
스타벅스 데이터 수집
1. 페이지 접근
from selenium import webdriver
# 1. 스타벅스 페이지 접근
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get("https://www.starbucks.co.kr/store/store_map.do")2. 지역 선택
# '지역검색' 선택
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
search_tag = driver.find_element(By.CSS_SELECTOR, value='#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search')
action = ActionChains(driver)
action.click(search_tag)
action.perform()3. 서울 선택
# '서울' 선택
# 강의에선 이렇게 하는데, 이렇게 하면 에러남..
driver.find_element(By.CSS_SELECTOR, "sido_arae_box > li > a").click()
# 대신 이렇게 하면 실행됨
driver.find_element(By.CSS_SELECTOR,
'#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a').click()
# 아래는 과제 제출 시 내가 작성한 것
seoul_tag = driver.find_element(By.CSS_SELECTOR, value='#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(seoul_tag)
action.perform()4. 전체 선택
# 전체 선택
driver.find_element(By.CSS_SELECTOR, value='#mCSB_2_container > ul > li:nth-child(1) > a').click()
# 아래는 과제 제출 시 내가 작성한 것
seoul_tag = driver.find_element(By.CSS_SELECTOR, value='#mCSB_2_container > ul > li:nth-child(1) > a')
action = ActionChains(driver)
action.click(seoul_tag)
action.perform()5. 검색 결과 리스트 가져오기(beautifulsoup)
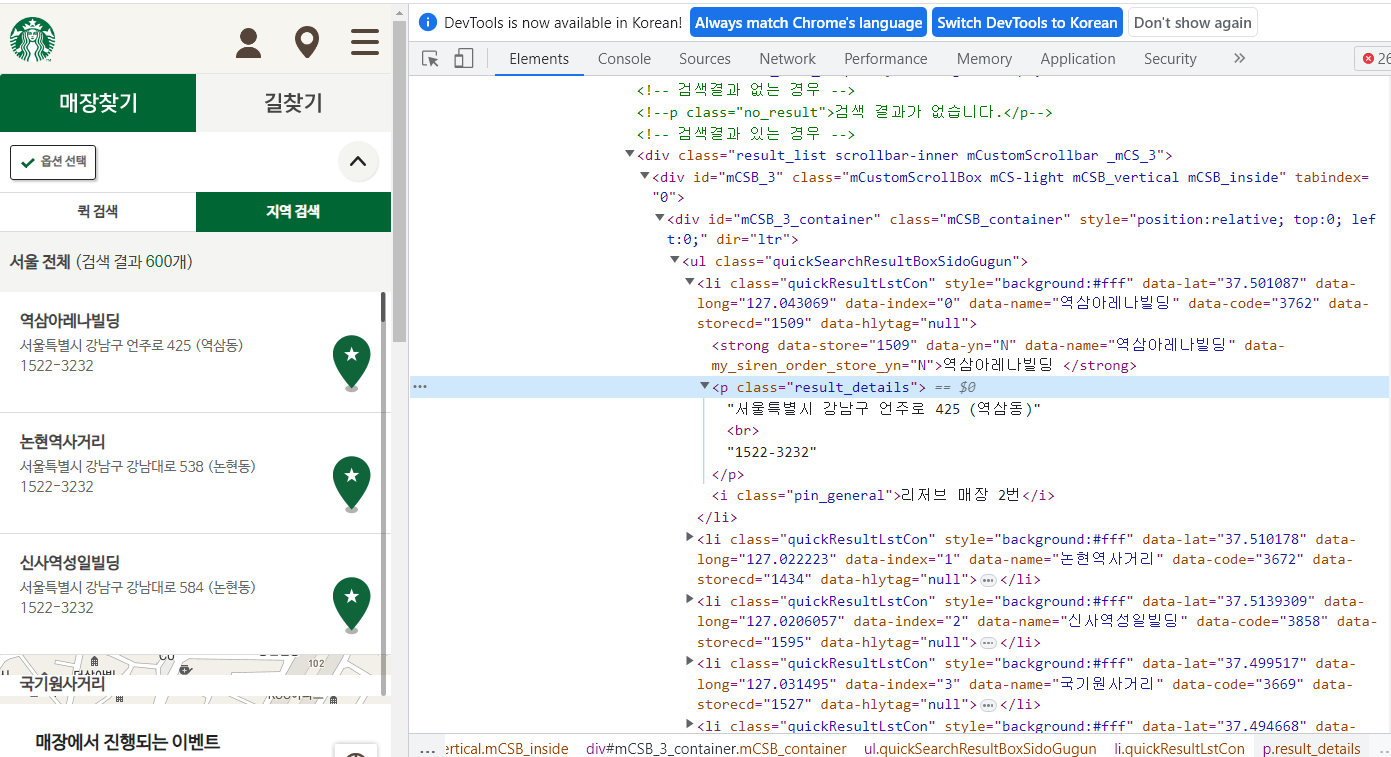
# 검색 결과 리스트 가져오기(beautifulsoup)
# #mCSB_3_container : id 가 mCSB_3_container
# #mCSB_3_container ul li : id 가 mCSB_3_container 이고 그 밑에 ul, 그 밑에 li를 모두 가져와
driver.find_elements(By.CSS_SELECTOR, "#mCSB_3_container ul li")
# 길이 확인
# 600개 매장에 대한 정보를 모두 가져왔다
tmp_list = driver.find_elements(By.CSS_SELECTOR, "#mCSB_3_container ul li")
len(tmp_list)
>> 6006. 데이터 수집(매장 이름, 주소, 위도, 경도)
from bs4 import BeautifulSoup
# html로 읽어오기
req = driver.page_source
dom = BeautifulSoup(req, "html.parser")
dom
sbuck_list = dom.select("#mCSB_3_container ul li")
len(sbuck_list)
>> 600sbuck_list[0]
>>
# 아래 결과물은 내가 임의로 줄바꿈해서 보기좋게 나타냄
<li class="quickResultLstCon"
data-code="3762" data-hlytag="null" data-index="0"
data-lat="37.501087"
data-long="127.043069"
data-name="역삼아레나빌딩"
data-storecd="1509" style="background:#fff">
<strong data-my_siren_order_store_yn="N"
data-name="역삼아레나빌딩" data-store="1509" data-yn="N">역삼아레나빌딩
</strong>
<p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p>
<i class="pin_general">리저브 매장 2번</i></li># p태그 안의 값을 가져온다
address = sbuck_list[0]('p')
address
>>
[<p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p>]# 아래처럼 해도 값은 같다
address = sbuck_list[0].select_one('p')
address
>>
<p class="result_details">서울특별시 강남구 언주로 425 (역삼동)<br/>1522-3232</p>address = sbuck_list[0].select_one('p').text
address
>>
'서울특별시 강남구 언주로 425 (역삼동)1522-3232'# 전화번호 부분을 제외시킨다
address = sbuck_list[0].select_one('p').text[:-9]
address
>>
'서울특별시 강남구 언주로 425 (역삼동)'import pandas as pd
from tqdm import tqdm_notebook
datas = []
for content in tqdm_notebook(sbuck_list):
title = content['data-name']
address = content.select_one('p').text[:-9]
lat = content['data-lat']
lng = content['data-long']
datas.append({
'title': title,
'address': address,
'lat': lat,
'lng': lng
})
df = pd.DataFrame(datas)
df.tail()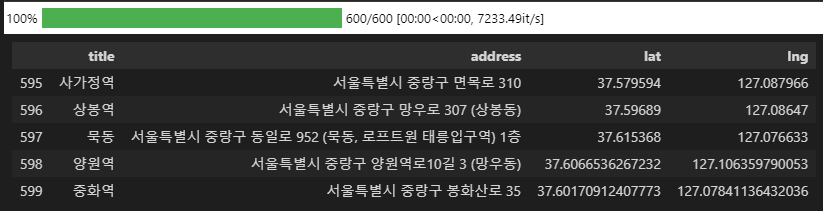
df.info()
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 600 entries, 0 to 599
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 600 non-null object
1 address 600 non-null object
2 lat 600 non-null object
3 lng 600 non-null object
dtypes: object(4)
memory usage: 18.9+ KB7. 구 컬럼 추가
df['address'][0]
>> '서울특별시 강남구 언주로 425 (역삼동)'df['address'][0].split()
>> ['서울특별시', '강남구', '언주로', '425', '(역삼동)']df['address'][0].split()[1]
>> '강남구'# 컬럼 구를 만들어서 강남구로 모두 채워버림 ㅋㅋㅋ
df['구'] = df['address'][0].split()[1]
df.tail(3)
# 컬럼 구를 만들어서 강남구로 모두 채워버림 ㅋㅋㅋ
df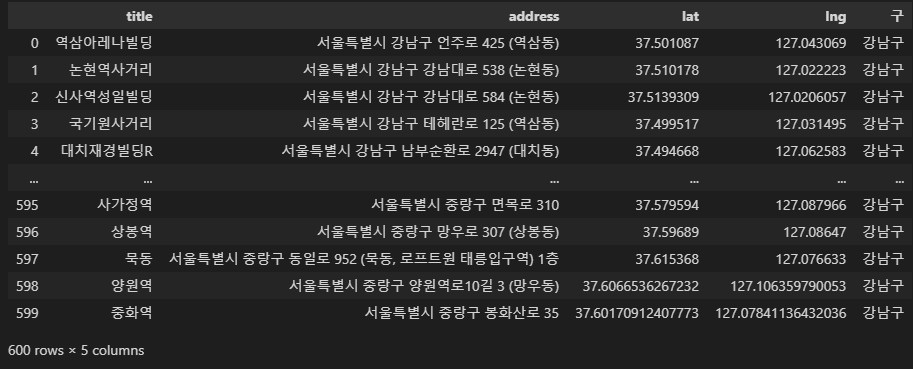
for idx, rows in df.iterrows():
print(idx)
>>
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
...
596
597
598
599for idx, rows in df.iterrows():
print(rows)
>>
Output exceeds the size limit. Open the full output data in a text editortitle 역삼아레나빌딩
address 서울특별시 강남구 언주로 425 (역삼동)
lat 37.501087
lng 127.043069
구 강남구
Name: 0, dtype: object
title 논현역사거리
address 서울특별시 강남구 강남대로 538 (논현동)
lat 37.510178
lng 127.022223
구 강남구
Name: 1, dtype: object
title 신사역성일빌딩
address 서울특별시 강남구 강남대로 584 (논현동)
lat 37.5139309
lng 127.0206057
구 강남구
...
lat 37.60170912407773
lng 127.07841136432036
구 강남구
Name: 599, dtype: objectfor idx, rows in df.iterrows():
print(rows['구']) # 현재 모든 구가 강남구임
>>
강남구
강남구
...
강남구
강남구
강남구
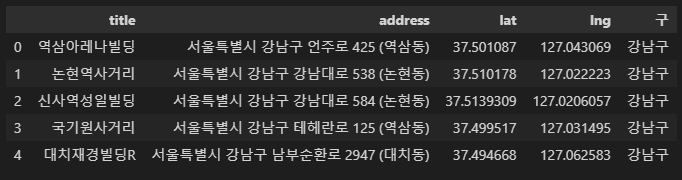
강남구for idx, rows in df.iterrows():
rows['구'] = df['address'][idx].split()[1]
# idx 마다 해당 구를 구해서 rows['구'] 에 넣음
df.head() # 해당구에 맞는 구가 잘 들어감
df.tail() # 해당구에 맞는 구가 잘 들어감
df.info()
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 600 entries, 0 to 599
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 600 non-null object
1 address 600 non-null object
2 lat 600 non-null object
3 lng 600 non-null object
4 구 600 non-null object
dtypes: object(5)
memory usage: 23.6+ KB8. 데이터 저장
# 데이터 저장
df.to_csv('../data/starbucks.csv', encoding='utf-8')- 데이터 불러와보기
# 데이터 읽어와보기
starbucks_df = pd.read_csv('../data/starbucks.csv', index_col=0)
starbucks_df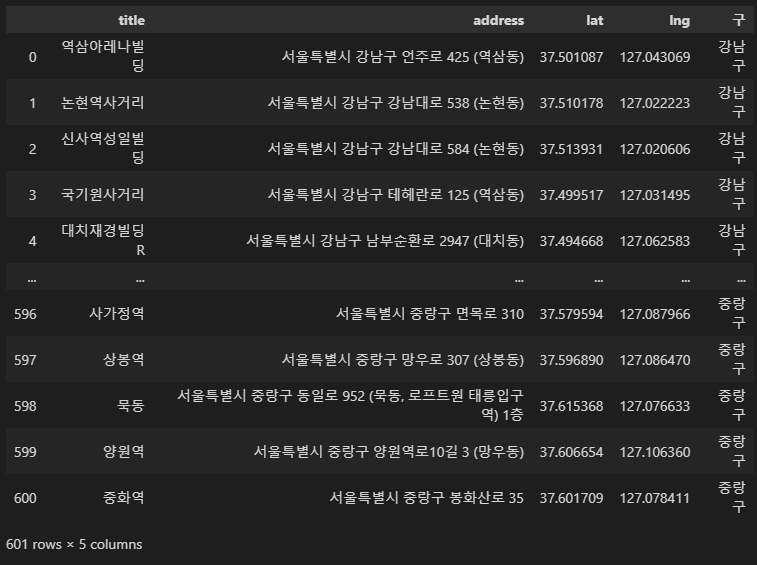
이디야 데이터 수집
1. 페이지 접근
# 1. 이디야 페이지 접근
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get("https://ediya.com/contents/find_store.html#c")2. 주소 검색 탭 선택
driver.find_element(By.CSS_SELECTOR, value='#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()3. 검색어(구) 만들기
스타벅스 구 컬럼 가져오기
# 3. 검색어(구) 만들기
# 스타벅스 매장 구 컬럼 가져오기
df["구"].unique()
>>
array(['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구',
'마포구', '서대문구', '서초구', '성북구', '송파구', '양천구', '영등포구', '은평구', '종로구',
'중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구'], dtype=object)
리스트형으로 변환
# gu_list 에 넣어주고 list 자료형으로 형변환
gu_list = list(df["구"].unique())
gu_list
>>
['강남구',
'강북구',
'강서구',
'관악구',
'광진구',
'금천구',
'노원구',
'도봉구',
'동작구',
'마포구',
'서대문구',
'서초구',
'성북구',
'송파구',
'양천구',
'영등포구',
'은평구',
'종로구',
'중구',
'강동구',
'구로구',
'동대문구',
'성동구',
'용산구',
'중랑구']'서울' 붙이기
# '서울' 붙이기
gu_list = [str('서울 ') + gu for gu in gu_list]
gu_list
>>
['서울 강남구',
'서울 강북구',
'서울 강서구',
'서울 관악구',
'서울 광진구',
'서울 금천구',
'서울 노원구',
'서울 도봉구',
'서울 동작구',
'서울 마포구',
'서울 서대문구',
'서울 서초구',
'서울 성북구',
'서울 송파구',
'서울 양천구',
'서울 영등포구',
'서울 은평구',
'서울 종로구',
'서울 중구',
'서울 강동구',
'서울 구로구',
'서울 동대문구',
'서울 성동구',
'서울 용산구',
'서울 중랑구']
구 확인
len(gu_list), gu_list[:3]
>>
(25, ['서울 강남구', '서울 강북구', '서울 강서구'])
4. 데이터 수집(for 문 x 2)
준비
# 데이터 수집 준비
keyword = driver.find_element(By.CSS_SELECTOR, value="#keyword")
keyword.clear() # 기존에 입력한 검색어 지우기
keyword.send_keys(gu_list[0]) # 일단 강남구 넣어봄
데이터 수집
import time
# 1. 이디야 페이지 접근
url = "https://ediya.com/contents/find_store.html#c"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.get(url)
# 2. 주소 검색 탭 선택
driver.find_element(By.CSS_SELECTOR, value='#contentWrap > div.contents > div > div.store_search_pop > ul > li:nth-child(2) > a').click()
# 3. 검색어를 입력할 공간 찾기
search_keyword = driver.find_element(By.CSS_SELECTOR, value="#keyword")
# 4. 클릭
search_btn = driver.find_element(By.CSS_SELECTOR, value="#keyword_div > form > button")
time.sleep(2)
ediya = []
for gu in gu_list:
search_keyword.clear()
search_keyword.send_keys(gu)
search_btn.click()
time.sleep(1)
html = driver.page_source
dom = BeautifulSoup(html, "html.parser")
contents = dom.select('#placesList li')
for content in contents:
title = content.select_one('dt').text
address = content.select_one('dd').text
ediya.append({
'title' : title,
'address' : address
})
df_ediya = pd.DataFrame(ediya)
df_ediya.tail()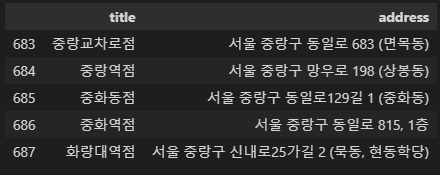
5. 구 컬럼 추가
# 구 컬럼 추가
df_ediya['gu'] = df_ediya['address'][0].split()[1]
for idx, rows in df_ediya.iterrows():
rows['gu'] = df_ediya['address'][idx].split()[1]
# idx 마다 해당 구를 구해서 rows['구'] 에 넣음
df_ediya['gu'].unique()
>>
array(['강남구', '강북구', '강서구', '관악구', '광진구', '금천구', '노원구', '도봉구', '동작구',
'마포구', '서대문구', '서초구', '성북구', '송파구', '양천구', '영등포구', '은평구', '종로구',
'중구', '강동구', '구로구', '동대문구', '성동구', '용산구', '중랑구'], dtype=object)
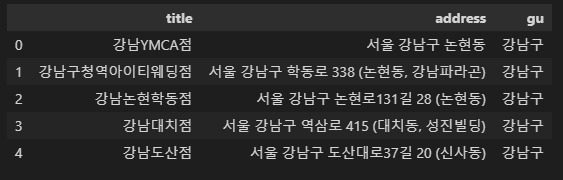
df_ediya.tail()

df_ediya.head()
len(df_ediya)
>> 688
6. 위도, 경도 (googlemaps)
준비
# googlemaps 이용한 매장 위치 좌표
# 위도, 경도 컬럼 추가
import googlemaps
gmaps_key = '_____________' # 본인 키 입력
gmaps = googlemaps.Client(key=gmaps_key)위도, 경도 컬럼 만들도 nan 값으로 채우기
import numpy as np
df_ediya['lat'] = np.nan
df_ediya['lng'] = np.nandf_ediya.head(2)
위도, 경도 넣기
# 위도, 경도 넣기
# 에러가 난다.
for idx, rows in tqdm_notebook(df_ediya.iterrows()):
address = rows['address']
tmp = gmaps.geocode(address, language='ko')
tmp[0].get('formatted_address')
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
df_ediya.loc[idx, 'lat'] = lat
df_ediya.loc[idx, 'lng'] = lng
- 에러를 찾아보자
# 에러를 찾아보자
# 위 코드를 아래와 같이 바꾼다.
# if, else 문을 넣어서 if 실행이 안되면 else 이하 구문이 실행된다
# 위에서 에러가 267에서 났는데, 아래를 보면 else에서 267 값부터 출력된다.
for idx, rows in tqdm_notebook(df_ediya.iterrows()):
address = rows['address']
tmp = gmaps.geocode(address, language='ko')
if tmp:
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
df_ediya.loc[idx, 'lat'] = lat
df_ediya.loc[idx, 'lng'] = lng
else:
print(idx, rows["address"])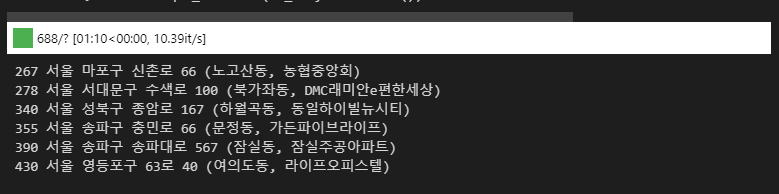
# 267번재째 주소 가져오기
df_ediya.iloc[267]
>>
title 신촌하나로마트점
address 서울 마포구 신촌로 66 (노고산동, 농협중앙회)
gu 마포구
lat NaN
lng NaN
Name: 267, dtype: object
# 267번재째 주소 가져오기
address_267 = df_ediya.loc[267]['address']
address_267
>>
'서울 마포구 신촌로 66 (노고산동, 농협중앙회)'# 진짜 안되네.
tmp_267 = gmaps.geocode(address_267, language='ko')
lat = tmp_267[0].get('geometry')['location']['lat']
lat
결측치 직접 입력
# 아놔.. 결측치 직접 입력해주기
# 구글지도 > 해당 주소 검색 > 해당 지역을 2번 클릭하면 위도, 경도 뜸 > 그러나 복사가 안됨
# 그래서 해당주소 검색하고 우클릭 > 여기를 출발지로 지정하면
# 주소창에 위도, 경도가 나옴 > 그걸 복사하면 됨
# 267 서울 마포구 신촌로 66 (노고산동, 농협중앙회)
# 278 서울 서대문구 수색로 100 (북가좌동, DMC래미안e편한세상)
# 340 서울 성북구 종암로 167 (하월곡동, 동일하이빌뉴시티)
# 355 서울 송파구 충민로 66 (문정동, 가든파이브라이프)
# 390 서울 송파구 송파대로 567 (잠실동, 잠실주공아파트)
# 430 서울 영등포구 63로 40 (여의도동, 라이프오피스텔)
df_ediya.loc[267, 'lat'] = 37.5560636
df_ediya.loc[267, 'lng'] = 126.9332046
df_ediya.loc[278, 'lat'] = 37.572623
df_ediya.loc[278, 'lng'] = 126.9104651
df_ediya.loc[340, 'lat'] = 37.6050265
df_ediya.loc[340, 'lng'] = 127.0308888
df_ediya.loc[355, 'lat'] = 37.477512
df_ediya.loc[355, 'lng'] = 127.1250286
df_ediya.loc[390, 'lat'] = 37.5151256
df_ediya.loc[390, 'lng'] = 127.0947932
df_ediya.loc[430, 'lat'] = 37.5194174
df_ediya.loc[430, 'lng'] = 126.9393364df_ediya.info()
# 컬럼마다 688개의 값이 NaN 값 없이 잘 들어갔다.
# 위도, 경도는 float 로 잘 들어갔다
>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 688 entries, 0 to 687
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 title 688 non-null object
1 address 688 non-null object
2 gu 688 non-null object
3 lat 688 non-null float64
4 lng 688 non-null float64
dtypes: float64(2), object(3)
memory usage: 27.0+ KB
7. 데이터 저장
# 데이터 저장
df_ediya.to_csv('../data/ediya.csv', encoding='utf-8')
- 데이터 불러와보기
# 파일 읽어와 보기
ediya_df = pd.read_csv('../data/ediya.csv', index_col=0)
ediya_df

데이터 분석 및 시각화
# 한글대응
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
%matplotlib inline
path = 'C:/Windows/Fonts/malgun.ttf'
if platform.system() == 'Darwin':
rc('font', family = 'Arial Unicode MS')
elif platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname = path).get_name()
rc('font', family = font_name)
else:
print('Unknown system. sorry.')
스타벅스 매장 주요 분포 지역
# 스타벅스 매장 주요 분포 지역
cafe_df['gu']
>>
0 강남구
1 강남구
2 강남구
3 강남구
4 강남구
...
1284 중랑구
1285 중랑구
1286 중랑구
1287 중랑구
1288 중랑구
Name: gu, Length: 1289, dtype: object스타벅스 상위 5개 구 확인
# 스타벅스 상위 5개 구 확인하기
# 구별 스타벅스 갯수 파악하기
# 구별 스타벅스 갯수를 내림차순 정렬하고, 상위 5개만 보자
cafe_df['gu'][cafe_df['brand']=='스타벅스'].value_counts(ascending=False)[:5]
>>
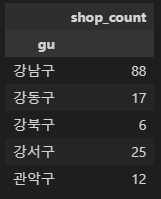
강남구 88
중구 53
서초구 48
영등포구 41
종로구 40
Name: gu, dtype: int64이디야 상위 5개 구 확인하기
# 이디야 상위 5개 구 확인하기
cafe_df['gu'][cafe_df['brand']=='이디야'].value_counts(ascending=False)[:5]
>>
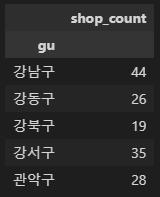
강남구 44
영등포구 41
송파구 38
강서구 35
마포구 34
Name: gu, dtype: int64
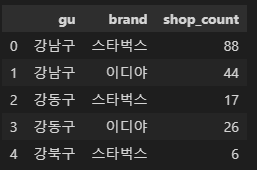
구별 매장 수
# 구별 매장 수
# 강남구 스타벅스는 88개
# 강남구 이디야는 44개
# ...
df1 = cafe_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
df1.head()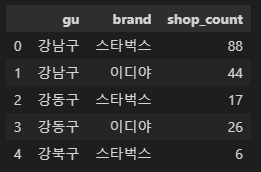
구별 매장 수 더 보기 좋게
# 위 구별 매장 수를 더 보기좋게 : 피봇테이블
# 구별 각 브랜드 매장 수 (피봇테이블)
# shop_count 왜 있지? 위에서 이미 만들어서 있는건가?
import numpy as np
df1.pivot_table(index='gu', columns='brand', aggfunc=np.sum)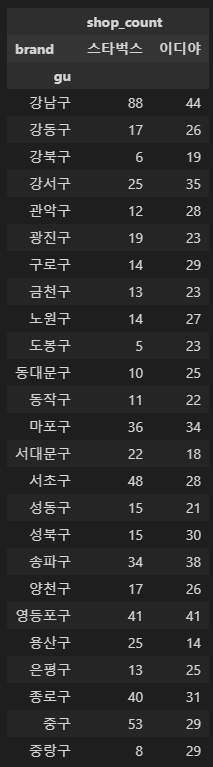
barplot
# 시각화
# 구별 매장 수 차이 1 (피봇테이블 사용x)
plt.figure(figsize=(24, 6))
sns.barplot(data=df1, x=df1['gu'], y=df1['shop_count'], hue='brand', palette='Set1')
plt.show()
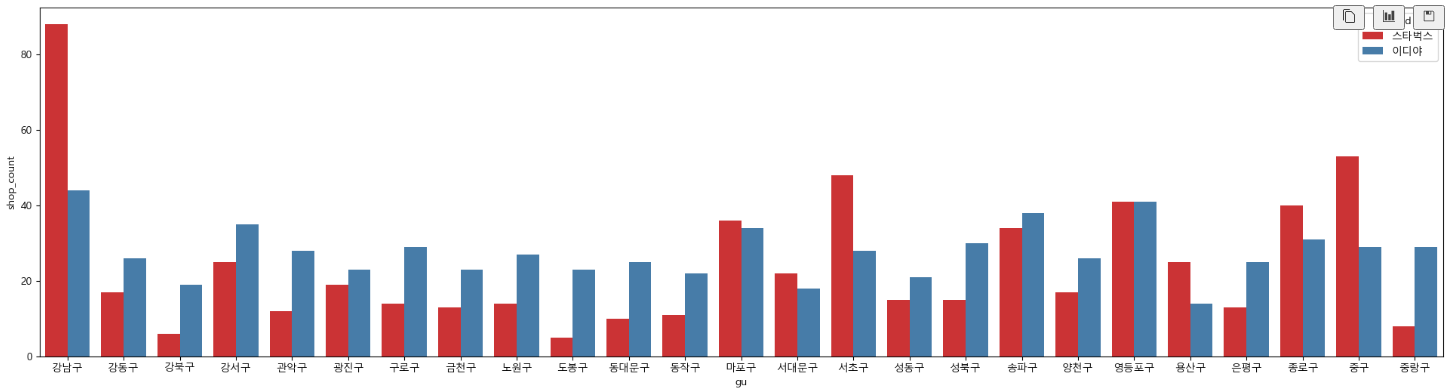
barplot - dodge(겹치기)
# 구별 매장 수 차이 2
# dodge=True : 그래프 안겹치게
# dodge=False : 그래프 겹치게
plt.figure(figsize=(24, 6))
sns.barplot(data=df1, x=df1['gu'], y=df1['shop_count'], hue='brand', dodge=True, alpha=0.8, palette='Set1')
plt.show()
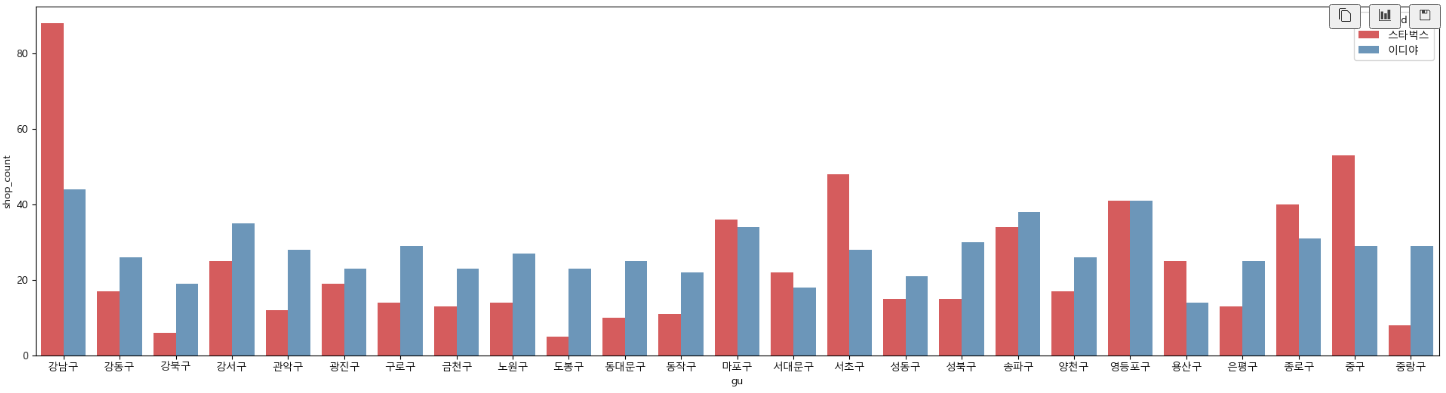
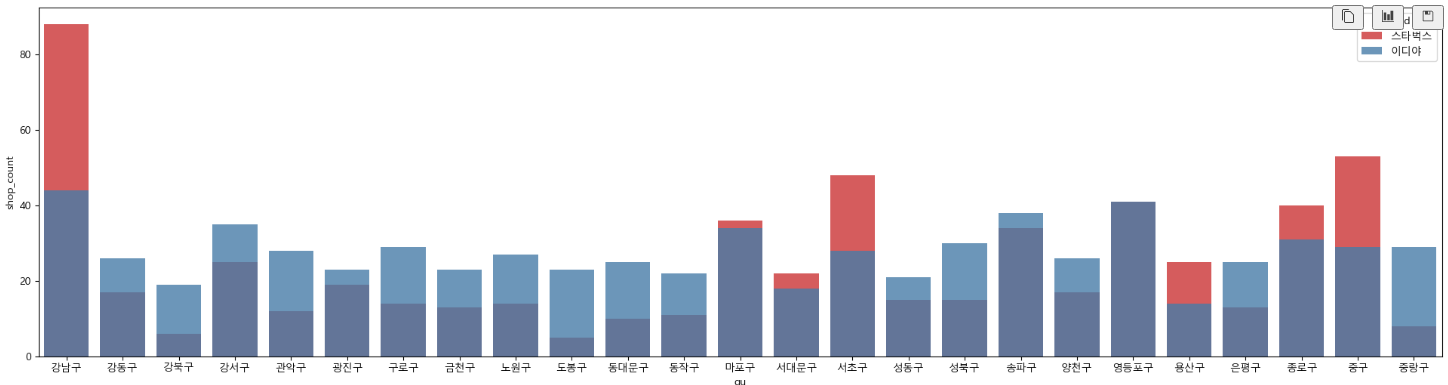
# 구별 매장 수 차이 2
# dodge=True : 그래프 안겹치게
# dodge=False : 그래프 겹치게
# 강남구, 마포구, 서대문구, 서초구, 용산구, 종로구, 중구에서는 스타벅스 매장이 더 많다
# 마포구, 송파구, 영등포구는 매장의 비율이 비슷한 지역인 것을 확인할 수 있다.
# 이디야 매장이 고르게 분포되어 있다.
plt.figure(figsize=(24, 6))
sns.barplot(data=df1, x=df1['gu'], y=df1['shop_count'], hue='brand', dodge=False, alpha=0.8, palette='Set1')
plt.show()
지도 시각화
지도 시각화 데이터프레임(스타벅스)
# 지도 시각화 데이터프레임(스타벅스)
stb_df_m = stb_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
stb_df_m = stb_df_m.pivot_table(index='gu')
stb_df_m.head()
# 지도 시각화 데이터프레임(이디야)
edi_df_m = ediya_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
edi_df_m = edi_df_m.pivot_table(index='gu')
edi_df_m.head()
folium
import folium
import json
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
서울시 지도 나타내기
# 서울시 지도 나타내기
sta_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
sta_m
지도에 구별 경계선 넣기
# 지도에 서울시 구별로 경계선 넣기
sta_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
sta_m.choropleth(
geo_data = geo_str,
data = stb_df_m['shop_count'],
columns = [stb_df_m.index, stb_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
sta_m

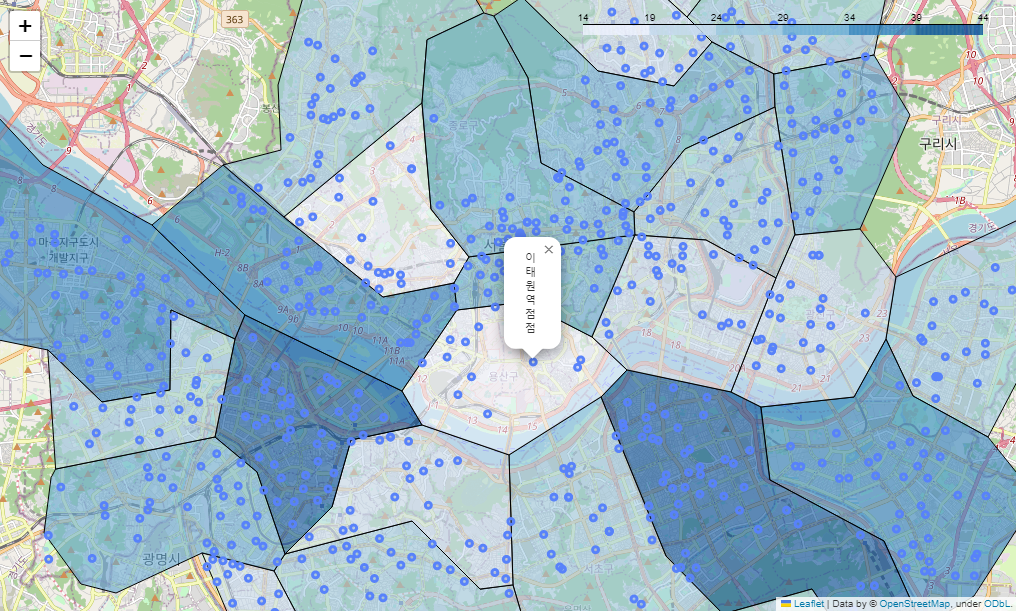
스타벅스 매장 시각화
# 스타벅스 매장 시각화
# 위 경계선 지도 데이터에 folium 만 더함
sta_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
sta_m.choropleth(
geo_data = geo_str,
data = stb_df_m['shop_count'],
columns = [stb_df_m.index, stb_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
for idx, rows in stb_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#2c9147',
fill_color='#2c9147'
).add_to(sta_m)
sta_m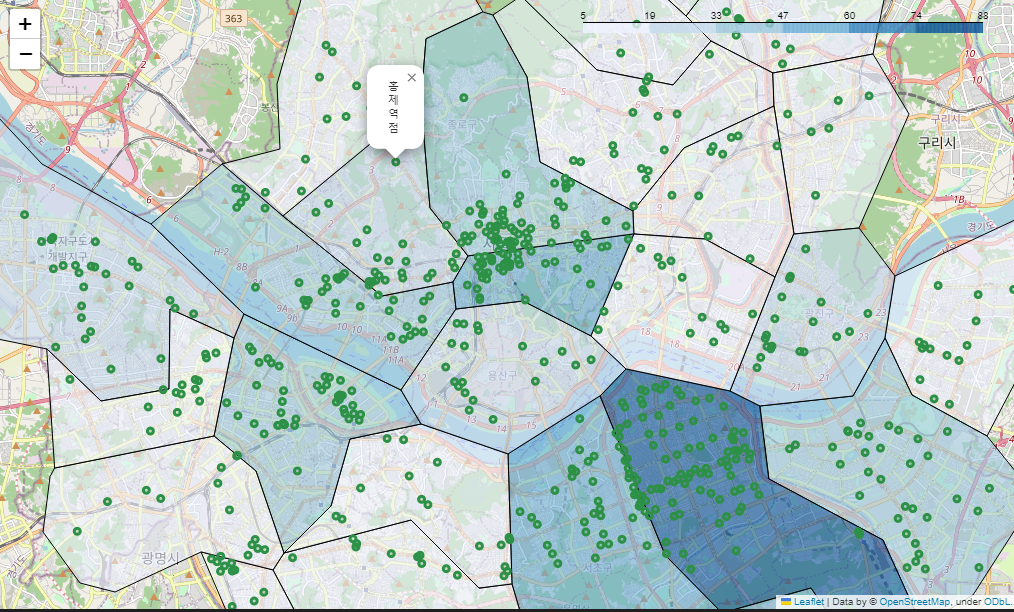
이디야 매장 시각화
# 이디야 매장 시각화
edi_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
edi_m.choropleth(
geo_data = geo_str,
data = edi_df_m['shop_count'],
columns = [edi_df_m.index, edi_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
for idx, rows in ediya_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#5882FA',
fill_color='#5882FA'
).add_to(edi_m)
edi_m
스타벅스+이디야 시각화
# 스타벅스 + 이디야 매장 지도 시각화(스타벅스 기준)
sta_edi_m = folium.Map(location=[37.5502, 126.982], zoom_start=12)
# 스타벅스 매장 기준 경계선
sta_edi_m.choropleth(
geo_data = geo_str,
data = stb_df_m['shop_count'],
columns = [stb_df_m.index, stb_df_m['shop_count']],
fiil_color = 'PuRd',
key_on = 'feature.id'
)
# 스타벅스 folium
for idx, rows in stb_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#2c9147',
fill_color='#2c9147'
).add_to(sta_edi_m)
# 이디야 folium
for idx, rows in ediya_df.iterrows():
folium.Circle(
location=[rows['lat'], rows['lng']],
radius=100,
popup=rows['title'] + '점',
color='#5882FA',
fill_color='#5882FA'
).add_to(sta_edi_m)
sta_edi_m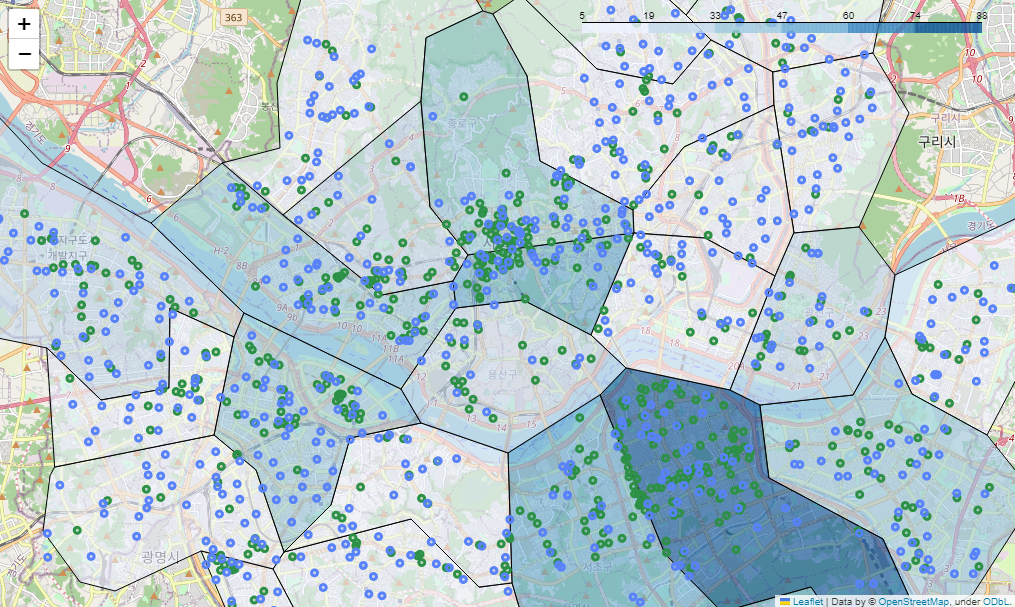
folium.Circle
- 데이터 준비
# 데이터 준비
df2 = cafe_df.groupby(['gu', 'brand'])['title'].count().reset_index(name='shop_count')
df2.head()
- 피봇테이블로 만들기
# 위 데이터에서는 shop_count 가 컬럼값이었는데,
# 여기에서는 values 값으로 넣어서 컬럼으로 안나오게 함
totalCnt = df2.pivot_table(index='gu', columns='brand', values='shop_count', aggfunc=np.sum)
totalCnt.head()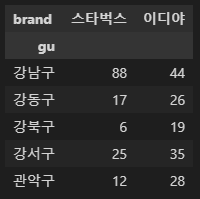
- 구글맵스로 위도, 경도 넣기
# 위도, 경도 nan 값으로 컬럼 만들고
# 구글맵스 임포트해서 위도, 경도 넣기
import googlemaps
gmaps_key = '키값넣기'
gmaps = googlemaps.Client(key=gmaps_key)
totalCnt["위도"] = np.nan
totalCnt["경도"] = np.nan
# 무슨 위도, 경도를 불러온거지?
# 구의 위도, 경도를 가져올 수 있나보네?
for idx, rows in totalCnt.iterrows():
tmp = gmaps.geocode(idx, language='ko')
if tmp:
lat= tmp[0].get("geometry")["location"]["lat"]
lng= tmp[0].get("geometry")["location"]["lng"]
totalCnt.loc[idx,"위도"]=lat
totalCnt.loc[idx,"경도"]=lng
else:
print(idx)
totalCnt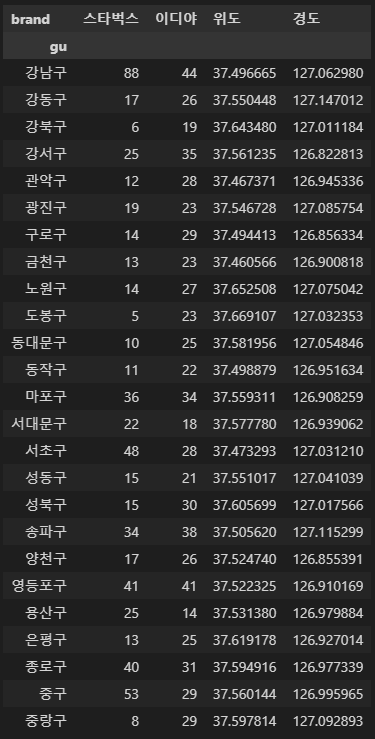
- folium.Circle
seoul = [37.517692, 126.989912]
resultMap = folium.Map(
location=seoul,
zoom_start=11,
tiles="OpenStreetMap"
)
for idx, rows in totalCnt.iterrows():
#스타벅스 --> 파란 원
folium.Circle(
location=[rows["위도"], rows["경도"]],
radius = rows["스타벅스"]* 50,
fill = True,
color = 'blue',
popup = idx,
tooltip = idx
).add_to(resultMap)
#이디야--> 붉은 원
folium.Circle(
location=[rows["위도"], rows["경도"]],
radius = rows["이디야"]* 50,
fill = True,
color = 'red',
popup = idx,
tooltip = idx
).add_to(resultMap)
resultMap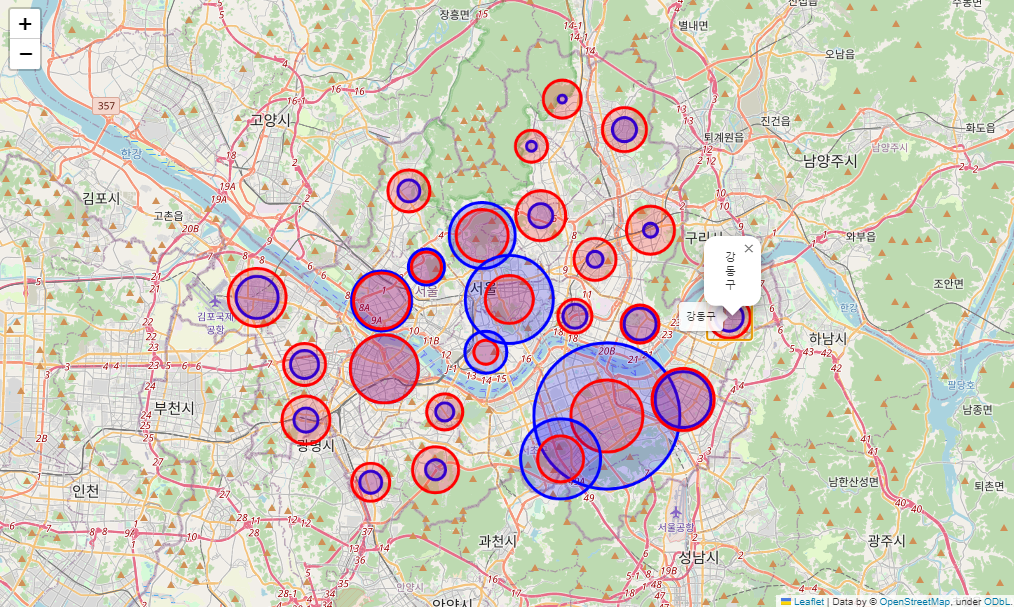
위 글은 제로베이스 데이터 취업 스쿨의 강의자료를 참고하여 작성되었습니다.

허재