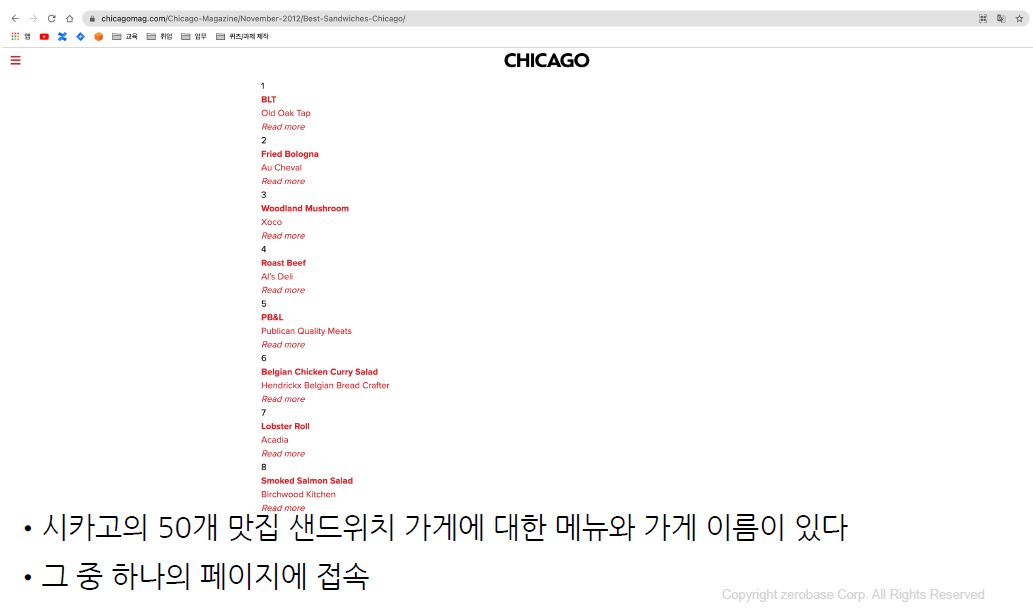













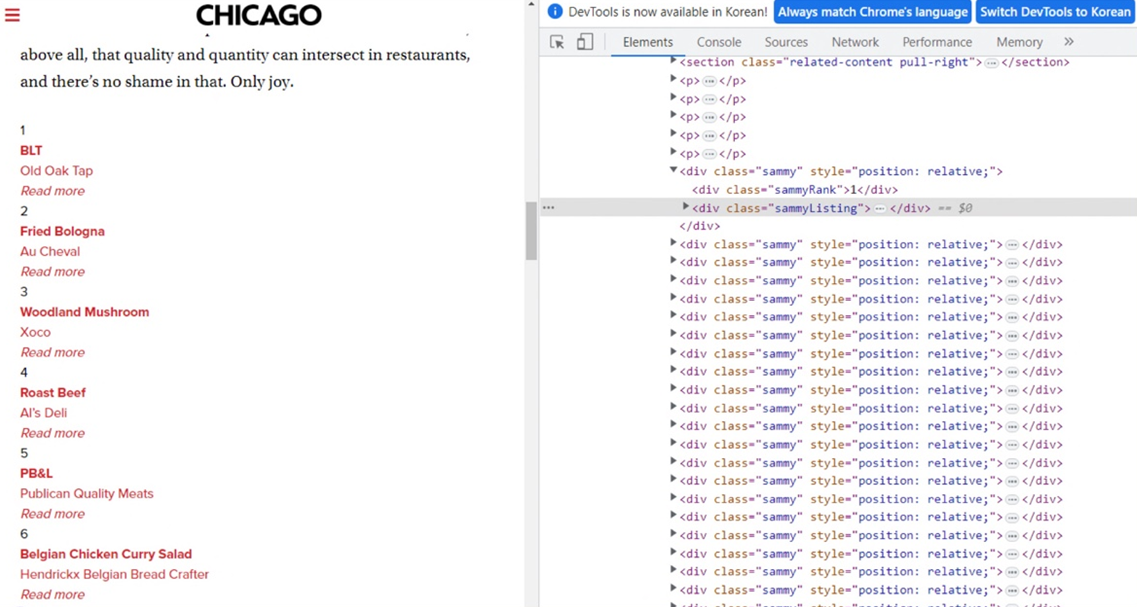
# 최종 목표
# 총 51개 페이지에서 각 가게의 정보를 가져온다
# - 가게임
# - 대표메뉴
# - 대표메뉴의 가격
# - 가게주소
# 주소 https://www.chicagomag.com/chicago-magazine/november-2012/best-sandwiches-chicago/
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
# reponse = urlopen(url)
# 위처럼하면 HTTPError: HTTP Error 403: Forbidden 가 나옴
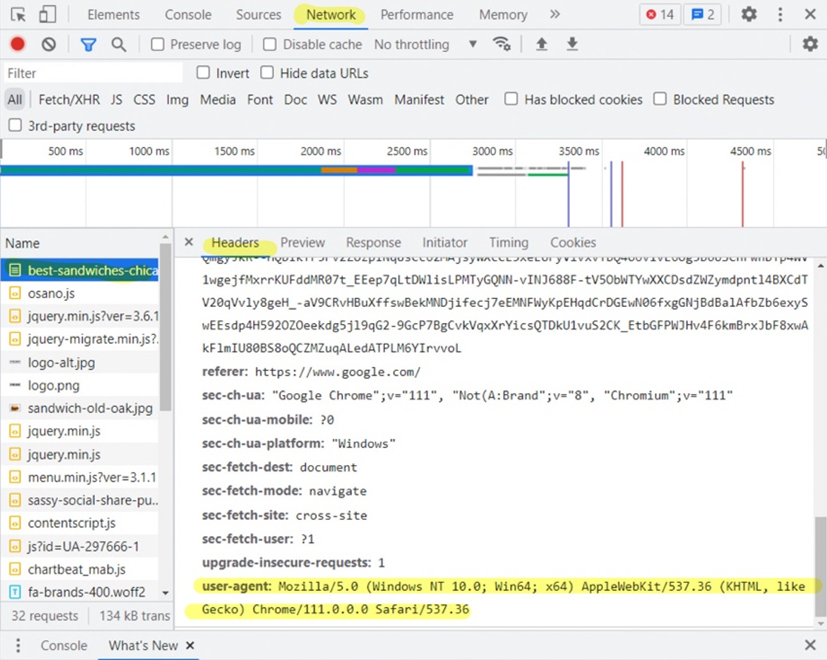
# 서버에서 막은것, 아래처럼 해결
# 크롬 > 개발자도구 > Network 에서 왼쪽 Name 에서 제일 위를 클릭 후
# 오른쪽에서 Request Headers 에서 아래와 같이 적혀있다.
# 이걸 넣어주면 된다
# user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36
# 즉 우선 위처럼 그냥 접속해보고, 안되면 headers 값을 주자
req = Request(url, headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"})
html = urlopen(req)
html
>>
<http.client.HTTPResponse at 0x2d3574f8f10>
--------------------------------------------------
html.status
>> 200
--------------------------------------------------
# 아래처럼 간단하게 해줘도 된다.
req = Request(url, headers={"User-Agent": "Chrome"})
html = urlopen(req)
html
>>
<http.client.HTTPResponse at 0x2d355156be0>
--------------------------------------------------
# UserAgent 값 랜덤 생성기
from fake_useragent import UserAgent
ua = UserAgent()
ua.ie
# 나는 에러뜸...
req = Request(url, headers={"User-Agent": ua.ie})
reponse = urlopen(req)
reponse
--------------------------------------------------
html = urlopen(req)
soup = BeautifulSoup(html, "html.parser")
print(soup.prettify())
>>
Output exceeds the size limit. Open the full output data in a text editor<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge" http-equiv="X-UA-Compatible">
<link href="https://gmpg.org/xfn/11" rel="profile"/>
<script src="https://cmp.osano.com/16A1AnRt2Fn8i1unj/f15ebf08-7008-40fe-9af3-db96dc3e8266/osano.js">
</script>
<title>
The 50 Best Sandwiches in Chicago – Chicago Magazine
</title>
<style type="text/css">
.heateor_sss_button_instagram span.heateor_sss_svg,a.heateor_sss_instagram span.heateor_sss_svg{background:radial-gradient(circle at 30% 107%,#fdf497 0,#fdf497 5%,#fd5949 45%,#d6249f 60%,#285aeb 90%)}
div.heateor_sss_horizontal_sharing a.heateor_sss_button_instagram span{background:#000!important;}div.heateor_sss_standard_follow_icons_container a.heateor_sss_button_instagram span{background:#000;}
.heateor_sss_horizontal_sharing .heateor_sss_svg,.heateor_sss_standard_follow_icons_container .heateor_sss_svg{
background-color: #000!important;
background: #000!important;
color: #fff;
border-width: 0px;
border-style: solid;
border-color: transparent;
}
.heateor_sss_horizontal_sharing .heateorSssTCBackground{
color:#666;
}
...
</script>
</body>
</html>
--------------------------------------------------
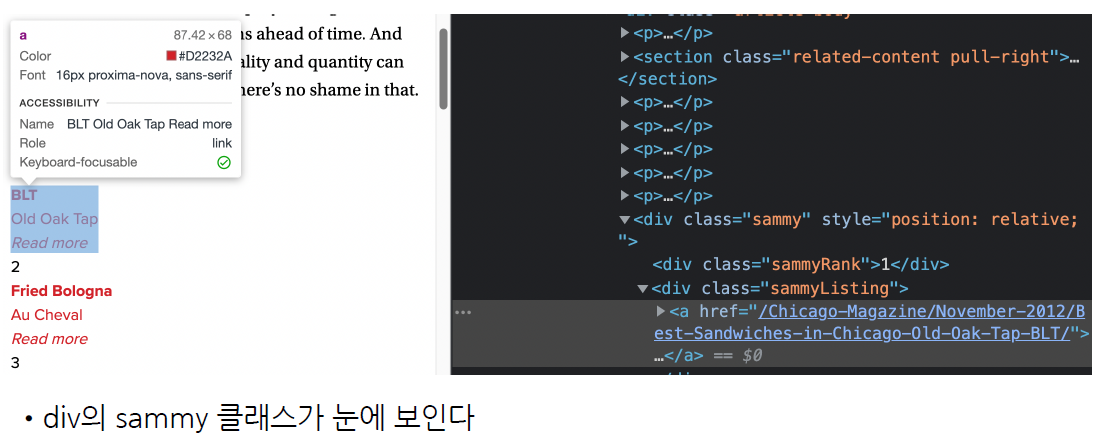
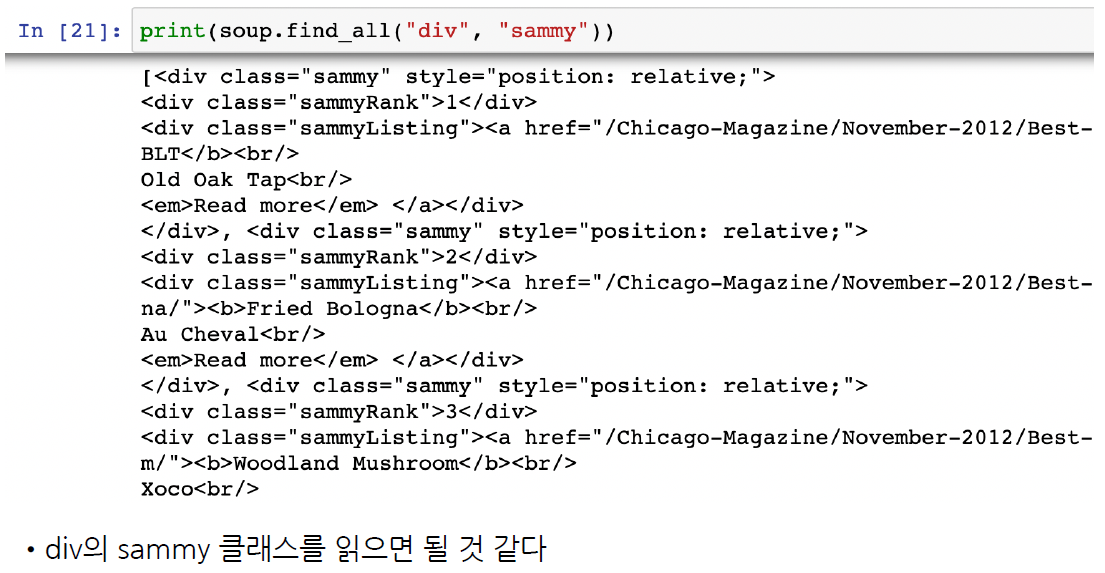
# 태그가 div 이고, class 가 "sammy" 인걸 찾아보자
soup.find_all("div", "sammy")
# soup.select(".sammy")
>>
Output exceeds the size limit. Open the full output data in a text editor[<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>,
<div class="sammy" style="position: relative;">
<div class="sammyRank">2</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/"><b>Fried Bologna</b><br/>
Au Cheval<br/>
<em>Read more</em> </a></div>
</div>,
<div class="sammy" style="position: relative;">
<div class="sammyRank">3</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/"><b>Woodland Mushroom</b><br/>
Xoco<br/>
<em>Read more</em> </a></div>
</div>,
<div class="sammy" style="position: relative;">
<div class="sammyRank">4</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Als-Deli-Roast-Beef/"><b>Roast Beef</b><br/>
Al’s Deli<br/>
<em>Read more</em> </a></div>
</div>,
<div class="sammy" style="position: relative;">
...
<div class="sammyRank">50</div>
<div class="sammyListing"><a href="https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Phoebes-Bakery-The-Gatsby/"><b>The Gatsby</b><br/>
Phoebe’s Bakery<br/>
<em>Read more</em> </a></div>
</div>]
--------------------------------------------------
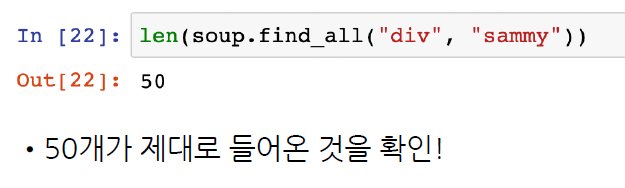
len(soup.find_all("div", "sammy"))
# len(soup.select(".sammy"))
>> 50
--------------------------------------------------
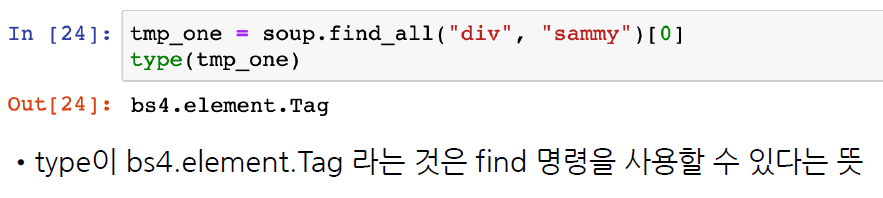
tmp_one = soup.find_all("div", "sammy")[0]
tmp_one
>>
<div class="sammy" style="position: relative;">
<div class="sammyRank">1</div>
<div class="sammyListing"><a href="/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/"><b>BLT</b><br/>
Old Oak Tap<br/>
<em>Read more</em> </a></div>
</div>
--------------------------------------------------
# bs4.element.Tag 이기때문에
# BeautifulSoup 을 쓸 수 있다.
type(tmp_one)
>>
bs4.element.Tag
--------------------------------------------------
tmp_one.find(class_="sammyRank").get_text()
# tmp_one.select_one(".sammyRank").text
>> '1'
--------------------------------------------------
tmp_one.find("div", {"class":"sammyListing"}).get_text()
# tmp_one.select_one(".sammyListing").text
>> 'BLT\nOld Oak Tap\nRead more '
--------------------------------------------------
tmp_one.find("a")["href"]
# tmp_one.select_one("a").get("href")
>>
'/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
--------------------------------------------------
import re
# 위 'BLT\nOld Oak Tap\nRead more ' 을
# \n 또는 \r\n 기준으로 나눠라, 리스트로 반환됨
# \ 는 그냥 엔터키 위 키, | 는 쉬프트 엔터키 위 키
tmp_string = tmp_one.find("div", {"class":"sammyListing"}).get_text()
re.split(("\n|\r\n"), tmp_string)
>> ['BLT', 'Old Oak Tap', 'Read more ']
--------------------------------------------------
print(re.split(("\n|\r\n"), tmp_string)[0])
print(re.split(("\n|\r\n"), tmp_string)[1])
print(re.split(("\n|\r\n"), tmp_string)[2])
>>
BLT
Old Oak Tap
Read more
--------------------------------------------------
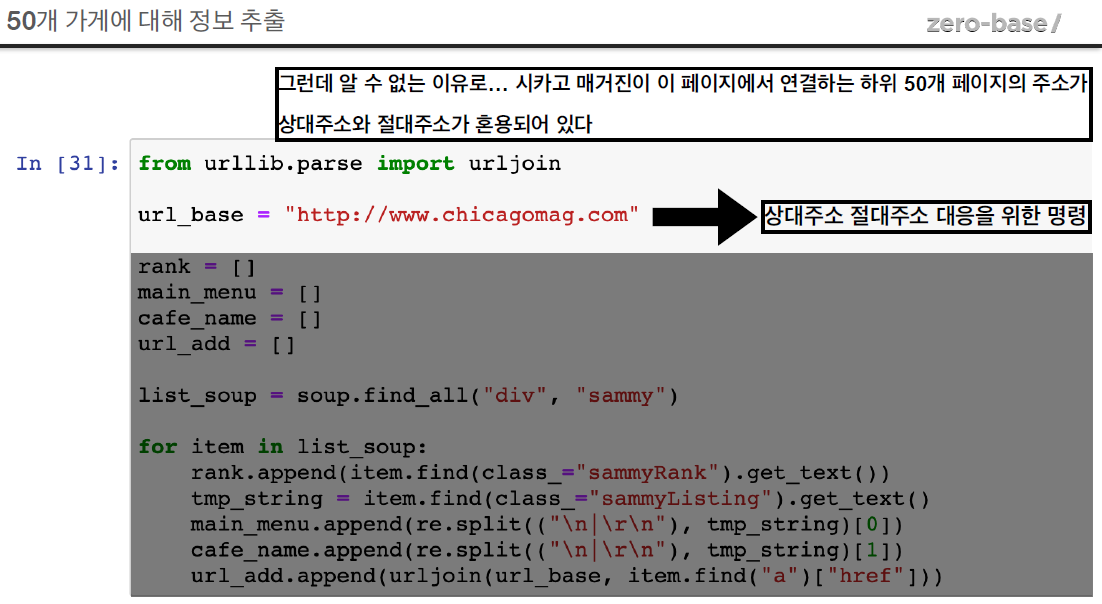
from urllib.parse import urljoin
url_base = "https://www.chicagomag.com/"
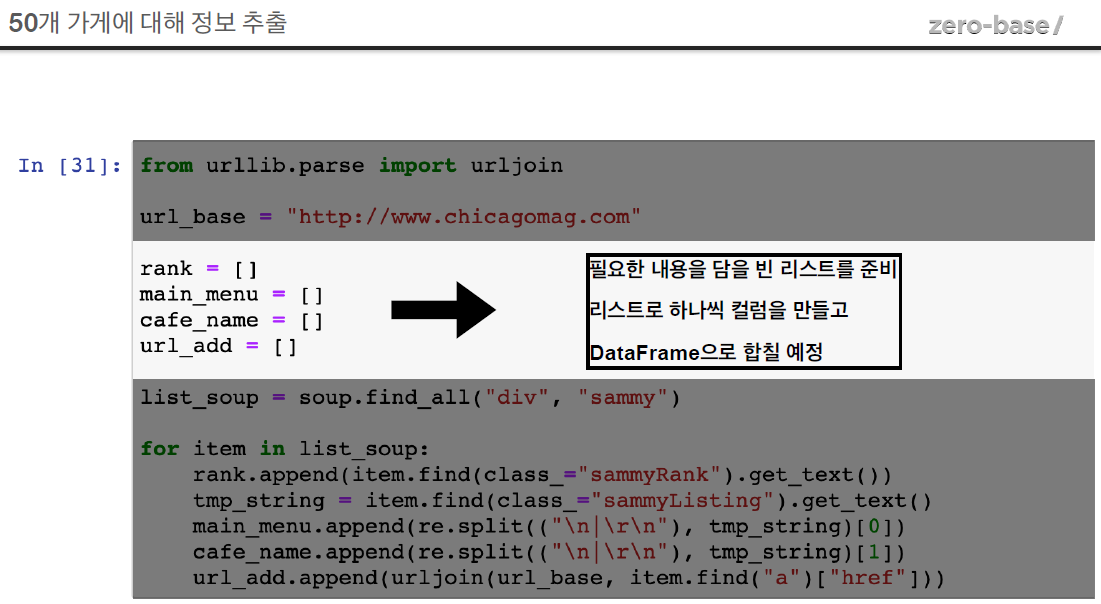
# 필요한 내뇽을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_menu = []
url_add = []
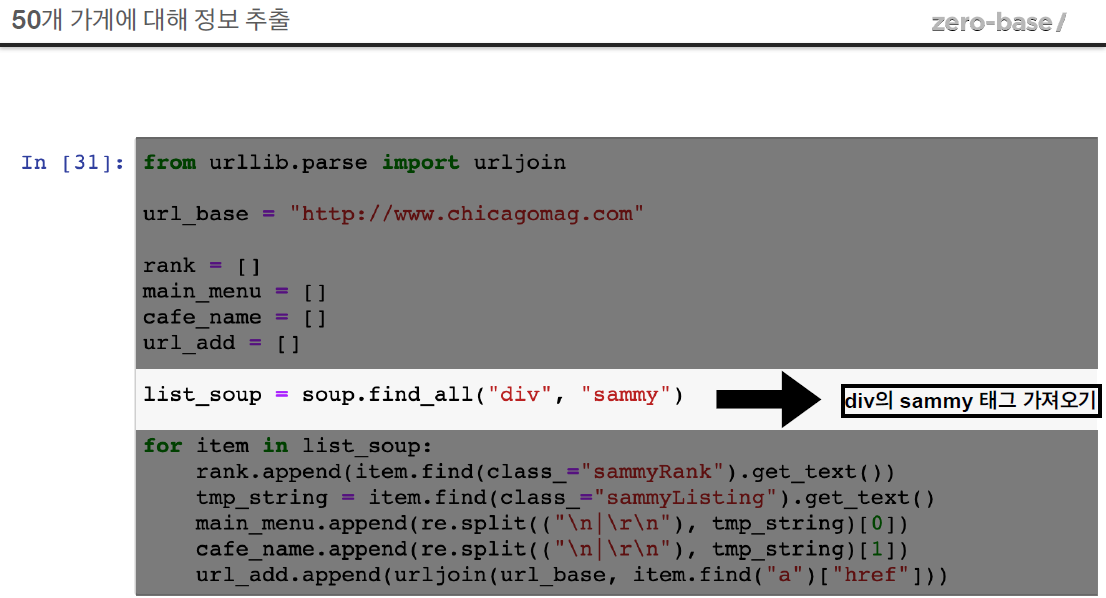
list_soup = soup.find_all("div", "sammy")
# soup.select(".sammy")
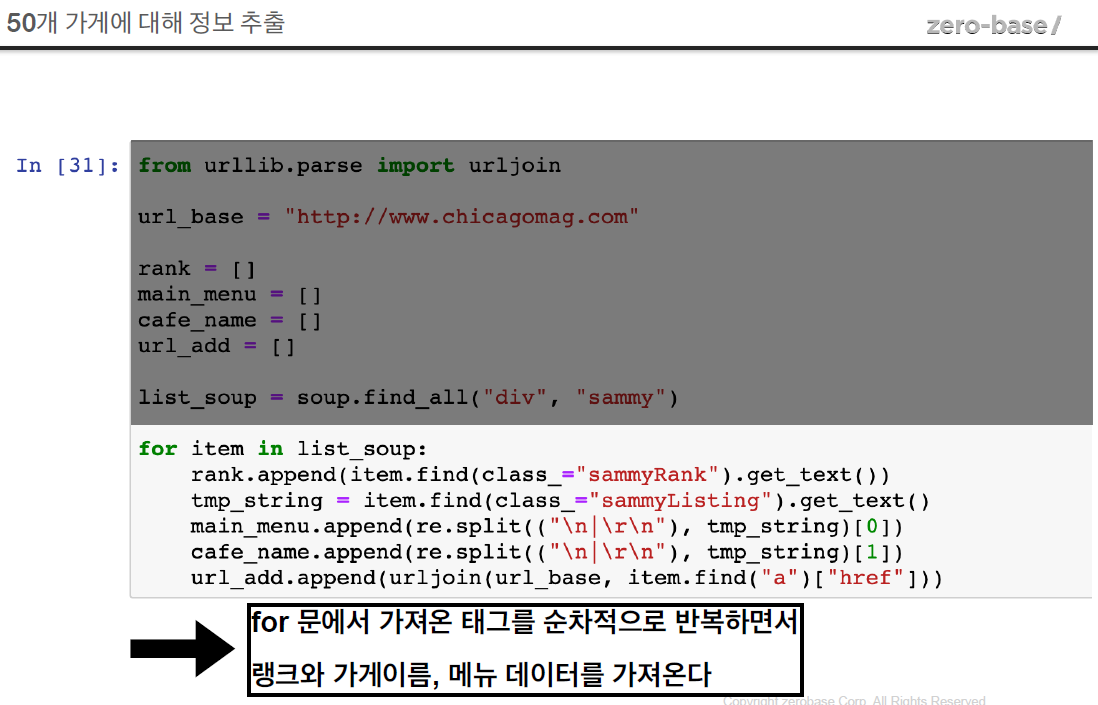
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
# 마지막에 .get_text() 붙이면 에러뜸
# 'NoneType' object has no attribute 'get_text'
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_menu.append(re.split(("\n|\r\n"), tmp_string)[1])
# urljoin : url_base 가 없으면 붙이고, 있으면 안붙이고
url_add.append(urljoin(url_base, item.find("a")["href"]))
len(rank), len(main_menu), len(cafe_menu), len(url_add)
>> (50, 50, 50, 50)
--------------------------------------------------
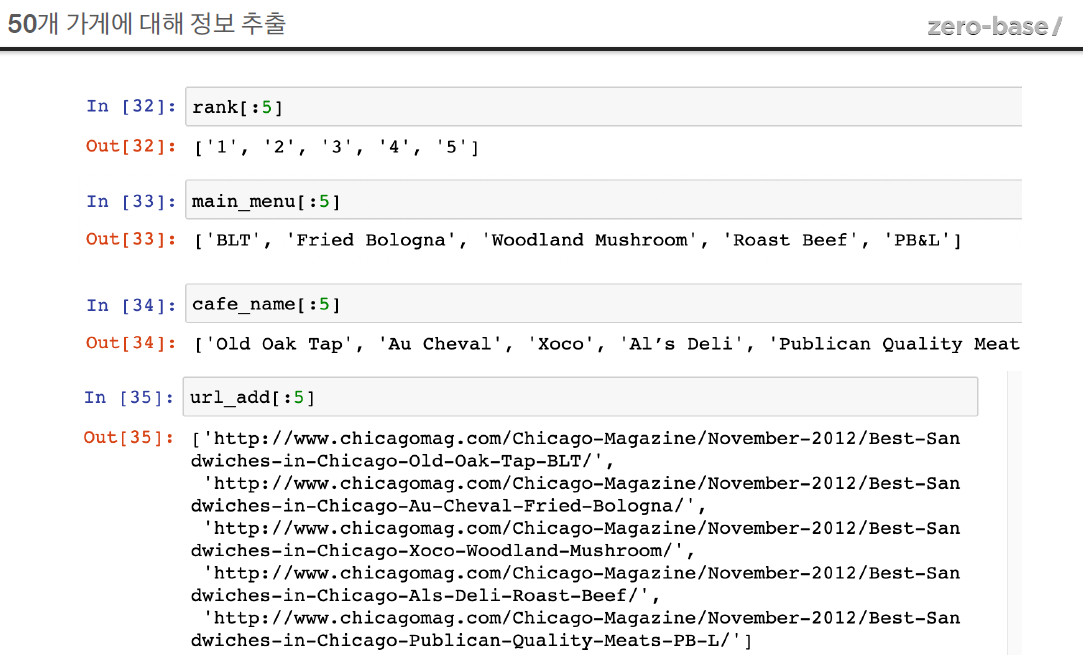
rank[:5]
>> ['1', '2', '3', '4', '5']
main_menu[:5]
>> ['BLT', 'Fried Bologna', 'Woodland Mushroom', 'Roast Beef', 'PB&L']
cafe_menu[:5]
>> ['Old Oak Tap', 'Au Cheval', 'Xoco', 'Al’s Deli', 'Publican Quality Meats']
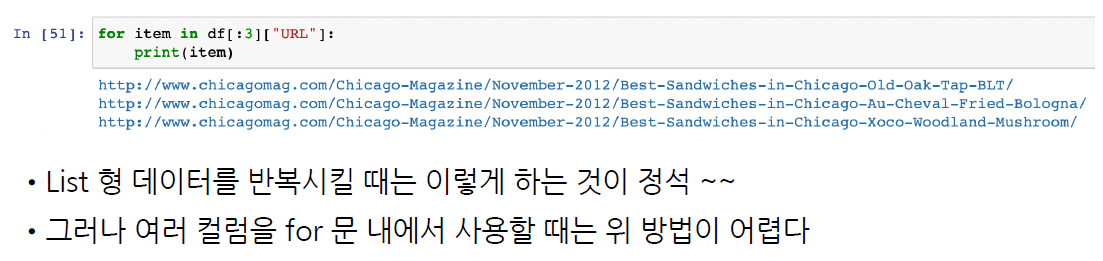
url_add[:5]
>>
['https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Au-Cheval-Fried-Bologna/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Xoco-Woodland-Mushroom/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Als-Deli-Roast-Beef/',
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Publican-Quality-Meats-PB-L/']
--------------------------------------------------
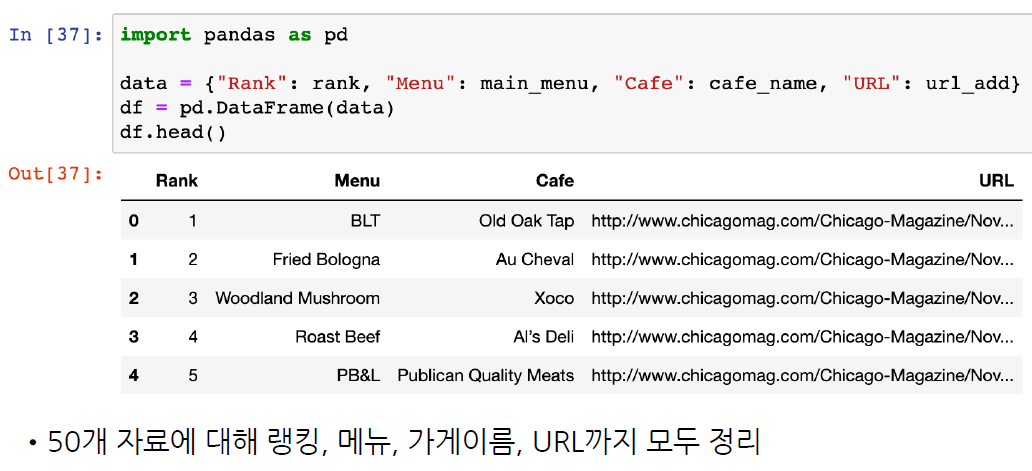
# 데이터 프레임으로 만들기
import pandas as pd
data = {
"Rank" : rank,
"Menu" : main_menu,
"Cafe" : cafe_menu,
"URL" : url_add
}
df = pd.DataFrame(data)
df
>>
Rank Menu Cafe URL
0 1 BLT Old Oak Tap https://www.chicagomag.com/Chicago-Magazine/No...
1 2 Fried Bologna Au Cheval https://www.chicagomag.com/Chicago-Magazine/No...
2 3 Woodland Mushroom Xoco https://www.chicagomag.com/Chicago-Magazine/No...
3 4 Roast Beef Al’s Deli https://www.chicagomag.com/Chicago-Magazine/No...
....
48 49 Le Végétarien Toni Patisserie https://www.chicagomag.com/Chicago-Magazine/No...
49 50 The Gatsby Phoebe’s Bakery https://www.chicagomag.com/Chicago-Magazine/No...
--------------------------------------------------
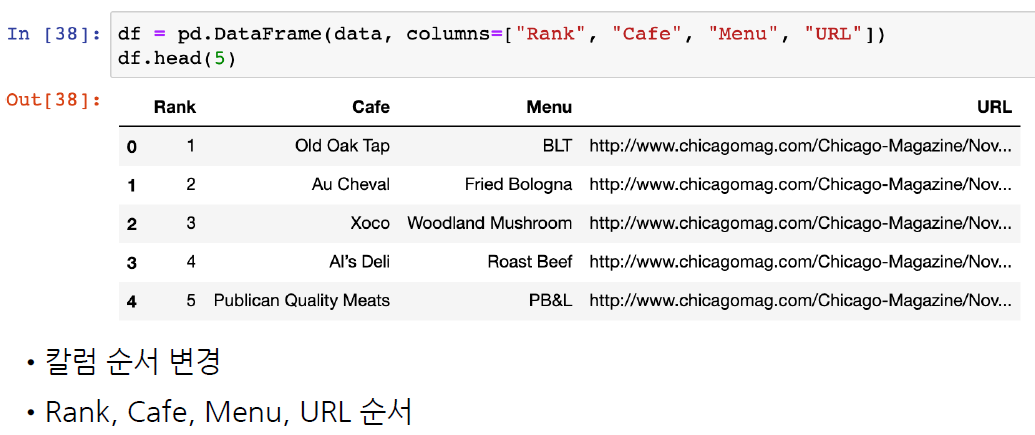
# 컬럼 순서 변경
df = pd.DataFrame(data, columns=["Rank", "Cafe", "Menu", "URL"])
df.tail()
>>
Rank Cafe Menu URL
45 46 Chickpea Kufta https://www.chicagomag.com/Chicago-Magazine/No...
46 47 The Goddess and Grocer Debbie’s Egg Salad https://www.chicagomag.com/Chicago-Magazine/No...
47 48 Zenwich Beef Curry https://www.chicagomag.com/Chicago-Magazine/No...
48 49 Toni Patisserie Le Végétarien https://www.chicagomag.com/Chicago-Magazine/No...
49 50 Phoebe’s Bakery The Gatsby https://www.chicagomag.com/Chicago-Magazine/No...
--------------------------------------------------
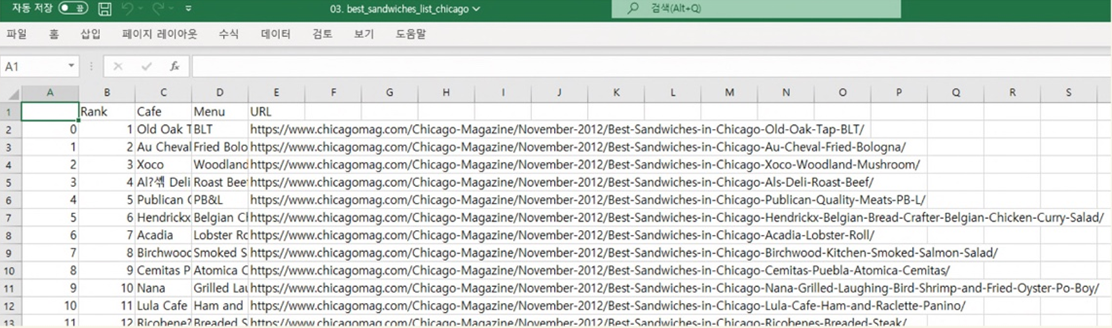
# 데이터 저장
df.to_csv(
"../data/03. best_sandwiches_list_chicago.csv", sep=",", encoding="utf-8"
--------------------------------------------------
시카고 맛집 데이터 분석 - 하위페이지


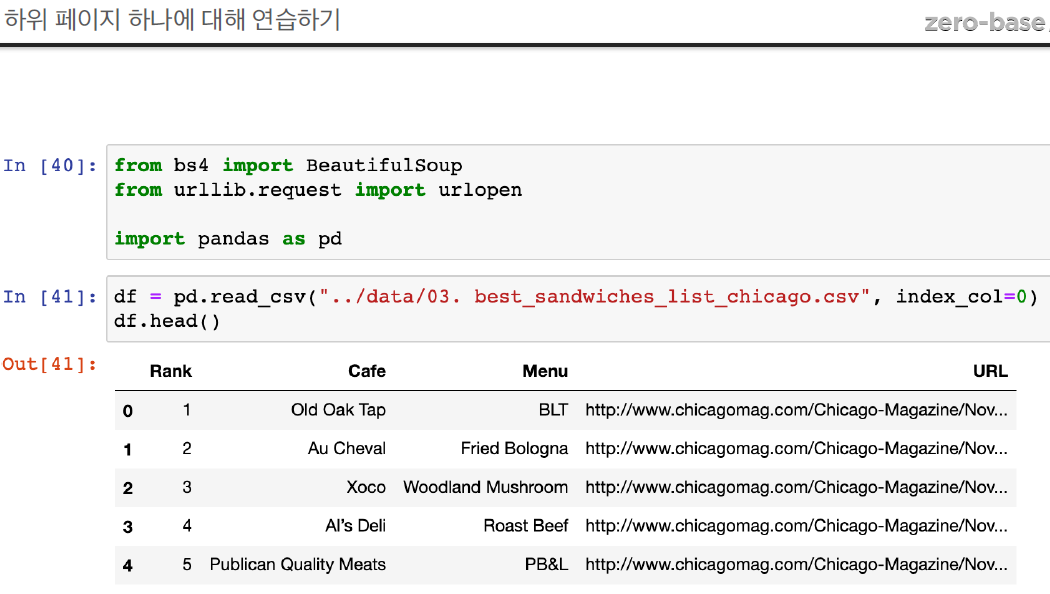











import pandas as pd
from urllib.request import urlopen, Request
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
# 1 부터 50까지의 URL 주소로 들어가서 메뉴의 가격, 가게 주소 가져오기
df = pd.read_csv("../data/03. best_sandwiches_list_chicago.csv", index_col=0)
df.tail()
>>
Rank Cafe Menu URL
45 46 Chickpea Kufta https://www.chicagomag.com/Chicago-Magazine/No...
46 47 The Goddess and Grocer Debbie’s Egg Salad https://www.chicagomag.com/Chicago-Magazine/No...
47 48 Zenwich Beef Curry https://www.chicagomag.com/Chicago-Magazine/No...
48 49 Toni Patisserie Le Végétarien https://www.chicagomag.com/Chicago-Magazine/No...
49 50 Phoebe’s Bakery The Gatsby https://www.chicagomag.com/Chicago-Magazine/No...
--------------------------------------------------
# 우선 하나만 실험
df.URL[0]
>>
'https://www.chicagomag.com/Chicago-Magazine/November-2012/Best-Sandwiches-in-Chicago-Old-Oak-Tap-BLT/'
--------------------------------------------------
# 우선 하나만 실험
req = Request(df["URL"][0], headers={"user-agent":"Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
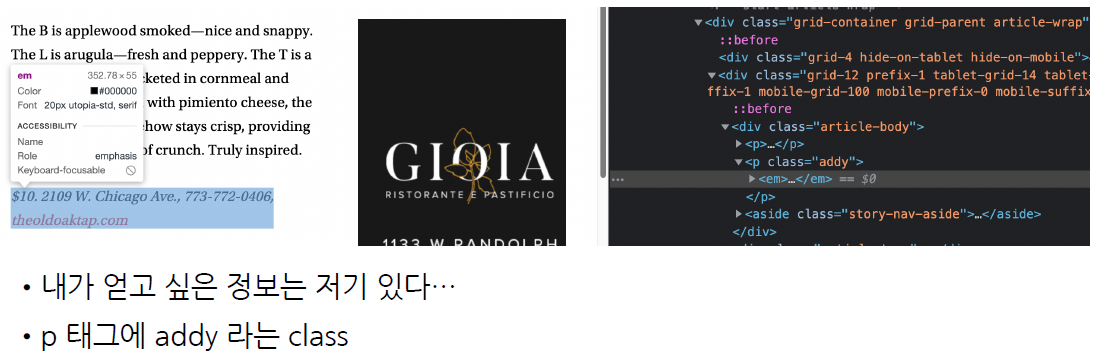
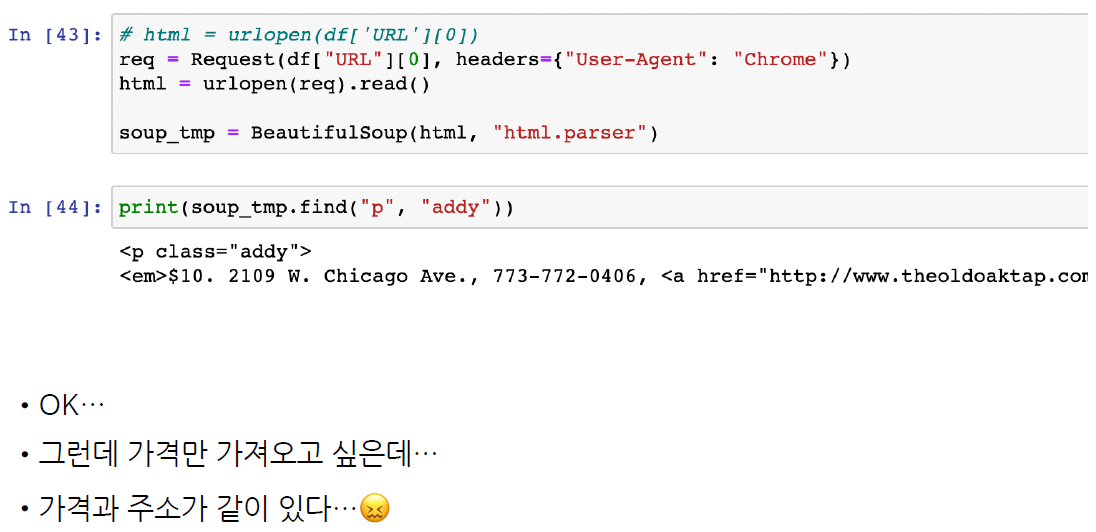
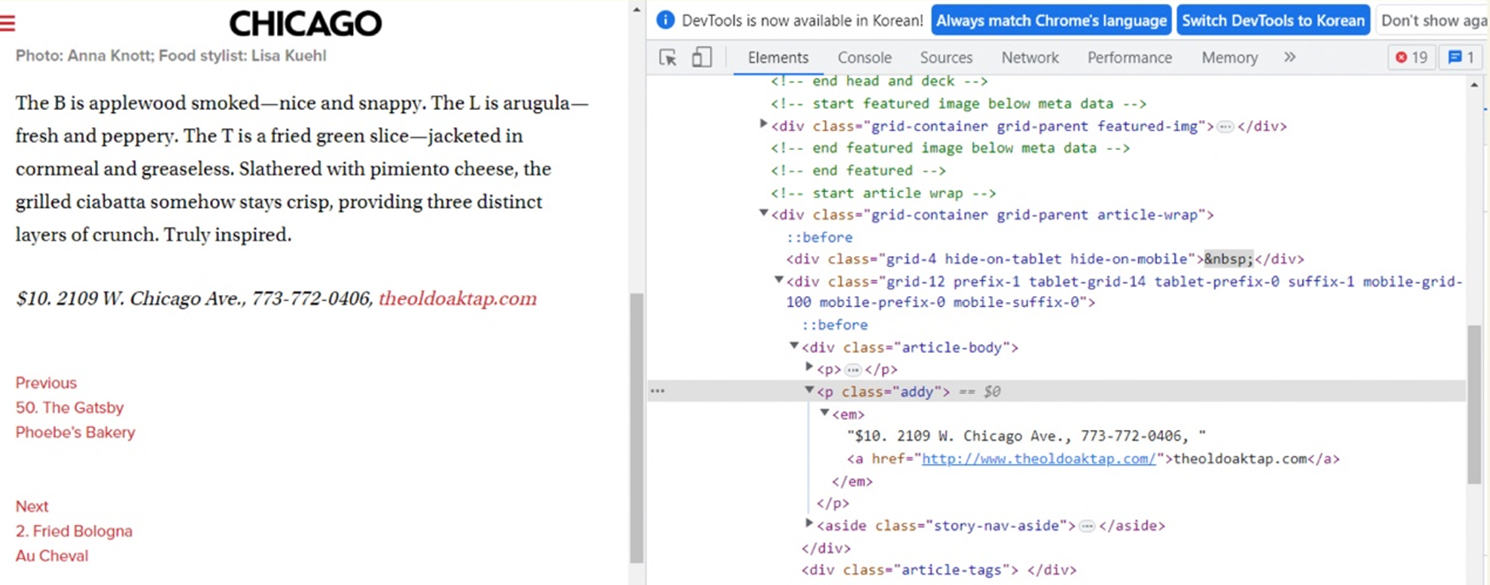
soup_tmp.find("p", "addy")
# soup_tmp.select_one(".addy")
>>
<p class="addy">
<em>$10. 2109 W. Chicago Ave., 773-772-0406, <a href="http://www.theoldoaktap.com/">theoldoaktap.com</a></em></p>
--------------------------------------------------
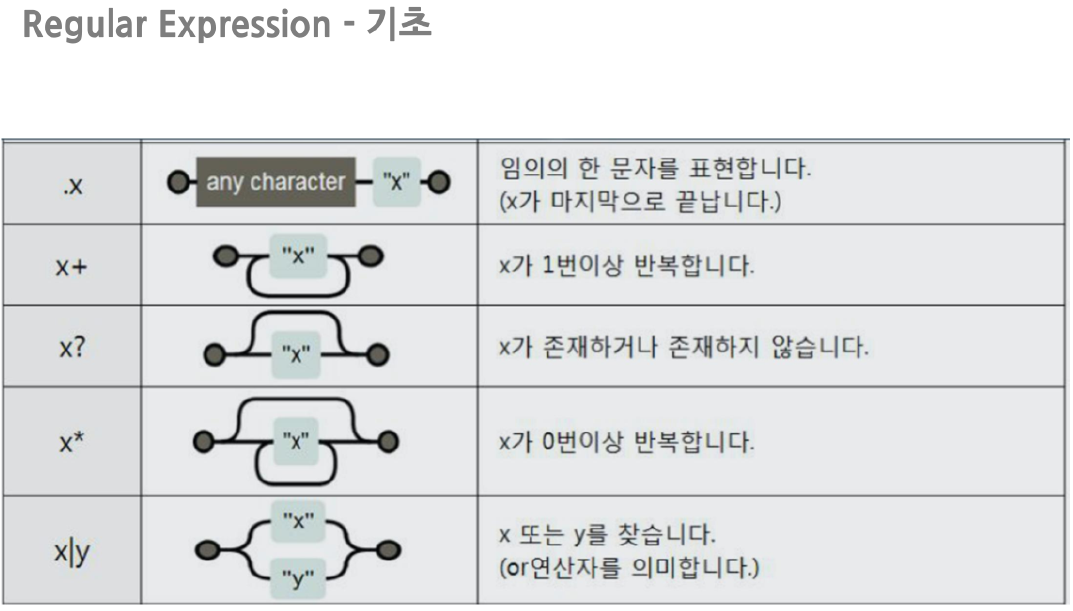
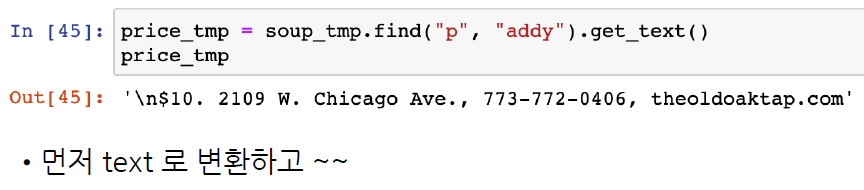
# regular expression 정규표현식 사용하기
price_tmp = soup_tmp.find("p", "addy").text
price_tmp
# \n$10. 2109 W. Chicago Ave. 만 필요하다. 뒤에는 필요없음
>>
'\n$10. 2109 W. Chicago Ave., 773-772-0406, theoldoaktap.com'
--------------------------------------------------
# regular expression 정규표현식 사용하기
import re
re.split(".,", price_tmp)
>>
['\n$10. 2109 W. Chicago Ave', ' 773-772-040', ' theoldoaktap.com']
--------------------------------------------------
price_tmp = re.split(".,", price_tmp)[0]
price_tmp
>> '\n$10. 2109 W. Chicago Ave'
--------------------------------------------------
re.search("\$\d+\.(\d+)?", price_tmp)
# 아래는 필터링한 raw 데이터
>> <re.Match object; span=(1, 5), match='$10.'>
--------------------------------------------------
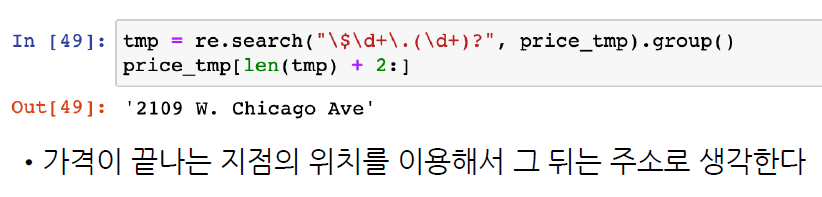
re.search("\$\d+\.(\d+)?", price_tmp).group()
>>'$10.'
--------------------------------------------------
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price_tmp[len(tmp) + 2:]
# '\n$10. 2109 W. Chicago Ave' 에서 가격이 끝나고 공백 지나고 부터 가져와라
>> '2109 W. Chicago Ave'
--------------------------------------------------
# 일단 3개 데이터 가져오기
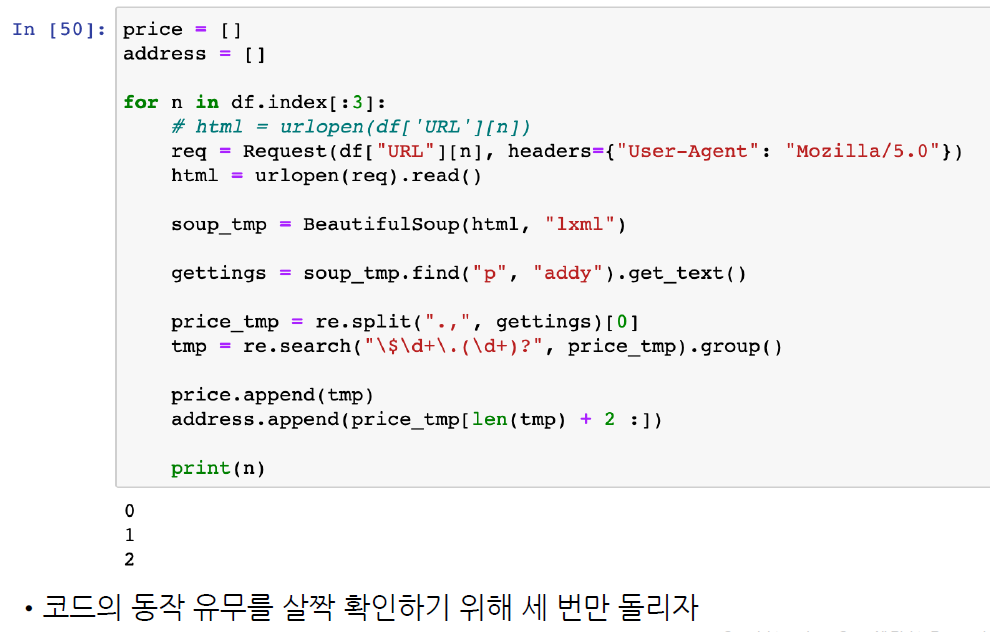
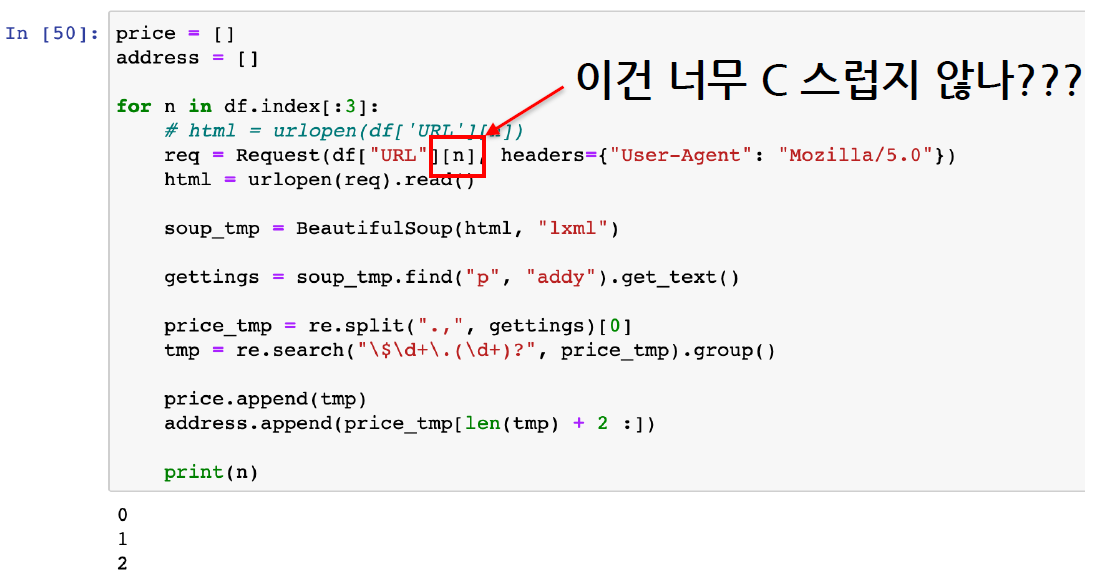
price = []
address = []
for n in df.index[:3]:
req = Request(df["URL"][n], headers={"user-agent":"Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
print(n)
>>
0
1
2
--------------------------------------------------
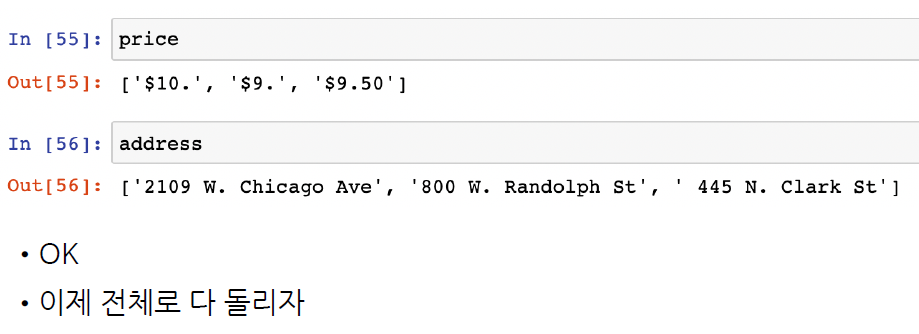
price, address
>>
(['$10.', '$9.', '$9.50'],
['2109 W. Chicago Ave', '800 W. Randolph St', ' 445 N. Clark St'])
--------------------------------------------------
# 일단 3개 데이터 가져오기
# 파이썬스럽게 바꾸기
price = []
address = []
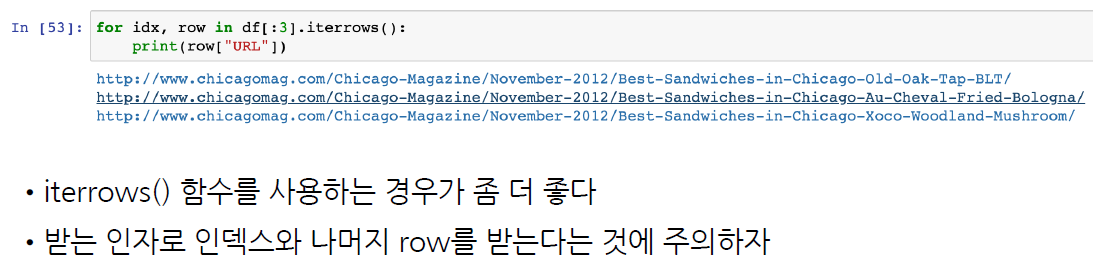
for idx, row in df[:3].iterrows():
req = Request(row["URL"], headers={"user-agent":"Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
print(idx)
--------------------------------------------------
from tqdm import tqdm
# 50개 데이터 가져오기
price = []
address = []
for idx, row in df.iterrows():
req = Request(row["URL"], headers={"user-agent":"Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp) + 2:])
print(idx)
>>
Output exceeds the size limit. Open the full output data in a text editor0
1
2
3
4
...
50
--------------------------------------------------
len(price), len(address)
>> (50, 50)
--------------------------------------------------
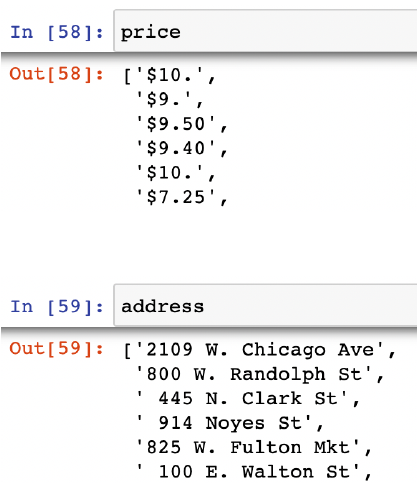
price[:5]
>> ['$10.', '$9.', '$9.50', '$9.40', '$10.']
--------------------------------------------------
address[:5]
>>
['2109 W. Chicago Ave',
'800 W. Randolph St',
' 445 N. Clark St',
' 914 Noyes St',
'825 W. Fulton Mkt']
--------------------------------------------------
# 원본 데이터프레임과 합치기
df.tail(2)
>>
Rank Cafe Menu URL
48 49 Toni Patisserie Le Végétarien https://www.chicagomag.com/Chicago-Magazine/No...
49 50 Phoebe’s Bakery The Gatsby https://www.chicagomag.com/Chicago-Magazine/No...
--------------------------------------------------
df["Price"] = price
df["Address"] = address
df.tail(2)
>>
Rank Cafe Menu URL Price Address
48 49 Toni Patisserie Le Végétarien https://www.chicagomag.com/Chicago-Magazine/No... $8.75 65 E. Washington St
49 50 Phoebe’s Bakery The Gatsby https://www.chicagomag.com/Chicago-Magazine/No... $6.85 3351 N. Broadwa
--------------------------------------------------
# 컬럼 수정하기(URL 빼기)
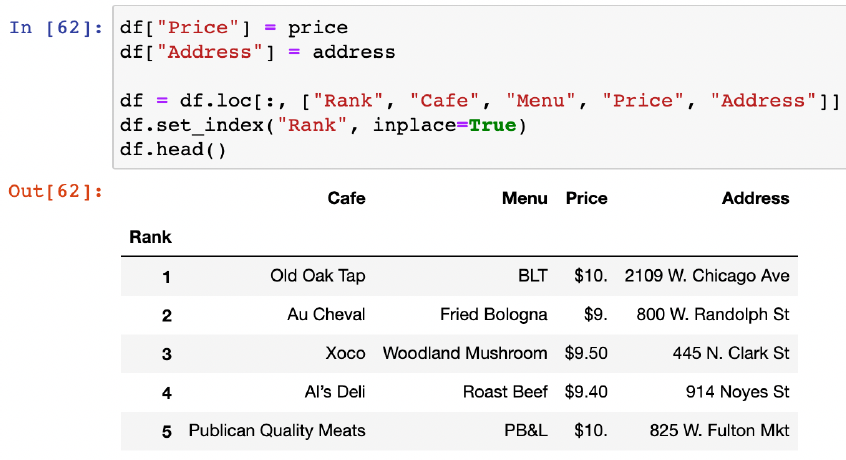
df = df.loc[:, ["Rank", "Cafe", "Menu", "Price", "Address"]]
df.tail(2)
df.set_index("Rank", inplace=True) # 랭크를 인덱스로 넣어주기
# 데이터 저장
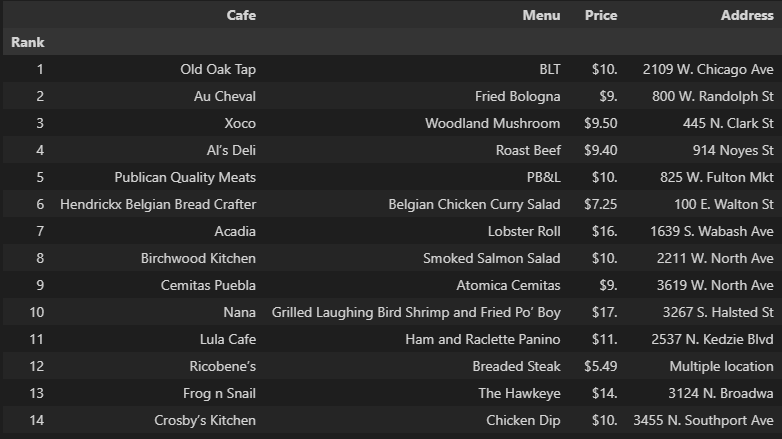
df.to_csv("../data/03. best_sandwiches_list_chicago2.csv", sep=",", encoding="utf-8")
pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
시카고 맛집 데이터 시각화

import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm
df = pd.read_csv("../data/03. best_sandwiches_list_chicago2.csv", index_col=0)
df.tail(2)
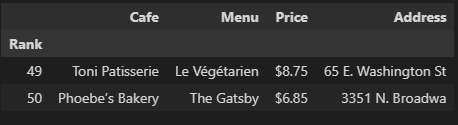
gmaps_key = "AIzaSyCXojm1lXkzaC1J7Xt-iolW74b8Q_eJ-08"
gmaps = googlemaps.Client(key = gmaps_key)
lat = [] # 위도
lng = [] # 경도
# 5개만 실험
# tqdm 넣으니까 안됨 > 그냥 뻄
for idx, row in df[:5].iterrows():
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
print(target_name)
>>
2109 W. Chicago Ave, Chicago
800 W. Randolph St, Chicago
445 N. Clark St, Chicago
914 Noyes St, Chicago
825 W. Fulton Mkt, Chicago
------------------------------
# 구글맵스 활용 시험
for idx, row in df[:5].iterrows():
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
gmaps_output = gmaps.geocode(target_name)
print(gmaps_output) 
# 구글맵스 활용 시험
for idx, row in df[:5].iterrows():
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
gmaps_output = gmaps.geocode(target_name)
print(gmaps_output[0].get("geometry"))

lat = [] # 위도
lng = [] # 경도
# 5개만 실험
# tqdm 넣으니까 안됨 > 그냥 뻄
for idx, row in df[:5].iterrows():
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)
len(lat), len(lng)
>> (5, 5)
-------------------------------------
lat = [] # 위도
lng = [] # 경도
# 50개 가져오기
# tqdm 넣으니까 안됨 > 그냥 뻄
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
gmaps_output = gmaps.geocode(target_name)
location_output = gmaps_output[0].get("geometry")
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)
len(lat), len(lng)
>> (50, 50)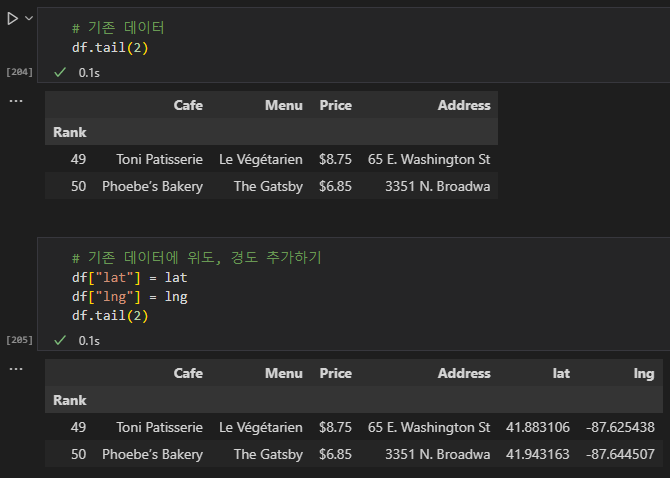
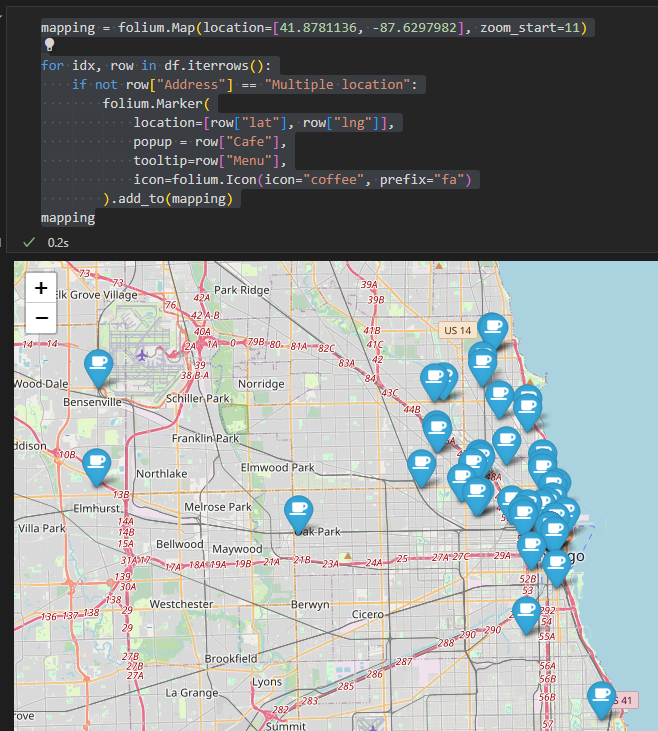
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
mapping
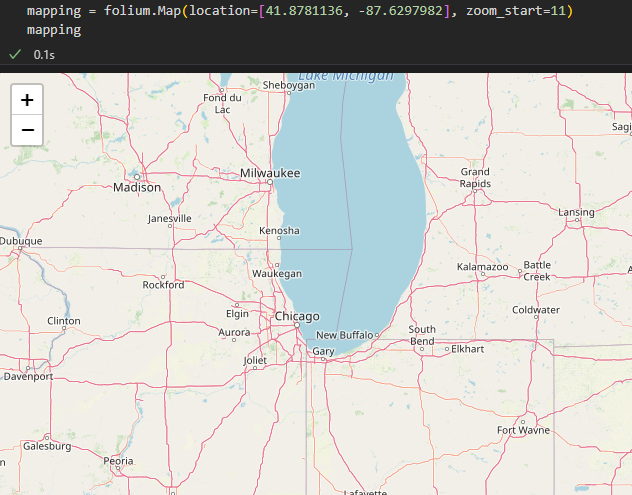
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup = row["Cafe"]
).add_to(mapping)
mapping
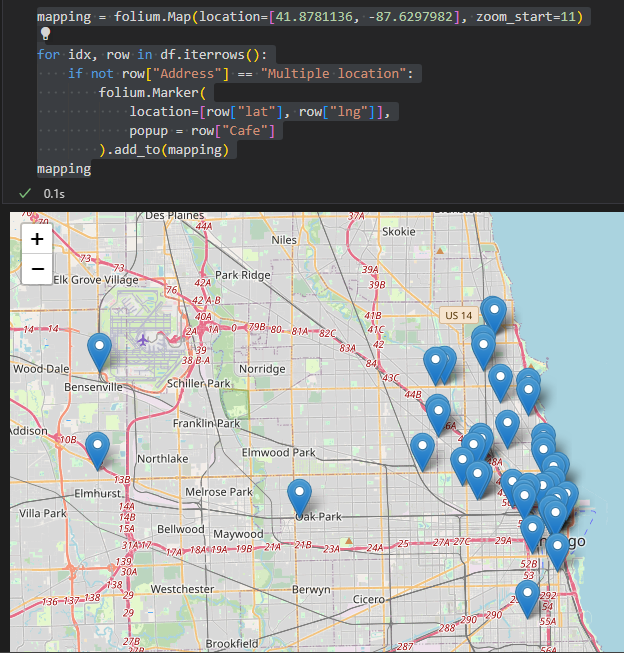
mapping = folium.Map(location=[41.8781136, -87.6297982], zoom_start=11)
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup = row["Cafe"],
tooltip=row["Menu"],
icon=folium.Icon(icon="coffee", prefix="fa")
).add_to(mapping)
mapping
위 글은 제로베이스 데이터 취업 스쿨의 강의자료를 참고하여 작성되었습니다.

허재