
신기술 스터디를 시작했다. 이를 위해서 첫 주차에 어떤 주제로 발표를 할까 고민하다가 졸업프로젝트를 kubernetes로 하기도 해서 다시 공부할 겸 kubernetes를 주제로 잡았다. 관련해서 최근에 토스에서 진행한 컨퍼런스가 있어서 준비해 봤다.
https://youtu.be/WdikCm_CYms?si=wr_MPFqGbn5NFSVl
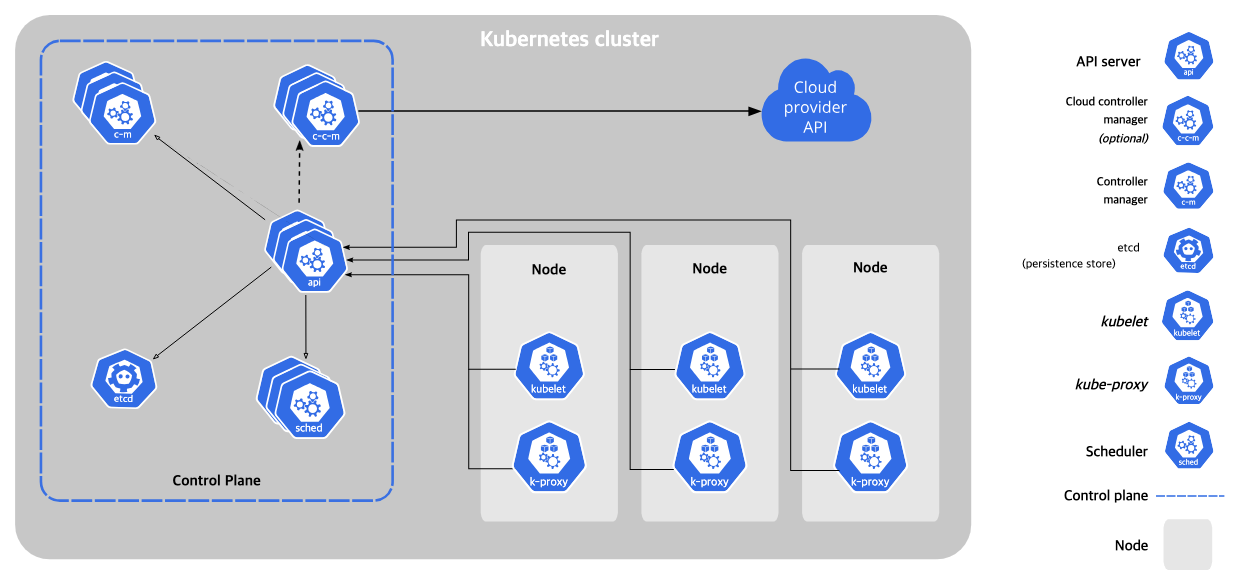
쿠버네티스란?
쿠버네티스는 인프라를 가상화해주는 도구이다. docker container 환경에서 개발하는 트렌드가 도래하고 개발자들은 컴퓨터 내에 가상화된 환경에서 프로세스를 관리하는 것에 익숙해졌다. 이를 인프라 단위로 가상화하여 관리하기 위해 나온 기술이 쿠버네티스.
개발자들은 쿠버네티스를 통해 어떤 물리적인 장치에 container가 실행되고 있는지 관심을 갖지 않아도 되고, 인프라 자원을 어떻게 효율적으로 사용할 지 크게 관심을 갖지 않아도 이를 적당히 효율적으로 처리해주기 때문에 이를 활용해 왔다.
Node란?
쿠버네티스(Kubernetes)에서 노드(Node)란, 실제 애플리케이션이 실행되는 서버(가상 머신 또는 물리 서버)를 의미한다. 클러스터에 속한 하나의 단위로서, 파드(Pod)가 배포되고 실행되는 장소이다.
쿠버네티스는 크게 master node와 worker node로 나뉘어서 일을 한다.
- master node: 클러스터의 제어판(Control Plane), 스케줄링/클러스터 관리 수행
- worker node: 실제로 파드가 배포되고 컨테이너가 실행되는 서버
워커 노드(Worker Node)의 구성 요소
| 구성 요소 | 역할 |
|---|---|
| kubelet | API 서버에서 전달받은 파드 명세에 따라 컨테이너 런타임에게 컨테이너 생성/삭제 명령 수행. 파드 상태를 주기적으로 보고하고 헬스체크도 수행함. |
| 컨테이너 런타임 (containerd, Docker 등) | 실제 컨테이너를 실행하는 엔진. kubelet의 명령을 받아 파드 내부 컨테이너를 실행함. |
| kube-proxy | 클러스터 내부 네트워크 트래픽을 라우팅하고 로드밸런싱, 포트포워딩, NAT 등을 처리함. |
| 운영체제 (Linux 등) | 위의 컴포넌트들이 실행되는 기반 환경 역할. 주로 리눅스 기반 운영체제 사용. |
마스터 노드(Control Plane Node)의 구성 요소
| 구성 요소 | 역할 |
|---|---|
| kube-apiserver | 클러스터의 중심이 되는 API 서버로, 모든 구성 요소와 통신하는 진입점. kubectl, kubelet 등이 이 API를 통해 명령 전달. |
| kube-scheduler | 새로 생성된 파드를 적절한 워커 노드에 할당하는 역할. 노드의 리소스 사용량, taint/toleration, affinity 등을 고려함. |
| kube-controller-manager | 다양한 컨트롤러(ReplicaSet, Node, Endpoints 등)를 실행시켜 실제 상태를 원하는 상태로 맞춤. |
| etcd | 클러스터의 모든 상태 정보를 저장하는 키-값 저장소. 고가용성을 위해 분산 환경으로 구성 가능. |
| cloud-controller-manager (선택) | 클라우드 벤더(AWS, Azure 등)의 리소스와 쿠버네티스 클러스터를 연동해주는 컴포넌트. 클라우드 환경에서만 사용. |
Pod란?
Pod는 Kubernetes에서 가장 작은 배포 단위이다. 하나 이상의 컨테이너가 공통 네트워크와 저장소를 공유하면서 함께 실행되는 단위.
Pod의 네트워크 특징
- 각 Pod는 고유한 IP 주소를 가짐.
- 같은 Pod 내의 컨테이너끼리는 localhost로 통신 가능.
- 다른 Pod와 통신하려면 Service 리소스를 이용.
Pod의 특징 정리
| 항목 | 설명 |
|---|---|
| 최소 배포 단위 | Kubernetes에서 컨테이너를 직접 다루지 않고 Pod로 다룸 |
| 공유 리소스 | 네트워크 네임스페이스, Volume 등 공유 |
| 컨테이너 수 | 보통 하나, 필요 시 여러 개도 가능 (예: 사이드카 패턴) |
| 생성 방식 | Pod, Deployment, DaemonSet, Job 등을 통해 생성 |
Kubernetes에서 Pod에 CPU 자원 할당하기
Kubernetes는 Pod에 대해 CPU와 메모리 리소스를 요청(request)/제한(limit)할 수 있도록 지원한다.
스케줄링과 리소스 제어를 위해 다음 두 가지를 설정:
리소스 설정 종류
| 설정 항목 | 설명 |
|---|---|
resources.requests.cpu | 스케줄러가 노드에 파드를 배치할 때 고려하는 최소 CPU량. 이 값만큼 노드에 여유가 있어야 파드가 스케줄됨. |
resources.limits.cpu | 파드가 사용할 수 있는 최대 CPU량. 이 값을 초과하면 쓰로틀링이 발생할 수 있음. |
YAML 예시
apiVersion: v1
kind: Pod
metadata:
name: cpu-example
spec:
containers:
- name: app
image: my-app
resources:
requests:
cpu: "500m" # 0.5 코어 요청
limits:
cpu: "1" # 최대 1코어 사용 가능CPU Throttling 해결하기
CFS (Completely Fair Scheduler)란?
CFS(Completely Fair Scheduler)는 리눅스 커널의 기본 CPU 스케줄러로, 실행 중인 프로세스들에게 공정하게 CPU 시간을 분배하는 것을 목표로 한다.
주요 특징
| 항목 | 설명 |
|---|---|
| 기본 스케줄러 | 대부분의 리눅스 시스템에서 기본적으로 사용되는 스케줄러 (SCHED_OTHER) |
| 공정성(Fairness) | 각 프로세스가 CPU를 사용할 수 있는 기회를 최대한 균등하게 분배 |
| 가중치 기반 분배 | 프로세스의 nice 값에 따라 CPU 분배 비율이 달라짐 |
| 레드-블랙 트리 사용 | 실행 가능한 프로세스를 정렬해 효율적인 스케줄링 수행 (O(log N)) |
| vruntime 사용 | 각 프로세스가 사용한 CPU 시간을 추적하여 덜 사용한 프로세스에게 우선권 부여 |
작동 방식 요약
- 모든 runnable 프로세스를 레드-블랙 트리로 관리
- 가장 작은
vruntime을 가진 프로세스를 선택해 실행 - 실행 시간만큼
vruntime증가 → 트리 재정렬 - 덜 실행된 프로세스에게 다시 CPU 우선권 부여
CFS와 Kubernetes
- Kubernetes는 직접 CPU 스케줄링을 하지 않음
- kubelet은 CFS 설정을 cgroup을 통해 간접 제어함
cpu.cfs_period_uscpu.cfs_quota_us
- 각 파드/컨테이너가 사용할 수 있는 CPU 시간 제한 설정 가능
관련 설정 (cgroup 기반)
| 설정 항목 | 설명 |
|---|---|
cpu.cfs_period_us | CFS 주기 (기본값: 100,000μs = 100ms) |
cpu.cfs_quota_us | 주기당 사용할 수 있는 최대 CPU 시간 |
예: 0.5코어만 쓰게 하려면 → quota = 50000, period = 100000
Cfs scheduler 때문에 진짜 kubernetes cpu 활용도가 떨어질 수 있을까?
이를 알아보기 위해 실제로 실험해보았다. m1 mac 환경에 minikube를 설치하고 grafana와 promethus를 통해 stress test의 결과를 직접 지켜보았다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-burst
namespace: stress-test
spec:
replicas: 1
selector:
matchLabels:
app: stress-burst
template:
metadata:
labels:
app: stress-burst
spec:
containers:
- name: stress
image: alpine
command: ["/bin/sh"]
args:
- "-c"
- |
apk update && apk add --no-cache stress-ng && \
echo "Burst testing..." && \
while true; do \
stress-ng --cpu 4 --timeout 2; \
sleep 5; \
done
resources:
limits:
cpu: "500m"
requests:
cpu: "200m"ng-stress를 통해서 빠르게 50ms의 cpu time을 모두 활용하게 해보았다.
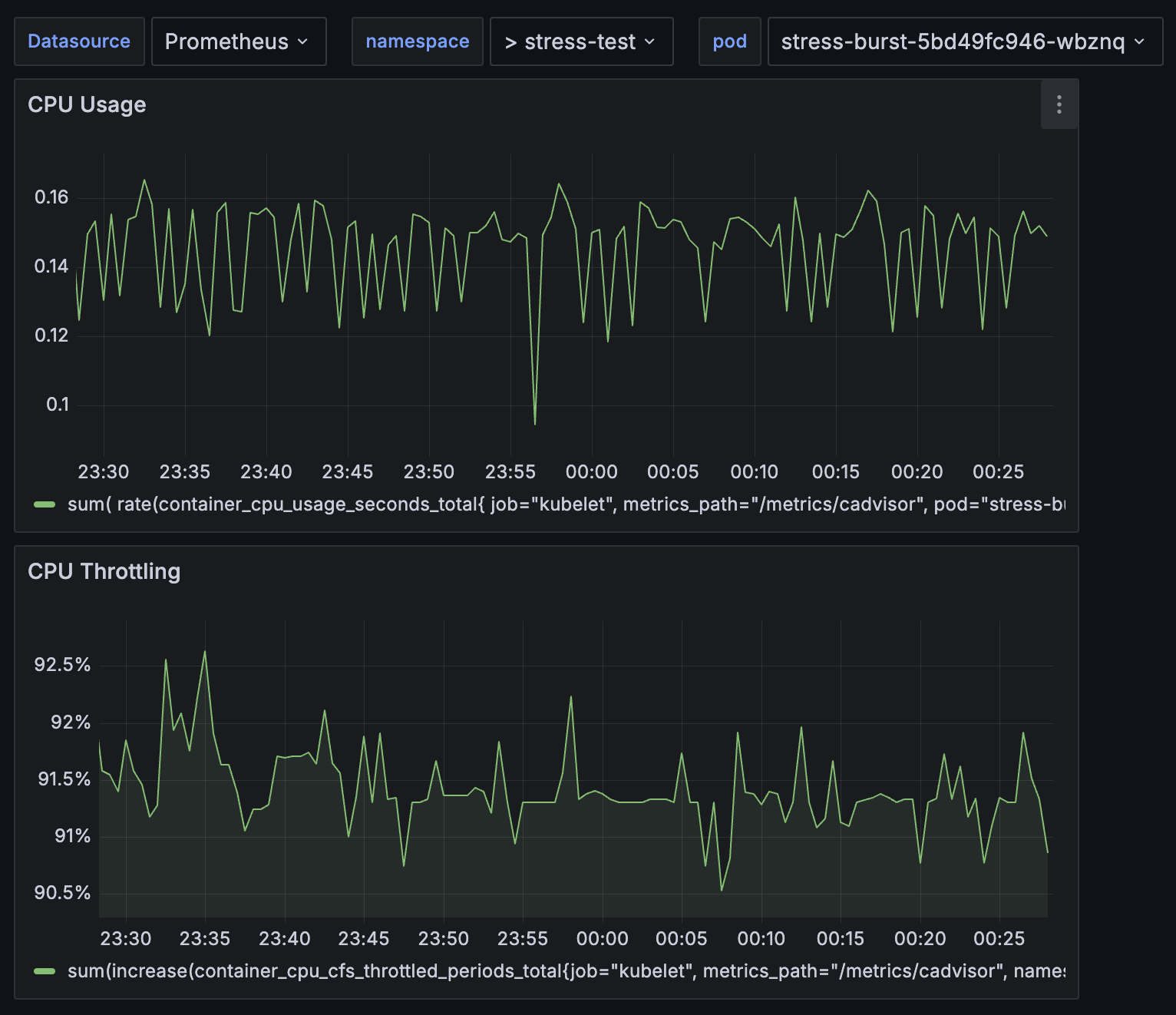
실제로 cpu사용량이 50%까지 가지 못하는 모습을 볼 수 있었다.
이를 해결하기 위해 영상에서 두 가지 해결책을 제시했다
- 완화: cfs quota period를 낮추자
- 방지: cfs quota 기능 비활성화 / no limit
Cfs quota period를 낮추면 어떻게 될까?
quota를 줄이면 한 번에 쓸 수 있는 시간은 줄지만, 쓰로틀 시간이 짧아져서 더 빨리 다시 실행될 수 있음
→ 오히려 idle 시간 감소 + context switching 증가
→ 결과적으로 CPU 활용률이 올라갈 수도 있음
예시 비교
| 설정 | 의미 | 결과 |
|---|---|---|
quota = 50ms, period = 100ms | 50ms 일하고 50ms 쉬는 구조 | 50% 활용, idle 시간 많음 |
quota = 25ms, period = 50ms | 25ms 일하고 25ms 쉬는 구조 | 더 자주 실행됨 → idle 시간 줄어듦 |
어떤 경우에 활용률이 올라가는가?
| 조건 | 이유 |
|---|---|
| 워크로드가 짧고 반복적일 때 | 짧게 자주 실행되며 쓰로틀 대기 시간 짧아짐 |
| 쓰로틀 주기(period)가 짧을 때 | 재실행까지 기다리는 시간이 짧아짐 |
| 다수의 파드가 경쟁적으로 CPU를 쓸 때 | 작은 quota로도 자주 기회가 돌아와 효율적 사용 가능 |
주의할 점
| 항목 | 설명 |
|---|---|
| context switching 오버헤드 | 너무 자주 스케줄되면 오히려 오버헤드 증가 가능 |
| 긴 연산엔 부적합 | 작업 중간에 끊기면 latency 증가 가능 |
| workload 특성 따라 다름 | I/O 위주인지, CPU bound인지 따라 전략 달라져야 함 |
결론
사실 이것도 실험해보고 싶었으나, kubelet 설정을 건드리는 것이 local 환경에서 container driver 문제로 충동이 일어나는 것 같았다. minikube와 kind환경 모두에서 정상적으로 control plane이 뜨지 않는 오류가 발생해서 확인하지 못했다.
quota를 줄이면 응답성이 좋아지고, 경우에 따라 CPU 활용률도 더 높아질 수 있다.
단, 이는 workload 특성에 따라 달라지며, 적절한 tuning과 실험이 필요하다.
병렬성 문제
병렬성 문제란, 각 컨테이너들이 프로세스를 실행할 때 worker node의 모든 resource를 사용할 수 있다고 믿어서 발생한다. worker node의 core개수가 8개라고 했을 때, 병렬처리하는 과정에서 8개의 코어를 다 쓸 수 있다고 생각한다.
하지만 pod 설정에서 limit가 1core라면 실제 사용할 수 있는 자원은 한 peirod에 100ms만 사용할 수 있다. 8개면 800ms 를 사용할 수 있어야 한다.
그래서 스레드 하나당 12ms 정도만 일을 하고 모두 쓰로틀이 발생해버리는 문제가 발생한다. 이를 위해서 병렬성 library를 사용할 때 자원을 인식하는 것을 개발자가 조절해 주어야 한다.
