
짧은 내 소개
나는 현재 국내 방송사의 AI 자회사에 근무 중이다. 영상을 분석하는 서비스를 만드는 중. 내가 다루는 분야는 서버 개발이며, 영상이 업로드 되었을 때 분석까지 하는 전체 파이프라인을 구성중에 있다.
django + ninja api를 이용한 대략적인 서버 개발은 5~6월간 마무리를 했고, 현재 작업중인 부분은 업로드된 영상을 후에 파이프라인을 하는 과정을 작업중이다. 작업 중에 만난 문제를 공유하기 위해 글을 쓰는 중.
현재 상황
서버에서 s3에 영상을 multipart로 올릴 수 있도록 로직을 구현해 두었다. 아래 도식은 대략적인 파이프라인을 그린 figjam board이다.

이 로직을 기반으로 클라이언트가 영상을 모두 올리고 나면, 클라이언트는 서버에 영상이 다 올라갔다고 알린다. azure에서 호스팅 중인 서버는 s3에 업로드 완료 신호를 보내고, 이 때 s3에 객체가 생성이 된다. 저 도식을 그릴 때에는 object storage를 local nas에 minIO를 띄워 두어서 그걸 이용했기 때문에, minIO 자체의 web hook 기능을 이용했었다(lambda라는 서비스를 모르기도 했고). 서비스 배포 직전에 도달한 상황이라서 사내 네트워크를 이용해서 들어오는 것을 막기 위해 S3를 사용하게 됨으로써 lambda를 이용하여 함수를 트리거 하기로 했고, 결과적으로 나는 이 객체 생성을 트리거로 삼아 두 가지 일을 수행해야 한다.
- FFprobe를 이용하여 영상의 메타데이터 추출
- mp3 파일만 추출하여 s3에 객체 생성
설계 시도
우선 lambda를 처음 사용해보는 것이므로 aws 공식 docs를 많이 참조하려고 했다. 정확히 내가 원하는 일을 보여주는 docs가 있었다.
https://docs.aws.amazon.com/ko_kr/lambda/latest/dg/with-s3-example.html

특히 3번의 방법을 자세히 알아보았고, 자습서가 깔끔하고 자세하게 설명이 되어있어서 따라가는 데에 전혀 지장이 없었다.
그대로 따라해서 lambda fucntion을 triggering 한 obejct의 정보를 어떻게 가져오고 접근하는 지 방법을 익혔다. 다른 점이라면 multipart upload 시에만 함수가 실행되어야 해서 그 부분만 변경하였다.
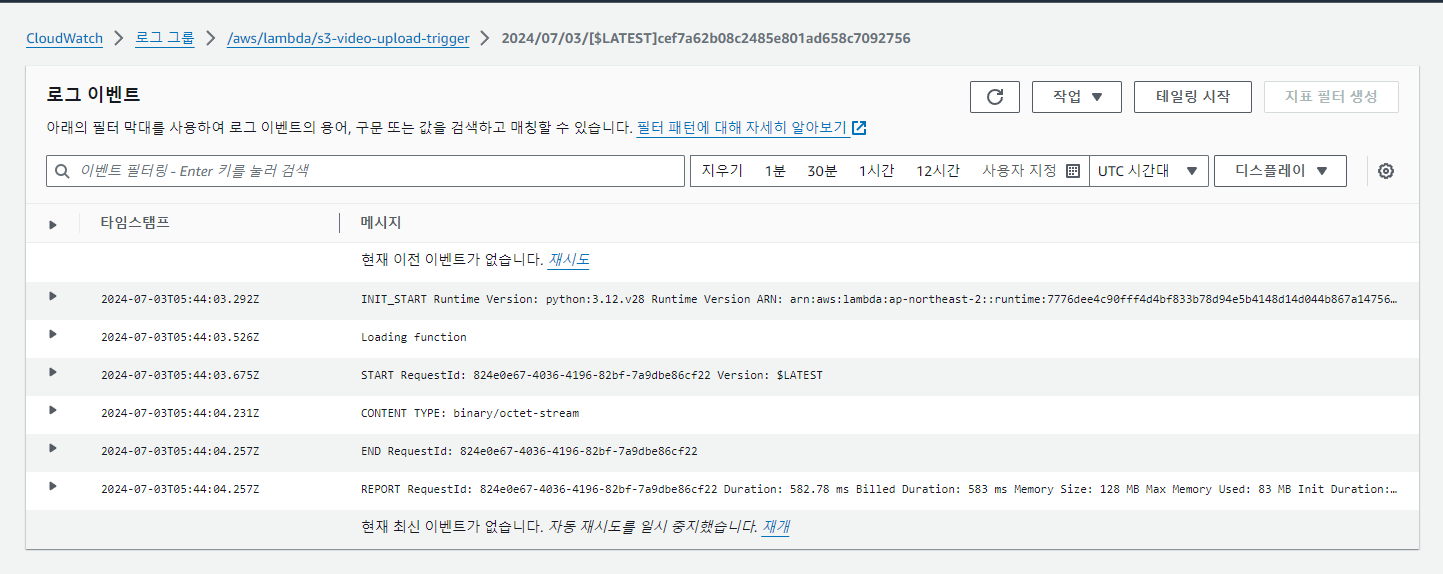
자습서에서 제공하는 코드는 event를 발생시킨 object의 bucket과 key를 제공받는 법과, 이를 통해 s3 object에 접근하여 타입을 알려주는 테스트 코드이다. 이를 cloud watch log에서 제대로 실행됨을 확인했다.
이제 이를 기반으로 내가 원하는 mp3 파일 추출과 서버에 업로드 완료 알림을 구현해보겠다.
두 일은 한 번의 function 안에 묶어 줄 것이고, 우선적으로 해결해주어야 할 부분은 업로드 완료를 서버에 알리는 것이다. 그래야 서버에서 업로드가 완료되었다는 사실을 알고 이제 영상 분석에 들어갔음을 보드에 알려줄 수 있기 때문이다.
amazon 자체 docs에서 제공한 코드에서는 get_object를 이용해서 객체에 접근하는 방식이었으나, 서비스에서 ffmpeg 라이브러리의 probe 함수를 이용해서 video의 meta data를 추출하는 방식이고, 해당 방식의 인자로 객체의 위치 정보가 필요하므로 url 형태로 접근할 수 있어야 했다. 그래서 presigned url을 발급받고 이를 인자로 넘겨 meta data를 추출하는 방식으로 구현했다.
그래서 이런식으로 구현했다.
- lambda에서 event 발생시킨 객체 정보를 이용하여 video presigned url 생성
- presinged url을 이용하여 video meta data 추출
- 서버 api 호출
- 서버에서 metadata db에 저장
문제 상황 및 해결
서버 api는 단순 meta data를 저장하는 함수이기에 간단하게 구현했는데, 하다보니 문득 “lambda 에서는 의존성 설치를 안해도 될까..?” 라는 고민이 들었다. 찾아보니 layer라는 것을 이용해서 미리 구성해두는 것 같았다.
zip 파일을 이용해서 의존성을 포함하고 있는 파일을 추가하고 해당 layer를 function에 묶어주는 식으로 해결하는 방식이었다. aws docs보다 더 잘 정리해둔 레포가 있어서 해당 레포를 참조해서 해결하려 했다.
https://ottl-seo.tistory.com/181
추가해주어야 하는 layer는 requests, ffprobe, ffmpeg 이렇게 세 가지 였고, 위의 레포에서 설명해주는 방식으로 layer를 추가했지만 lambda function에서는 계속 ffprobe, ffmpeg을 찾을 수 없다는 메시지를 반환했다.
이유는 ffmpeg python library가 래퍼 라이브러리이기 때문이었고, lambda function은 래퍼 라이브러리를 이용해서 layer를 추가하는 방식은 지원하지 않는 것이었다. 그래서 static version의 ffmpeg과 ffprobe를 내려받아서 작업하기 위해 aws에서 다른 글을 찾았다.
https://aws.amazon.com/ko/blogs/media/analyzing-media-files-using-ffprobe-in-aws-lambda/
ffmpeg과 ffprobe가 binary 파일이 분리되어 있다는 사실도 이걸 내려 받아 보면서 알았고 (...) 이를 각각 layer로 올려 작업을 해야한다는 것도 오랜 시행착오 끝에 알게 되었다.
해당 레포를 보고서 따라해도 해결이 되지 않아서 5일 정도 고생을 했는데(FFprobe 버전도 낮춰보고, 참조 방식, 함수 사용 방식 모두 변경해보았다.), 해결책은 lambda python runtime의 버전을 낮추는 것이었다. python latest 버전을 이용하면 ffmpeg과 ffprobe를 실행하는데에 오류가 발생한다. ffmpeg의 로그가 그렇게 썩 친절하지 않아서 많이 애를 먹었다. (Result code가 -11이라는 단서 말고는 아무것도 제공해주지 않았다 ㅠㅠ)
물론, 쓸모없는 시행착오는 아니었다. 과정에서 버전 문제 말고도 다른 몇 가지 서비스의 구조적 문제를 해결했다.
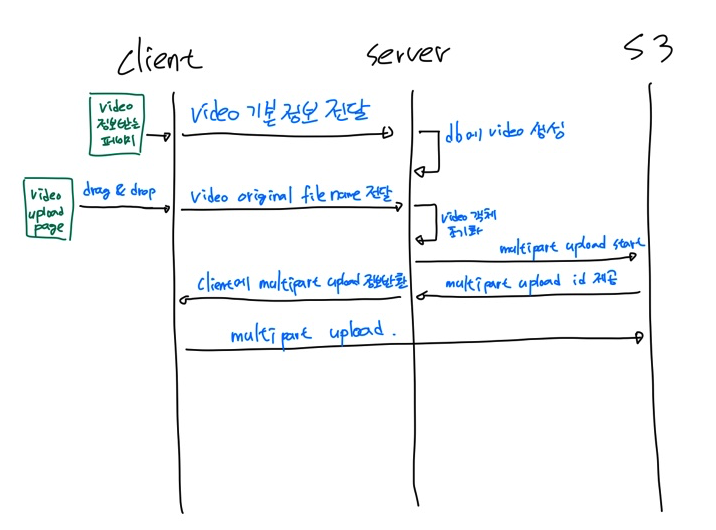
현재 우리 서비스는 비디오를 저장할 때 다음과 같은 흐름을 가지고 있다.
- 유저가 video가 속해야할 clip과 board에서 표시하기 싶은 video name 등 유저가 선택할 수 있는 데이터들을 작성하여 request를 요청한다.
- 서버는 request를 받고 해당 video의 고유 uuid를 생성하고, 이를 primary key로 하는 db entity를 생성한다. 그리고 생성한 uuid를 s3의 key 값으로 저장할 수 있는 multipart upload id를 발급하여 client에 제공한다.
- client는 유저에게 보여주는 화면을 drag & drop을 진행하는 화면으로 변경하고, 유저는 해당 웹 페이지에 video를 drag & drop을 던져 넣는다. 그러면 client가 multipart upload를 통해서 s3에 video를 업로드 한다.
이 과정을 거치면서 s3에는 uuid를 key로 하는 비디오 객체가 저장이 되게 되는데, 이렇게 되면 영상의 파일 확장자를 확인할 수 없고, probe는 파일의 형식을 추론할 때 반드시 파일 확장자를 이용한다는 점이 문제였다. 이 문제는 어제 고민하던 original filename을 어떻게 받지? 라는 고민과 연관되는 문제이다. 우리는 drag & drop이 될 때 original filename과 확장자를 알 수 있으므로, 해당 타이밍에 서버 api를 호출하도록 pipeline을 변경하기로 했다. 구조화한 파이프라인은 아래와 같다.
더 고민해 볼만한 것들
하지만 여전히 문제는 존재한다. lambda 함수의 temporary 저장소의 크기가 최대 10GB까지 설정이 가능하고, 이는 동적으로 설정할 수 있는 것이 아닌 고정 값으로 설정을 해야하는데, 영상 파일을 다운로드 하기 위해 고정으로 크게 설정해두면 작은 영상을 올릴 때에도 필요하지 않은 리소스를 사용하여 비용을 지불해야 하는 문제가 있다.
가장 좋은 해결책은 s3 - lambda - ec2 를 하나의 vpc안에 설정하여 내부에서만 네트워크가 흐르게 만든 후, ec2 에서 영상 분석을 하게 하는것이다.
우선은 가격 정책을 살펴보았는데 그렇게 데미지가 크지 않다고 판단되었다.
lambda에서 ap-northeast-2 region에 임시 스토리지 비용을
기가비트-초당 0.0000000352 USD
으로 책정 중인데, 이를 원화로 환산(1300원 가정)하고 5GB를 5분간 사용한다고 가정하면
0.06864 원
정도의 비용이 예상된다. 이러한 영상이 하루에 10,000개 올라온다고 하면 일당 680원 정도의 비용이 예측된다. 현재 ffprobe/ffmpeg 모두 의존성을 api server에서 제거하고 lambda에서 작업하도록 변경하였고, 임시 스토리지의 경우에는 가격 환산해보고 무리가 되지 않을 정도의 선으로 2GB로 확장해 두었다. (시간제한 10분)
하 여튼 이제 python 버전을 낮추어 ffprobe도, ffmpeg도 모두 lambda에서 진행 가능. 최종 코드는 아래와 같다.
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: Apache-2.0
import json
import urllib.parse
import boto3
import os
import subprocess
import requests
print('Loading function')
s3 = boto3.client('s3')
def get_presigned_url(bucket: str, key: str):
url = s3.generate_presigned_url(
'get_object',
Params={
'Bucket': bucket,
'Key': key,
},
ExpiresIn=3600
)
return url
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
object_url = get_presigned_url(bucket, key)
except Exception as e:
print(e)
raise(e)
try:
video_meta_data = subprocess.run(['/opt/bin/ffprobe', '-loglevel', 'error', '-show_streams', object_url, '-print_format', 'json'], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
except Exception as e:
print('video meta data error')
raise(e)
video_meta_data_decoded = json.loads(video_meta_data.stdout.decode()).get('streams', [])
if video_meta_data.returncode == 0:
payload = {}
for init in video_meta_data_decoded:
if init["codec_type"] == "video":
for ke, value in init.items():
if ke in ["duration", "duration_ts", "width", "height", "nb_frames"]:
payload[ke] = str(value)
data = {
'file_size': event['Records'][0]['s3']['object']['size'],
'duration': float(payload.get('duration', 0)),
'duration_ts': int(payload.get('duration_ts', 0)),
'width': int(payload.get('width', 0)),
'height': int(payload.get('height', 0)),
'nb_frames': int(payload.get('nb_frames', 0))
}
requests.post(f'url/{key.split(".")[0]}', json=data)
input_path = f'/tmp/{key}'
output_path = f'/tmp/{key.split(".")[0]}.mp3'
try:
s3.download_file(bucket, key, input_path)
except Exception as e:
print(f"Error downloading file from S3: {e}")
raise(e)
try:
subprocess.call(['ffmpeg', '-i', input_path, output_path])
except subprocess.CalledProcessError as e:
print(f"Error converting video to mp3: {e}")
raise(e)
except Exception as e:
print(f"Unexpected error during conversion: {e}")
raise(e)
try:
s3.upload_file(output_path, 'mp3-bucket-name', f'{key.split(".")[0]}.mp3')
except Exception as e:
print(f"Error uploading mp3 to S3: {e}")
raise(e)