웹 스크래핑 vs 웹 크롤링
- 웹 스크래핑: 필요한 부분만
- 웹 크롤링: 마구잡이로
웹
🏡집이 있다고 할 때,
1. HTML : 뼈대
2. CSS : 인테리어, 예쁘게 하는 것
3. JS : 집을 살아있게 하는 것
HTML(Hyper TexT Markup Lanuage)
<html></html>: <여는 태그><닫는태그>
=<html/>: 한 줄로 표현 가능
<html>
<head></head>
<body></body>
</html><head></head>: 홈페이지의 제목을 정의 또는 HTML문서작업을 위해 선행하는 작업을 하는 부분<body></body>: 웹페이지의 본문을 정의
ex)
<html>
<head>
<title>나도코딩 홈페이지</title>
</head>
<body>
<h1>안녕하세요, 나도코딩입니다.</h1>
</body>
</html>*저장(Ctrl+s)후 실행
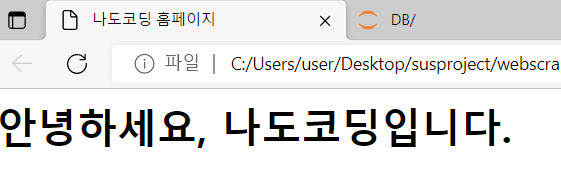 홈페이지 생성😆
홈페이지 생성😆
- 로그인 페이지 만들기
<html>
<head>
<meta charset="utf-8">
<title>나도코딩 홈페이지</title>
</head>
<body>
<input type="text" value="아이디를 입력하세요">
<input type="password">
<input type="button" value="로그인">
<a href="http://google.com">구글로 이동하기</a>
</body>
</html>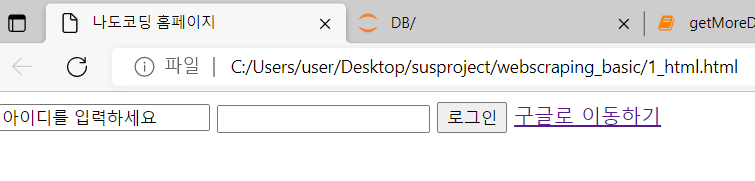
따란🙂
cf) html을 더 배우고 싶다면, w3school 검색
XPath
-
위의 예에서
<input type="button" value="로그인">이 값을 가져오고 싶다
👉 경로를 알아야한다 👉 이 때, 경로를 의미하는 것이 XPath -
ex) 1학년 1반의 이지은 학생 2명이라 누가 교무실에 부르면 누가 가야할지 모름
/학교/학년/반/학생[2]이때, 학번을 추가하여 XPath를 줄일 수 있다
//*[@학번"1-1-5"]✔️ 만약 이런 경우, 매우 유용
\html\body\div\div\div\div\div\div\span\a...html 한참 밑에 어떤 값이 login인 것을 찾는 전체 경로 대신
\\*[@id="login"]id가 login인 것을 모든 문서에서 찾아 줌
(여기서 '*' 의 의미: 학교, 학년, 학생 상관없이 모든 태그에서 찾음)
Requests
: html문서정보를 가져오기 위해 쓸 수 있는 라이브러리
1. TERMINAL창에 pip install request를 실행
2. import후, 사이트 불러 옴(ex.네이버)

- API 요청 방식
GET 방식:request.get()
POST 방식:request.post()
PUT 방식:request.put()
DELETE 방식:request.delete()
3. 사이트 오류 확인
1️⃣ res.status_code
: 정보 잘 받아왔는지, 페이지 접속 권한이 없는 지등의 문제가 여부를 파악하기 위한 코드 → 응답코드가 200일 경우, 정상⭕️


2️⃣ res.raise_for_status()
: 오류 발생 시, 오류를 내뱉고, 프로그램을 끝냄
→ 밑의 예에서 오류가 발생 시,print가 실행되지 않는다.

⇒ 아래 사진과 같이 3코드를 세트처럼 사용

4. 응답 전문 (3가지 방식)
response = requests.get("url")로 API 요청 후, 3가지 방식을 응답 전문을 읽어올 수 있다.
1️⃣ responese.content : 바이러니 원문
2️⃣ responese.text : UTF-8로 인코딩 된 문자열
3️⃣ responses.json() : 응답 데이터 JSON 포멧 👉 딕셔너리 객체
User Agent
Chrome에 user agent string 검색
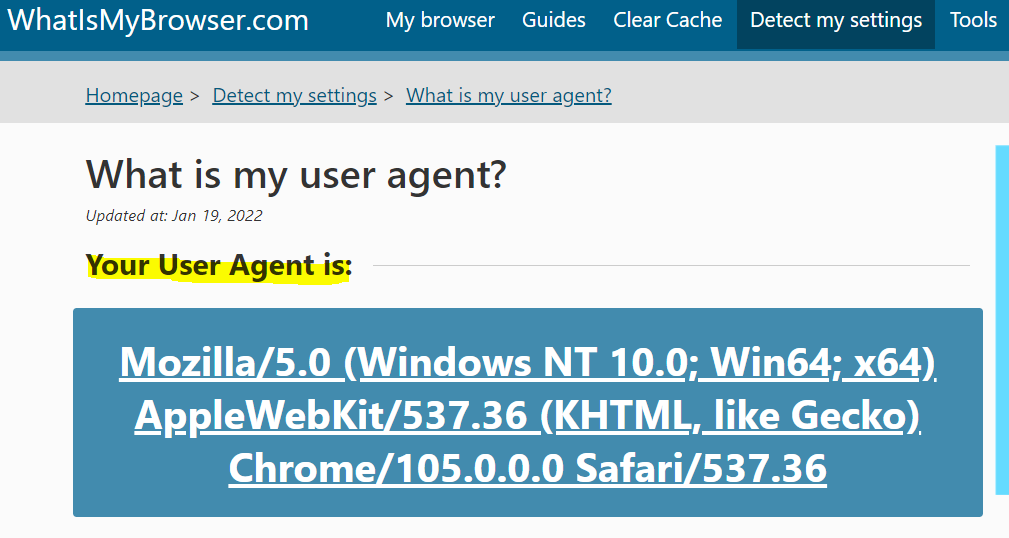
👉 복사하여, 아래 "User=Agnet": 코드 뒤에 삽입

헤더 옵션 추가하여 응답전문 받기: requests.get(url, headers = 헤더)
Selenium 기본1
1. webdriver import 후, 크롬 브라우저 호출
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("url")그 다음 단계 오류 발생!!!!!!
구글 무비
구글 무비에서 할인하고 있는 정보만 가져 오려 함
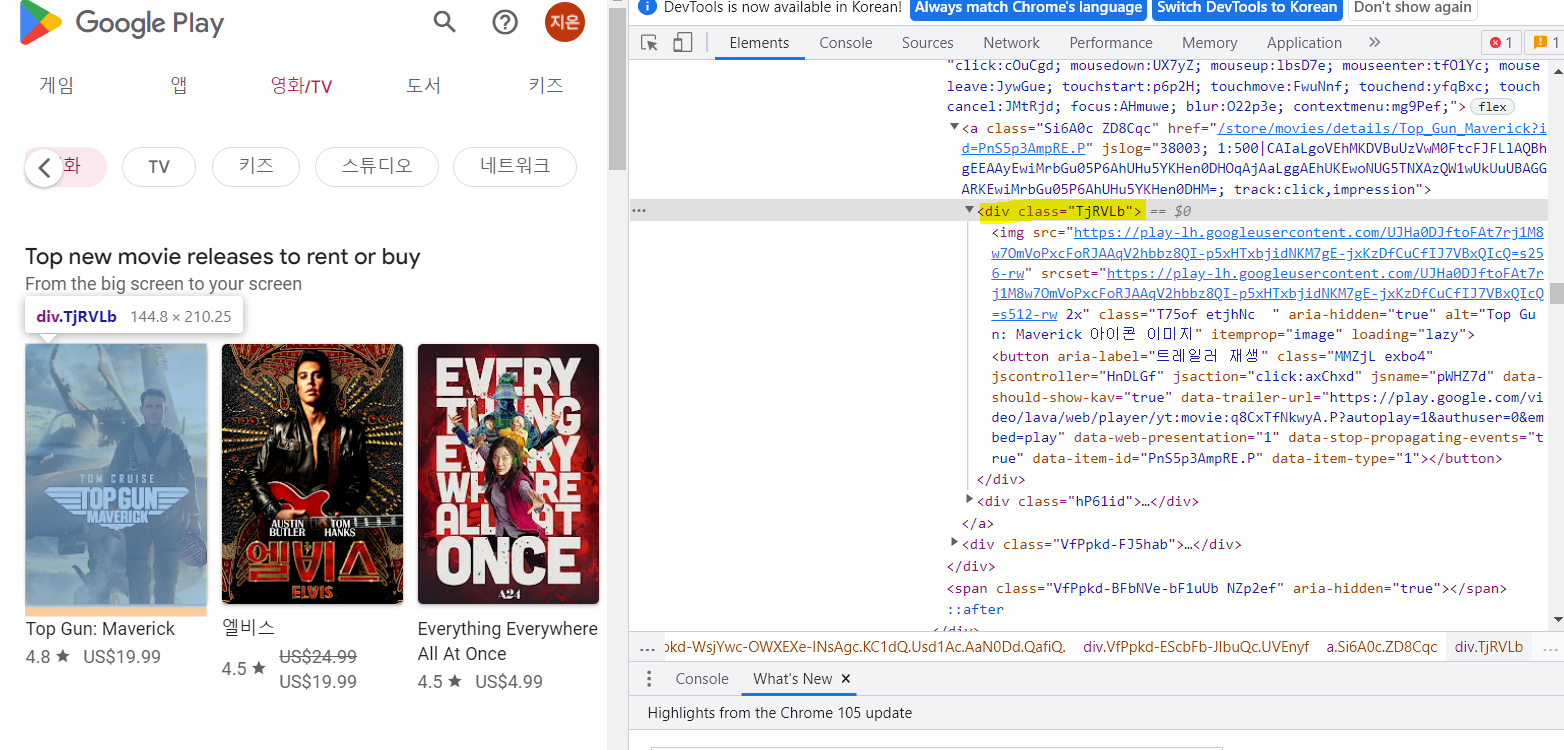
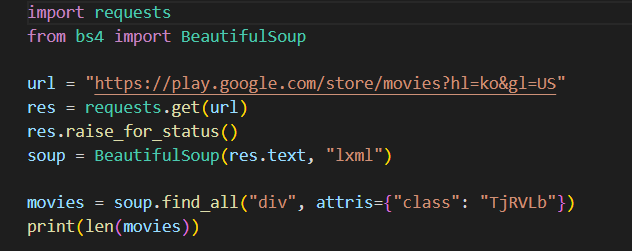
👉 결과 값으로 0이 도출
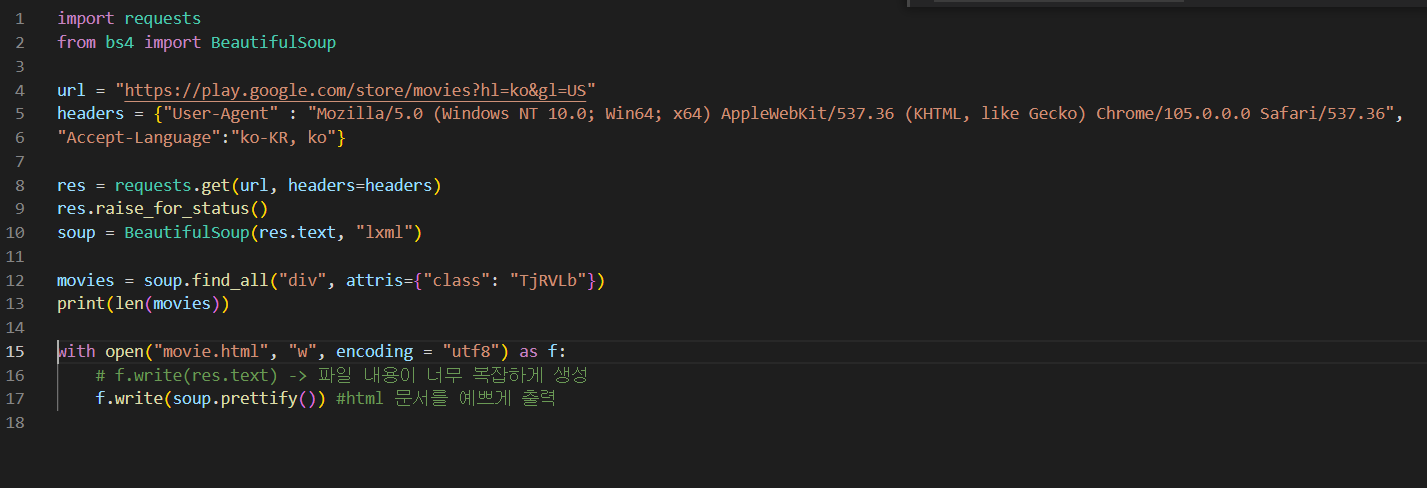
헤더 정보입력, 언어설정 변경 👉 결과 값으로 10이 도출(되어야 하는데 나는 안 됨 케켘,,)
💬 BeautifulSoup import과정에서 에러 발생
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
→ 해결 방법 : lxml 설치(pip install lxml)@참고: https://www.daleseo.com/python-requests/
@참고: https://blog.daum.net/sualchi/13721870
