1. NoSQL
1) RDBMS 특징
- Data는 column과 table에 저장
- DML, DDL을 사용
- Transaction의 병행처리와 복구를 보장
- Abstraction from physical layer
: physical layer에 저장된 방식과 상관 없이 application에서 동작(data independence★) - HDD에 있는 data의 위치를 바꿔도 application에서 수정이 필요하지 않음
- index를 사용해서 query를 실행할 수 있음
- in memory database
: 자주 쓰는 소규모 database를 M/M에 올려 I/O 없이 READ/WRTIE할 수 있음
2) NoSQL
- Not following Relational DBMS
3) Big data & NoSQL
- Big Data의 경우 대량의 data를 어떻게 저장하고. 접근할 때 crash 발생 시 어떻게 처리하고 백업해둘지
- 병렬처리가 필수적
- Web data(semi structured)를 어떻게 관리할 것인가?
e.g. web data : twitter , face book data 등
- explosion of social media
- cloud-based solution
- schema가 자주 바뀜(frequently changing schema)
- dealing with open-source
Big data를 처리하는데 왜 RDBMS가 적합하지 않은가?
web data는 no or semi structured, but RDBMS requires full structured!
4) NoSQL 특징
- big data
- 확장성 있는 복제 및 분산
- 대부분의 query는 update(system이나 관리자가 수행)보다 read(검색)을 수행
- 비동기식 insert & update ( log- based , primary site로부터 나중에 보고 쓰는 방식)
- ACID가 아닌 BASE
- CAP
- open source 환경
2. NoSQL Database Types
- 4 Major types of databae
1) Sorted ordered column store
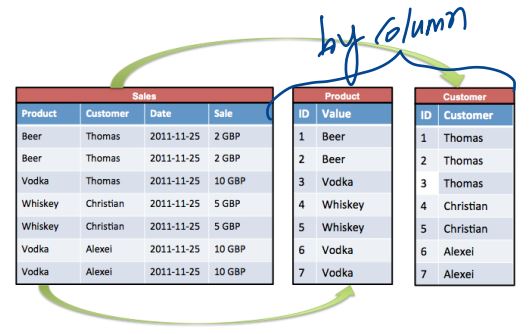
2) Document database
- RDBMS의 row(행)에 해당하는 data를 document형식으로 저장
- document의 unique key based adressed
- schema free
- diffrent documents can have structures & schema

e.g. MongoDB, CouchDB
3) Key-Value Store
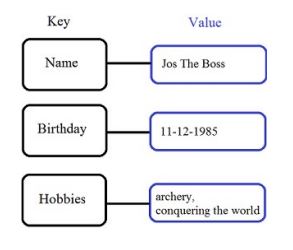
- 가장 심플 ver, 각 database의 단일 아이템이 키와 값의 쌍으로 구성
4) Graph Database
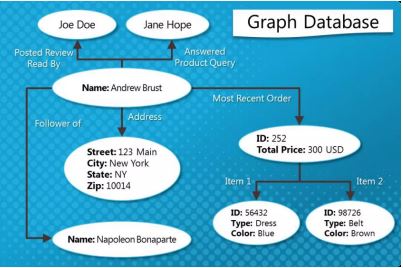
e.g. SNS Data
3. CAP Theorem
- CAP 속성 중 2가지 속성을 동시에 만족 (Pick Two)
① Consistency
: 일관성은 분산 시스템의 모든 노드에서 데이터가 항상 일관된 상태로 유지되는 것을 의미합니다. 일관성을 유지하기 위해서는 모든 노드 간에 동일한 데이터를 복제하거나 동기화 해야함
② Availability
: 가용성은 분산 시스템이 항상 요청에 응답하고 사용 가능한 상태를 유지하는 것을 의미합니다. 가용성을 보장하기 위해서는 시스템 장애에도 데이터에 접근할 수 있도록 데이터를 복제하거나 분산하여 처리
③ Partition tolerance
: 분할 허용성(Partition tolerance) 네트워크 분할이 발생하거나 노드 간 통신이 실패해도 시스템이 정상적으로 작동할 수 있는 능력. 분할 허용성을 갖추기 위해서는 데이터를 여러 파티션으로 분산하여 저장하고 처리
