
운영체제란
- 여기저기서 가져온 문구
- 하드웨어와 소프트웨어를 관리하는 일꾼
- 운영체제(Operating System, OS)는 컴퓨터의 하드웨어 자원을 관리하고, 사용자 및 응용 프로그램이 컴퓨터와 상호작용할 수 있도록 지원하는 소프트웨어의 집합
- 하드웨어를 관리하고, 컴퓨터 시스템의 자원들을 효율적으로 관리하며, 응용 프로그램과 하드웨어 간의 인터페이스로써 다른 응용 프로그램이 유용한 작업을 할 수 있도록 환경을 제공
- 컴퓨터 시스템의 핵심 소프트웨어로, 컴퓨터 하드웨어와 응용 프로그램 간의 상호작용을 관리하고 제어하는 역할을 한다.
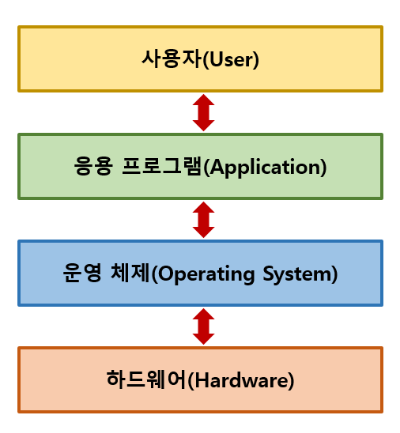
내 생각: 컴퓨터의 자원을 효율적이고 안전하게 사용할 수 있도록 도와주는 소프트웨어. 하드웨어와 소프트웨어를 연결해주는 인터페이스
운영체제의 역할
- I/O device 관리
- I/O 디바이스와 컴퓨터 간의 데이터를 주고 받는 것을 관리
- interrupt
- I/O 디바이스와 컴퓨터 간의 데이터를 주고 받는 것을 관리
- process 관리
- 사용자가 실행한 프로그램이 정상적으로 작동할 수 있도록 관리
- cpu scheduling
- 사용자가 실행한 프로그램이 정상적으로 작동할 수 있도록 관리
- memory 관리
- process를 실행함에 있어서 효율적으로 메모리를 활용 할 수 있도록 관리
- virtual memory
- paging
- process를 실행함에 있어서 효율적으로 메모리를 활용 할 수 있도록 관리
- storage 관리
- 컴퓨터에 저장되는 데이터들을 효율적으로 관리
- file system
- 컴퓨터에 저장되는 데이터들을 효율적으로 관리
- protection and security
운영체제의 구조
유저 프로그램 → 인터페이스 → 시스템콜 → 커널 → 하드웨어
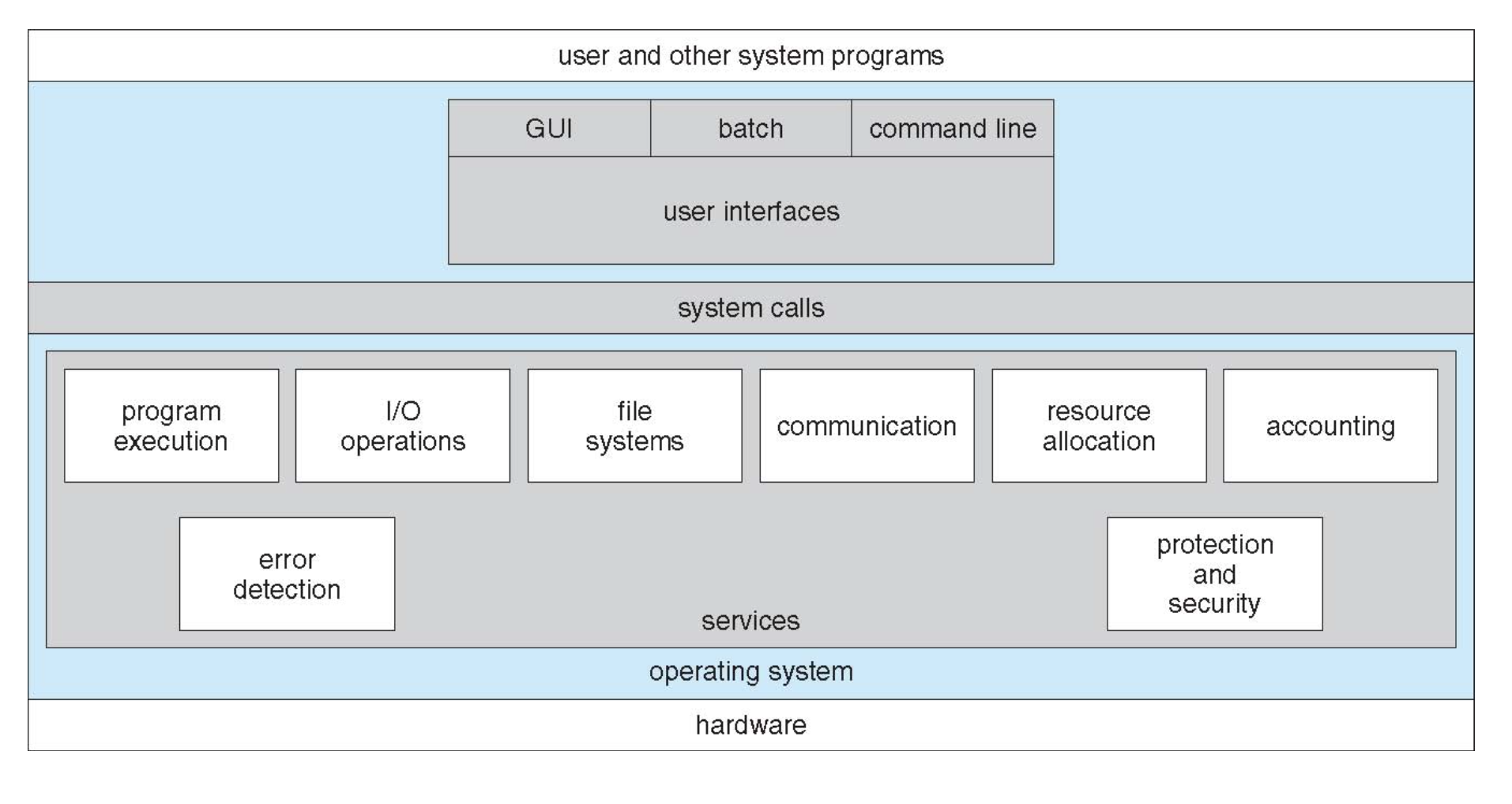
- 운영체제는 이 중 인터페이스 ~ 커널 부분에 해당함
- 프로세스와 하드웨어 사이의 인터페이스라고 생각하면 됨
시스템 콜
- OS의 서비스를 호출하는 interface
- 주로 하드웨어에 접근하는 명령어.
- 유저가 직접 하드웨어에 접근하는 것은 시스템 보안 및 안전상 좋은 선택이 아니므로 system call을 통해 kernel에 접근하게 된다
- high-level language로 작성되어 있다. c or c++
- system call을 바로 호출하기 보다는, API를 통해 호출하게 된다
- ex) printf 함수를 통해서 system call 함수를 간접적으로 호출한다
- 이식성이 높다.
- 운영체제마다 하는 일을 같더라도 함수명과 사용법은 다르다.
- 그래서 만약 API로 호출하지 않고 직접 system call로 코드를 짜게 되면 이식성(potability)이 낮아진다
- 우리는 그래서 같은 코드를 작성해서 다른 운영체제에서 실행할 수 있다.
- 반드시 그렇진 않다..
- 왜 게임은 그러면 운영체제를 타지?
- 반대로 응용 소프트웨어는 많이 안탄다.
- 왜 어플리케이션은 운영체제를 탈까?
- 번호로 저장이 되어있으며, 이를 통해 메모리에 올라와 있는 syscall table(IDT)을 참조하여 실행하게 됨
시스템 콜 작동 방식 - Dual mode operation
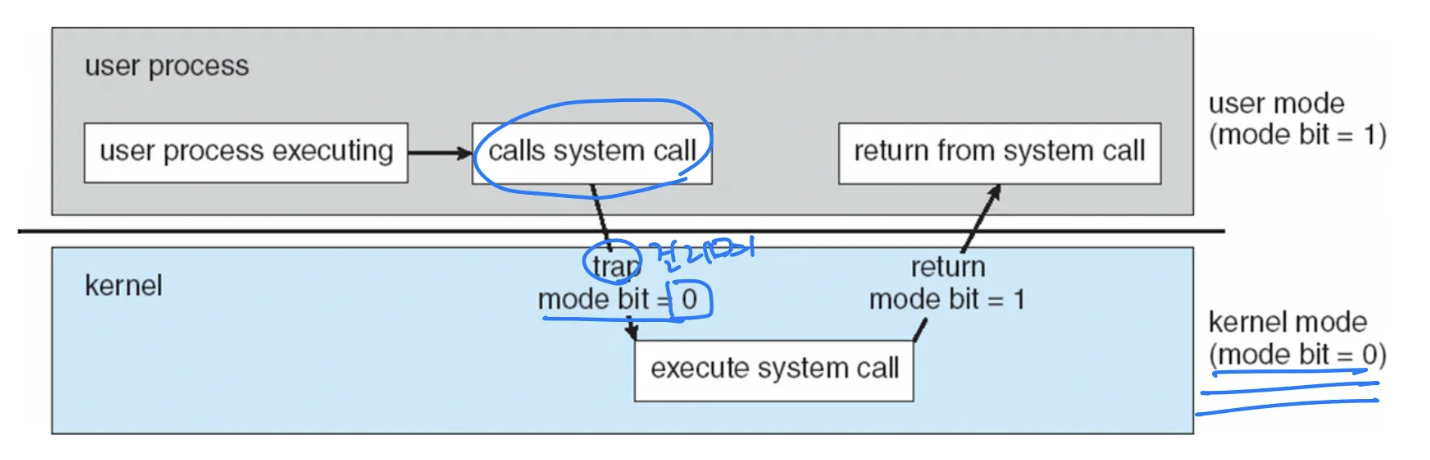
- 시스템 콜이 호출되면 trap을 발생시킴
- trap vs interrupt
- trap은 cpu 내부에서 발생하는 즉 소프트웨어에서 발생하는 예외 및 조건에 의해 다른 일을 처리해야할 때 사용하는 기능
- trap vs interrupt
- trap에 의해 modebit이 0이 되면 유저 모드에서 커널 모드로 변경되어 I/O를 실행
- 이를 통해 유저가 직접 하드웨어와 컴퓨터 자원에 직접적 접근을 하는 것을 막을 수 있음
Interrupt
cpu
- 계산을 처리하는 장치
- register: 임시기억장치. 매우 작고 매우 빠름
- CU: cpu의 동작을 컨트롤함
- ALU: 계산을 담당
- 한 번에 하나의 연산만 할 수 있고, 엄청 빠름
- 하지만 컴퓨터는 지금 진행하고 있는 일 말고도 예외적인 상황이나 더 중요한 상황이 자주 발생함
- 이 상황을 cpu가 모두 관리 감독하며 polling 방식으로 처리하는 것은 cpu 자원을 낭비함
- 그렇다고 cpu가 중요한 일이라고 다른 장치를 기다리는 것은 죄악임
interrupt란
-
cpu가 하고있는 일을 잠시 정지시키고 더 우선순위가 높거나 중요한 일을 하게 하는 것.
- cpu가 아닌 다른 하드웨어나 소프트웨어가 발생시킴.
- 즉, 지금 중요한 일이 있는 주체가 자신의 이벤트를 직접 cpu에게 알리는 것
-
하던 일을 멈추고 인터럽트 핸들러 함수를 실행하게 함
-
하드웨어 인터럽트: 입출력 장치와 같은 하드웨어에서 발생하는 인터럽트
-
소프트웨어 인터럽트: 트랩. 프로세스 오류나 예외 등으로 프로세스가 시스템 콜을 호출하며 발생
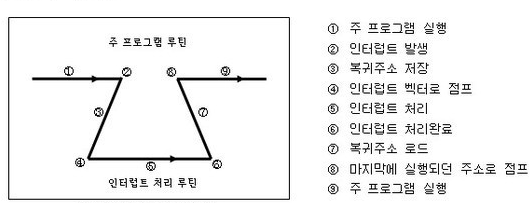
interrupt 작동 방식
- interrupt 발생 시, 현재 프로세스의 정보와 복귀 주소를 저장.
- interrupt handler 함수로 이동
- interrupt 처리
- 복귀 주소로 이동
- 하던 일 마저 진행
DMA
- I/O 장치는 메모리에 직접 접근할 수 없음
- 보안상의 위험으로
- 그런데 cpu는 word 단위로 데이터를 일일히 읽어서 메모리에 적재해야 하는 상황임
- [disk나 buffer] - [cpu] - [memory] 순서
- 이것을 작업하는 동안 cpu가 다른 일을 못함
- 한 워드 읽고 인터럽트 받고, 한 워드 읽고 인터럽트 받아야 함
- 인터럽트가 너무 많이 들어옴
- 그래서 cpu가 아닌 장치가 memory에 접근할 수 있도록 하는 장치를 만듦 → DMA
multi-programming
- 이제 interrupt가 있으니 cpu가 놀지 않고 효율적으로 계속 일할 수 있을 것이라고 생각했음
- 하지만 I/O 처리에 있어서 문제가 발생
- 컴퓨터의 작업은 I/O 작업을 빼고 말할 수 없음
- I/O간의 순서가 중요한 경우가 있는데, Long I/O가 아직 끝나지 않아 interrupt가 오지 않은 상황에서 다른 I/O작업이 들어오면 어쩔 수 없이 cpu가 놀아야함
- 그래서 다른 프로세스를 실행하기로 함
- 동시에 실행하는게 아니라, process를 각각 실행하는거임
- 이를 multi-programming 이라고 함
Memory
메모리 계층 구조
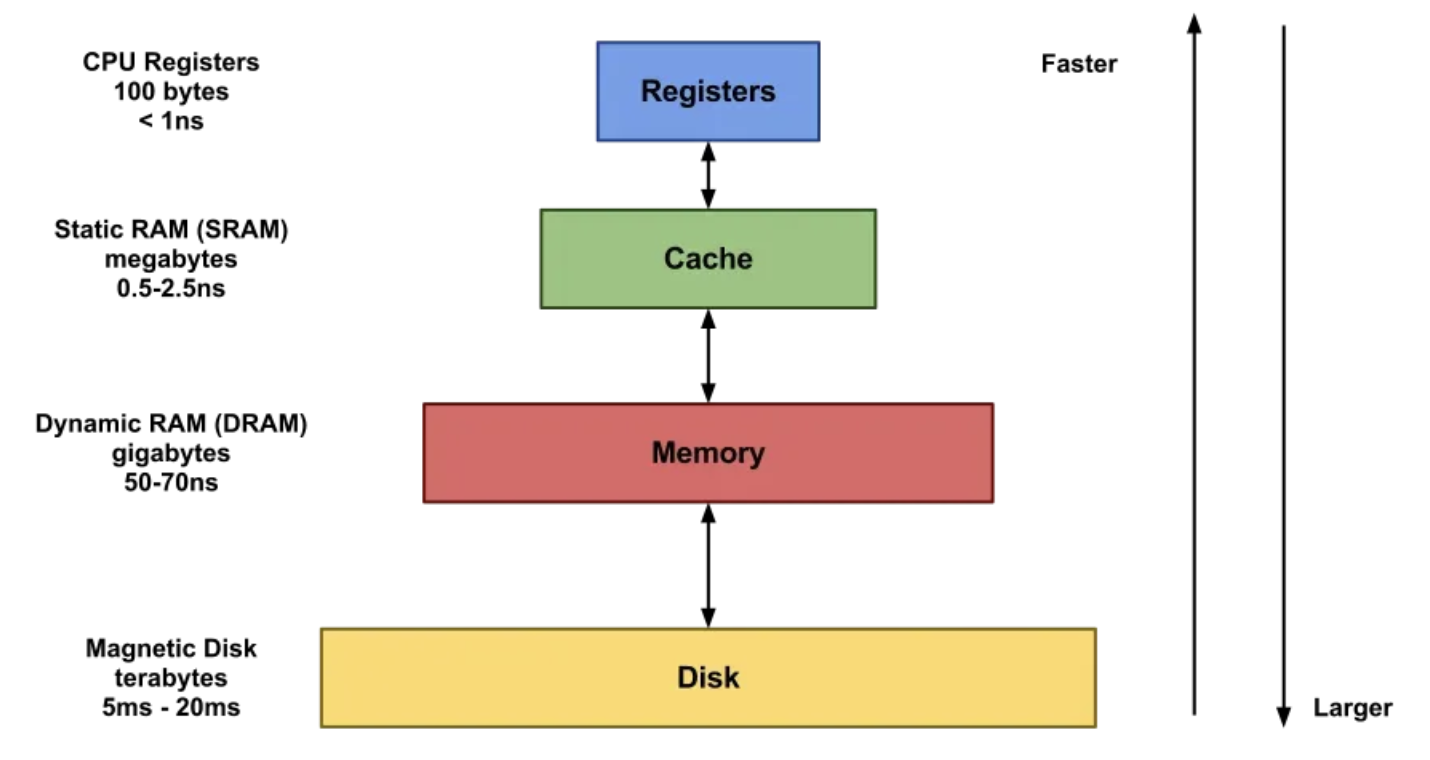
- 위로 갈수록 빠르고, 용량이 작고, 비쌈
- 아래로 갈수록 느리고, 용량이 작고, 싸다.
- 이런 구조를 가지고 있는 이유는 cpu가 일을 할 때 특정 데이터 혹은 명령어에 빈번하게 접근되는 현상이 있기 때문이다 → 참조지역성
- 그래서 지금 빈번하게 접근되는 소량의 데이터를 빠른 저장장치에 놓고, 그렇지 않은 데이터일수록 데이터계층 아래에 두면 경제적이다.
참조지역성
시간지역성 - 최근에 사용한 데이터에 다시 접근하려는 특성
공간지역성 - 최근에 사용한 데이터에 인접한 데이터에 접근하려는 특성
- 이를 활용하여 메모리와 레지스터 사이에 캐시를 둔다
- cpu와 메모리사이의 속도 차이가 메모리와 저장장치 사이의 속도 차이보다 크다
- 그래서 메모리에서 데이터를 가져올 때 block단위로 한꺼번에 근처 데이터까지 가져와 캐시에 저장한다
- 그리고 프로세서는 캐시에 저장된 데이터를 word 단위로 읽으며 처리하는데, 참조지역성에 의해 캐시히트가 많이 나게된다.
프로세스 주소공간
- 프로세스는 기본적으로 모든 데이터가 메모리 위에 올라와야 실행됨
- 메모리에 탑재된 프로세스를 주소공간에서 표현하면 아래와 같음
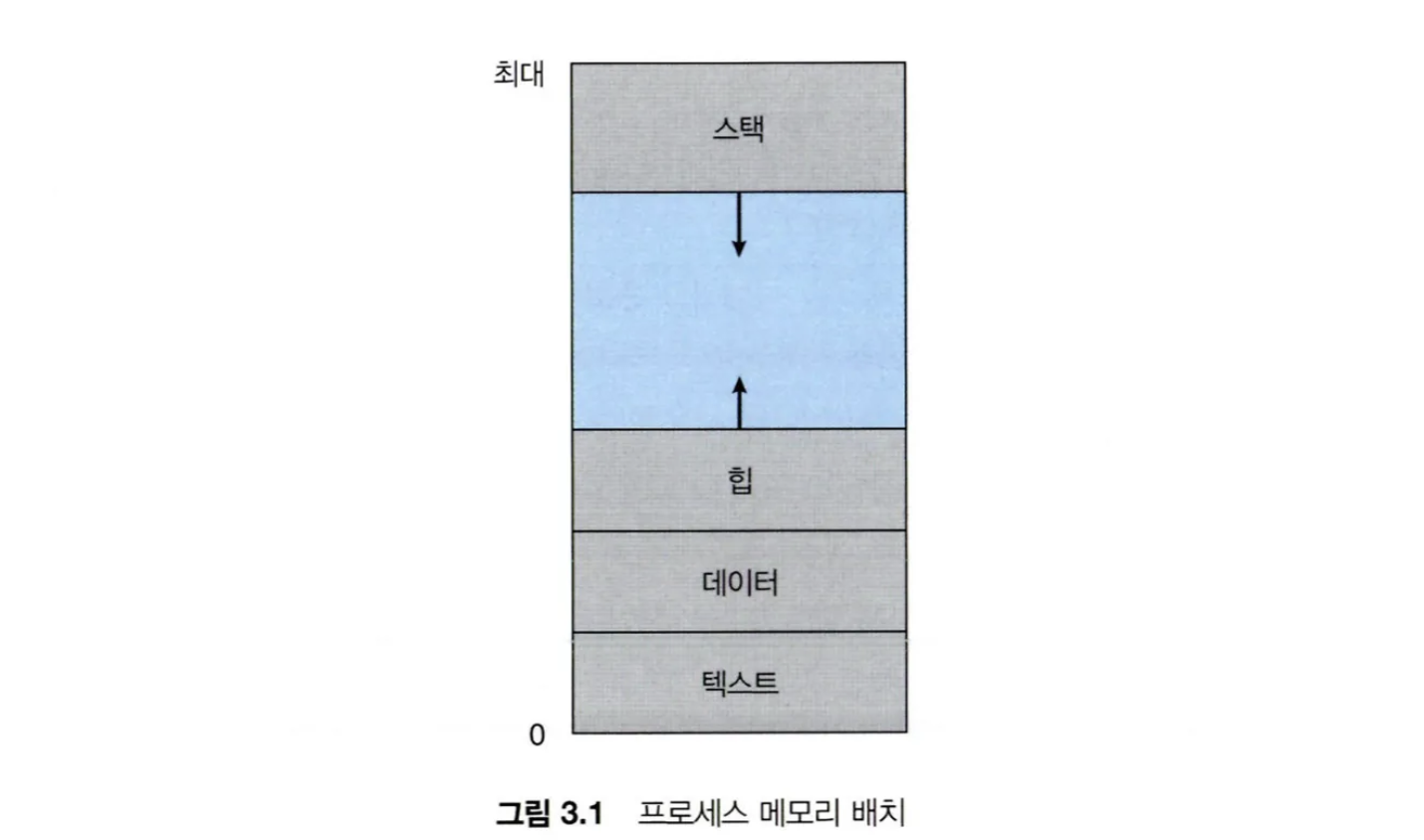
stack
- 함수 호출과 관련된 데이터들이 저장되는 영역
- 지역변수, 매개변수, return address 등
- 주소가 큰 쪽에서 낮은 쪽으로 할당되고, 아래로 커짐
- 늘어나다가 영역을 초과하면 stack overflow가 발생
Heap
- 동적할당으로 발생하는 데이터들이 저장되는 영역
- 즉, 런타임에 할당되는 데이터가 저장되는 영역
- 주소가 낮은 쪽에서 높은 쪽으로 할당되고, 위로 커짐
Data
- 전역변수, static 변수 등이 저장되는 영역
- 즉, 컴파일 단계에 데이터가 저장되는 영역
- 크기 고정
Text
- program code가 저장된 영역
- 크기 고정
PCB & Context Switching
PCB(Process control block)
- program을 실체화하는 자료구조
- 각 프로세스의 메타데이터를 저장함
- process ID
- process state
- process proiority
- cpu register
- Program Counter
- memory usage
왜 필요한가
- multi programming 환경을 지원하기 위해
- interrupt가 발생하여 cpu가 해당 process를 더이상 진행할 수 없을 때, 진행 중이던 process를 저장해놓고 다시 돌아올 수 있어야 함
Context Switching
- cpu가 실행하던 process의 상태를 저장하고 다른 process를 실행하는 것
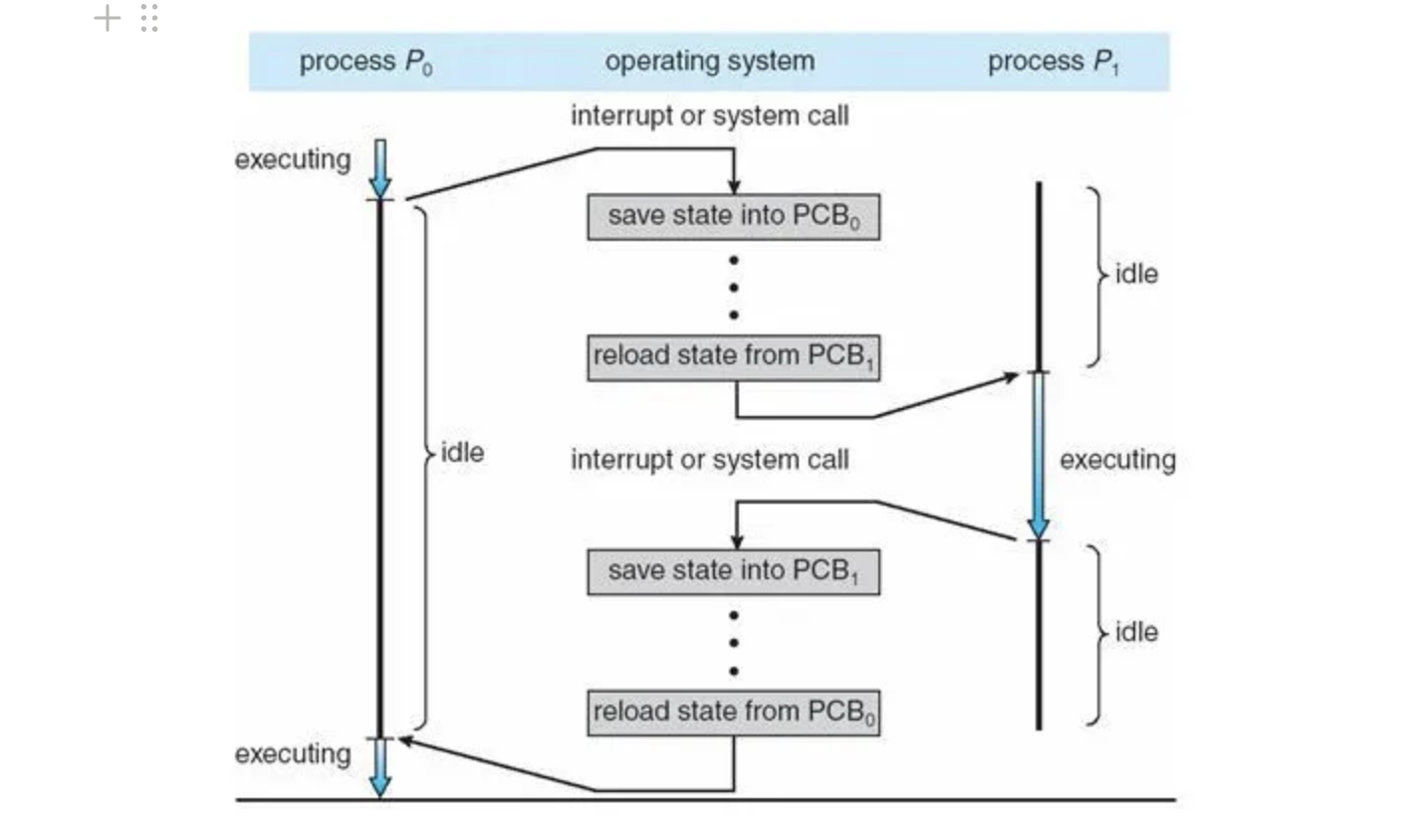
- interrupt가 발생하면 현재 실행중인 process의 메타 데이터를 PCB에 저장
- 다음 실행할 process의 메타 데이터를 해당 프로세스의 PCB에서 가져와 세팅
- process 실행
장단점
- 이것은 multi-programming을 수행하기 위한 overhead로 작용함
- cache miss overhead도 존재
- 새로운 process가 실행될 때, cache에 전에 실행하던 process의 메모리 정보가 저장되어 있기 때문에 cache를 비워야함
- 그러면 프로세스를 처음 실행할 때에는 cache miss가 자주 발생
- memory 접근이 느려서 cache를 만들었는데 memory에 자주 접근해야해 cache의 존재의미가 옅어짐
- 하지만, 그럼에도 cpu가 쉬지않고 일을 진행할 수 있기 때문에 이러한 overhead를 감수
CPU Scheduling
- cpu 자원을 현재 수행중인 process중 누구에게 줄 지 결정하는 것
- 기본적으로, I/O가 많은 I/O bound job에 cpu를 자주 주고, 계산이 많은 CPU bound job에 cpu를 덜 줘야함
- I/O 가 많은 작업이 더 interactive하기 때문임
- 오래걸리는 작업이 조금 더 오래걸리는 것보다 빨리 작업되어야 할 것이 조금이라도 늦게 작업되는 것은 다름
Process state
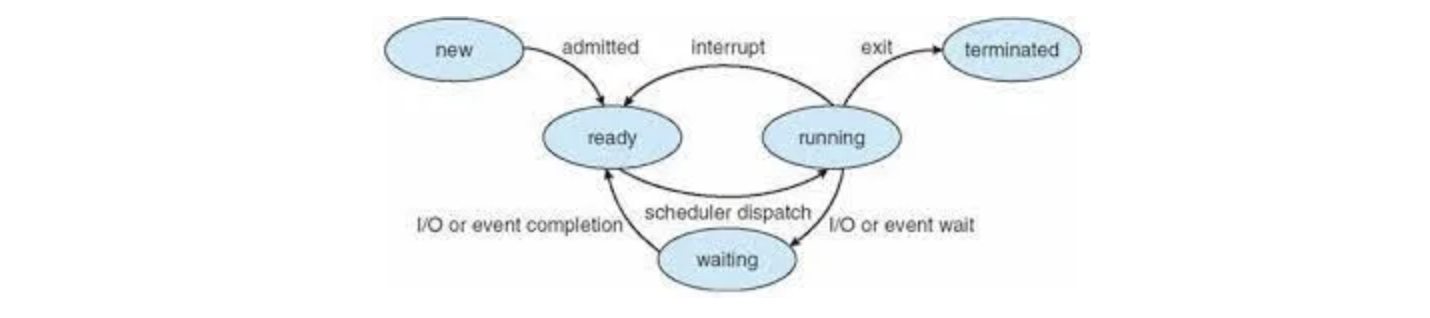
- new: process 가 생성된 상태
- running: process 가 실행중인 상태
- waiting: process가 어떤 event가 발생하길 기다리는 중 (주로 I/O)
- ready: 일할 준비가 된 process. 아직 cpu를 할당받지 못함
- terminated: 종료된 process
Scheduler
Long term scheduler (Job scheduler)
- 빈번하게 발생하지 않음
- 새롭게 발생한 process를 queue에 넣을지 말지 결정
- degree of multi programming을 관리
- 최대 몇개의 process가 실행가능하게 할 지 관리 가능
Short term scheduler (CPU scheduler)
- 빈번하게 발생
- ready 상태에 있는 process 중 누구에게 cpu 자원을 할당할 지 결정
- 얘를 cpu scheduler 라고 함
Medium term scheduler
- multi programming 환경에서 process를 여러개 실행하다보면 메모리가 부족할 수 있음
- memory에 있는 process를 disk로 내려버림
- 다시 running 상태가 되면 memory에 올림
CPU scheduler
- 메모리에 존재하고, i/o 작업이 일어나지 않아 지금 당장 일할 수 있는 process중 하나에게 cpu 자원을 할당
- cpu scheduling은 아래 상황에서 발생함
- cpu 자원을 할당받은 process가 waiting 상태에 들어갈 때 (I/O)
- cpu 자원을 할당받은 process가 ready 상태에 들어갈 때 (timeout)
- waiting중이던 process가 waiting을 끝내고 ready 상태에 들어갈 때 (finished interrupt)
- process가 종료되었을 때
- 1,4번의 상황을 비강제적(nonpreemptive), 2,3번 상황을 강제적(preemptive)라고 함
- cpu scheduling의 가장 중요한 기준은 두 가지
- cpu utilization
- waiting time
Scheduling Algorithm
비선점형(Nonpreemptive)
FCFS
먼저 들어온 process에게 cpu 자원을 할당하는 구조
- 단점: convoy effect - cpu를 오랫동안 이용해야하는 process가 있다면 뒤에 들어온 cpu를 짧게 이용하는 일들의 waiting time이 증가
SJF
빨리 끝나는 process 먼저 cpu 자원을 할당하는 구조
- 장점: 평균 waiting time이 가장 적음
- 단점: cpu burst, 즉 해당 process가 얼마나 cpu를 이용해야 하는 지 예측할 수 있어야 한다
- 하지만 이를 알 수 없다
- 그래서 해당 프로세스가 전에 실행되었던 기록을 바탕으로 예측해야 함
선점형(Preemptive)
SRTF
종료까지 남은 시간이 가장 적은 process 먼저 cpu 자원을 할당하는 구조
- SJF와 비슷하나, 진행중인 process도 중간에 새로운 process의 remaining time이 더 적다면 해당 프로세스를 강제로 진행한다는 차이가 있음
Priority-scheduling
우선순위가 높은 process에 먼저 cpu 자원을 할당하는 구조
- 단점: 우선순위를 정하기 어려움, 우선순위가 낮은 프로세스의 starvation 가능성
- 해결책: aging / priority boost 진행
Round Robin
process 마다 최대로 cpu 자원을 할당받을 수 있는 시간을 정해 시간이 종료되면 강제로 cpu 자원을 다른 process에 할당하는 구조 (기본은 FCFS)
- 효과: time quantum이 정해지면 ready queue에서 process가 기다릴 최대 시간인 upper bound를 알 수 있으므로 계획적으로 일할 수 있음 time quantum이 너무 크면 FCFS와 다를게 없음 time quantum이 너무 크면 CPU가 일하는 시간이 짧아져 context switching의 overhead가 부각 multi-programming을 실현 - 여러 process가 동시에 동작할 수 있음
- 장점: response 시간이 빨라짐
- 단점: SJF보다 turnarround time 일반적으로 안좋음
Multilevel Queue
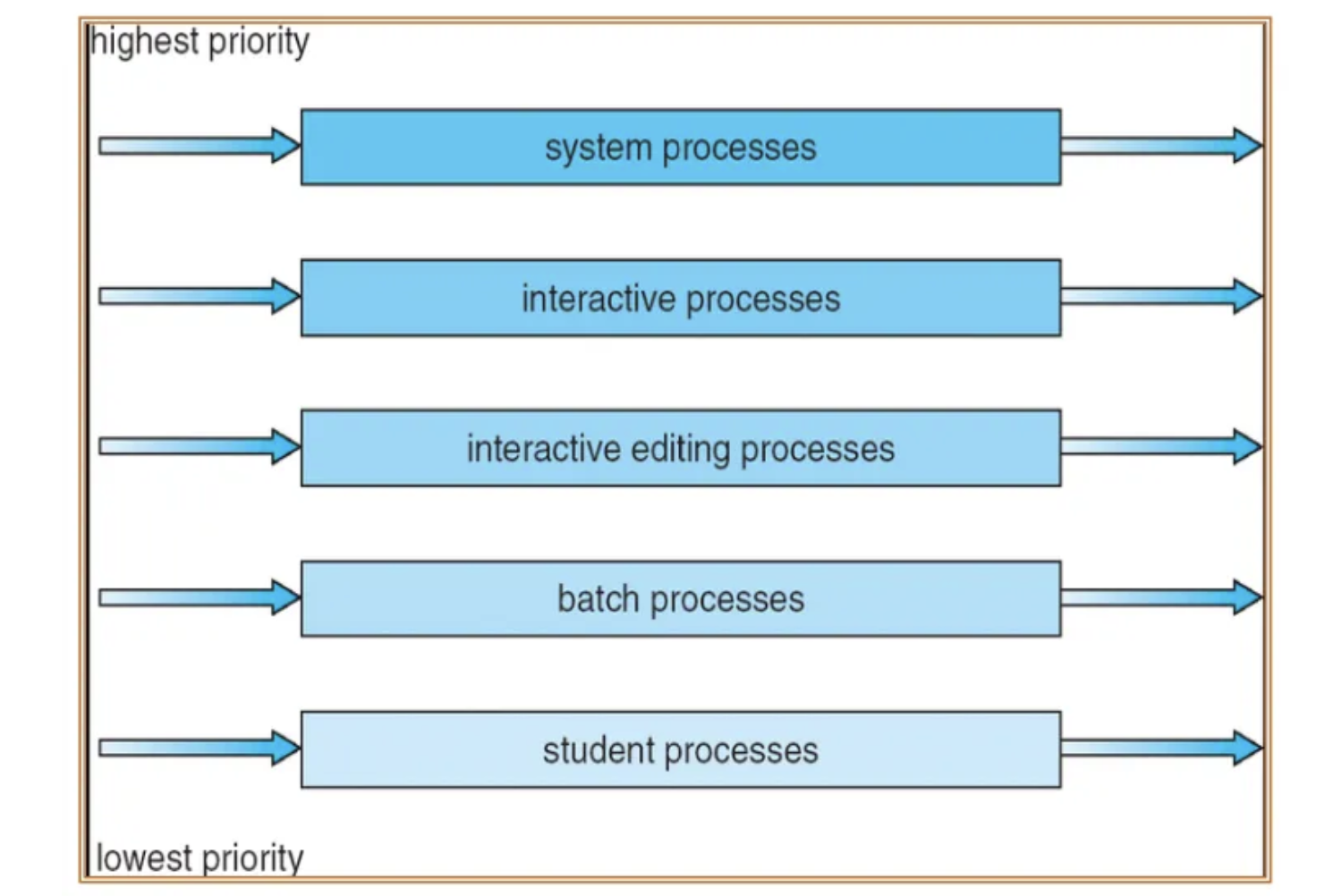
Ready queue를 여러개로 분할하여 운영하는 방식
- 개요
- Round Robin만으로는 I/O job과 CPU job을 나누어 cpu 자원을 할당할 수 없어서 탄생
- process는 생성될 때 하나의 큐에 고정
- 각각의 큐는 서로다른 scheduling algorithm을 가질 수 있음
- 큐마다 우선순위가 있음 → 큐 스케줄링
- 예시: foreground queue - interactive(i/o bound job) - Round Robin background queue - batch(cpu bound job) - FCFS
- 큐 스케줄링 방식
- 우선순위 방식
- 우선순위가 높은 큐가 비면 우선순위가 낮은 큐의 process에게 cpu 자원을 줌
- starvation 발생 가능
- time slice 방식
- cpu 시간을 큐마다 일정 시간으로 분배
- 우선순위 방식
Multilevel Feedback Queue
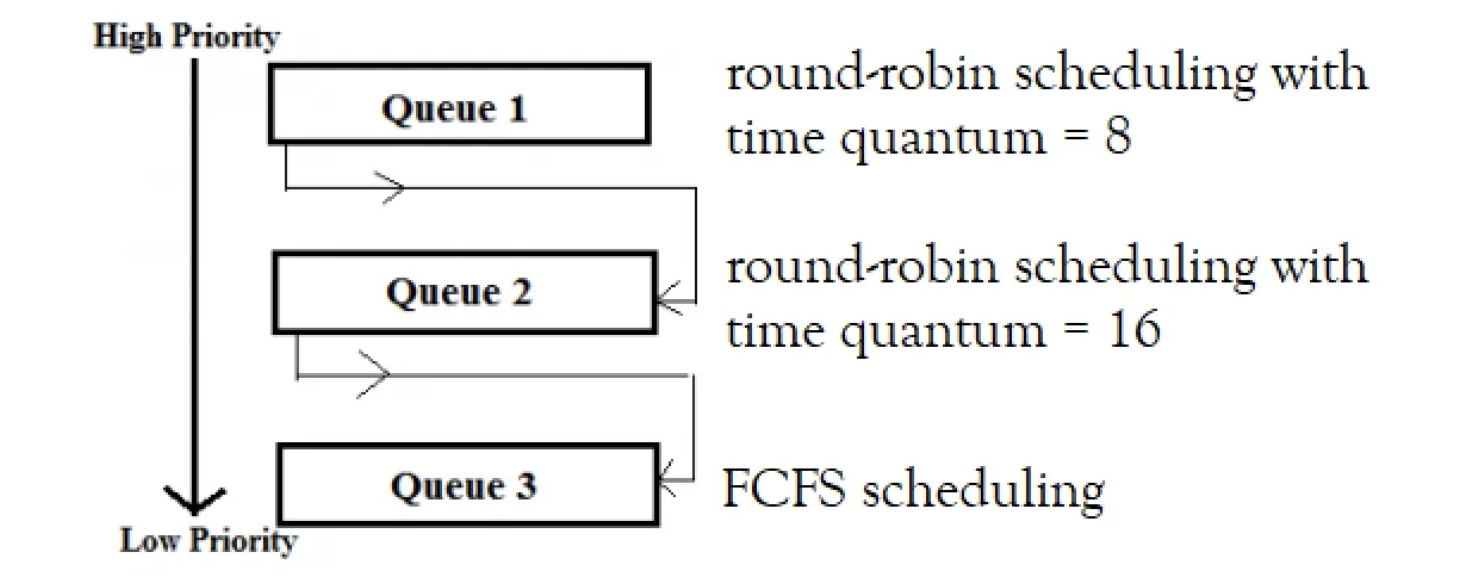
Multilevel queue에서 process를 queue 간에 이동 가능하게 하여 단점을 극복하는 방식
- 개요
- process는 마다 cpu bound job인지 I/O bound job인지 알 수 없음
- 그래서 queue간 이동을 하도록 만듦
- 필요 정보
- queue 개수
- 각 큐에 적용되는 스케줄링 알고리즘
- 큐간 이동조건
- 최초로 어느 큐에 넣을 것인지 정의
- 효과
- 조금만 일해도 되는 일들은 앞쪽 queue에서 끝나고, 오래 일해야 하는 일은 다음 queue로 넘어가서 진행하는 방식이기 때문에 I/O bound job과 cpu bound job을 자동으로 구분할 수 있음
- 아래 큐로 내려가서 너무 오랫동안 일을 안하게 된다면 priority boost로 문제를 해결 할 수 있음
Process & Thread
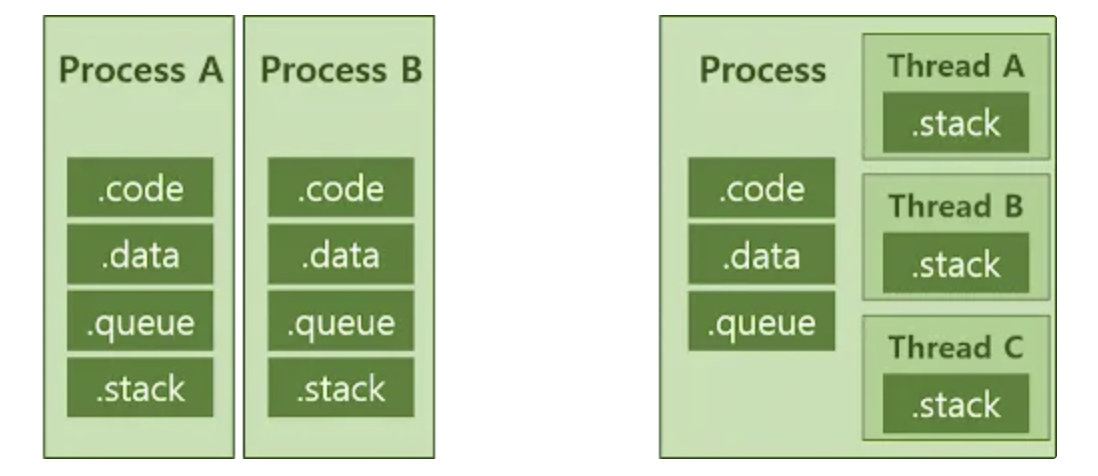
thread란
- 경량화된 process
- process에서 code, data, heap 부분은 공유받음
- stack부분만 thread별로 따로 관리
- 하나의 프로세스는 여러 스레드를 가질 수 있음
thread의 장점
-
응답성
process가 일을 하다가 I/O가 발생하면 원래 멈추고 다른 process의 작업을 진행해야 하지만, thread를 여러개로 작업하게 되면 같은 프로세스의 다른 일을 진행할 수 있다. 그래서 프로세스 전체적으로 보면 계속해서 일을 할 수 있다.
-
자원공유
multi process(하나의 프로세스를 여러 프로세스로 나누어서 실행)로도 thread가 하는 일을 할 수 있으나, 메모리에 동일한 자원이 중첩되어서 올라가니 비효율적이다.
-
경제성
프로세스를 새로 만들기 위해서는 thread보다 데이터가 크기 때문에 overhead가 크게 들어간다. thread는 stack부분만 새로 만들어주면 되므로 훨씬 경제적이다.
-
확장성
다중 프로세서 환경에서 하나의 프로그램을 여러 프로세서를 활용해서 병렬적으로 작업할 수 있다.
multi-process vs multi thread
multi-process
- 장점
- 안정성이 높다. 하나의 프로세스가 종료되더라도 프로세스마다 독립적인 메모리 공간을 가지므로 다른 프로세스에 영향을 주지않는다.
- 시스템 확장성이 높다. 새로운 기능이나 모듈을 추가하더라도 다른 프로세스에 영향을 주지 않기 때문에, pm2와 같은 다중 서버환경을 제공할 수 있다.
- 단점
- context switching overhead가 발생한다.
- 메모리에 동일한 자원이 많이 올라오기 때문에 비효율적이다.
multi-thread
- 장점
- 가볍다. 가볍기 때문에 생성, 제거할 때 overhead가 적다.
- 자원을 공유한다. stack을 제외한 대부분의 process 데이터를 공유하기 때문이다. 또한 process간 통신을 통해 자원을 공유할 필요가 없기 때문에 시스템 자원 소모가 줄어든다.
- context switching overhead가 적다. PCB보다 TCB의 크기가 훨씬 작기 때문이다.
- 응답시간이 빠르다. 프로세스간 통신보다 가벼운 스레드간의 통신과 자원공유가 더 빠르기 때문이다.
- 단점
- 안정성이 낮다. 하나의 스레드에서 발생한 문제가 다른 스레드에 전파될 수 있다.
- 동기화를 해결해야한다. 스레드는 공유 자원을 이용하기 때문에 올바르게 해결하지 않으면 병목 현상이나 데드락이 발생할 수 있다.
- 여전히 context switching overhead가 존재한다.
- 그래서 항상 multi thread가 single thread보다 빠르다고 말할 수는 없다
- 디버깅이 어렵다.
- 잔여 스레드의 리소스 낭비가 발생할 수 있다.
- 항상 모든 thread를 사용하지 않고 한 두개의 thread만 사용한다면, 나머지 thread는 자원 낭비
