
1. About Subquery
하나의 SQL 문 안에 포함되어 있는 또 다른 SQL 문을 말한다.
메인쿼리가 서브쿼리를 포함하는 종속적인 관계이다.
• 서브쿼리는 메인쿼리의 칼럼 사용 가능
• 메인쿼리는 서브쿼리의 칼럼 사용 불가
Subquery 사용시 주의
• Subquery 는 괄호로 묶어서 사용
• 단일 행 혹은 복수 행 비교 연산자와 함께 사용 가능
• subquery 에서는 order by 를 사용X
Subquery 종류
• 스칼라 서브쿼리 (Scalar Subquery) - SELECT 절에 사용
• 인라인 뷰 (Inline View) - FROM 절에 사용
• 중첩 서브쿼리 (Nested Subquery) - WHERE 절에 사용
2. 스칼라 서브쿼리 (Scalar Subquery)
- SELECT 절에서 사용하는 서브쿼리.
- 결과는 하나의 Column 이어야 한다(SELECT 절에서 사용되기 때문)
SELECT column1, (SELECT column2 FROM table2 WHERE condition) FROM table1 WHERE condition;
- 예제 : 서울은평경찰서의 강도 검거 건수와 서울시 경찰서 전체의 평균 강도 검거 건수를 조회
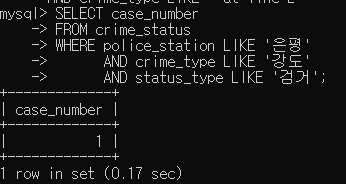
1) 서울은평경찰서의 강도 검거 건수
SELECT case_number FROM crime_status WHERE police_station LIKE '은평' AND crime_type LIKE '강도' AND status_type LIKE '검거';
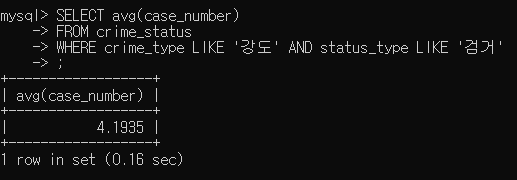
2) 서울시 경찰서 전체의 평균 강도 검거 건수
SELECT avg(case_number) FROM crime_status WHERE crime_type LIKE '강도' AND status_type LIKE '검거'
3) 전체
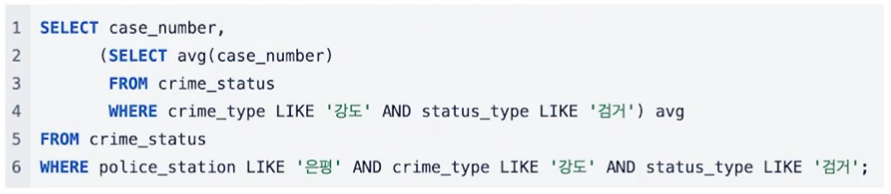
SELECT case_number, (SELECT avg(case_number) FROM crime_status WHERE crime_type LIKE '강도' AND status_type LIKE '검거') avg FROM crime_status WHERE police_station LIKE '은평' AND crime_type LIKE '강도' AND status_type LIKE '검거';

3. 인라인 뷰 (Inline View)
-
FROM 절에 사용하는 서브쿼리. 메인쿼리에서는 인라인 뷰에서 조회한 Column 만 사용가능하다.
-
쿼리가 실행된 결과 set을 하나의 table로 인식한다 (이걸 view table 이라고 한다)
SELECT a.column, b.column FROM table a, (SELECT column1, column2 FROM table2) b WHERE condition;
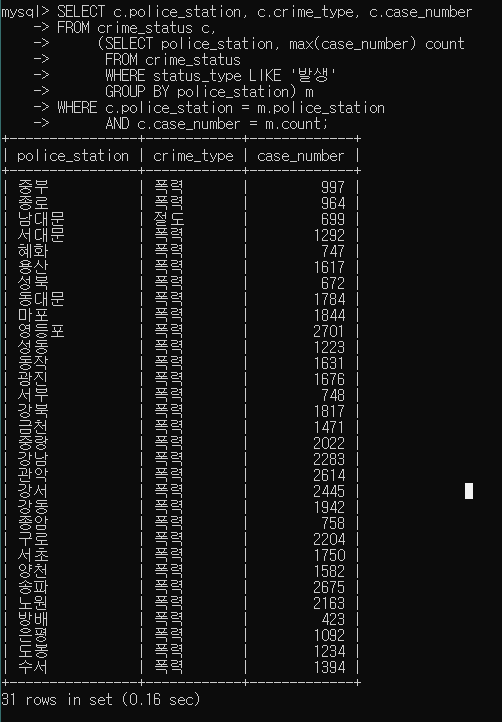
- 예제 : 경찰서 별로 가장 많이 발생한 범죄 건수와 범죄 유형을 조회
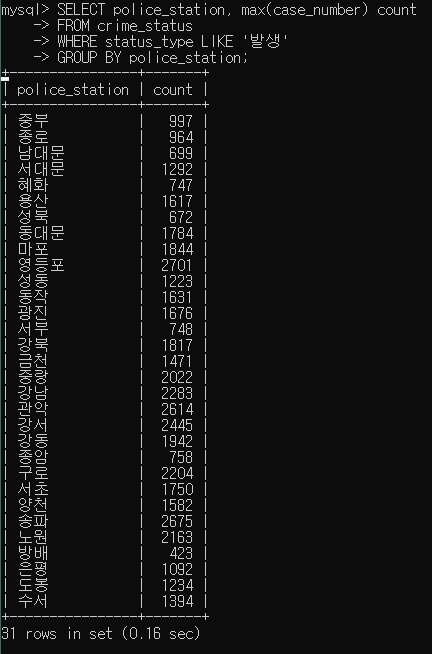
1) 경찰서 별로 가장 많이 발생한 범죄 건수
이 결과가 테이블이 되어서 (alis m)
SELECT police_station, max(case_number) count FROM crime_status WHERE status_type LIKE '발생' GROUP BY police_station;
2) 전체
SELECT c.police_station, c.crime_type, c.case_number FROM crime_status c, (SELECT police_station, max(case_number) count FROM crime_status WHERE status_type LIKE '발생' GROUP BY police_station) m WHERE c.police_station = m.police_station AND c.case_number = m.count;
4. 중첩 서브쿼리 (Nested Subquery)
WHERE 절에서 사용하는 서브쿼리.
• Single Row - 하나의 행을 검색(반환)하는 서브쿼리
• Multiple Row - 하나 이상의 행을 검색(반환)하는 서브쿼리
• Multiple Column - 하나 이상의 열을 검색(반환)하는 서브쿼리
Single Row Subquery
서브쿼리가 비교연산자( =, >, >=, <, <=, <>, !=)와 사용되는 경우,
서브쿼리의 검색 결과는 한 개의 결과값을 가져야 한다. (두개 이상인 경우 에러)
# = 등호가 있다 (비교연산자 예시) SELECT column_names FROM table_name WHERE column_name = (SELECT column_name FROM table_name WHERE condition) ORDER BY column_name;
- 예제 1. 괄호 없어서 (에러)
SELECT name FROM celeb WHERE name = SELECT host FROM snl_show;

- 예제 2. 한 개 이상의 결과 (괄호, 에러)
(하나의 row 이상이 리턴되었다.)
SELECT name FROM celeb WHERE name = (SELECT host FROM snl_show);

- 예제
SELECT name FROM celeb WHERE name = (SELECT host FROM snl_show WHERE id =1);

Multiple Row - IN
- 행이 2개 이상.
- 서브쿼리 결과 중에 포함 될때
- 목록 대신에 서브쿼리를 줌
- ~ 안에 있으면
- IN 대신에 JOIN 사용가능
# IN과 함께 사용되는 경우 SELECT column_names FROM table_name WHERE column_name IN (SELECT column_name FROM table_name WHERE condition) ORDER BY column_names;
- 예제 : SNL 에 출연한 영화배우를 조회
1) 영화배우를 조회
SELECT name
FROM celeb
WHERE job_title LIKE '%영화배우%'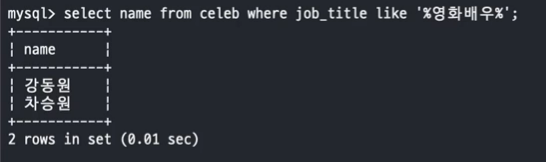
2) snl 에 출연한 영화배우
SELECT host
FROM snl_show;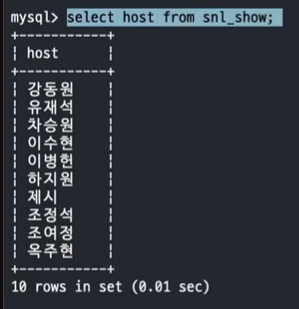
3) 전체
# IN과 함께 사용되는 경우 SELECT host FROM snl_show WHERE host IN (SELECT name FROM celeb WHERE job_title LIKE '%영화배우%');

Multiple Row - EXISTS
- 서브쿼리 결과에 값이 있으면 반환
# EXISTS 함께 사용되는 경우 SELECT column_names FROM table_name WHERE column_name EXISTS (SELECT column_name FROM table_name WHERE condition) ORDER BY column_names;
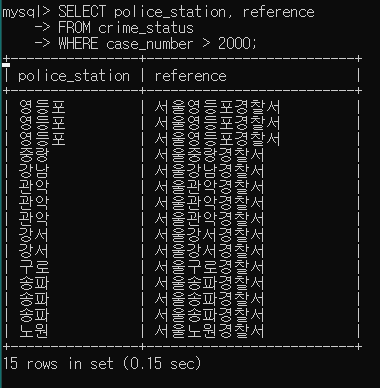
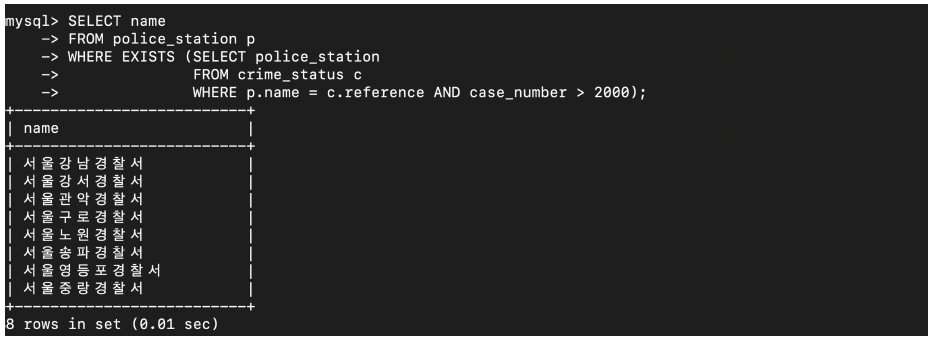
- 예제 : 범죄 검거 혹은 발생 건수가 2000건 보다 큰 경찰서 조회
1) 건수가 2000건 보다 큰 경찰서
SELECT police_station, reference FROM crime_status WHERE case_number > 2000;
2) 전체
# EXISTS 함께 사용되는 경우 SELECT name FROM police_station p WHERE EXISTS (SELECT police_station FROM crime_status c WHERE p.name = c.reference AND case_number > 2000);
Multiple Row - ANY
서브쿼리 결과 중에 최소한 하나라도 만족하면 True 리턴(비교연산자 사용)
# ANY 함께 사용되는 경우 SELECT column_names FROM table_name WHERE column_name = ANY (SELECT column_name FROM table_name WHERE condition) ORDER BY column_names;
- 예제 : SNL 에 출연한 적이 있는 연예인 이름 조회
# ANY 함께 사용되는 경우 SELECT name FROM celeb WHERE name = ANY (SELECT host FROM snl_show);

Multiple Row - ALL
서브쿼리 결과를 모두 만족하면 (비교 연산자 사용)
ANY와 달리 ALL은 모두 만족해야하므로 WHERE 조건을 붙임
# ALL 함께 사용되는 경우 SELECT column_names FROM table_name WHERE column_name = ALL (SELECT column_name FROM table_name WHERE condition) ORDER BY column_names;
- 예제 : 서브쿼리 결과를 모두 만족하면 (비교 연산자 사용)
# ALL 함께 사용되는 경우 SELECT name FROM celeb WHERE name = ALL (SELECT host FROM snl_show WHERE id = 1);

Multi Column Subquery - 연관 서브쿼리
-
Multi Column Subquery(연관서브쿼리) :컬럼 여러개를 반환하는 쿼리
-
서브쿼리 내에 메인쿼리 컬럼이 같이 사용되는 경우.

SELECT column_names FROM tablename a WHERE (a.column1, a.column2, ...) IN (SELECT b.column1, b.column2, ... FROM tablename b WHERE a.cloumn_name = b.column_name) ORDER BY column_names;
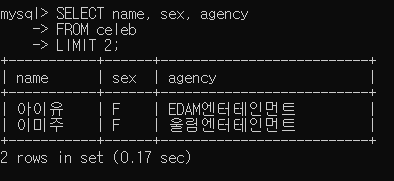
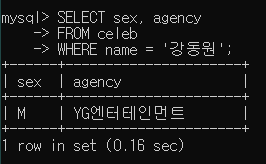
- 예제 : 강동원과 성별, 소속사가 같은 연예인의 이름, 성별, 소속사를 조회
SELECT name, sex, agency FROM celeb LIMIT 2;
SELECT sex, agency FROM celeb WHERE name = '강동원';
SELECT name, sex, agency FROM celeb WHERE (sex, agency) IN (SELECT sex, agency FROM celeb WHERE name = '강동원');

혼자서 해봅시다
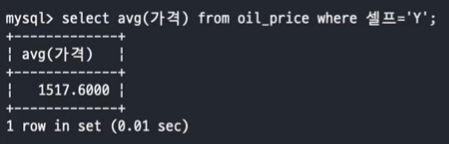
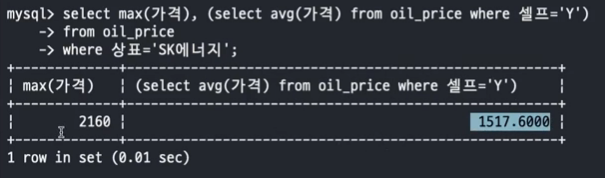
- 문제 1. oil_price 테이블에서 셀프주유의 평균가격과 SK에너지의 가장 비싼 가격을 Scalar Subquery 를 사용하여 조회
SELECT * FROM oil_price LIMIT 1;

SELECT avg(가격) FROM oil_price WHERE 셀프='Y';
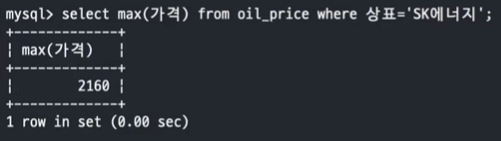
SELECT MAX(가격) FROM oil_price WHERE 상표='SK에너지';
SELECT MAX(가격), (SELECT avg(가격) FROM oil_price WHERE 셀프='Y') FROM oil_price WHERE 상표='SK에너지';
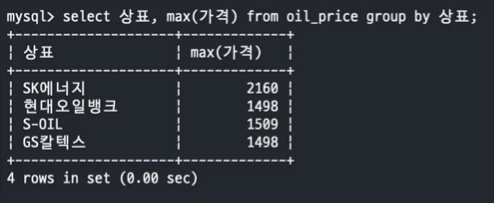
- 문제 2. oil_price 테이블에서 상표별로 가장 비싼 가격과 상호를 Inline View 를 사용하여 조회하세요.
SELECT 상표, MAX(가격) FROM oil_price GROUP BY 상표;
SELECT o.상호, o.상표, s.max_price FROM oil_price o, (SELECT 상표, MAX(가격) max_price FROM oil_price GROUP BY 상표) s WHERE o.상표 = s.상표 AND o.가격 = s.max_price;

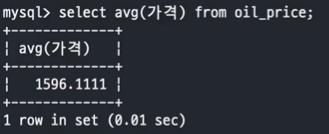
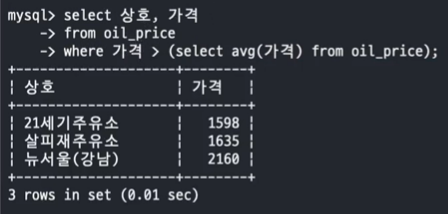
- 문제 3. 평균가격 보다 높은 주유소 상호와 가격을 Nested Subquery 를 사용하여 조회하세요.
SELECT avg(가격) FROM oil_price;
SELECT 상호, 가격 FROM oil_price WHERE 가격 > (SELECT avg(가격) FROM oil_price);
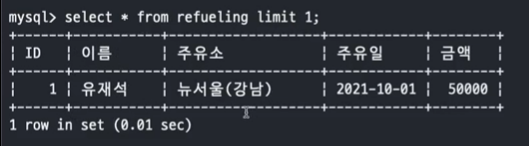
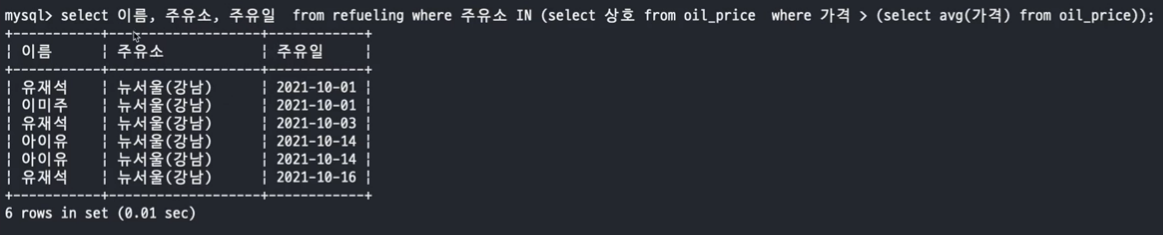
- 문제 4. 3번에서 조회한 주유소에서 주유한 연예인의 이름과 주유소, 주유일을 Nested Subquery 를 사용하여 조회하세요. (refueling 테이블)
SELECT * FROM refueling LIMIT 1;
SELECT 이름, 주유소, 주유일 FROM refueling WHERE 주유소 IN (SELECT 상호 FROM oil_price WHERE 가격 > (SELECT AVG(가격) FROM oil_price));
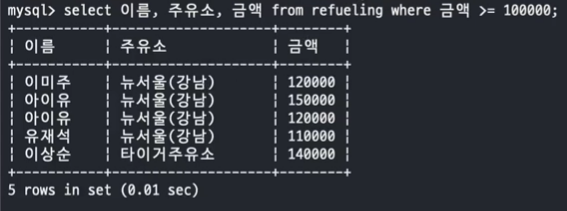
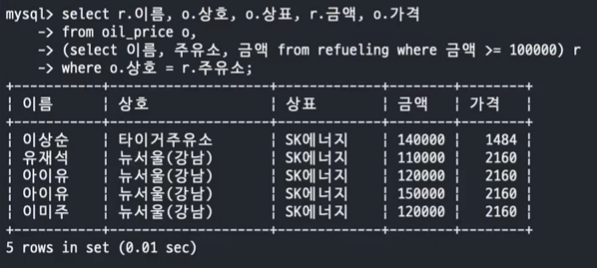
- 문제 5. refueling 테이블과 oil_price 테이블에서 10만원 이상 주유한 연예인 이름, 상호, 상표, 주유 금액, 가격을 Inline View 를 사용하여 조회하세요.
SELECT 이름, 주유소, 금액 FROM refueling WHERE 금액 >= 100000;
SELECT r.이름, o.상호, o.상표, r.금액, o.가격 FROM refueling o, (SELECT 이름, 주유소, 금액 FROM refueling WHERE 금액 >= 100000) r WHERE o.상호 = r.주유소;
위 글은 제로베이스 데이터 취업 스쿨의 강의자료를 참고하여 작성되었습니다.
