
beautifulsoup
뷰티풀 수프(Beautiful Soup)는 HTML과 XML 문서들의 구문을 분석하기 위한 파이썬 패키지이다. HTML로부터 데이터를 추출하기 위해 사용할 수 있는 파싱된 페이지의 파스 트리를 만드는데, 이는 웹 스크래핑에 유용하다.
html문서, 또는 인터넷페이지를 html 로 읽어와서 분석한다.
- beautifulsoup 설치
conda install -c anaconda beautifulsoup4
pip install beautifulsoup4
- html 기초
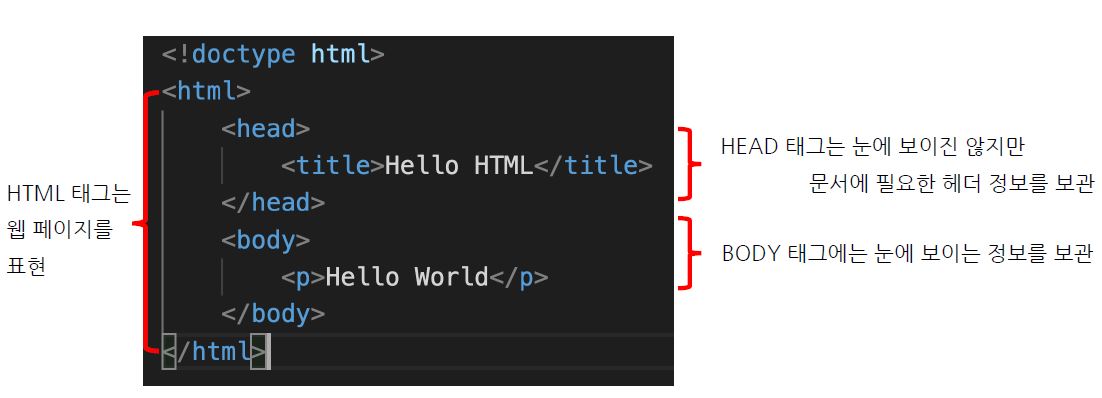
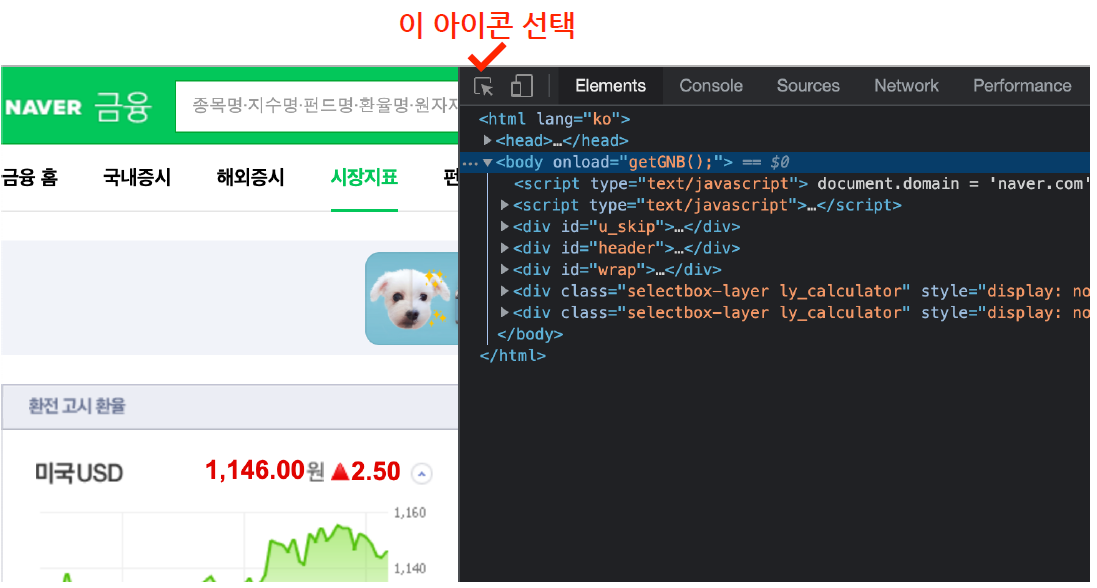
- 크롬 개발자도구
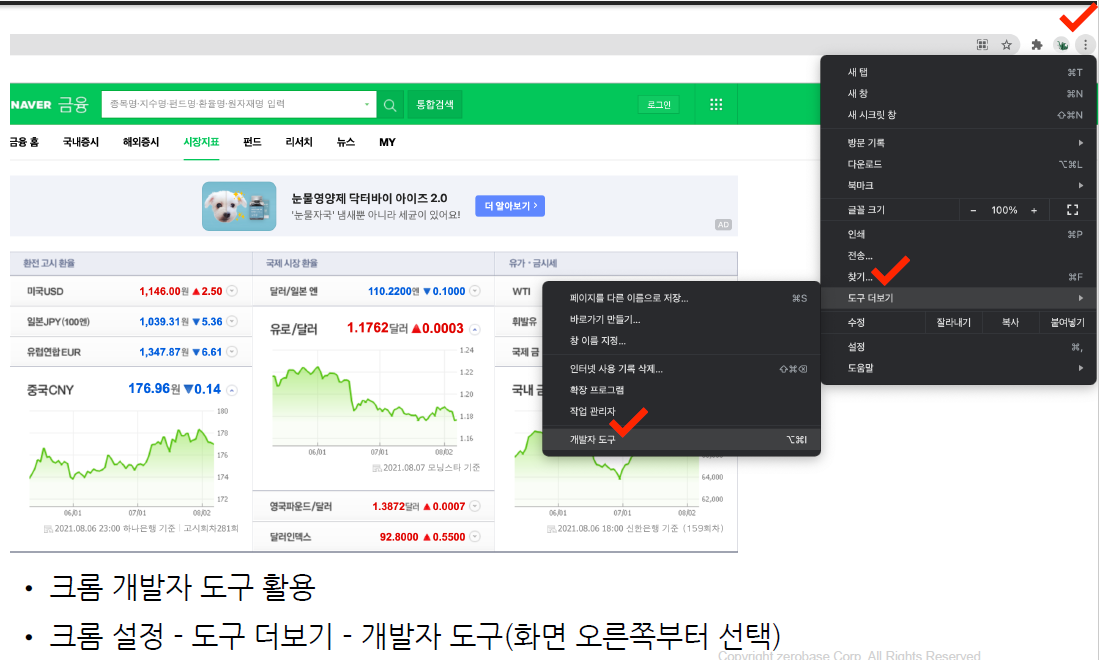
인터넷에 html을 보기위한 도구
크롬 오른쪽 상단 ... > 도구 더보기 > 개발자 도구
또는 그냥 F12

- urllib의 request 모듈
웹주소(url)에 접근할 때 필요한 모듈
- request 임포트 방법 1
# 방법 1
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://finance.naver.com/"
reponse = urlopen(url)
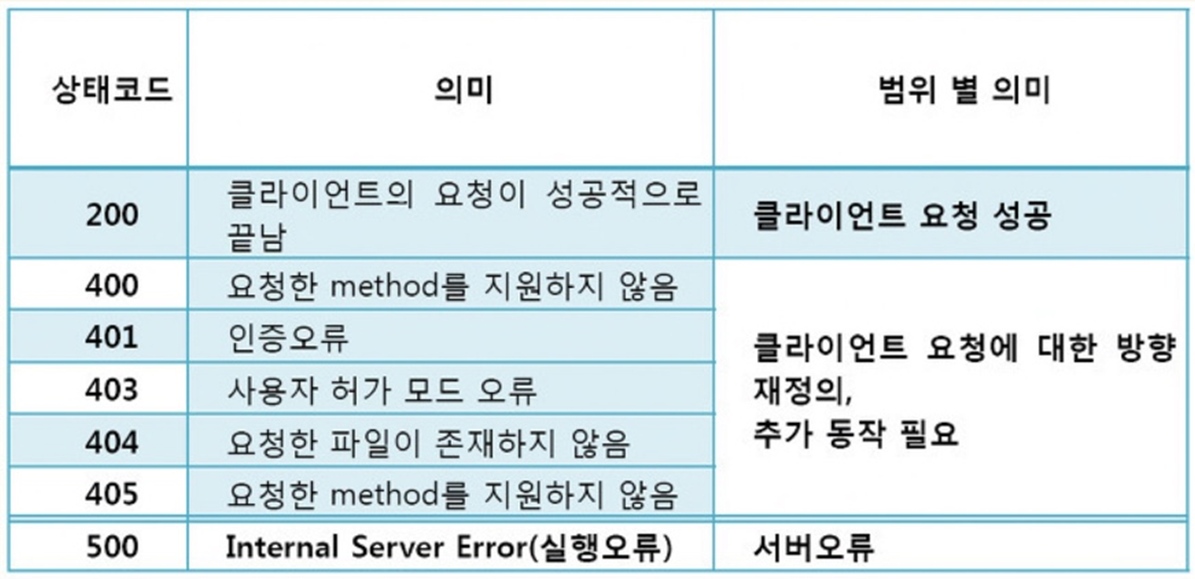
reponse.status
# 200 이라는 숫자가 정상적으로 요청을 했고, 정상적으로 받았다는 뜻
# http 상태코드라고 한다
# 번호에 따라서 웹페이지의 상태를 나타낸다
# 그 번호에 따라서 나의 잘못인지, 서버오류인지 등을 알 수 있다.
>>
200- request 임포트 방법 2
# 방법 2
import requests
# from urllib.request.Request
# 위 requests 와 기능은 똑같다고는 하는데,
# from urllib.request.Request 는 실행하면 에러남
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
reponse = requests.get(url)
# requests.get()
# requests.post()
# 두가지 방식이 있지만 설명은 안해줌
reponse
>> <Response [200]>
------------------------------------------------------
reponse.text
>> '\n<script language=javascript src="/template/....
------------------------------------------------------- HTTP 상태코드(200이 정상이다)
beautifulsoup 기초
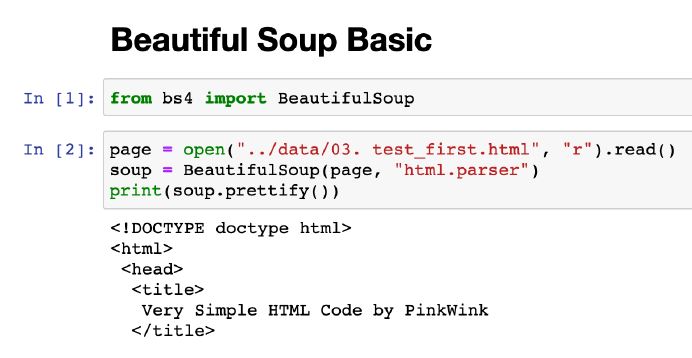
- import
# import
from bs4 import BeautifulSoup• 파일로 저장된 html 파일을 읽을 때
• open : 파일명과 함께 읽기(r) / 쓰기(w) 속성을 지정
• html.parser : Beautiful Soup의 html을 읽는 엔진 중 하나(lxml도 많이 사용)
• prettify() : html 출력을 이쁘게 만들어 주는 기능
- html 데이터 가져오기
- 컴에서 가져오기
from bs4 import BeautifulSoup
page = open("../data/03.zerobase.html", "r").read()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
- 웹에서 가져오기
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://finance.naver.com/"
reponse = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())데이터 추출하기(태그 가져오기)
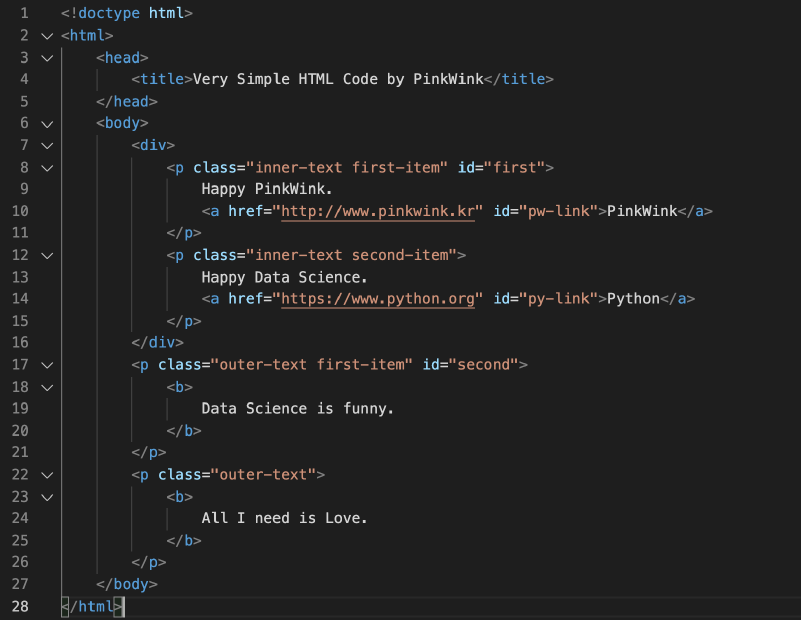
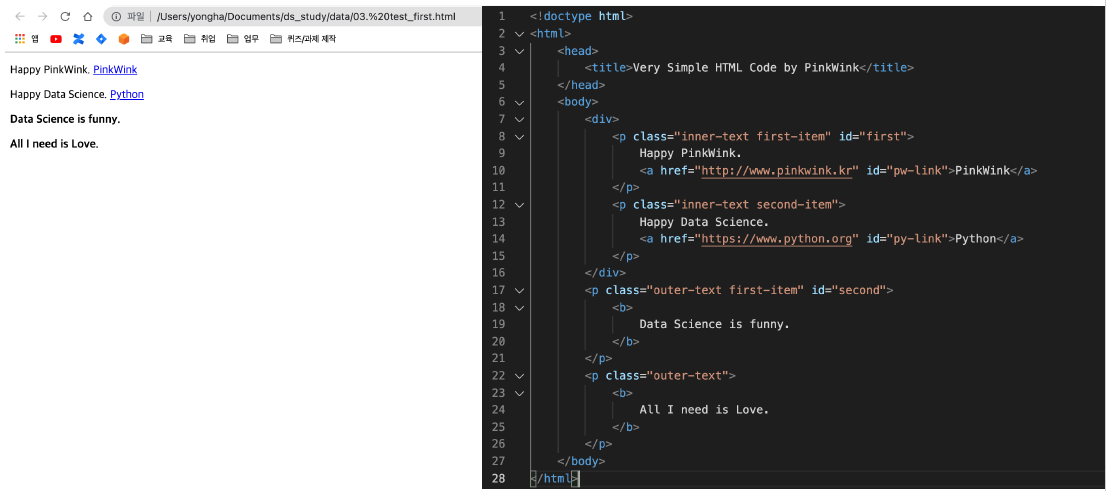
- 예제 html ( soup = BeautifulSoup(page, "html.parser") )
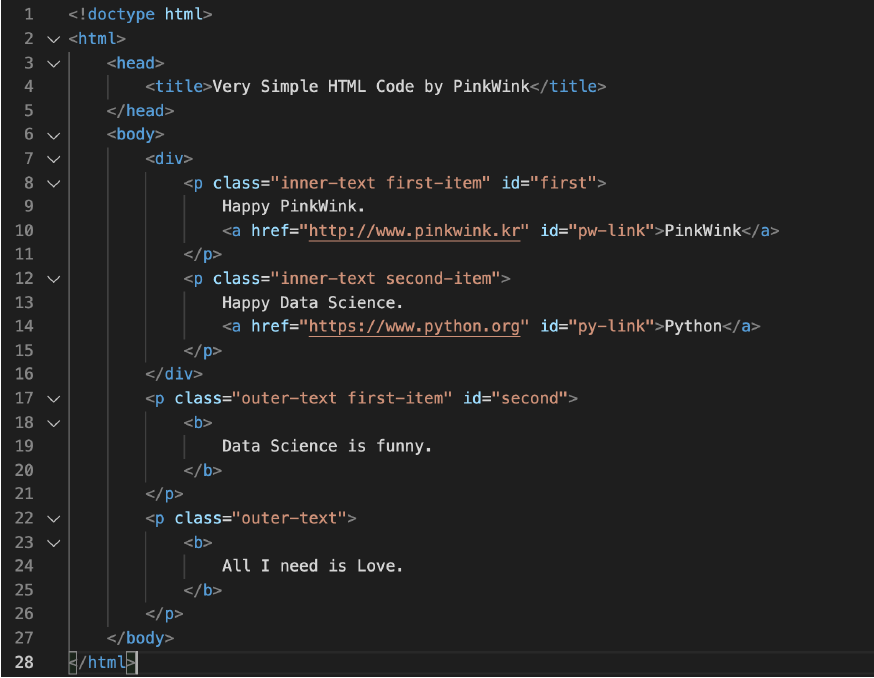
- head 태그 확인
soup.head
- body 태그 확인
soup.body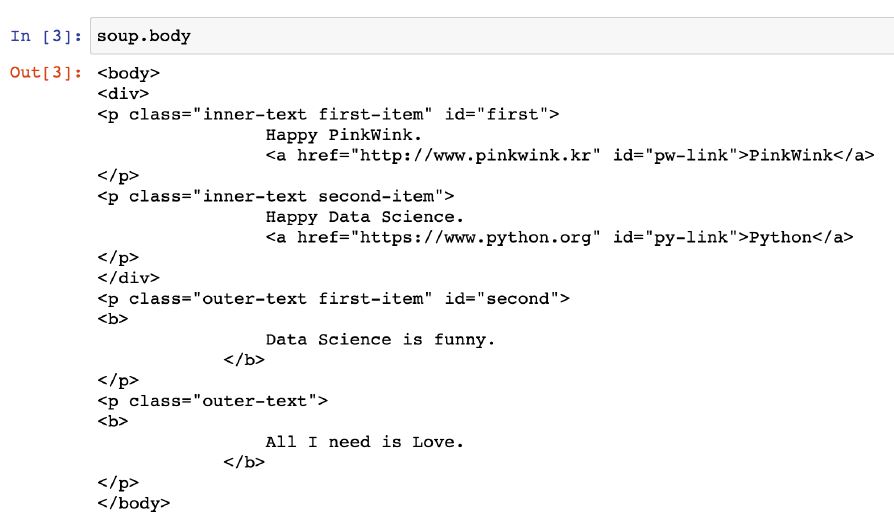
- p 태그 확인(find, find_all, select)
3가지 방법이 있다.
- 변수.태그
- 변수.find('태그')
- 변수.find_all('태그') : 여러 개의 태그 반환, 리스트 형태로 반환
- findall 은 리스트 형태로 반환되기 때문에 soup.find_all(class="outer-text")[0] 이런 식으로 가능하다.
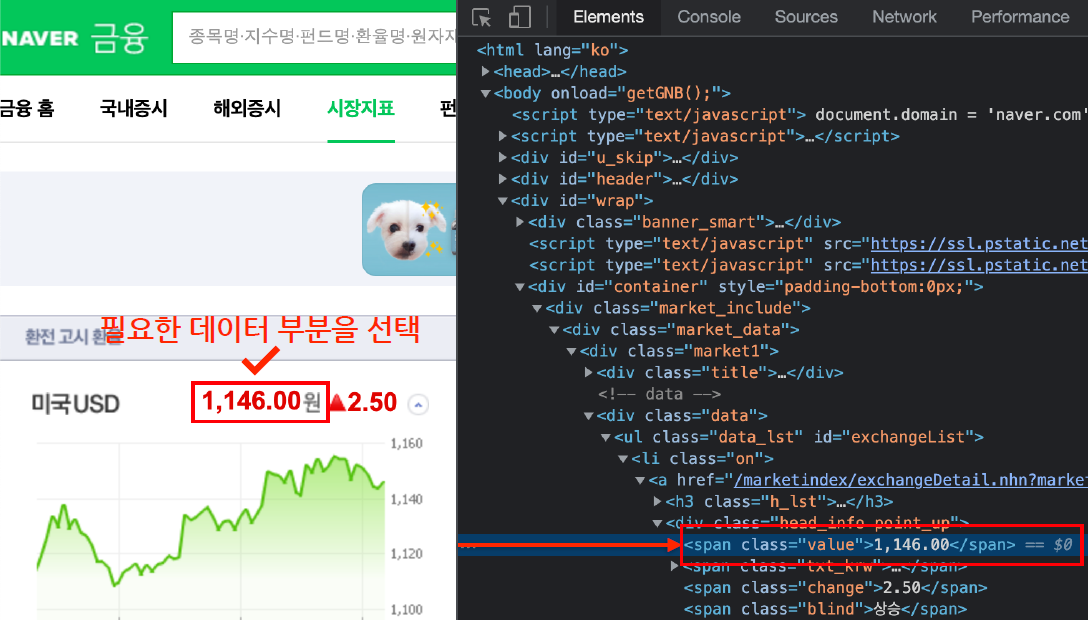
- select : select 사용예시는 아래 네이버 금융 참조
- find - 하나 선택
- find_all - 여러개 선택
- 위와 같은 기능을 하는 select, select_one 이 있다
- select_one - 하나 선택
- select - 여러개 선택
- select 상위하위로 이동이 좀 더 자유롭다
- soup.find_all("li","on")(# li 태그의 on 클래스) 와 같은 방법으로 아래와 같이 할 수 있다.
- exchangeList = soup.select("li")
- exchangeList = soup.select("#exchangeList > li")
- select 사용법 : 클래스는 점(.)을 앞에 붙이고
- select 사용법 : id 는 샾(#)을 앞에 붙인다
- #exchangeList > li : id exchangeList 바로 밑에(>) li 태그를 모두 가져온다
- title = exchangeList[0].select_one(".h_lst").text # '미국 USD'
- exchange = exchangeList[0].select_one(".value").text # '1,319.00'
- change = exchangeList[0].select_one(".change").text
- updown = exchangeList[0].select_one("div.head_info.point_dn > .blind").text
- exchangeList[0].select_one("a").get("href")
soup.p
soup.find('p')
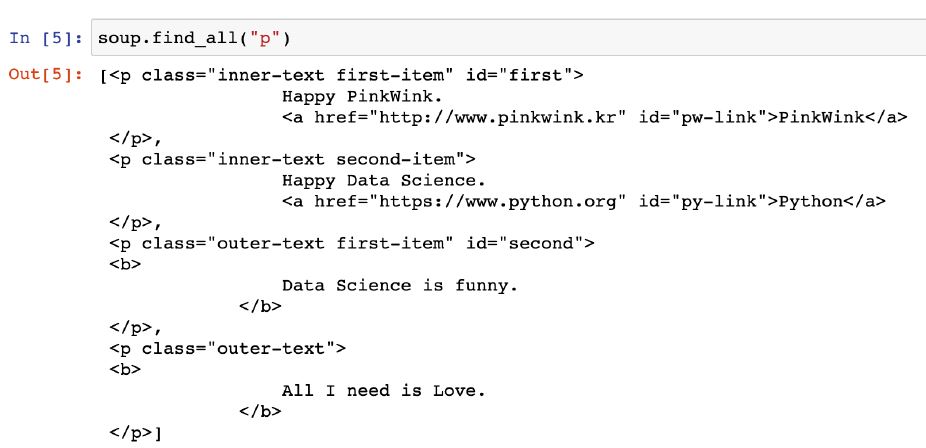
soup.find_all('p')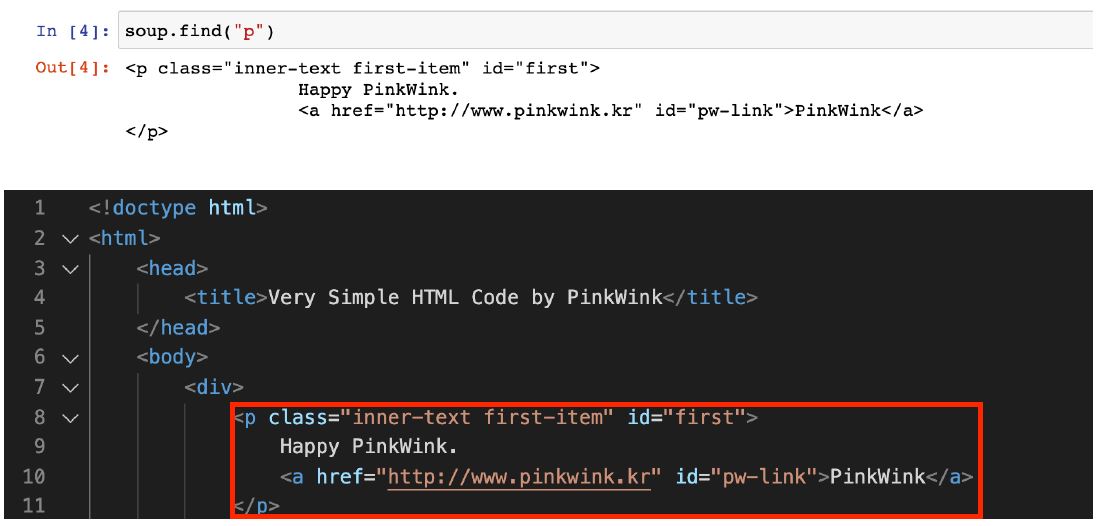
soup.find("p", class_="~~") # class 뒤에 언더바_ 주의
soup.find("p", {"class":"~~"})
위 2가지 모두 가능. 반환값은 같다.
soup.find("p", {"class":"~~", "id":"~~"})
이렇게도 가능
• find_all()은 지정된 태그를 모두 찾아준다
• 리스트형태로 반환된다
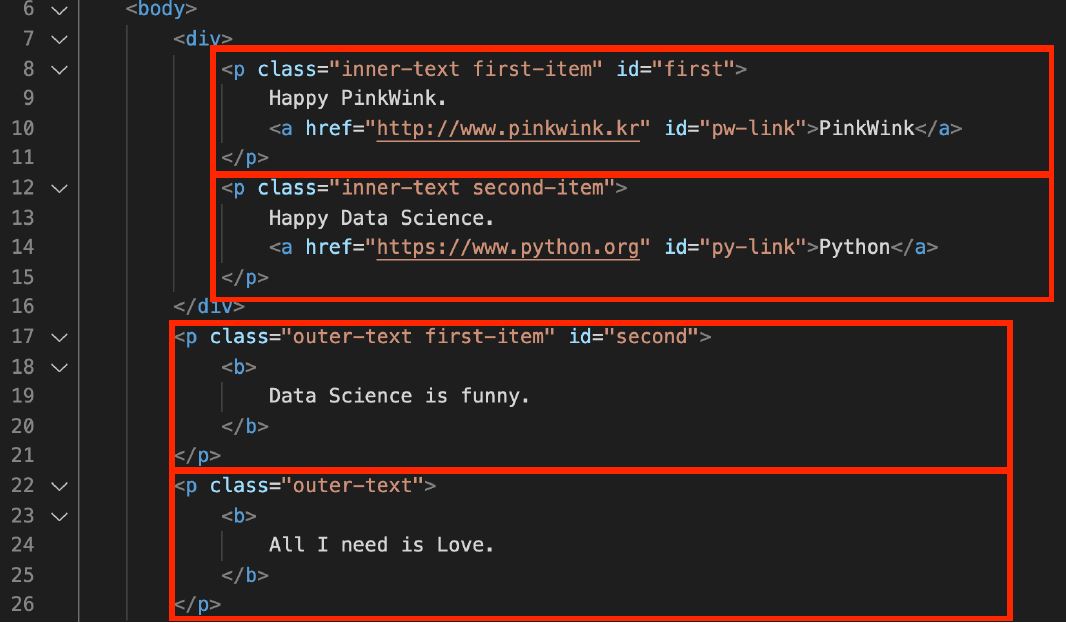
- p 태그 안에 특정 클래스만 찾기
-
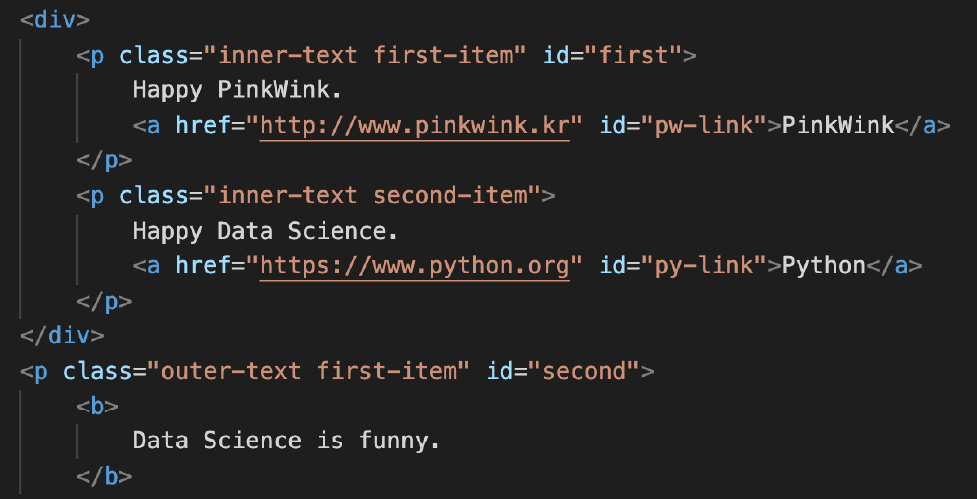
예제 html
-
class 가 "outer-text"인 곳 모두 출력 (class_ 주의)
soup.find_all(class_="outer-text")
- p 태그 중 class가 "innter-text second-item"
soup.find("p", class_= "innter-text second-item")
그러나 그냥 이렇게 사용하는 경우가 더 많다.

HTML 내에서 속성 id는 딱 한 번만 나타난다
그래서 find_all() 함수는 의미가 없다
단, 검색결과를 list로 받고 싶다면 id라도 find_all() 함수를 사용한다
- p 태그 리스트에서 텍스트 속성만 출력
# p 태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all("p"):
print("=" * 50)
print(each_tag.text)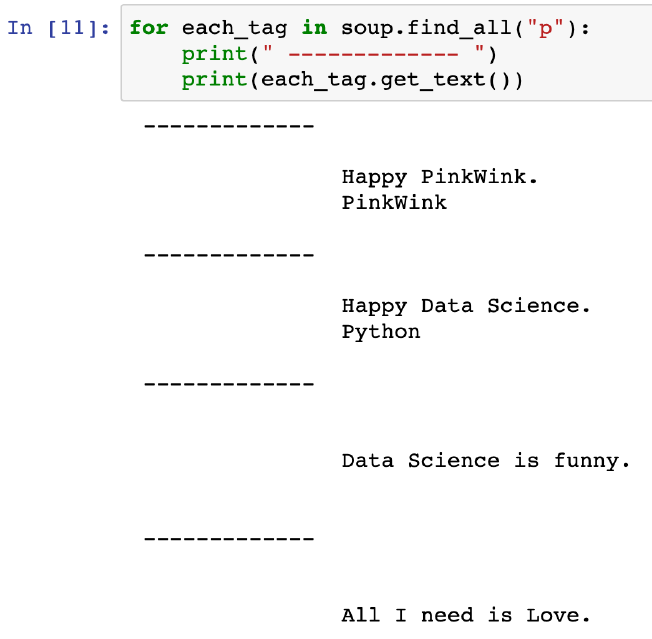
텍스트만 추출하기
soup.find_all(class_="outer-text")[0].text
soup.find(class_="outer-text").string
soup.find(class_="outer-text").get_text()
이렇게하면 해당 텍스트만 나옴.
strip() 은 공백지우기, 빈칸이 있는 경우에만 넣음
.text 과 같은 기능인 것들
1. .string
2. .get_text()
- 예시
soup.find("p", {"class": "outer-text first-item"}).text.strip() # strip: 공백 지우기
>> 'Data Science is Funny.'
- 다중조건
p 태그 안에 class 속성값이 "inner-text first-item" 이면서, id 속성값이 "first" 인 것
# 다중 조건
soup.find("p", {"class": "inner-text first-item", "id":"first"}).text.strip()
>> 'Happy PinkWink,'외부로 연결되는 링크주소 추출(href)
- a 태그에서 href 속성값에 있는 값 추출
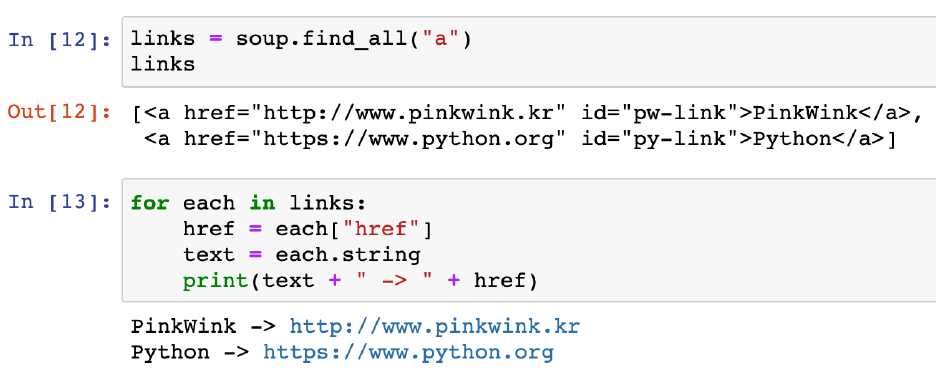
links = soup.find_all("a")
# print(links)
# print(links[0].get("href"), links[1]["href"])
for each in links:
href = each.get("href") # each["href"]
text = each.get_text()
print(text + " => " + href)네이버 금융
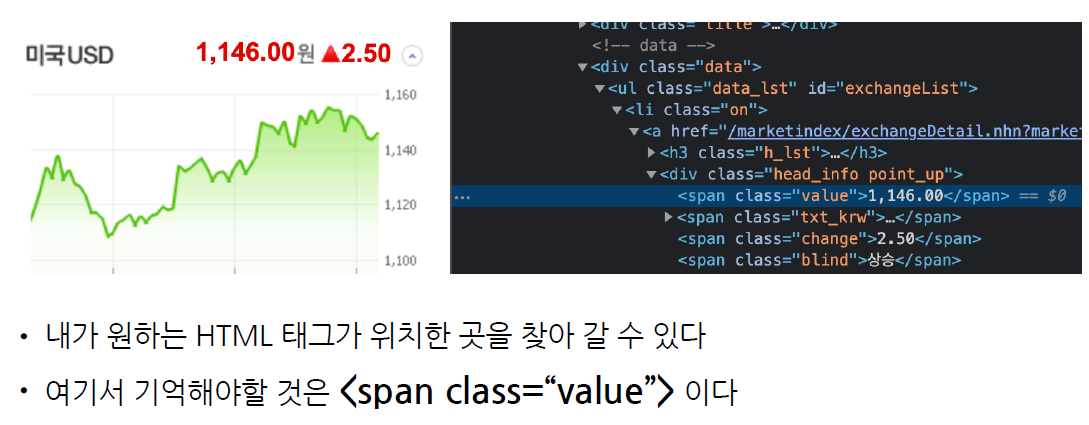

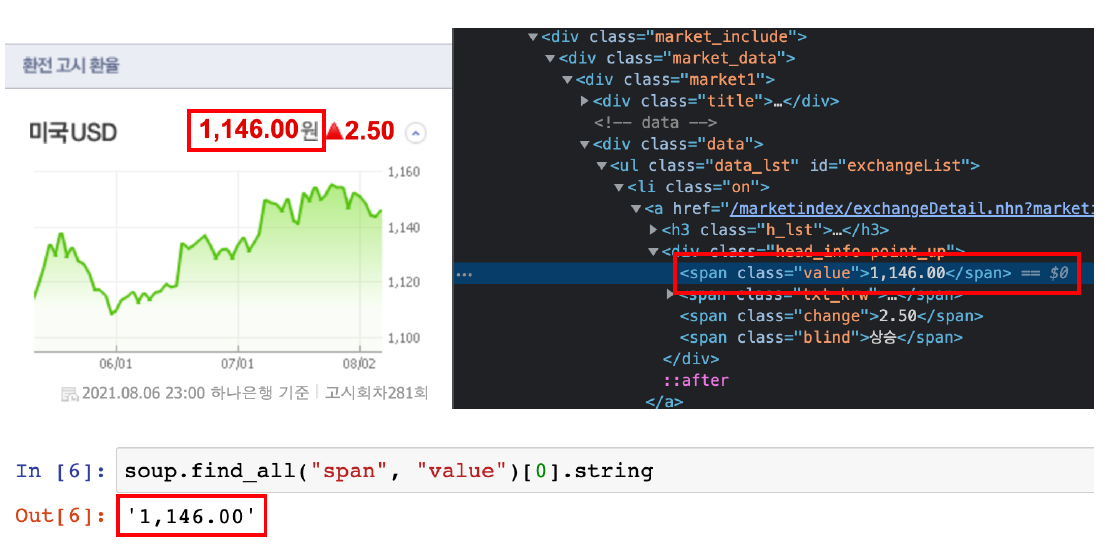
# 네이버금융
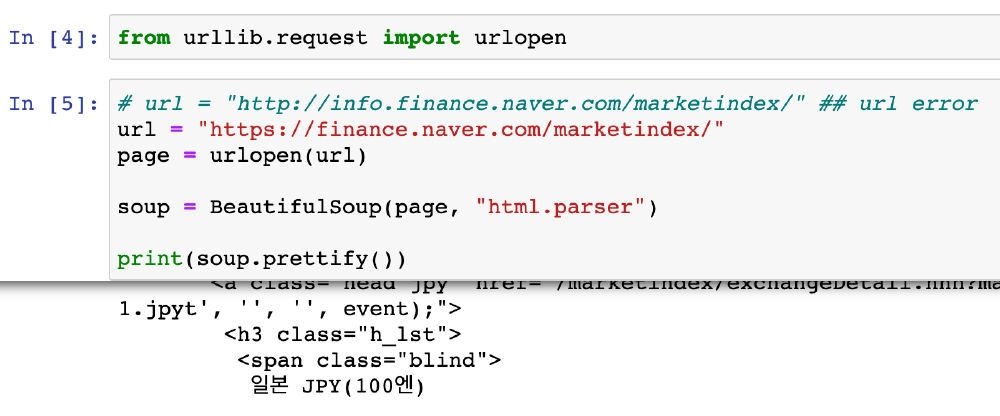
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = "https://finance.naver.com/"
reponse = urlopen(url)
reponse.status
# 200 이라는 숫자가 정상적으로 요청을 했고, 정상적으로 받았다는 뜻
# http 상태코드라고 한다
# 번호에 따라서 웹페이지의 상태를 나타낸다
# 그 번호에 따라서 나의 잘못인지, 서버오류인지 등을 알 수 있다.
>>
200• HTTP 상태코드
- html 데이터 가져오기
-----------------------------------------------------------------
url = "https://finance.naver.com/"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
>>
Output exceeds the size limit. Open the full output data in a text editor<html lang="ko">
<head>
<title>
네이버 증권
</title>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="text/javascript" http-equiv="Content-Script-Type"/>
<meta content="text/css" http-equiv="Content-Style-Type"/>
<meta content="네이버 증권" name="apple-mobile-web-app-title"/>
<meta content="네이버 증권" property="og:title"/>
<meta content="https://ssl.pstatic.net/static/m/stock/im/2016/08/og_stock-200.png" property="og:image"/>
<meta content="https://finance.naver.com" property="og:url"/>
<meta content="국내 해외 증시 지수, 시장지표, 뉴스, 증권사 리서치 등 제공" property="og:description"/>
<meta content="article" property="og:type"/>
<meta content="" property="og:article:thumbnailUrl"/>
<meta content="네이버 증권" property="og:article:author"/>
<meta content="http://FINANCE.NAVER.COM" property="og:article:author:url"/>
<link href="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/css/finance_header.css" rel="stylesheet" type="text/css"/>
<link href="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/css/finance.css" rel="stylesheet" type="text/css"/>
<link href="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/css/newstock3.css" rel="stylesheet" type="text/css"/>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/jindo.min.ns.1.5.3.euckr.js" type="text/javascript">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/release/common.js" type="text/javascript">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/jindoComponent/jindo.Component.1.0.3.js" type="text/javascript">
...
jindo.$Fn(mainPageDomReadyFn).attach(document, "domready");
</script>
</body>
</html>데이터 추출하기(태그 가져오기)
# 방법 1
soup.find_all("span", "num")
# 방법 2
soup.find_all("span", class_ = "num")
>>
[<span class="num _au_real_list">@code@</span>,
<span class="num">2,490.41</span>,
<span class="num">880.07</span>,
<span class="num">323.36</span>]
------------------------------------------------------
# 방법 3 + len() : 갯수확인까지
soup.find_all("span", {"class":"num"}), len(soup.find_all("span", {"class":"num"}))
>>
([<span class="num _au_real_list">@code@</span>,
<span class="num">2,490.41</span>,
<span class="num">880.07</span>,
<span class="num">323.36</span>],
4)
------------------------------------------------------
# 방법 1
soup.find_all("span", class_ = "num")[1].text
# 방법 2
soup.find_all("span", class_ = "num")[1].string
# 방법 3
soup.find_all("span", class_ = "num")[1].get_text()
>> '2,490.41'
------------------------------------------------------
import requests
# from urllib.request.Request
# 위 requests 와 기능은 똑같다고는 하는데,
# from urllib.request.Request 는 실행하면 에러남
from bs4 import BeautifulSoup
url = "https://finance.naver.com/marketindex/"
reponse = requests.get(url)
# requests.get()
# requests.post()
# 두가지 방식이 있지만 설명은 안해줌
reponse
>> <Response [200]>
------------------------------------------------------
reponse.text
>> '\n<script language=javascript src="/template/....
------------------------------------------------------
soup = BeautifulSoup(reponse.text, "html.parser")
print(soup.prettify())
>>
Output exceeds the size limit. Open the full output data in a text editor<script language="javascript" src="/template/head_js.naver?referer=info.finance.naver.com&menu=marketindex&submenu=market">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/info/jindo.min.ns.1.5.3.euckr.js" type="text/javascript">
</script>
<script src="https://ssl.pstatic.net/imgstock/static.pc/20230321170048/js/jindo.1.5.3.element-text-patch.js" type="text/javascript">
</script>
<div id="container" style="padding-bottom:0px;">
<div class="market_include">
<div class="market_data">
<div class="market1">
<div class="title">
<h2 class="h_market1">
<span>
환전 고시 환율
</span>
</h2>
</div>
<!-- data -->
<div class="data">
<ul class="data_lst" id="exchangeList">
<li class="on">
<a class="head usd" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdt', '', '', event);">
<h3 class="h_lst">
<span class="blind">
미국 USD
...
window.addEventListener('mousedown', gnbLayerClose);
}
</script>
------------------------------------------------------
# find - 하나 선택
# find_all - 여러개 선택
# 위와 같은 기능을 하는 select, select_one 이 있다
# select_one - 하나 선택
# select - 여러개 선택
# select 상위하위로 이동이 좀 더 자유롭다
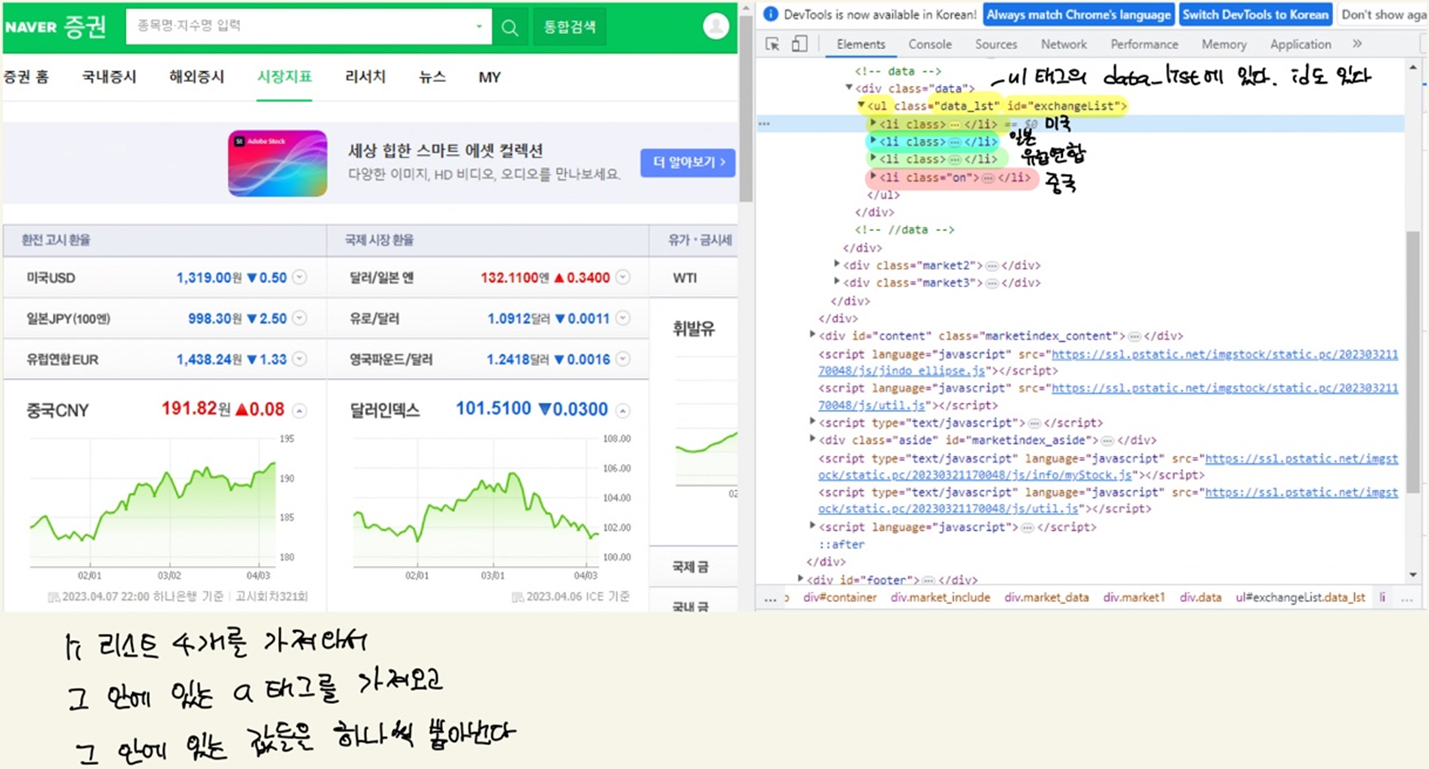
# li 태그 리스트 4개를 가져와서
# 그 안에 있는 a 태그를 가져오고
# 그 안에 있는 값들을 하나씩 뽑아낸다.
------------------------------------------------------
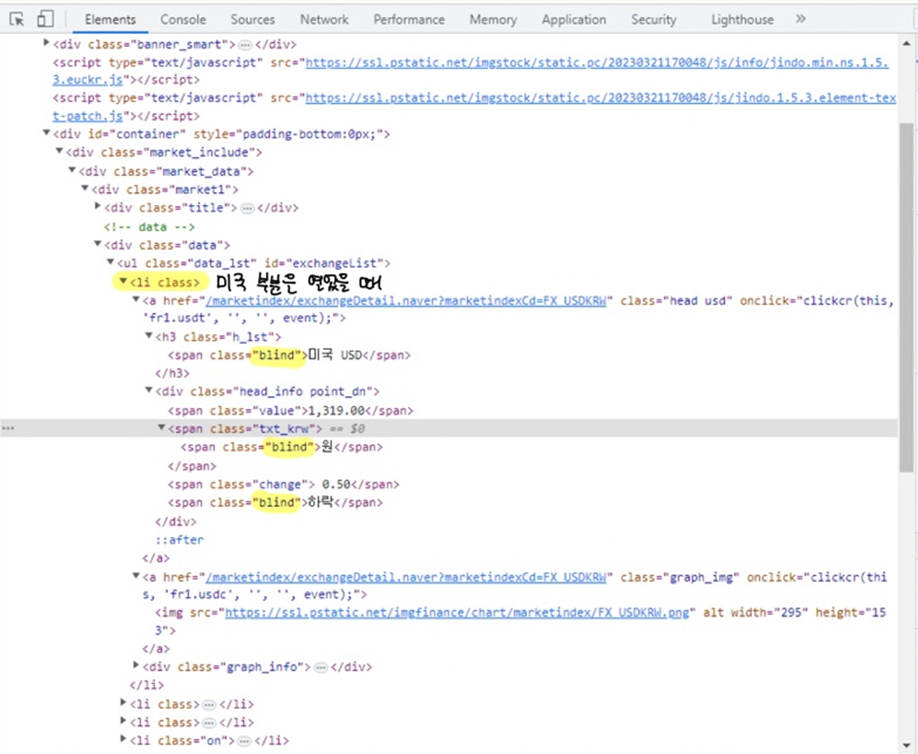
soup.find_all("li","on") # li 태그의 on 클래스
>>
Output exceeds the size limit. Open the full output data in a text editor[<li class="on">
<a class="head usd" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdt', '', '', event);">
<h3 class="h_lst"><span class="blind">미국 USD</span></h3>
<div class="head_info point_dn">
<span class="value">1,319.00</span>
<span class="txt_krw"><span class="blind">원</span></span>
<span class="change"> 0.50</span>
<span class="blind">하락</span>
</div>
</a>
<a class="graph_img" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdc', '', '', event);">
<img alt="" height="153" src="https://ssl.pstatic.net/imgfinance/chart/marketindex/FX_USDKRW.png" width="295"/>
</a>
<div class="graph_info">
<span class="time">2023.04.07 22:00</span>
<span class="source">하나은행 기준</span>
<span class="count">고시회차<span class="num">321</span>회</span>
</div>
</li>,
<li class="on">
<a class="head jpy_usd" href="/marketindex/worldExchangeDetail.naver?marketindexCd=FX_USDJPY" onclick="clickcr(this, 'fr2.jpyut', '', '', event);">
<h3 class="h_lst"><span class="blind">달러/일본 엔</span></h3>
<div class="head_info point_up">
<span class="value">132.1100</span>
<span class="txt_jpy"><span class="blind">엔</span></span>
...
------------------------------------------------------
# soup.find_all("li","on")(# li 태그의 on 클래스) 와 같은 방법으로 아래와 같이 할 수 있다.
exchangeList = soup.select("li")
len(exchangeList) # 4개를 가져와야 하는데 36개 나옴
>> 36
------------------------------------------------------
exchangeList = soup.select("#exchangeList > li")
# select 사용법 : 클래스는 점(.)을 앞에 붙이고
# select 사용법 : id 는 샾(#)을 앞에 붙인다
# #exchangeList > li : id exchangeList 바로 밑에(>) li 태그를 모두 가져온다
len(exchangeList), exchangeList # li 태그 정보 4개를 모두 가져왔다
>>
Output exceeds the size limit. Open the full output data in a text editor(4,
[<li class="on">
<a class="head usd" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdt', '', '', event);">
<h3 class="h_lst"><span class="blind">미국 USD</span></h3>
<div class="head_info point_dn">
<span class="value">1,319.00</span>
<span class="txt_krw"><span class="blind">원</span></span>
<span class="change"> 0.50</span>
<span class="blind">하락</span>
</div>
</a>
<a class="graph_img" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW" onclick="clickcr(this, 'fr1.usdc', '', '', event);">
<img alt="" height="153" src="https://ssl.pstatic.net/imgfinance/chart/marketindex/FX_USDKRW.png" width="295"/>
</a>
<div class="graph_info">
<span class="time">2023.04.07 22:00</span>
<span class="source">하나은행 기준</span>
<span class="count">고시회차<span class="num">321</span>회</span>
</div>
</li>,
<li class="">
<a class="head jpy" href="/marketindex/exchangeDetail.naver?marketindexCd=FX_JPYKRW" onclick="clickcr(this, 'fr1.jpyt', '', '', event);">
<h3 class="h_lst"><span class="blind">일본 JPY(100엔)</span></h3>
<div class="head_info point_dn">
<span class="value">998.30</span>
...
<span class="time">2023.04.07 22:00</span>
<span class="source">하나은행 기준</span>
<span class="count">고시회차<span class="num">321</span>회</span>
</div>
</li>])
------------------------------------------------------
# select 사용법 : 클래스는 점(.)을 앞에 붙이고
# select 사용법 : id 는 샾(#)을 앞에 붙인다
title = exchangeList[0].select_one(".h_lst").text # '미국 USD'
exchange = exchangeList[0].select_one(".value").text # '1,319.00'
change = exchangeList[0].select_one(".change").text
updown = exchangeList[0].select_one("div.head_info.point_dn > .blind").text
# blind 가 2군데 쓰였으므로 구분해주기 위함
# 띄워쓰기 주의 : head_info point_dn 는 속성값이 2개다(head_info 와 point_dn)
# 위에서는 띄워쓰기는 점(.)으로 대체함
# div.head_info.point_dn > .blind 에서 > 는 바로 밑의 하위를 뜻하므로 하락 부분을 가져온다
# > 가 없다면 첫번째로 나오는 '원' 을 가져온다
title, exchange, change, updown
>>
('미국 USD', '1,319.00', ' 0.50', '하락')
------------------------------------------------------
# 위 코드를 find_all 로 한다면,
findmethod = soup.find_all("ul", id="exchangeList")
findmethod[0].find_all("span", "value")
>>
[<span class="value">1,319.00</span>,
<span class="value">998.30</span>,
<span class="value">1,438.24</span>,
<span class="value">191.82</span>]
------------------------------------------------------
exchangeList[0].select_one("a").get("href")
>>
'/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'
------------------------------------------------------
baseUrl = "https://finance.naver.com"
baseUrl + exchangeList[0].select_one("a").get("href")
>>
'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'
------------------------------------------------------
# 4개 데이터 수집
# 현재 exchangeList 에 4개 나라의 정보가 담겨져 있음
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title" : item.select_one(".h_lst").text,
"exchange" : item.select_one(".value").text,
"change" : item.select_one(".change").text,
"updown" : item.select_one("div.head_info.point_dn > .blind"),
# 중국이 updown 에러남, 'updown': None
# 그래서 .text 쓰면 에러남
"link" : baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
exchange_datas
# 리스트 안의 딕셔너리 형태
>>
[{'title': '미국 USD',
'exchange': '1,319.00',
'change': ' 0.50',
'updown': <span class="blind">하락</span>,
'link': 'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW'},
{'title': '일본 JPY(100엔)',
'exchange': '998.30',
'change': ' 2.50',
'updown': <span class="blind">하락</span>,
'link': 'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_JPYKRW'},
{'title': '유럽연합 EUR',
'exchange': '1,438.24',
'change': ' 1.33',
'updown': <span class="blind">하락</span>,
'link': 'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_EURKRW'},
{'title': '중국 CNY',
'exchange': '191.82',
'change': '0.08',
'updown': None,
'link': 'https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_CNYKRW'}]
------------------------------------------------------
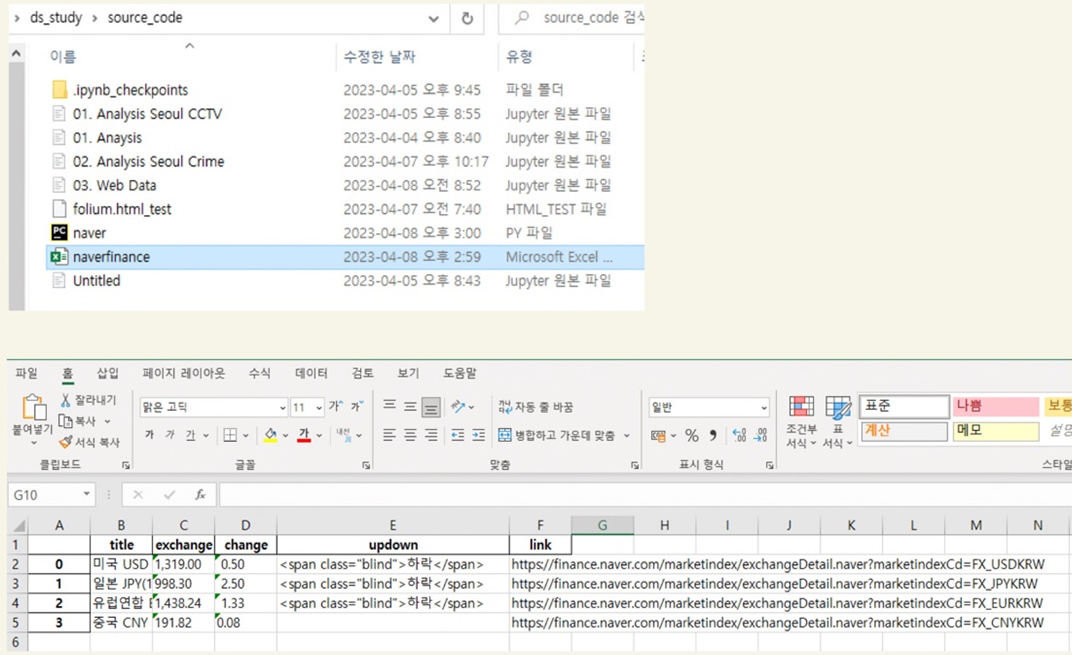
import pandas as pd
df = pd.DataFrame(exchange_datas)
>>
title exchange change updown link
0 미국 USD 1,319.00 0.50 [하락] https://finance.naver.com/marketindex/exchange...
1 일본 JPY(100엔) 998.30 2.50 [하락] https://finance.naver.com/marketindex/exchange...
2 유럽연합 EUR 1,438.24 1.33 [하락] https://finance.naver.com/marketindex/exchange...
3 중국 CNY 191.82 0.08 None https://finance.naver.com/marketindex/exchange...
------------------------------------------------------
df.to_excel("./naverfinance.xlsx", encoding="utf-8")
>>
c:\Users\hjh\miniconda3\envs\ds_study\lib\site-packages\pandas\util\_decorators.py:211: FutureWarning: the 'encoding' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'encoding'
return func(*args, **kwargs)
위 글은 제로베이스 데이터 취업 스쿨의 강의자료를 참고하여 작성되었습니다.

허재