
📖 학습 주제
- HTTP
- Python으로 HTTP 통신하기
- 윤리적인 웹 스크래핑,크롤링
- 웹 브라우저가 HTML을 다루는 방법
✏️ 주요 메모 사항 소개
HTTP (Hypertext Transfer Protocol)
- 인터넷은 여러 컴퓨터 끼리 네트워크로 연결한 것.
Web은 인터넷 상에서 정보를 교환하기 위한 시스템.Web상에서 정보를 주고받는데HTTP를 사용한다.HTTP란 웹 상에서 정보를 주고받기 위한 약속을 말한다.
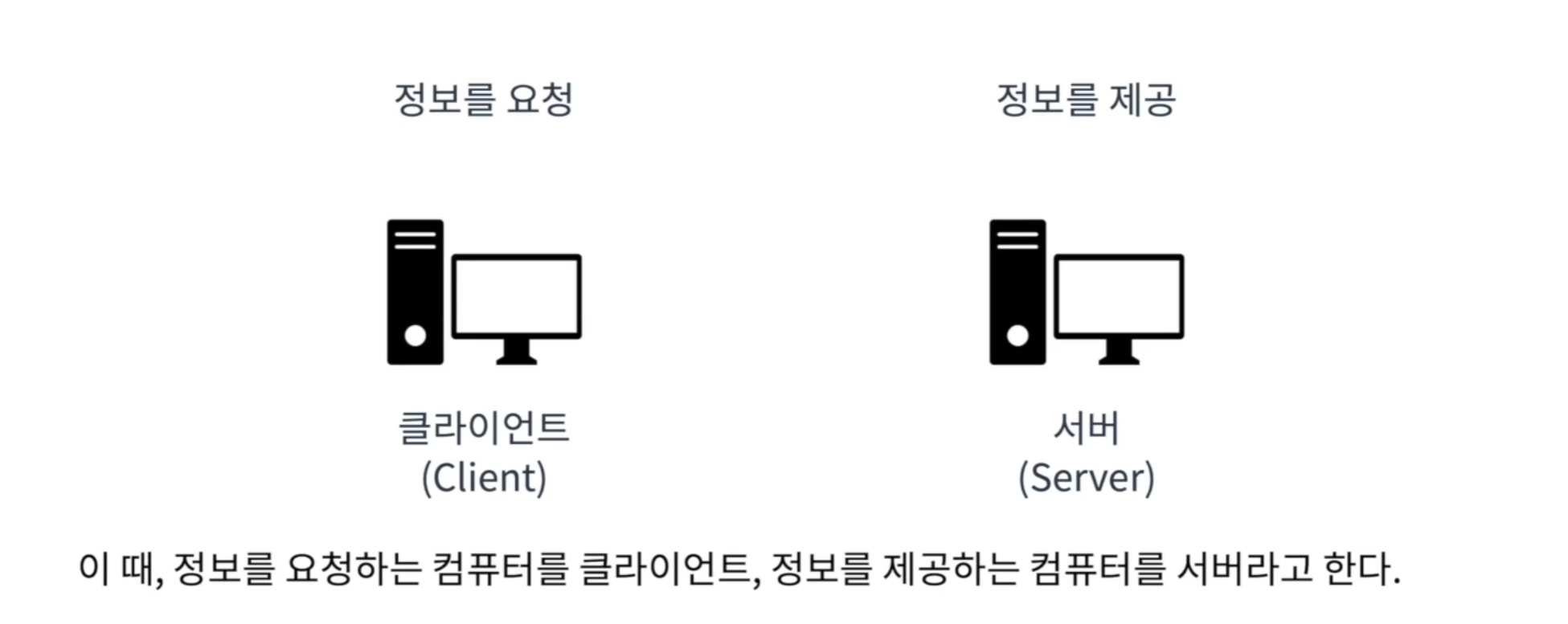
<상호작용 과정>
HTTP 요청 (Request): 클라이언트가 서버에 정보를 요청- 요청에 대해서 서버가 작업을 수행
HTTP 응답 (Response): 수행한 작업의 결과를 클라이언트에게 응답
<HTTP의 구조>
Head: 요청/응답에 대한 정보Body: 내용물
<웹 페이지와 웹 브라우저>
- 웹 브라우저는 HTML 요청을 보내고, HTTP 응담에 담긴 HTML 문서를 우리가 보기 쉬운 형태로 화면을 그려주는 역할을 담당
- 웹 페이지는 HTML 이라는 형식으로 되어있고, 웹 브라우저는 우리가 HTTP 요청을 보내고, 응답받은 HTML 코드를 렌더링 해주었다.
- 웹 스크래핑 관점에서 우리는 원하는 내용이 HTML 문서의 어디에 어떤 태그로 묶여있는지를 관찰해야 한다.
HTTP 통신 코드
- Python은
requests라이브러리를 이용해 간단히 HTTP 통신이 가능하다. 터미널에서requests라이브러리를 설치하자.
pip install requests
<정보 요청하기> GET
import requests
res = requests.get("https://www.naver.com")
<정보 확인>
res.headers
res.text[:1000]
<정보 갱신 요청> POST
payload = {"name": "Hello", "age": 13}
res = requests.post("https://webhook.site/0083feff-1b48-406d-84c3-045bb2eec58c", payload)
res.status_codeWeb Scrapping
웹 크롤링 vs 웹 스크래핑
Web Scrapping : 특정학 목적으로 웹 페이지들로부터 우리가 원하는 정보를 추출, (데이터 추출)
Web Crawling : URL을 타고다니며 반복적으로 크롤러(Crawler)를 이용하여 웹 페이지의 정보를 인덱싱 (데이터 색인)
<주의점>
- 웹 스크래핑/크롤링을 통해 어떤 목적을 달성하고자 하는가?
- 나의 웹 스크래핑/크롤링이 서버에 영향을 미치지는 않는가?
로봇 배제 프로토콜 (REP)
- 웹 브라우징은 사람이 아닌, 로봇이 진행할 수도 있다. 따라서 무턱대고 모든 사이트에 대해 모든 정보를 취득하는 것이 정당할까? 라는 의문에 약속을 정함.
- 웹 크롤러들은 이 규칙을 지키면서 크롤링을 진행해야 한다.
robots.txt문서의User-agent,Allow,Disallow여부를 확인
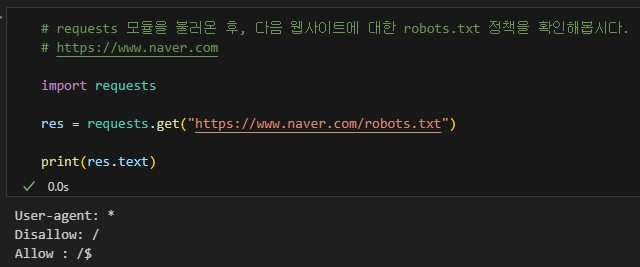
requests라이브러리를 이용하여 웹 페이지의robots.txt파일을 읽어온 결과 값에 따라 크롤링을 할지 말지를 결정해야 한다.- 위의 예제는 모든 유저에 대해 모든 페이지에 크롤링을 금지하고 있다.
웹 브라우저가 HTML을 다루는 방법
DOM (Document Object Model)
- 브라우저의 렌더링 엔진은 웹 문서를 로드한 후, 파싱을 진행, 이를 묶어서 만들어낸 것을
DOM이라고 한다.- 파싱한 단위를 객체로 만들어서
DOM Tree를 만들어 순회해서 특정 원소를 추가와 같은 동작을 수행할 수 있다.- 이렇게 하면 원하는 요소를 동적으로 변경할 수 있고, 원하는 요소를 쉽게 찾을 수 있다.
- 위와 유사한 방식으로 파이썬으로 HTML을 분석하고 사용하기 위해서
HTML Parser가 필요하다.
💦 공부하며 어려웠던 내용
웹 공부를 하다와서 기본적인 HTTP 내용이라 어려움은 없었다. 스크래핑과 크롤링은 알고 있었는데 로봇 배제 프로토콜은 처음 들어봐서 더 알아보고 싶다는 생각이 들었다.
