 들어있는 것을 확인할 수 있습니다.
