
📖 학습 주제
- GROUP BY
- CTAS & CTE
✏️ 주요 메모 사항 소개
GROUP BY
테이블의 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산하는 명령어. 먼저 그룹핑을 할 필드(하나 이상의 필드 가능)를 결정하고 그룹별로 계산할 내용을 결정한다. 두번째 단계에서
Aggregate함수를 사용한다. (EX. COUNT, SUM. AVG, MIN ...)
예제
- 월별 세션 수를 계산하는 SQL (
raw_data.session_timestamp테이블을 사용,sessionId&ts필드)
SELECT
LEFT(ts, 7) AS mon,
COUNT(1) AS session_count
FROM raw_data.session_timestamp
GROUP BY 1 -- GROUP BY mon, GROUP BY LEFT(ts, 7)
ORDER BY 1;- 가장 많이 사용된 채널을 알아내는 SQL
SELECT
channel,
COUNT(1) AS session_count,
COUNT(DISTINCT userId) AS user_count
FROM raw_data.user_session_channel
GROUP BY 1 -- GROUP BY channel
ORDER BY 2 DESC; -- ORDER BY session_count DESC- 가장 많은 세션을 만들어낸 사용자 ID를 구하는 SQL
SELECT
userId,
COUNT(1) AS count
FROM raw_data.user_session_channel
GROUP BY 1 -- GROUP BY userId
ORDER BY 2 DESC -- ORDER BY count DESC
LIMIT 1; -- 한개만 출력- 월별 유니크한 사용자 수를 구하는 SQL,
Monthly Active User를 구하는 SQL (JOIN필요)
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS MONTH,
COUNT(DISTINCT B.userID) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionId = B.sessionId
GROUP BY 1
ORDER BY 1 DESC;- 월별 채널별 유니크한 사용자 수를 구하는 SQL
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month
channel,
COUNT(DISTINCT B.userId) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionId = B.sessionId
GROUP BY 1,2
ORDER BY 1 DESC, 2;CTAS
- 간단하게 새로운 테이블을 만드는 방법으로 자주 조인하는 테이블들이 있다면 이를 CTAS를 사용해서 먼저 조인해두면 편리해진다.
DROP TABLE IF EXISTS adhoc.keeyong_session_summary;
CREATE TABLE adhoc.sangwon_session_summary AS
SELECT B.* A.ts FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionId = B.sessionId;- 이렇게 만들어 놓으면 앞선 예제에 있었던 '월별 유니크한 사용자 수' 찾기와 같은 SQL 문을 간결하게 작성할 수 있다.
SELECT
TO_CHAR(ts, 'YYYY-MM') AS month,
COUNT(DISTINCT userId) as mau
FROM adhoc.sangwon_session_summary
GROUP BY 1
ORDER BY 1 DESC;데이터 품질 확인
- 이렇게 새로운 테이블을 만들거나 사용할 때는 다음과 같은 방식으로 항상 데이터 품질을 확인해보아야 한다.
- 중복된 레코드들 체크하기
-- 두개의 SELECT 결과의 값을 비교해서 중복을 검사 만약 중복이 있다면 아래의 값이 위의 값보다 적게 나올 것
-- 총 레코드 수
SELECT COUNT(1)
FROM adhoc.sangwon_session_summary;
-- 중복 제거한 레코드 수
SELECT CONUT(1)
FROM (
SELECT DISTINCT userId, sessionId, ts, channel
FROM adhoc.sangwon_session_summary
);
-- CTE를 사용해서 중복을 제거할 수도 있다. 이렇게 사용하게 되면 뒤에서 추가적으로 ds라는 임시 테이블을 재사용할 수 있다.
With ds AS(
SELECT DISTINCT userId, sessionId, ts, channel
FROM adhoc.sangwon_session_summary
)
SELECT COUNT(1)
FROM ds;
- 최근 데이터의 존재 여부 체크하기 (freshness)
-- timestamp가 찍힌 ts의 MIN과 MAX를 비교해서 언제부터 언제까지의 데이터가 존재하는지 체크
SELECT MIN(ts), MAX(ts)
FROM adhoc.sangwon_session_summary;
- Primary key uniqueness가 지켜지는지 체크하기
-- 각각의 sessionId의 COUNT를 내림차순으로 1개만 출력해서 만약 2 이상의 값이 나온다면 uniqueness가 지켜지지 않고 있다고 판단한다.
SELECT sessionId, COUNT(1)
FROM adhoc.sangwon_session_summary
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1;
- 값이 비어있는 컬럼들이 있는지 체크하기
-- 각 레코드의 칼럼에 NULL 값이 존재할 시 각 칼럼의 null count를 1로 리턴, 출력값이 0이 아닐 시 비어있는 칼럼들이 있다는 뜻
SELECT
COUNT(CASE WHEN sessionId is NULL THEN 1 END) sessionId_null_count,
COUNT(CASE WHEN userId is NULL THEN 1 END) userId_null_count,
COUNT(CASE WHEN ts is NULL THEN 1 END) ts_null_count,
COUNT(CASE WHEN channel is NULL THEN 1 END) channel_null_count
FROM adhoc.sangwon_session_summary;숙제
- 현재 DB의 테이블 구성은 다음과 같다
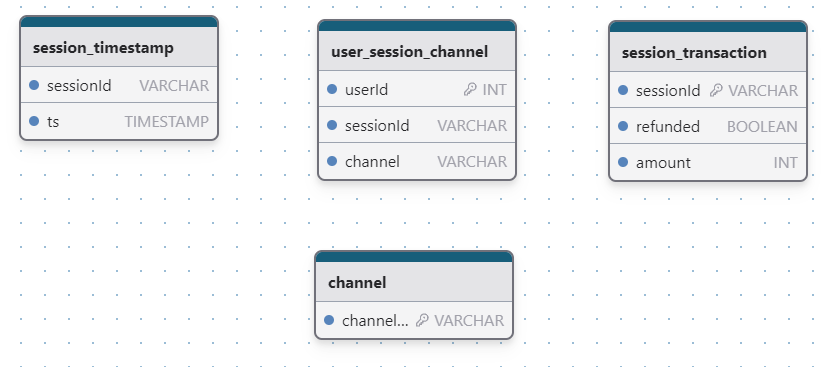
- 이 테이블들을 적절히 활용하여 다음 조건에 맞는 테이블을 만들기

CREATE TABLE channel_month_revenue AS
SELECT
TO_CHAR(raw_st.ts, 'YYYY-MM') AS month,
raw_usc.channel AS channel,
COUNT(DISTINCT raw_usc.userId) AS uniqueUsers,
COUNT(DISTINCT CASE WHEN raw_st2.refunded = FALSE THEN raw_st2.sessionId ELSE NULL END) AS paidUsers,
ROUND(
CASE
WHEN COUNT(DISTINCT raw_usc.userId) > 0 THEN
COUNT(DISTINCT CASE WHEN raw_st2.refunded = FALSE THEN raw_st2.sessionId ELSE NULL END)::FLOAT / COUNT(DISTINCT raw_usc.userId)
ELSE
0
END
, 2) AS conversionRate,
SUM(raw_st2.amount) AS grossRevenue,
SUM(CASE WHEN raw_st2.refunded = FALSE THEN raw_st2.amount ELSE 0 END) AS netRevenue
FROM
raw_data.session_timestamp AS raw_st
JOIN
raw_data.user_session_channel AS raw_usc ON raw_st.sessionId = raw_usc.sessionId
JOIN
raw_data.session_transaction AS raw_st2 ON raw_st.sessionId = raw_st2.sessionId
GROUP BY
TO_CHAR(raw_st.ts, 'YYYY-MM'), raw_usc.channel- 결과
SELECT * FROM channel_month_revenue
ORDER BY month, channel
LIMIT 15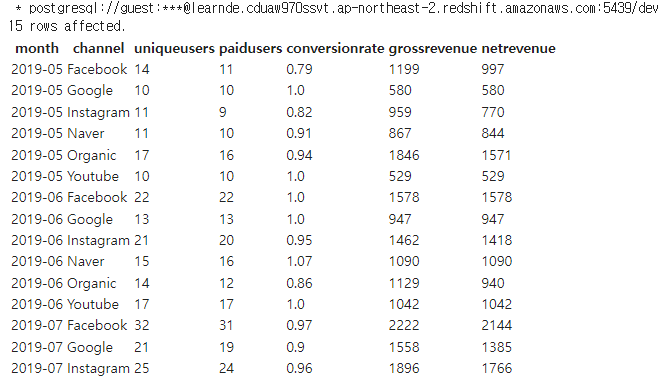
숙제 리뷰 추가
- 테이블을 만들기 앞서 혹시 OUT JOIN이 필요한지 테이블 점검이 필요하다
-- 두 테이블간의 sessionId에 차이가 있는지 확인하기
select distinct sessionid from raw_data.session_timestamp
minus
select distinct sessionid from raw_data.user_session_channel;
select distinct sessionid from raw_data.user_session_channel
minus
select distinct sessionid from raw_data.session_timestamp;
-- amout에 잘못된 값이 들어있는지 확인하기
select * from raw_data.session_transaction
where amount <= 0- uniqueUsers를 구하는 부분과 paidUsers를 구하는 부분이 잘못된 것 같다. LEFT 조인을 하지 않아서 transaction이나 timestamp와 매치되지 않는 레코드들이 다 날라가버려서 값이 이상하게 나온다. 다음은 수정된 코드
DROP TABLE IF EXISTS channel_month_revenue;
CREATE TABLE channel_month_revenue AS
SELECT LEFT(ts, 7) "month",
channel,
COUNT(DISTINCT usc.userId) uniqueUsers,
COUNT(DISTINCT CASE WHEN amount > 0 THEN usc.userId END) paidUsers,
ROUND(paidUsers::float*100 / NULLIF(uniqueUsers, 0), 2) conversionRate,
SUM(amount) grossRevenue,
SUM(CASE WHEN refunded is False THEN amount END) netRevenue
FROM raw_data.user_session_channel usc
LEFT JOIN raw_data.session_timestamp t ON t.sessionId = usc.sessionId
LEFT JOIN raw_data.session_transaction st ON st.sessionId = usc.sessionId
GROUP BY 1, 2;