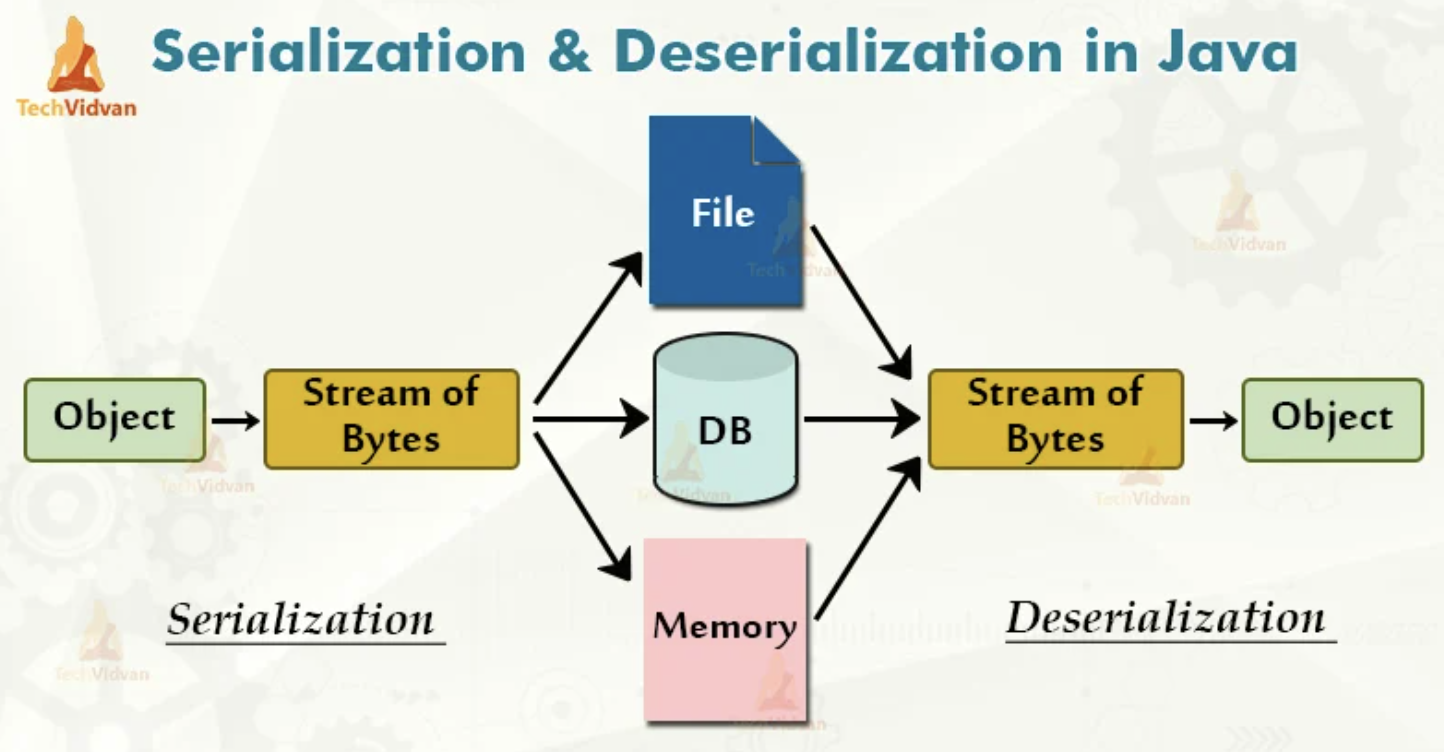
직렬화와 역직렬화의 정의
직렬화
객체들의 데이터를 연속적인 데이터(스트림)로 변형하여 전송 가능한 형태로 만드는 것
역직렬화
직렬화된 데이터를 다시 객체의 형태로 만드는 것
객체 데이터를 통신하기 쉬운 포맷(Byte,CSV,Json..) 형태로 만들어주는 작업을 직렬화라고 볼 수 있고,
역으로, 포맷(Byte,CSV,Json..) 형태에서 객체로 변환하는 과정을 역직렬화라고 할 수 있겠다.
class Person{
private String name;
public Sample(String name) {
this.name = name;
}
}
위와 같은 클래스가 있다고 할 때, Json 데이터 형식을 예로 들면,
Person person = new Person("김철수"); 객체를 { "name" : "김철수"} 와 같은 방식으로 변경하는 것을 직렬화,
{ "name" : "김철수"} 데이터를 받아서 Person이라는 객체의 name 필드에 "김철수" 를 할당하고 객체를 생성하는 것을 역직렬화라고 할 수 있다.
직렬화가 필요한 이유
기본형 타입의 데이터는 stack에서 값 그 자체를 갖고 있어 외부로 데이터를 전달할 때, 값을 일정한 형식의 raw byte 형태로 변경하여 전달할 수 있으나, 참조형 타입의 데이터는 Heap 영역에 존재하고, stack 에서는 Heap 영역에 존재하는 객체의 주소값만 갖고 있다.
그런데 만약 참조값의 데이터 전송이 필요한 상황이 생겼다고 가정해보자. 그럼 위 조건대로라면 stack 영역에 있는 주소값만이 전송될 테고, 전달받은 메모리 주소에는 전송하려던 데이터가 있을 리가 없다.
따라서 이 주소값의 데이터(실체)를 값을 지니는 기본형 타입의 데이터 형식으로 변환하는 작업을 거칠 필요가 있는데, 이렇게 해야 파일 저장이나 네트워크 전송 시 파싱할 수 있는 유의미한 데이터가 된다.
파싱
어떤 큰 자료에서 원하는 정보만을 가공하여 추출하고, 분해와 분석 목적에 맞춰 구조를 결정해 원하는 때에 불러올 수 있게 하는 것으로 파싱을 수행하는 프로그램을 파서라고 부름. xml, dom, sax, json 과 같은 파싱 기법이 있음
직렬화 상황
- JVM에 상주하는 객체 데이터를 영속화할 때 사용
본디 Java에서는 프로그램이 JVM 내에서 실행되는 동안 객체가 메모리에 상주하며, 프로그램이 종료되거나 JVM이 종료되면 객체가 휘발성 메모리에 저장되므로 데이터 손실을 겪는 게 일반적이다. 그러나 직렬화를 통해, 객체 상태를 바이트 스트림으로 변환하여 파일을 저장하거나 네트워크를 통해 전송함으로써 이러한 바이트를 나중에 객체로 역질렬화하여 복원하기 때문에 영속성을 지속시킬 수 있다. - Servlet Session
웹 애플리케이션의 HTTP 요청 간에 상태 정보를 유지하는 방법이다. 세션의 지속성을 위해 직렬화를 사용하며, 나중에 서버가 다시 시작되거나 세선이 필요할 때 직렬화된 데이터를 저장소에서 읽고 역질렬화한 다음 세션 개체로 복원할 수 있다. - Cache
캐시는 일반적으로 데이터 소스(ex. 데이터베이스 또는 외부 서비스)에서 검색된 개체를 저장한다. 캐시는 객체를 직렬화함으로써 복잡한 데이터 구조를 유지할 필요 없이 메모리나 디스크에 객체를 효율적으로 저장할 수 있다. 언어간의 호환성 측면에서도 다양한 프로그래밍 언어끼리 호환시킬 수 있기 때문에 이점이 있다. - Java RMI(Remote Method Invocation)
Java RMI를 사용하여 원격 객체에서 메소드를 호출할 때 메소드에 전달된 매개변수와 반환 값은 네트워크를 통해 전송되어야 한다. 이때, 네트워크 통신에 이용되는 개체는 직렬화를 통해 바이트 스트림으로 변환되어야 하며, 반대의 경우에 역직렬화되어 반환되어야 한다.
직렬화와 역질렬화가 작동하는 예시
public class Test {
public static void main(String[] args) throws IOException, ClassNotFoundException {
Person person = new Person("김철수",19);
// 직렬화된 객체를 바이트 배열에 저장
byte[] serializedPerson;
try (ByteArrayOutputStream baos = new ByteArrayOutputStream()) {
try (ObjectOutputStream oos = new ObjectOutputStream(baos)) {
oos.writeObject(person);
// 바이트 배열로 직렬화
serializedPerson = baos.toByteArray();
}
}
// 바이트 배열로 생성된 직렬화 데이터를 base64로 변환
System.out.println(Base64.getEncoder().encodeToString(serializedPerson));
// 역직렬화
try (ByteArrayInputStream bais = new ByteArrayInputStream(serializedPerson)){
try (ObjectInputStream ois = new ObjectInputStream(bais)){
Object objectPerson = ois.readObject();
Person newPerson = (Person) objectPerson;
// 객체의 toString() 정보 불러옴
System.out.println(newPerson);
}
}
}
}
class Person implements Serializable {
String name;
int age;
public Person(String name, int age){
this.name = name;
this.age = age;
}
@Override
public String toString(){
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}직렬화 주의 사항
직렬화 serialVersionUID
직렬화 시킨 byte 배열을 그대로 갖고 있는 상태에서 Peson 클래스의 멤버 변수의 타입을 변경하거나 이름을 변경하거나 새로운 멤버 변수가 추가 되는 경우, 역질렬화 과정에서 serialVersionUID가 일치하지 않는다는 에러가 발생한다.
이는 serialVersionUID를 명시해주지 않으면 클래스의 기본 해쉬값을 사용하는데, Person 클래스에 변화를 주게 되면 serialVersionUID도 새로운 값으로 변경되며 따라서 오류가 발생했다고 볼 수 있다.
class Person implements Serializable {
private static final long serialVersionUID = 1L;
String name;
int age;위와 같이 serialVersionUID 를 명시해준 뒤, 직렬화를 다시 한 다음에 Pesron 에 새로운 멤버 변수를 추가하거나 기존에 있던 멤버 변수를 삭제하고 역직렬화를 다시 시도해도 에러가 발생하지 않는다.
직렬화의 장단점
추가적인 라이브러리의 설치가 없이 객체 데이터를 영속화시킬 수 있다. 다만, 직렬화 결과물의 용량이 상대적으로 커서 비효율적인 문제를 갖고 있으며, 자주 변경되는 데이터를 직렬화해서 보관하게 되면 나중에 변경이 생겼을 때 역직렬화가 불가능해지므로 쓸모없는 데이터가 될 수 있다는 단점이 있다.
